 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRunsheng Xu
Light the Night: A Multi-Condition Diffusion Framework for Unpaired Low-Light Enhancement in Autonomous Driving
Apr 07, 2024
Vision-centric perception systems for autonomous driving have gained considerable attention recently due to their cost-effectiveness and scalability, especially compared to LiDAR-based systems. However, these systems often struggle in low-light conditions, potentially compromising their performance and safety. To address this, our paper introduces LightDiff, a domain-tailored framework designed to enhance the low-light image quality for autonomous driving applications. Specifically, we employ a multi-condition controlled diffusion model. LightDiff works without any human-collected paired data, leveraging a dynamic data degradation process instead. It incorporates a novel multi-condition adapter that adaptively controls the input weights from different modalities, including depth maps, RGB images, and text captions, to effectively illuminate dark scenes while maintaining context consistency. Furthermore, to align the enhanced images with the detection model's knowledge, LightDiff employs perception-specific scores as rewards to guide the diffusion training process through reinforcement learning. Extensive experiments on the nuScenes datasets demonstrate that LightDiff can significantly improve the performance of several state-of-the-art 3D detectors in night-time conditions while achieving high visual quality scores, highlighting its potential to safeguard autonomous driving.
V2X-DGW: Domain Generalization for Multi-agent Perception under Adverse Weather Conditions
Mar 29, 2024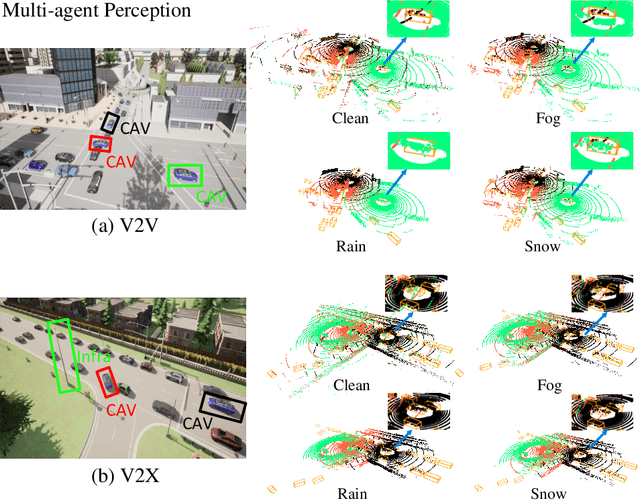
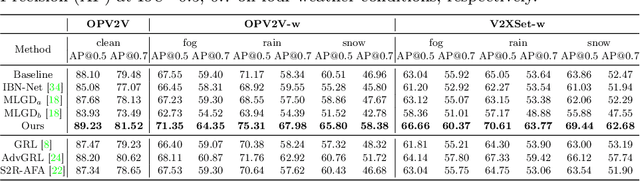
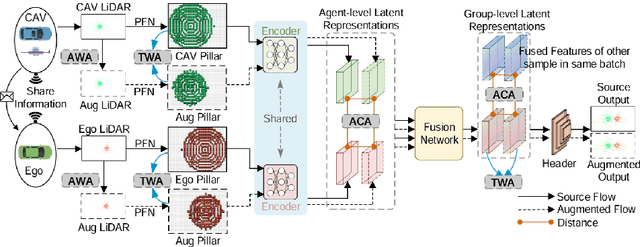
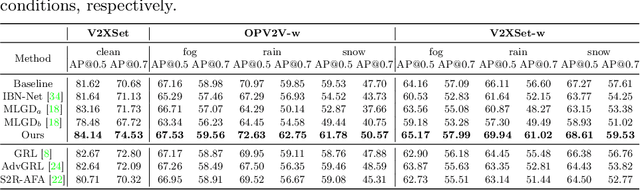
Current LiDAR-based Vehicle-to-Everything (V2X) multi-agent perception systems have shown the significant success on 3D object detection. While these models perform well in the trained clean weather, they struggle in unseen adverse weather conditions with the real-world domain gap. In this paper, we propose a domain generalization approach, named V2X-DGW, for LiDAR-based 3D object detection on multi-agent perception system under adverse weather conditions. Not only in the clean weather does our research aim to ensure favorable multi-agent performance, but also in the unseen adverse weather conditions by learning only on the clean weather data. To advance research in this area, we have simulated the impact of three prevalent adverse weather conditions on two widely-used multi-agent datasets, resulting in the creation of two novel benchmark datasets: OPV2V-w and V2XSet-w. To this end, we first introduce the Adaptive Weather Augmentation (AWA) to mimic the unseen adverse weather conditions, and then propose two alignments for generalizable representation learning: Trust-region Weather-invariant Alignment (TWA) and Agent-aware Contrastive Alignment (ACA). Extensive experimental results demonstrate that our V2X-DGW achieved improvements in the unseen adverse weather conditions.
V2X-Real: a Largs-Scale Dataset for Vehicle-to-Everything Cooperative Perception
Mar 24, 2024Recent advancements in Vehicle-to-Everything (V2X) technologies have enabled autonomous vehicles to share sensing information to see through occlusions, greatly boosting the perception capability. However, there are no real-world datasets to facilitate the real V2X cooperative perception research -- existing datasets either only support Vehicle-to-Infrastructure cooperation or Vehicle-to-Vehicle cooperation. In this paper, we propose a dataset that has a mixture of multiple vehicles and smart infrastructure simultaneously to facilitate the V2X cooperative perception development with multi-modality sensing data. Our V2X-Real is collected using two connected automated vehicles and two smart infrastructures, which are all equipped with multi-modal sensors including LiDAR sensors and multi-view cameras. The whole dataset contains 33K LiDAR frames and 171K camera data with over 1.2M annotated bounding boxes of 10 categories in very challenging urban scenarios. According to the collaboration mode and ego perspective, we derive four types of datasets for Vehicle-Centric, Infrastructure-Centric, Vehicle-to-Vehicle, and Infrastructure-to-Infrastructure cooperative perception. Comprehensive multi-class multi-agent benchmarks of SOTA cooperative perception methods are provided. The V2X-Real dataset and benchmark codes will be released.
Breaking Data Silos: Cross-Domain Learning for Multi-Agent Perception from Independent Private Sources
Feb 20, 2024The diverse agents in multi-agent perception systems may be from different companies. Each company might use the identical classic neural network architecture based encoder for feature extraction. However, the data source to train the various agents is independent and private in each company, leading to the Distribution Gap of different private data for training distinct agents in multi-agent perception system. The data silos by the above Distribution Gap could result in a significant performance decline in multi-agent perception. In this paper, we thoroughly examine the impact of the distribution gap on existing multi-agent perception systems. To break the data silos, we introduce the Feature Distribution-aware Aggregation (FDA) framework for cross-domain learning to mitigate the above Distribution Gap in multi-agent perception. FDA comprises two key components: Learnable Feature Compensation Module and Distribution-aware Statistical Consistency Module, both aimed at enhancing intermediate features to minimize the distribution gap among multi-agent features. Intensive experiments on the public OPV2V and V2XSet datasets underscore FDA's effectiveness in point cloud-based 3D object detection, presenting it as an invaluable augmentation to existing multi-agent perception systems.
DUSA: Decoupled Unsupervised Sim2Real Adaptation for Vehicle-to-Everything Collaborative Perception
Oct 12, 2023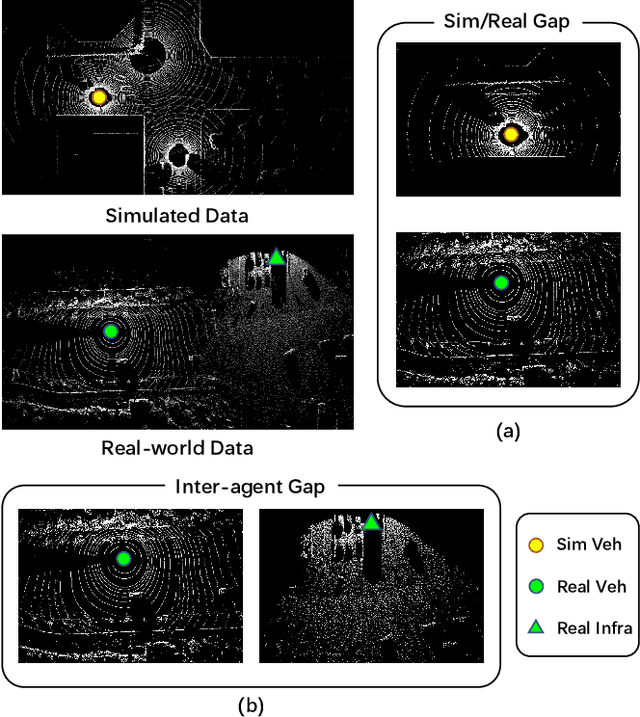
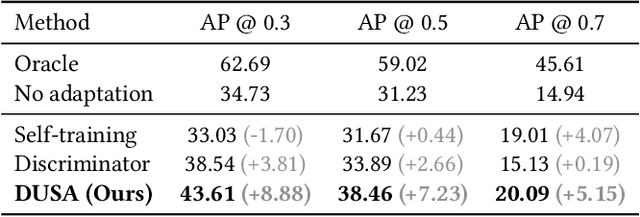
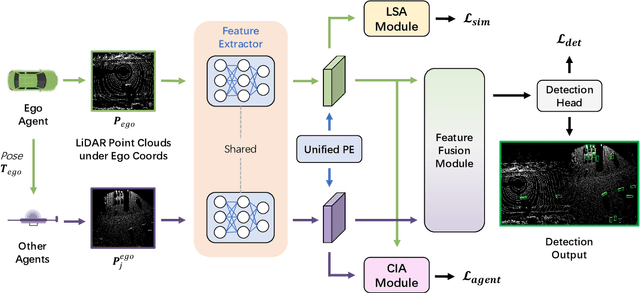
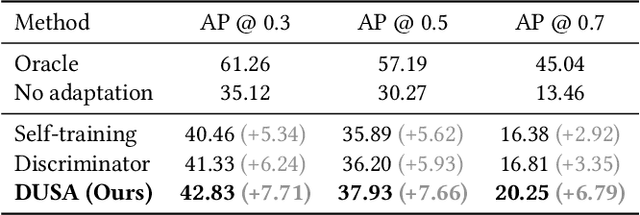
Vehicle-to-Everything (V2X) collaborative perception is crucial for autonomous driving. However, achieving high-precision V2X perception requires a significant amount of annotated real-world data, which can always be expensive and hard to acquire. Simulated data have raised much attention since they can be massively produced at an extremely low cost. Nevertheless, the significant domain gap between simulated and real-world data, including differences in sensor type, reflectance patterns, and road surroundings, often leads to poor performance of models trained on simulated data when evaluated on real-world data. In addition, there remains a domain gap between real-world collaborative agents, e.g. different types of sensors may be installed on autonomous vehicles and roadside infrastructures with different extrinsics, further increasing the difficulty of sim2real generalization. To take full advantage of simulated data, we present a new unsupervised sim2real domain adaptation method for V2X collaborative detection named Decoupled Unsupervised Sim2Real Adaptation (DUSA). Our new method decouples the V2X collaborative sim2real domain adaptation problem into two sub-problems: sim2real adaptation and inter-agent adaptation. For sim2real adaptation, we design a Location-adaptive Sim2Real Adapter (LSA) module to adaptively aggregate features from critical locations of the feature map and align the features between simulated data and real-world data via a sim/real discriminator on the aggregated global feature. For inter-agent adaptation, we further devise a Confidence-aware Inter-agent Adapter (CIA) module to align the fine-grained features from heterogeneous agents under the guidance of agent-wise confidence maps. Experiments demonstrate the effectiveness of the proposed DUSA approach on unsupervised sim2real adaptation from the simulated V2XSet dataset to the real-world DAIR-V2X-C dataset.
Optimizing the Placement of Roadside LiDARs for Autonomous Driving
Oct 11, 2023Multi-agent cooperative perception is an increasingly popular topic in the field of autonomous driving, where roadside LiDARs play an essential role. However, how to optimize the placement of roadside LiDARs is a crucial but often overlooked problem. This paper proposes an approach to optimize the placement of roadside LiDARs by selecting optimized positions within the scene for better perception performance. To efficiently obtain the best combination of locations, a greedy algorithm based on perceptual gain is proposed, which selects the location that can maximize the perceptual gain sequentially. We define perceptual gain as the increased perceptual capability when a new LiDAR is placed. To obtain the perception capability, we propose a perception predictor that learns to evaluate LiDAR placement using only a single point cloud frame. A dataset named Roadside-Opt is created using the CARLA simulator to facilitate research on the roadside LiDAR placement problem.
Towards Vehicle-to-everything Autonomous Driving: A Survey on Collaborative Perception
Aug 31, 2023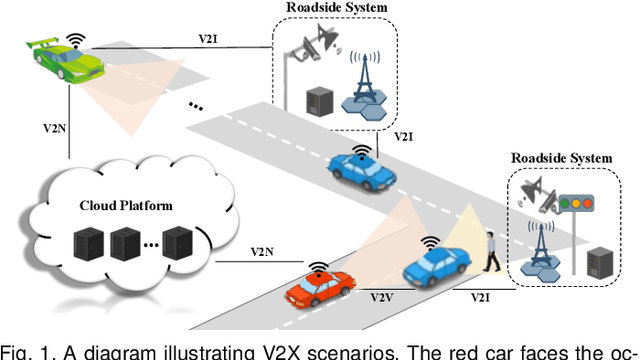
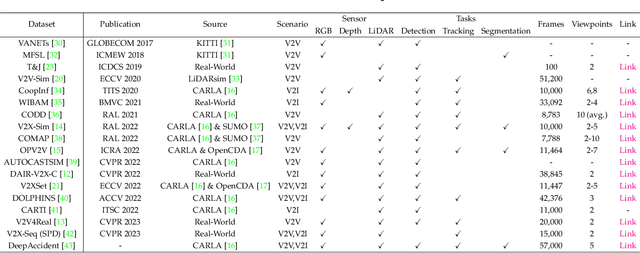
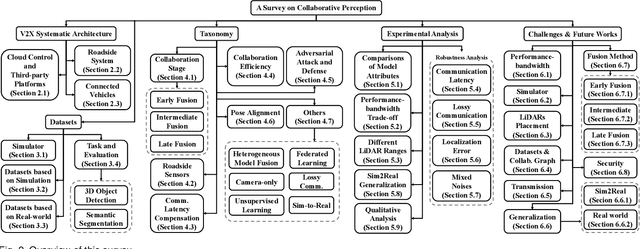
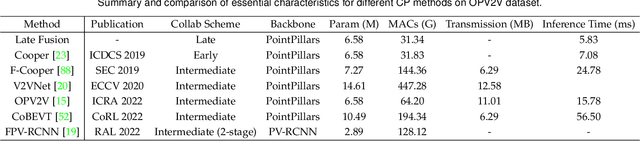
Vehicle-to-everything (V2X) autonomous driving opens up a promising direction for developing a new generation of intelligent transportation systems. Collaborative perception (CP) as an essential component to achieve V2X can overcome the inherent limitations of individual perception, including occlusion and long-range perception. In this survey, we provide a comprehensive review of CP methods for V2X scenarios, bringing a profound and in-depth understanding to the community. Specifically, we first introduce the architecture and workflow of typical V2X systems, which affords a broader perspective to understand the entire V2X system and the role of CP within it. Then, we thoroughly summarize and analyze existing V2X perception datasets and CP methods. Particularly, we introduce numerous CP methods from various crucial perspectives, including collaboration stages, roadside sensors placement, latency compensation, performance-bandwidth trade-off, attack/defense, pose alignment, etc. Moreover, we conduct extensive experimental analyses to compare and examine current CP methods, revealing some essential and unexplored insights. Specifically, we analyze the performance changes of different methods under different bandwidths, providing a deep insight into the performance-bandwidth trade-off issue. Also, we examine methods under different LiDAR ranges. To study the model robustness, we further investigate the effects of various simulated real-world noises on the performance of different CP methods, covering communication latency, lossy communication, localization errors, and mixed noises. In addition, we look into the sim-to-real generalization ability of existing CP methods. At last, we thoroughly discuss issues and challenges, highlighting promising directions for future efforts. Our codes for experimental analysis will be public at https://github.com/memberRE/Collaborative-Perception.
Domain Adaptation based Enhanced Detection for Autonomous Driving in Foggy and Rainy Weather
Jul 20, 2023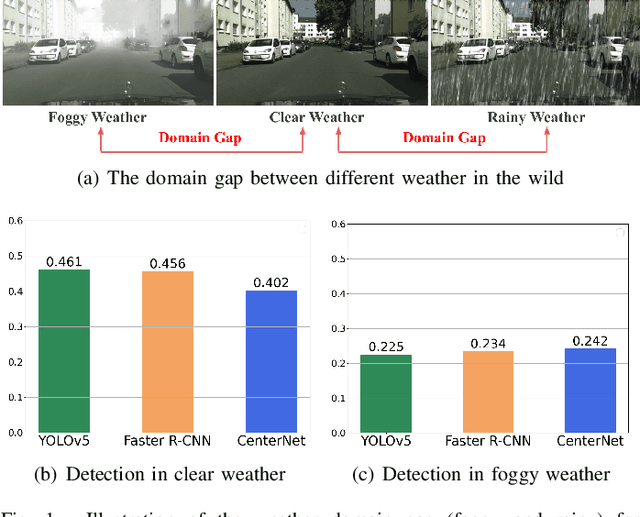
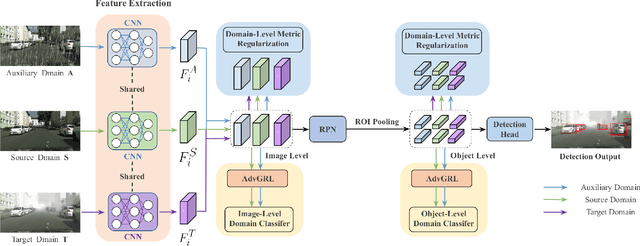

Typically, object detection methods for autonomous driving that rely on supervised learning make the assumption of a consistent feature distribution between the training and testing data, however such assumption may fail in different weather conditions. Due to the domain gap, a detection model trained under clear weather may not perform well in foggy and rainy conditions. Overcoming detection bottlenecks in foggy and rainy weather is a real challenge for autonomous vehicles deployed in the wild. To bridge the domain gap and improve the performance of object detectionin foggy and rainy weather, this paper presents a novel framework for domain-adaptive object detection. The adaptations at both the image-level and object-level are intended to minimize the differences in image style and object appearance between domains. Furthermore, in order to improve the model's performance on challenging examples, we introduce a novel adversarial gradient reversal layer that conducts adversarial mining on difficult instances in addition to domain adaptation. Additionally, we suggest generating an auxiliary domain through data augmentation to enforce a new domain-level metric regularization. Experimental findings on public V2V benchmark exhibit a substantial enhancement in object detection specifically for foggy and rainy driving scenarios.
S2R-ViT for Multi-Agent Cooperative Perception: Bridging the Gap from Simulation to Reality
Jul 18, 2023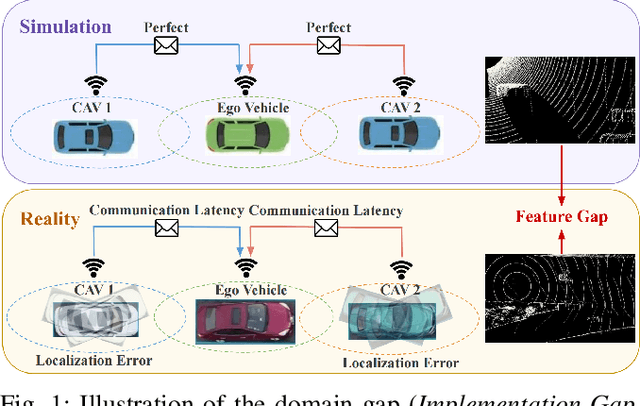
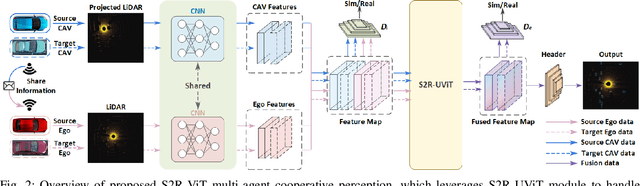
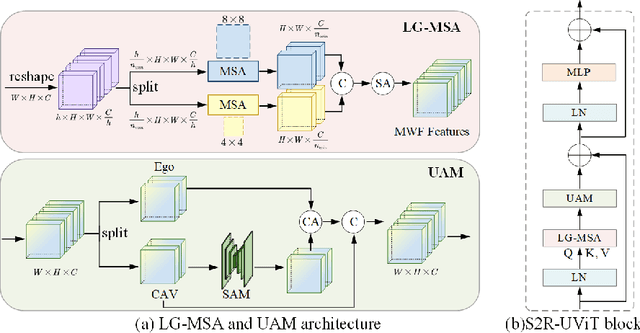
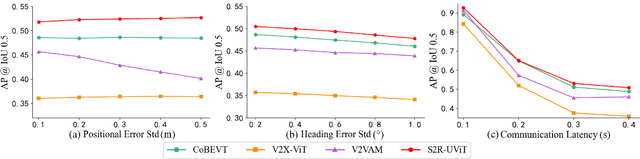
Due to the lack of real multi-agent data and time-consuming of labeling, existing multi-agent cooperative perception algorithms usually select the simulated sensor data for training and validating. However, the perception performance is degraded when these simulation-trained models are deployed to the real world, due to the significant domain gap between the simulated and real data. In this paper, we propose the first Simulation-to-Reality transfer learning framework for multi-agent cooperative perception using a novel Vision Transformer, named as S2R-ViT, which considers both the Implementation Gap and Feature Gap between simulated and real data. We investigate the effects of these two types of domain gaps and propose a novel uncertainty-aware vision transformer to effectively relief the Implementation Gap and an agent-based feature adaptation module with inter-agent and ego-agent discriminators to reduce the Feature Gap. Our intensive experiments on the public multi-agent cooperative perception datasets OPV2V and V2V4Real demonstrate that the proposed S2R-ViT can effectively bridge the gap from simulation to reality and outperform other methods significantly for point cloud-based 3D object detection.
HM-ViT: Hetero-modal Vehicle-to-Vehicle Cooperative perception with vision transformer
Apr 20, 2023



Vehicle-to-Vehicle technologies have enabled autonomous vehicles to share information to see through occlusions, greatly enhancing perception performance. Nevertheless, existing works all focused on homogeneous traffic where vehicles are equipped with the same type of sensors, which significantly hampers the scale of collaboration and benefit of cross-modality interactions. In this paper, we investigate the multi-agent hetero-modal cooperative perception problem where agents may have distinct sensor modalities. We present HM-ViT, the first unified multi-agent hetero-modal cooperative perception framework that can collaboratively predict 3D objects for highly dynamic vehicle-to-vehicle (V2V) collaborations with varying numbers and types of agents. To effectively fuse features from multi-view images and LiDAR point clouds, we design a novel heterogeneous 3D graph transformer to jointly reason inter-agent and intra-agent interactions. The extensive experiments on the V2V perception dataset OPV2V demonstrate that the HM-ViT outperforms SOTA cooperative perception methods for V2V hetero-modal cooperative perception. We will release codes to facilitate future research.