 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChengyou Jia
Noisy Correspondence Learning with Self-Reinforcing Errors Mitigation
Dec 27, 2023
Cross-modal retrieval relies on well-matched large-scale datasets that are laborious in practice. Recently, to alleviate expensive data collection, co-occurring pairs from the Internet are automatically harvested for training. However, it inevitably includes mismatched pairs, \ie, noisy correspondences, undermining supervision reliability and degrading performance. Current methods leverage deep neural networks' memorization effect to address noisy correspondences, which overconfidently focus on \emph{similarity-guided training with hard negatives} and suffer from self-reinforcing errors. In light of above, we introduce a novel noisy correspondence learning framework, namely \textbf{S}elf-\textbf{R}einforcing \textbf{E}rrors \textbf{M}itigation (SREM). Specifically, by viewing sample matching as classification tasks within the batch, we generate classification logits for the given sample. Instead of a single similarity score, we refine sample filtration through energy uncertainty and estimate model's sensitivity of selected clean samples using swapped classification entropy, in view of the overall prediction distribution. Additionally, we propose cross-modal biased complementary learning to leverage negative matches overlooked in hard-negative training, further improving model optimization stability and curbing self-reinforcing errors. Extensive experiments on challenging benchmarks affirm the efficacy and efficiency of SREM.
Generating Action-conditioned Prompts for Open-vocabulary Video Action Recognition
Dec 04, 2023Exploring open-vocabulary video action recognition is a promising venture, which aims to recognize previously unseen actions within any arbitrary set of categories. Existing methods typically adapt pretrained image-text models to the video domain, capitalizing on their inherent strengths in generalization. A common thread among such methods is the augmentation of visual embeddings with temporal information to improve the recognition of seen actions. Yet, they compromise with standard less-informative action descriptions, thus faltering when confronted with novel actions. Drawing inspiration from human cognitive processes, we argue that augmenting text embeddings with human prior knowledge is pivotal for open-vocabulary video action recognition. To realize this, we innovatively blend video models with Large Language Models (LLMs) to devise Action-conditioned Prompts. Specifically, we harness the knowledge in LLMs to produce a set of descriptive sentences that contain distinctive features for identifying given actions. Building upon this foundation, we further introduce a multi-modal action knowledge alignment mechanism to align concepts in video and textual knowledge encapsulated within the prompts. Extensive experiments on various video benchmarks, including zero-shot, few-shot, and base-to-novel generalization settings, demonstrate that our method not only sets new SOTA performance but also possesses excellent interpretability.
Disentangled Representation Learning with Transmitted Information Bottleneck
Nov 03, 2023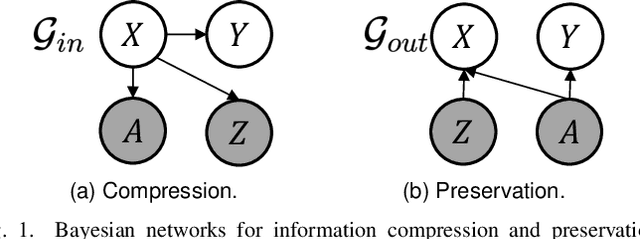
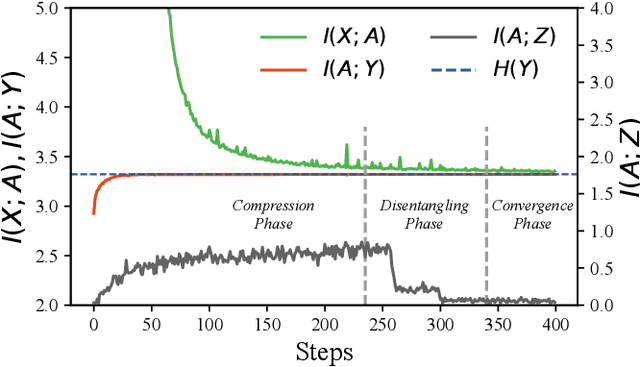

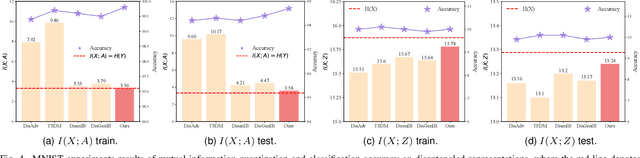
Encoding only the task-related information from the raw data, \ie, disentangled representation learning, can greatly contribute to the robustness and generalizability of models. Although significant advances have been made by regularizing the information in representations with information theory, two major challenges remain: 1) the representation compression inevitably leads to performance drop; 2) the disentanglement constraints on representations are in complicated optimization. To these issues, we introduce Bayesian networks with transmitted information to formulate the interaction among input and representations during disentanglement. Building upon this framework, we propose \textbf{DisTIB} (\textbf{T}ransmitted \textbf{I}nformation \textbf{B}ottleneck for \textbf{Dis}entangled representation learning), a novel objective that navigates the balance between information compression and preservation. We employ variational inference to derive a tractable estimation for DisTIB. This estimation can be simply optimized via standard gradient descent with a reparameterization trick. Moreover, we theoretically prove that DisTIB can achieve optimal disentanglement, underscoring its superior efficacy. To solidify our claims, we conduct extensive experiments on various downstream tasks to demonstrate the appealing efficacy of DisTIB and validate our theoretical analyses.
PSDiff: Diffusion Model for Person Search with Iterative and Collaborative Refinement
Sep 20, 2023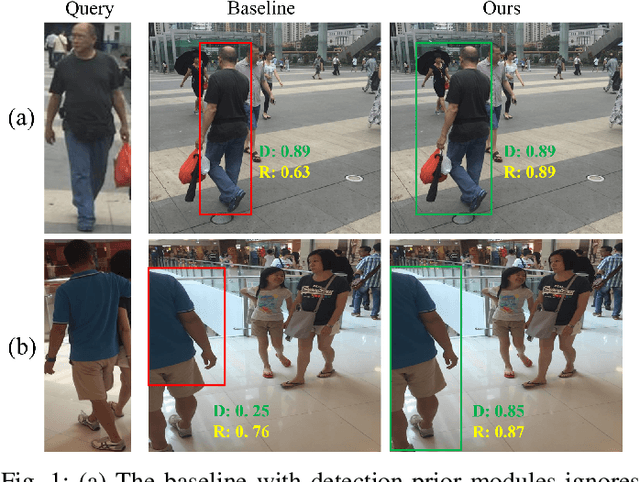
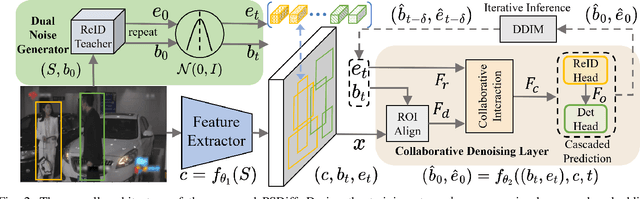
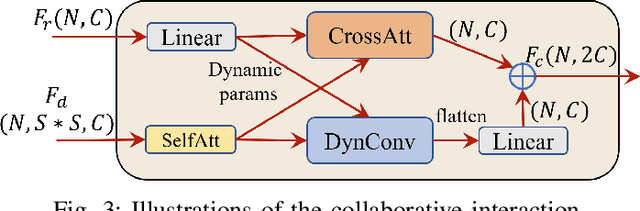
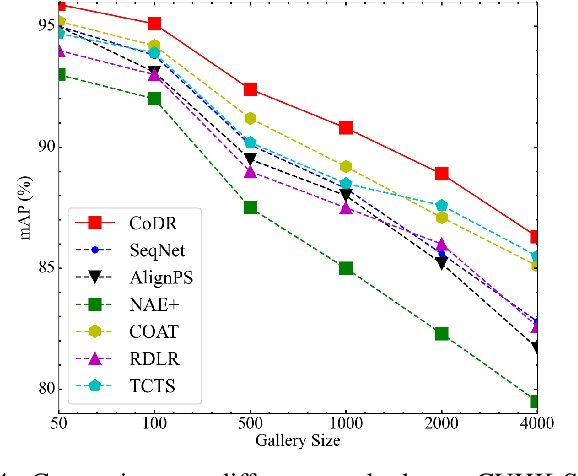
Dominant Person Search methods aim to localize and recognize query persons in a unified network, which jointly optimizes two sub-tasks, \ie, detection and Re-IDentification (ReID). Despite significant progress, two major challenges remain: 1) Detection-prior modules in previous methods are suboptimal for the ReID task. 2) The collaboration between two sub-tasks is ignored. To alleviate these issues, we present a novel Person Search framework based on the Diffusion model, PSDiff. PSDiff formulates the person search as a dual denoising process from noisy boxes and ReID embeddings to ground truths. Unlike existing methods that follow the Detection-to-ReID paradigm, our denoising paradigm eliminates detection-prior modules to avoid the local-optimum of the ReID task. Following the new paradigm, we further design a new Collaborative Denoising Layer (CDL) to optimize detection and ReID sub-tasks in an iterative and collaborative way, which makes two sub-tasks mutually beneficial. Extensive experiments on the standard benchmarks show that PSDiff achieves state-of-the-art performance with fewer parameters and elastic computing overhead.
SSMG: Spatial-Semantic Map Guided Diffusion Model for Free-form Layout-to-Image Generation
Aug 20, 2023
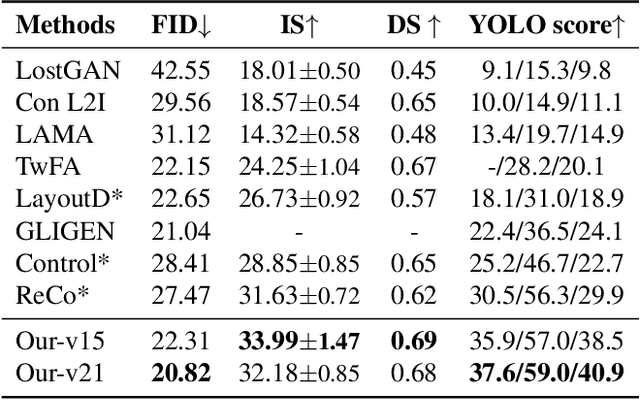
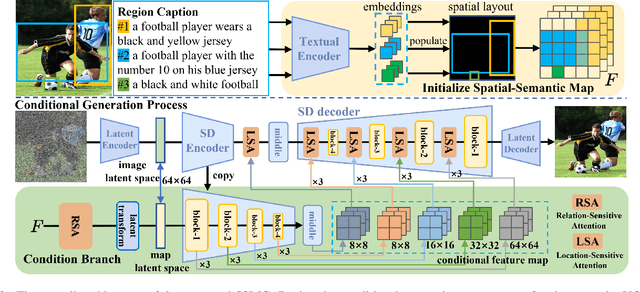
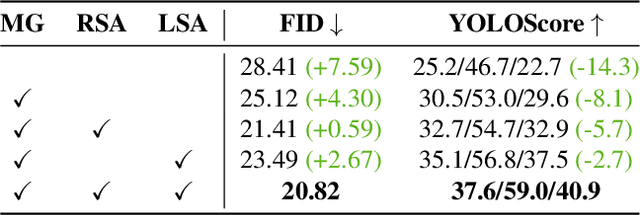
Despite significant progress in Text-to-Image (T2I) generative models, even lengthy and complex text descriptions still struggle to convey detailed controls. In contrast, Layout-to-Image (L2I) generation, aiming to generate realistic and complex scene images from user-specified layouts, has risen to prominence. However, existing methods transform layout information into tokens or RGB images for conditional control in the generative process, leading to insufficient spatial and semantic controllability of individual instances. To address these limitations, we propose a novel Spatial-Semantic Map Guided (SSMG) diffusion model that adopts the feature map, derived from the layout, as guidance. Owing to rich spatial and semantic information encapsulated in well-designed feature maps, SSMG achieves superior generation quality with sufficient spatial and semantic controllability compared to previous works. Additionally, we propose the Relation-Sensitive Attention (RSA) and Location-Sensitive Attention (LSA) mechanisms. The former aims to model the relationships among multiple objects within scenes while the latter is designed to heighten the model's sensitivity to the spatial information embedded in the guidance. Extensive experiments demonstrate that SSMG achieves highly promising results, setting a new state-of-the-art across a range of metrics encompassing fidelity, diversity, and controllability.
Multi-Modality Multi-Scale Cardiovascular Disease Subtypes Classification Using Raman Image and Medical History
Apr 18, 2023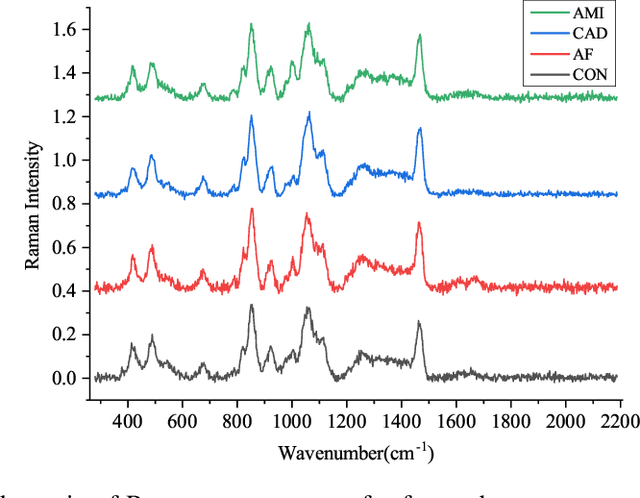

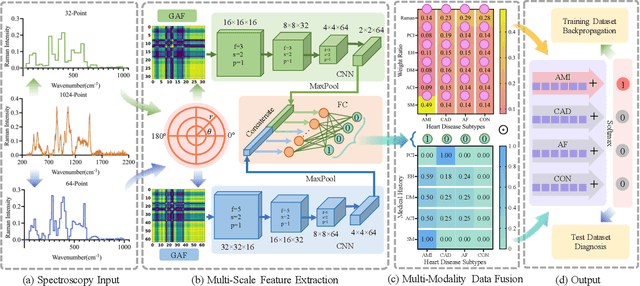
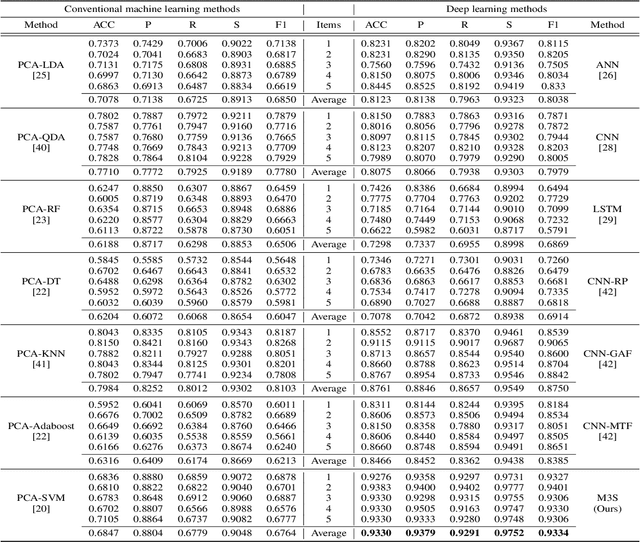
Raman spectroscopy (RS) has been widely used for disease diagnosis, e.g., cardiovascular disease (CVD), owing to its efficiency and component-specific testing capabilities. A series of popular deep learning methods have recently been introduced to learn nuance features from RS for binary classifications and achieved outstanding performance than conventional machine learning methods. However, these existing deep learning methods still confront some challenges in classifying subtypes of CVD. For example, the nuance between subtypes is quite hard to capture and represent by intelligent models due to the chillingly similar shape of RS sequences. Moreover, medical history information is an essential resource for distinguishing subtypes, but they are underutilized. In light of this, we propose a multi-modality multi-scale model called M3S, which is a novel deep learning method with two core modules to address these issues. First, we convert RS data to various resolution images by the Gramian angular field (GAF) to enlarge nuance, and a two-branch structure is leveraged to get embeddings for distinction in the multi-scale feature extraction module. Second, a probability matrix and a weight matrix are used to enhance the classification capacity by combining the RS and medical history data in the multi-modality data fusion module. We perform extensive evaluations of M3S and found its outstanding performance on our in-house dataset, with accuracy, precision, recall, specificity, and F1 score of 0.9330, 0.9379, 0.9291, 0.9752, and 0.9334, respectively. These results demonstrate that the M3S has high performance and robustness compared with popular methods in diagnosing CVD subtypes.
Disentangled Generation with Information Bottleneck for Few-Shot Learning
Nov 29, 2022



Few-shot learning (FSL), which aims to classify unseen classes with few samples, is challenging due to data scarcity. Although various generative methods have been explored for FSL, the entangled generation process of these methods exacerbates the distribution shift in FSL, thus greatly limiting the quality of generated samples. To these challenges, we propose a novel Information Bottleneck (IB) based Disentangled Generation Framework for FSL, termed as DisGenIB, that can simultaneously guarantee the discrimination and diversity of generated samples. Specifically, we formulate a novel framework with information bottleneck that applies for both disentangled representation learning and sample generation. Different from existing IB-based methods that can hardly exploit priors, we demonstrate our DisGenIB can effectively utilize priors to further facilitate disentanglement. We further prove in theory that some previous generative and disentanglement methods are special cases of our DisGenIB, which demonstrates the generality of the proposed DisGenIB. Extensive experiments on challenging FSL benchmarks confirm the effectiveness and superiority of DisGenIB, together with the validity of our theoretical analyses. Our codes will be open-source upon acceptance.
CGUA: Context-Guided and Unpaired-Assisted Weakly Supervised Person Search
Mar 27, 2022



Recently, weakly supervised person search is proposed to discard human-annotated identities and train the model with only bounding box annotations. A natural way to solve this problem is to separate it into detection and unsupervised re-identification (Re-ID) steps. However, in this way, two important clues in unconstrained scene images are ignored. On the one hand, existing unsupervised Re-ID models only leverage cropped images from scene images but ignore its rich context information. On the other hand, there are numerous unpaired persons in real-world scene images. Directly dealing with them as independent identities leads to the long-tail effect, while completely discarding them can result in serious information loss. In light of these challenges, we introduce a Context-Guided and Unpaired-Assisted (CGUA) weakly supervised person search framework. Specifically, we propose a novel Context-Guided Cluster (CGC) algorithm to leverage context information in the clustering process and an Unpaired-Assisted Memory (UAM) unit to distinguish unpaired and paired persons by pushing them away. Extensive experiments demonstrate that the proposed approach can surpass the state-of-the-art weakly supervised methods by a large margin (more than 5% mAP on CUHK-SYSU). Moreover, our method achieves comparable or better performance to the state-of-the-art supervised methods by leveraging more diverse unlabeled data. Codes and models will be released soon.