 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHechang Chen
DS-Agent: Automated Data Science by Empowering Large Language Models with Case-Based Reasoning
Mar 13, 2024
In this work, we investigate the potential of large language models (LLMs) based agents to automate data science tasks, with the goal of comprehending task requirements, then building and training the best-fit machine learning models. Despite their widespread success, existing LLM agents are hindered by generating unreasonable experiment plans within this scenario. To this end, we present DS-Agent, a novel automatic framework that harnesses LLM agent and case-based reasoning (CBR). In the development stage, DS-Agent follows the CBR framework to structure an automatic iteration pipeline, which can flexibly capitalize on the expert knowledge from Kaggle, and facilitate consistent performance improvement through the feedback mechanism. Moreover, DS-Agent implements a low-resource deployment stage with a simplified CBR paradigm to adapt past successful solutions from the development stage for direct code generation, significantly reducing the demand on foundational capabilities of LLMs. Empirically, DS-Agent with GPT-4 achieves an unprecedented 100% success rate in the development stage, while attaining 36% improvement on average one pass rate across alternative LLMs in the deployment stage. In both stages, DS-Agent achieves the best rank in performance, costing \$1.60 and \$0.13 per run with GPT-4, respectively. Our code is open-sourced at https://github.com/guosyjlu/DS-Agent.
Learning Generalizable Agents via Saliency-Guided Features Decorrelation
Oct 08, 2023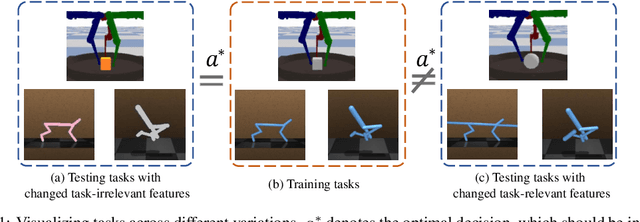
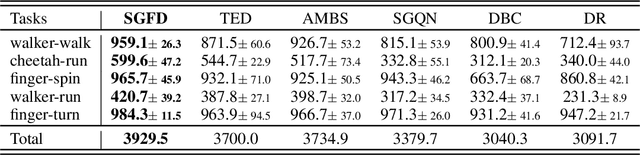
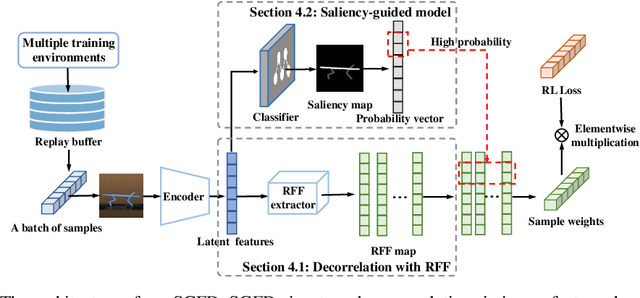

In visual-based Reinforcement Learning (RL), agents often struggle to generalize well to environmental variations in the state space that were not observed during training. The variations can arise in both task-irrelevant features, such as background noise, and task-relevant features, such as robot configurations, that are related to the optimal decisions. To achieve generalization in both situations, agents are required to accurately understand the impact of changed features on the decisions, i.e., establishing the true associations between changed features and decisions in the policy model. However, due to the inherent correlations among features in the state space, the associations between features and decisions become entangled, making it difficult for the policy to distinguish them. To this end, we propose Saliency-Guided Features Decorrelation (SGFD) to eliminate these correlations through sample reweighting. Concretely, SGFD consists of two core techniques: Random Fourier Functions (RFF) and the saliency map. RFF is utilized to estimate the complex non-linear correlations in high-dimensional images, while the saliency map is designed to identify the changed features. Under the guidance of the saliency map, SGFD employs sample reweighting to minimize the estimated correlations related to changed features, thereby achieving decorrelation in visual RL tasks. Our experimental results demonstrate that SGFD can generalize well on a wide range of test environments and significantly outperforms state-of-the-art methods in handling both task-irrelevant variations and task-relevant variations.
Careful at Estimation and Bold at Exploration
Aug 22, 2023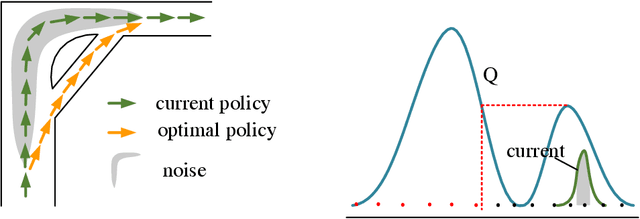
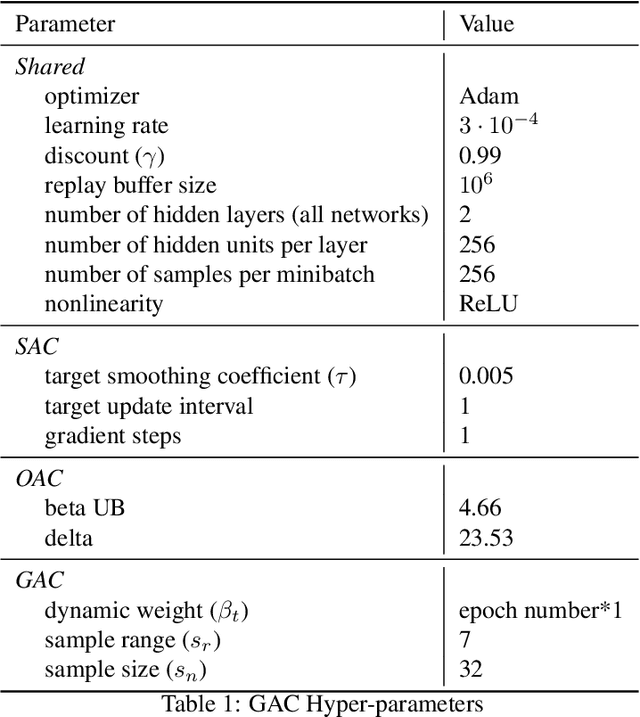
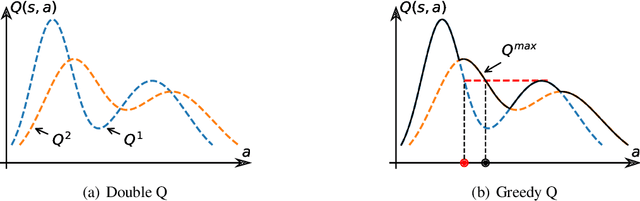
Exploration strategies in continuous action space are often heuristic due to the infinite actions, and these kinds of methods cannot derive a general conclusion. In prior work, it has been shown that policy-based exploration is beneficial for continuous action space in deterministic policy reinforcement learning(DPRL). However, policy-based exploration in DPRL has two prominent issues: aimless exploration and policy divergence, and the policy gradient for exploration is only sometimes helpful due to inaccurate estimation. Based on the double-Q function framework, we introduce a novel exploration strategy to mitigate these issues, separate from the policy gradient. We first propose the greedy Q softmax update schema for Q value update. The expected Q value is derived by weighted summing the conservative Q value over actions, and the weight is the corresponding greedy Q value. Greedy Q takes the maximum value of the two Q functions, and conservative Q takes the minimum value of the two different Q functions. For practicality, this theoretical basis is then extended to allow us to combine action exploration with the Q value update, except for the premise that we have a surrogate policy that behaves like this exploration policy. In practice, we construct such an exploration policy with a few sampled actions, and to meet the premise, we learn such a surrogate policy by minimizing the KL divergence between the target policy and the exploration policy constructed by the conservative Q. We evaluate our method on the Mujoco benchmark and demonstrate superior performance compared to previous state-of-the-art methods across various environments, particularly in the most complex Humanoid environment.
A Simple Unified Uncertainty-Guided Framework for Offline-to-Online Reinforcement Learning
Jun 13, 2023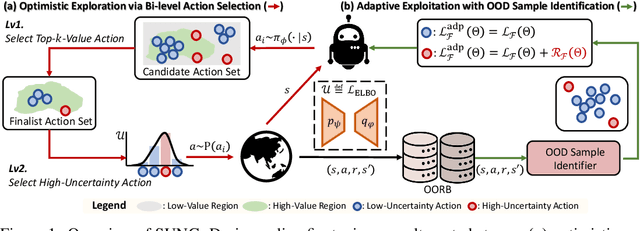
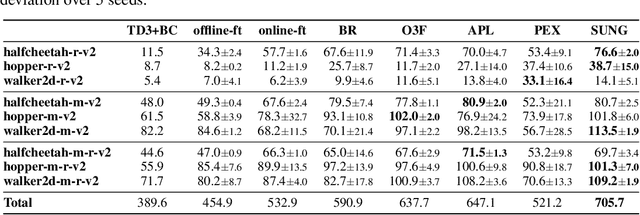
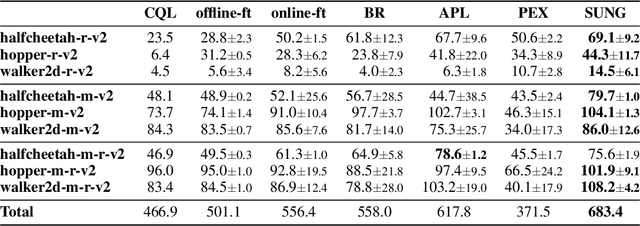
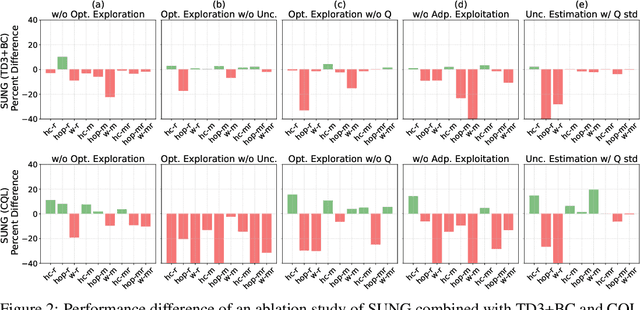
Offline reinforcement learning (RL) provides a promising solution to learning an agent fully relying on a data-driven paradigm. However, constrained by the limited quality of the offline dataset, its performance is often sub-optimal. Therefore, it is desired to further finetune the agent via extra online interactions before deployment. Unfortunately, offline-to-online RL can be challenging due to two main challenges: constrained exploratory behavior and state-action distribution shift. To this end, we propose a Simple Unified uNcertainty-Guided (SUNG) framework, which naturally unifies the solution to both challenges with the tool of uncertainty. Specifically, SUNG quantifies uncertainty via a VAE-based state-action visitation density estimator. To facilitate efficient exploration, SUNG presents a practical optimistic exploration strategy to select informative actions with both high value and high uncertainty. Moreover, SUNG develops an adaptive exploitation method by applying conservative offline RL objectives to high-uncertainty samples and standard online RL objectives to low-uncertainty samples to smoothly bridge offline and online stages. SUNG achieves state-of-the-art online finetuning performance when combined with different offline RL methods, across various environments and datasets in D4RL benchmark.
Instructed Diffuser with Temporal Condition Guidance for Offline Reinforcement Learning
Jun 08, 2023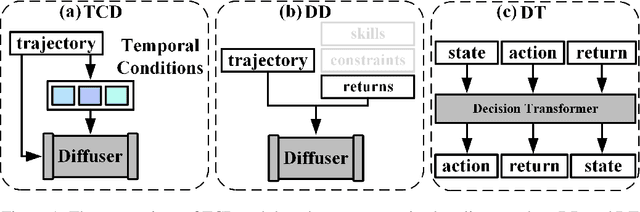
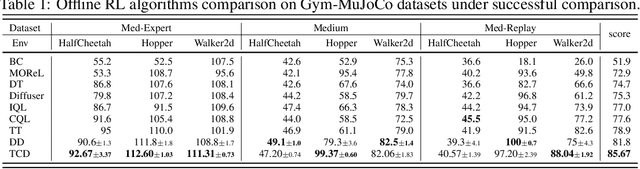
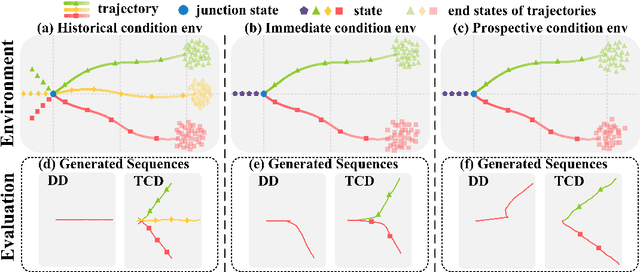
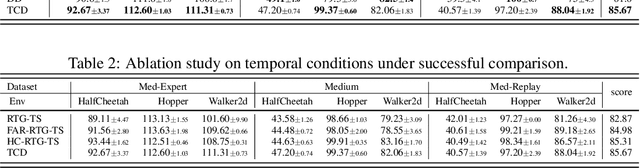
Recent works have shown the potential of diffusion models in computer vision and natural language processing. Apart from the classical supervised learning fields, diffusion models have also shown strong competitiveness in reinforcement learning (RL) by formulating decision-making as sequential generation. However, incorporating temporal information of sequential data and utilizing it to guide diffusion models to perform better generation is still an open challenge. In this paper, we take one step forward to investigate controllable generation with temporal conditions that are refined from temporal information. We observe the importance of temporal conditions in sequential generation in sufficient explorative scenarios and provide a comprehensive discussion and comparison of different temporal conditions. Based on the observations, we propose an effective temporally-conditional diffusion model coined Temporally-Composable Diffuser (TCD), which extracts temporal information from interaction sequences and explicitly guides generation with temporal conditions. Specifically, we separate the sequences into three parts according to time expansion and identify historical, immediate, and prospective conditions accordingly. Each condition preserves non-overlapping temporal information of sequences, enabling more controllable generation when we jointly use them to guide the diffuser. Finally, we conduct extensive experiments and analysis to reveal the favorable applicability of TCD in offline RL tasks, where our method reaches or matches the best performance compared with prior SOTA baselines.
Multi-Modality Multi-Scale Cardiovascular Disease Subtypes Classification Using Raman Image and Medical History
Apr 18, 2023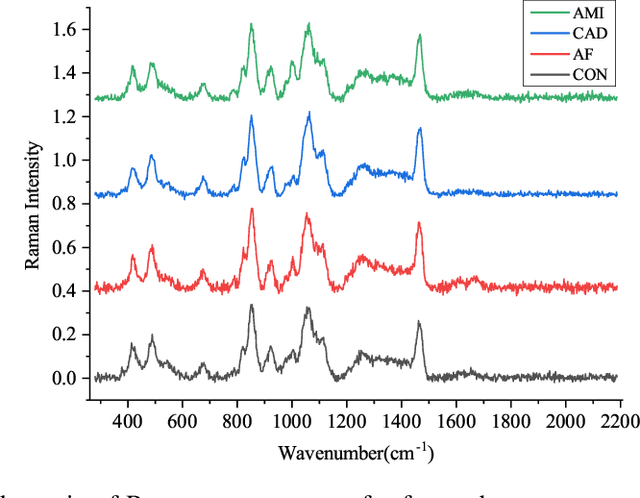

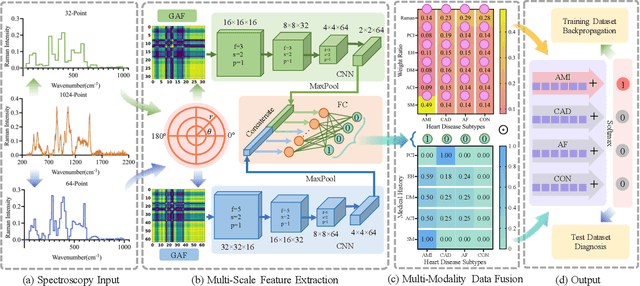
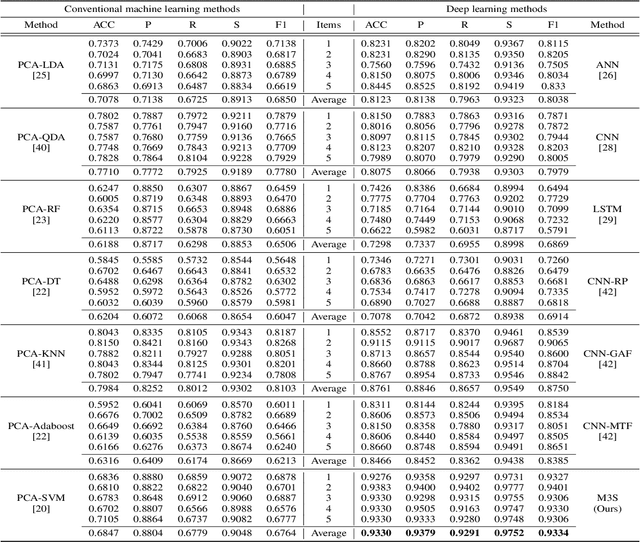
Raman spectroscopy (RS) has been widely used for disease diagnosis, e.g., cardiovascular disease (CVD), owing to its efficiency and component-specific testing capabilities. A series of popular deep learning methods have recently been introduced to learn nuance features from RS for binary classifications and achieved outstanding performance than conventional machine learning methods. However, these existing deep learning methods still confront some challenges in classifying subtypes of CVD. For example, the nuance between subtypes is quite hard to capture and represent by intelligent models due to the chillingly similar shape of RS sequences. Moreover, medical history information is an essential resource for distinguishing subtypes, but they are underutilized. In light of this, we propose a multi-modality multi-scale model called M3S, which is a novel deep learning method with two core modules to address these issues. First, we convert RS data to various resolution images by the Gramian angular field (GAF) to enlarge nuance, and a two-branch structure is leveraged to get embeddings for distinction in the multi-scale feature extraction module. Second, a probability matrix and a weight matrix are used to enhance the classification capacity by combining the RS and medical history data in the multi-modality data fusion module. We perform extensive evaluations of M3S and found its outstanding performance on our in-house dataset, with accuracy, precision, recall, specificity, and F1 score of 0.9330, 0.9379, 0.9291, 0.9752, and 0.9334, respectively. These results demonstrate that the M3S has high performance and robustness compared with popular methods in diagnosing CVD subtypes.
Data and Knowledge Co-driving for Cancer Subtype Classification on Multi-Scale Histopathological Slides
Apr 18, 2023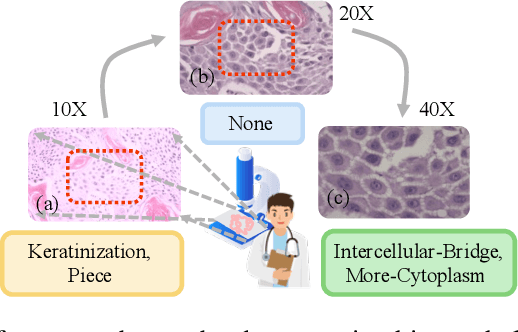
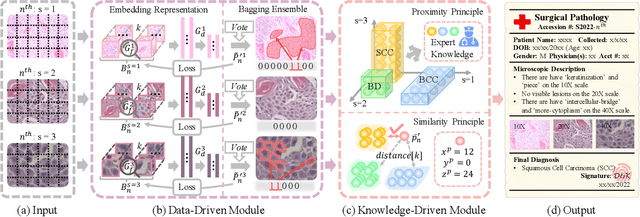
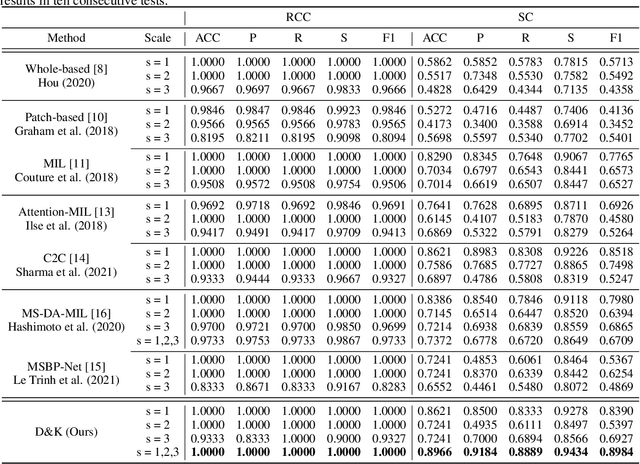
Artificial intelligence-enabled histopathological data analysis has become a valuable assistant to the pathologist. However, existing models lack representation and inference abilities compared with those of pathologists, especially in cancer subtype diagnosis, which is unconvincing in clinical practice. For instance, pathologists typically observe the lesions of a slide from global to local, and then can give a diagnosis based on their knowledge and experience. In this paper, we propose a Data and Knowledge Co-driving (D&K) model to replicate the process of cancer subtype classification on a histopathological slide like a pathologist. Specifically, in the data-driven module, the bagging mechanism in ensemble learning is leveraged to integrate the histological features from various bags extracted by the embedding representation unit. Furthermore, a knowledge-driven module is established based on the Gestalt principle in psychology to build the three-dimensional (3D) expert knowledge space and map histological features into this space for metric. Then, the diagnosis can be made according to the Euclidean distance between them. Extensive experimental results on both public and in-house datasets demonstrate that the D&K model has a high performance and credible results compared with the state-of-the-art methods for diagnosing histopathological subtypes. Code: https://github.com/Dennis-YB/Data-and-Knowledge-Co-driving-for-Cancer-Subtypes-Classification
Policy Dispersion in Non-Markovian Environment
Feb 28, 2023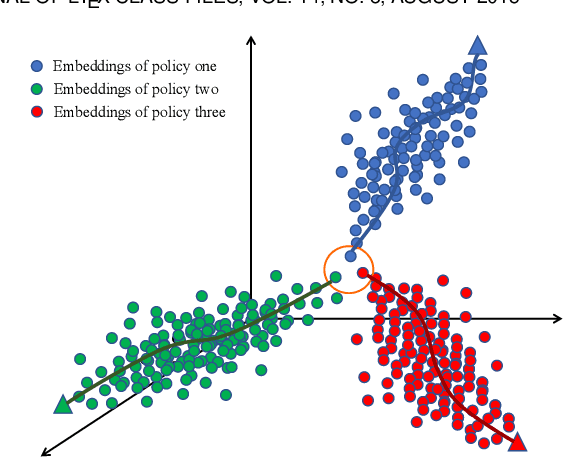

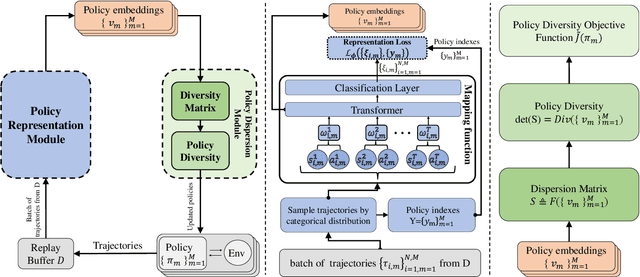

Markov Decision Process (MDP) presents a mathematical framework to formulate the learning processes of agents in reinforcement learning. MDP is limited by the Markovian assumption that a reward only depends on the immediate state and action. However, a reward sometimes depends on the history of states and actions, which may result in the decision process in a non-Markovian environment. In such environments, agents receive rewards via temporally-extended behaviors sparsely, and the learned policies may be similar. This leads the agents acquired with similar policies generally overfit to the given task and can not quickly adapt to perturbations of environments. To resolve this problem, this paper tries to learn the diverse policies from the history of state-action pairs under a non-Markovian environment, in which a policy dispersion scheme is designed for seeking diverse policy representation. Specifically, we first adopt a transformer-based method to learn policy embeddings. Then, we stack the policy embeddings to construct a dispersion matrix to induce a set of diverse policies. Finally, we prove that if the dispersion matrix is positive definite, the dispersed embeddings can effectively enlarge the disagreements across policies, yielding a diverse expression for the original policy embedding distribution. Experimental results show that this dispersion scheme can obtain more expressive diverse policies, which then derive more robust performance than recent learning baselines under various learning environments.
Distributional Reward Estimation for Effective Multi-Agent Deep Reinforcement Learning
Oct 14, 2022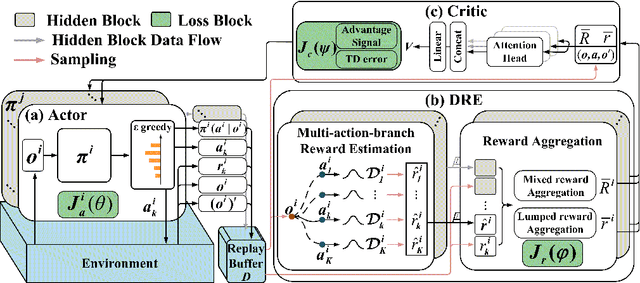
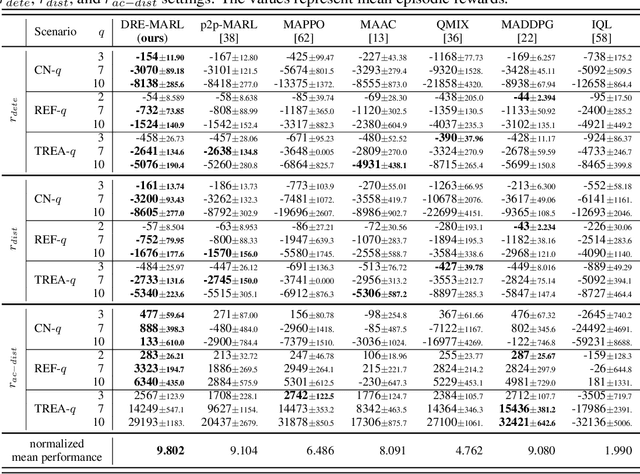

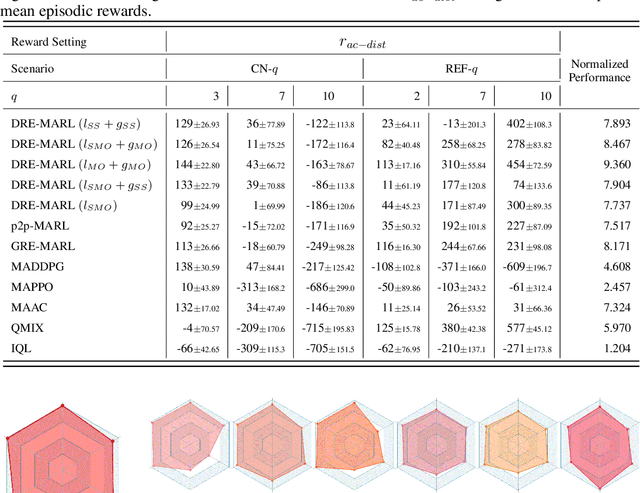
Multi-agent reinforcement learning has drawn increasing attention in practice, e.g., robotics and automatic driving, as it can explore optimal policies using samples generated by interacting with the environment. However, high reward uncertainty still remains a problem when we want to train a satisfactory model, because obtaining high-quality reward feedback is usually expensive and even infeasible. To handle this issue, previous methods mainly focus on passive reward correction. At the same time, recent active reward estimation methods have proven to be a recipe for reducing the effect of reward uncertainty. In this paper, we propose a novel Distributional Reward Estimation framework for effective Multi-Agent Reinforcement Learning (DRE-MARL). Our main idea is to design the multi-action-branch reward estimation and policy-weighted reward aggregation for stabilized training. Specifically, we design the multi-action-branch reward estimation to model reward distributions on all action branches. Then we utilize reward aggregation to obtain stable updating signals during training. Our intuition is that consideration of all possible consequences of actions could be useful for learning policies. The superiority of the DRE-MARL is demonstrated using benchmark multi-agent scenarios, compared with the SOTA baselines in terms of both effectiveness and robustness.