 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGuang Dai
TryOn-Adapter: Efficient Fine-Grained Clothing Identity Adaptation for High-Fidelity Virtual Try-On
Apr 01, 2024
Virtual try-on focuses on adjusting the given clothes to fit a specific person seamlessly while avoiding any distortion of the patterns and textures of the garment. However, the clothing identity uncontrollability and training inefficiency of existing diffusion-based methods, which struggle to maintain the identity even with full parameter training, are significant limitations that hinder the widespread applications. In this work, we propose an effective and efficient framework, termed TryOn-Adapter. Specifically, we first decouple clothing identity into fine-grained factors: style for color and category information, texture for high-frequency details, and structure for smooth spatial adaptive transformation. Our approach utilizes a pre-trained exemplar-based diffusion model as the fundamental network, whose parameters are frozen except for the attention layers. We then customize three lightweight modules (Style Preserving, Texture Highlighting, and Structure Adapting) incorporated with fine-tuning techniques to enable precise and efficient identity control. Meanwhile, we introduce the training-free T-RePaint strategy to further enhance clothing identity preservation while maintaining the realistic try-on effect during the inference. Our experiments demonstrate that our approach achieves state-of-the-art performance on two widely-used benchmarks. Additionally, compared with recent full-tuning diffusion-based methods, we only use about half of their tunable parameters during training. The code will be made publicly available at https://github.com/jiazheng-xing/TryOn-Adapter.
DreamSalon: A Staged Diffusion Framework for Preserving Identity-Context in Editable Face Generation
Mar 28, 2024While large-scale pre-trained text-to-image models can synthesize diverse and high-quality human-centered images, novel challenges arise with a nuanced task of "identity fine editing": precisely modifying specific features of a subject while maintaining its inherent identity and context. Existing personalization methods either require time-consuming optimization or learning additional encoders, adept in "identity re-contextualization". However, they often struggle with detailed and sensitive tasks like human face editing. To address these challenges, we introduce DreamSalon, a noise-guided, staged-editing framework, uniquely focusing on detailed image manipulations and identity-context preservation. By discerning editing and boosting stages via the frequency and gradient of predicted noises, DreamSalon first performs detailed manipulations on specific features in the editing stage, guided by high-frequency information, and then employs stochastic denoising in the boosting stage to improve image quality. For more precise editing, DreamSalon semantically mixes source and target textual prompts, guided by differences in their embedding covariances, to direct the model's focus on specific manipulation areas. Our experiments demonstrate DreamSalon's ability to efficiently and faithfully edit fine details on human faces, outperforming existing methods both qualitatively and quantitatively.
Learning to Rematch Mismatched Pairs for Robust Cross-Modal Retrieval
Mar 08, 2024
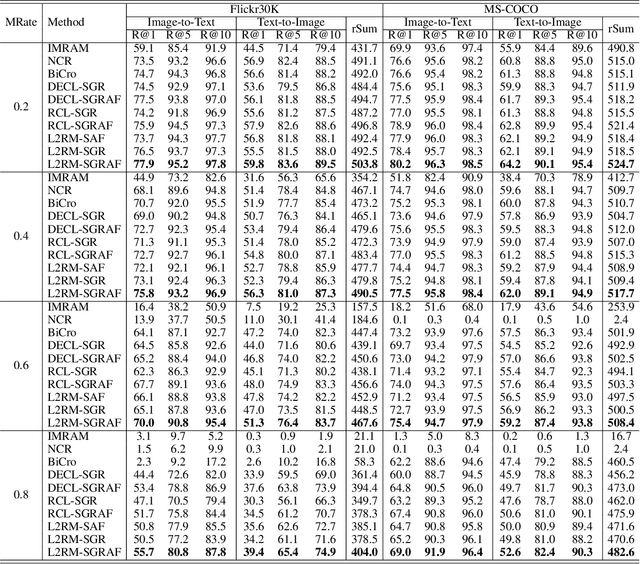
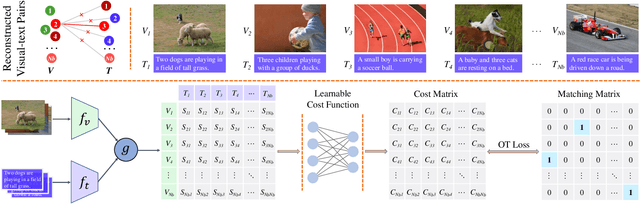
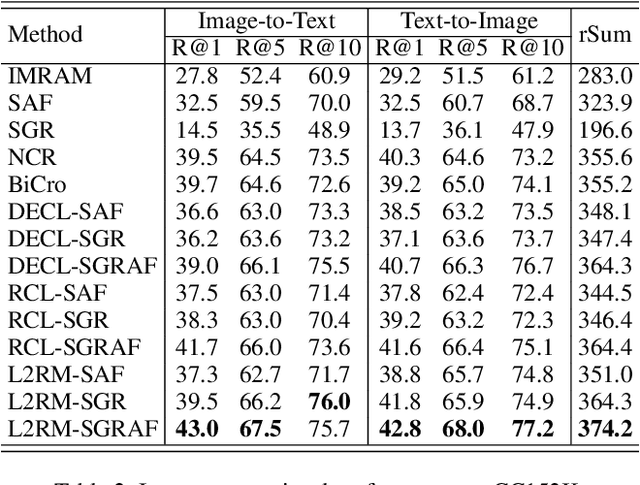
Collecting well-matched multimedia datasets is crucial for training cross-modal retrieval models. However, in real-world scenarios, massive multimodal data are harvested from the Internet, which inevitably contains Partially Mismatched Pairs (PMPs). Undoubtedly, such semantical irrelevant data will remarkably harm the cross-modal retrieval performance. Previous efforts tend to mitigate this problem by estimating a soft correspondence to down-weight the contribution of PMPs. In this paper, we aim to address this challenge from a new perspective: the potential semantic similarity among unpaired samples makes it possible to excavate useful knowledge from mismatched pairs. To achieve this, we propose L2RM, a general framework based on Optimal Transport (OT) that learns to rematch mismatched pairs. In detail, L2RM aims to generate refined alignments by seeking a minimal-cost transport plan across different modalities. To formalize the rematching idea in OT, first, we propose a self-supervised cost function that automatically learns from explicit similarity-cost mapping relation. Second, we present to model a partial OT problem while restricting the transport among false positives to further boost refined alignments. Extensive experiments on three benchmarks demonstrate our L2RM significantly improves the robustness against PMPs for existing models. The code is available at https://github.com/hhc1997/L2RM.
Second-Order Fine-Tuning without Pain for LLMs:A Hessian Informed Zeroth-Order Optimizer
Feb 23, 2024Fine-tuning large language models (LLMs) with classic first-order optimizers entails prohibitive GPU memory due to the backpropagation process. Recent works have turned to zeroth-order optimizers for fine-tuning, which save substantial memory by using two forward passes. However, these optimizers are plagued by the heterogeneity of parameter curvatures across different dimensions. In this work, we propose HiZOO, a diagonal Hessian informed zeroth-order optimizer which is the first work to leverage the diagonal Hessian to enhance zeroth-order optimizer for fine-tuning LLMs. What's more, HiZOO avoids the expensive memory cost and only increases one forward pass per step. Extensive experiments on various models (350M~66B parameters) indicate that HiZOO improves model convergence, significantly reducing training steps and effectively enhancing model accuracy. Moreover, we visualize the optimization trajectories of HiZOO on test functions, illustrating its effectiveness in handling heterogeneous curvatures. Lastly, we provide theoretical proofs of convergence for HiZOO. Code is publicly available at https://anonymous.4open.science/r/HiZOO27F8.
M2-CLIP: A Multimodal, Multi-task Adapting Framework for Video Action Recognition
Jan 22, 2024Recently, the rise of large-scale vision-language pretrained models like CLIP, coupled with the technology of Parameter-Efficient FineTuning (PEFT), has captured substantial attraction in video action recognition. Nevertheless, prevailing approaches tend to prioritize strong supervised performance at the expense of compromising the models' generalization capabilities during transfer. In this paper, we introduce a novel Multimodal, Multi-task CLIP adapting framework named \name to address these challenges, preserving both high supervised performance and robust transferability. Firstly, to enhance the individual modality architectures, we introduce multimodal adapters to both the visual and text branches. Specifically, we design a novel visual TED-Adapter, that performs global Temporal Enhancement and local temporal Difference modeling to improve the temporal representation capabilities of the visual encoder. Moreover, we adopt text encoder adapters to strengthen the learning of semantic label information. Secondly, we design a multi-task decoder with a rich set of supervisory signals to adeptly satisfy the need for strong supervised performance and generalization within a multimodal framework. Experimental results validate the efficacy of our approach, demonstrating exceptional performance in supervised learning while maintaining strong generalization in zero-shot scenarios.
Noisy Correspondence Learning with Self-Reinforcing Errors Mitigation
Dec 27, 2023Cross-modal retrieval relies on well-matched large-scale datasets that are laborious in practice. Recently, to alleviate expensive data collection, co-occurring pairs from the Internet are automatically harvested for training. However, it inevitably includes mismatched pairs, \ie, noisy correspondences, undermining supervision reliability and degrading performance. Current methods leverage deep neural networks' memorization effect to address noisy correspondences, which overconfidently focus on \emph{similarity-guided training with hard negatives} and suffer from self-reinforcing errors. In light of above, we introduce a novel noisy correspondence learning framework, namely \textbf{S}elf-\textbf{R}einforcing \textbf{E}rrors \textbf{M}itigation (SREM). Specifically, by viewing sample matching as classification tasks within the batch, we generate classification logits for the given sample. Instead of a single similarity score, we refine sample filtration through energy uncertainty and estimate model's sensitivity of selected clean samples using swapped classification entropy, in view of the overall prediction distribution. Additionally, we propose cross-modal biased complementary learning to leverage negative matches overlooked in hard-negative training, further improving model optimization stability and curbing self-reinforcing errors. Extensive experiments on challenging benchmarks affirm the efficacy and efficiency of SREM.
Generating Action-conditioned Prompts for Open-vocabulary Video Action Recognition
Dec 04, 2023Exploring open-vocabulary video action recognition is a promising venture, which aims to recognize previously unseen actions within any arbitrary set of categories. Existing methods typically adapt pretrained image-text models to the video domain, capitalizing on their inherent strengths in generalization. A common thread among such methods is the augmentation of visual embeddings with temporal information to improve the recognition of seen actions. Yet, they compromise with standard less-informative action descriptions, thus faltering when confronted with novel actions. Drawing inspiration from human cognitive processes, we argue that augmenting text embeddings with human prior knowledge is pivotal for open-vocabulary video action recognition. To realize this, we innovatively blend video models with Large Language Models (LLMs) to devise Action-conditioned Prompts. Specifically, we harness the knowledge in LLMs to produce a set of descriptive sentences that contain distinctive features for identifying given actions. Building upon this foundation, we further introduce a multi-modal action knowledge alignment mechanism to align concepts in video and textual knowledge encapsulated within the prompts. Extensive experiments on various video benchmarks, including zero-shot, few-shot, and base-to-novel generalization settings, demonstrate that our method not only sets new SOTA performance but also possesses excellent interpretability.
Disentangled Representation Learning with Transmitted Information Bottleneck
Nov 03, 2023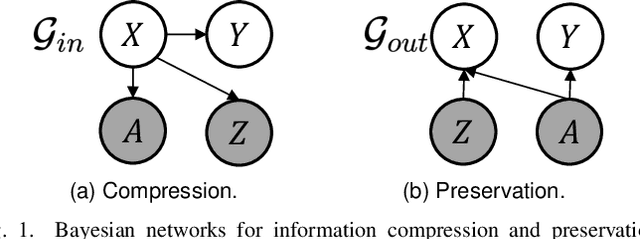
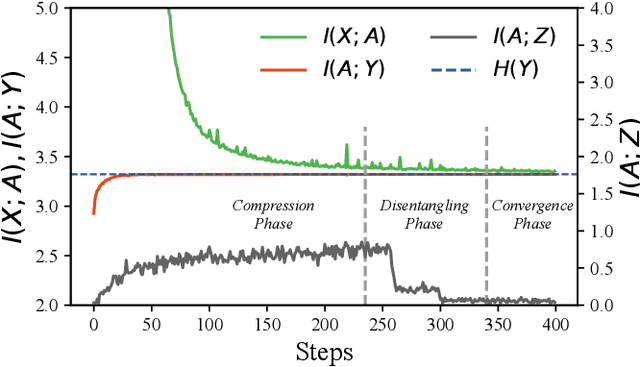

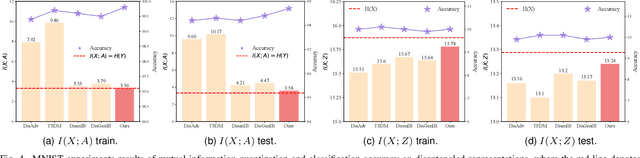
Encoding only the task-related information from the raw data, \ie, disentangled representation learning, can greatly contribute to the robustness and generalizability of models. Although significant advances have been made by regularizing the information in representations with information theory, two major challenges remain: 1) the representation compression inevitably leads to performance drop; 2) the disentanglement constraints on representations are in complicated optimization. To these issues, we introduce Bayesian networks with transmitted information to formulate the interaction among input and representations during disentanglement. Building upon this framework, we propose \textbf{DisTIB} (\textbf{T}ransmitted \textbf{I}nformation \textbf{B}ottleneck for \textbf{Dis}entangled representation learning), a novel objective that navigates the balance between information compression and preservation. We employ variational inference to derive a tractable estimation for DisTIB. This estimation can be simply optimized via standard gradient descent with a reparameterization trick. Moreover, we theoretically prove that DisTIB can achieve optimal disentanglement, underscoring its superior efficacy. To solidify our claims, we conduct extensive experiments on various downstream tasks to demonstrate the appealing efficacy of DisTIB and validate our theoretical analyses.
SUBP: Soft Uniform Block Pruning for 1xN Sparse CNNs Multithreading Acceleration
Oct 10, 2023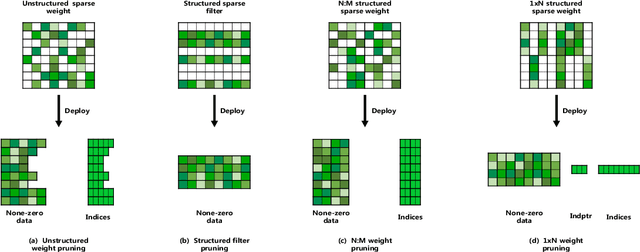
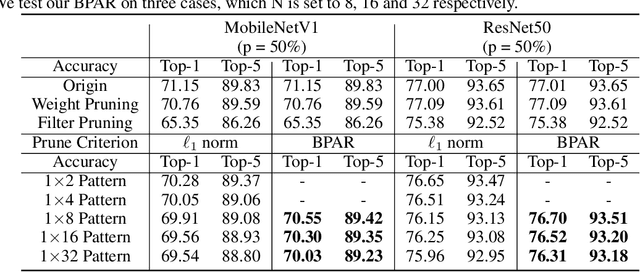
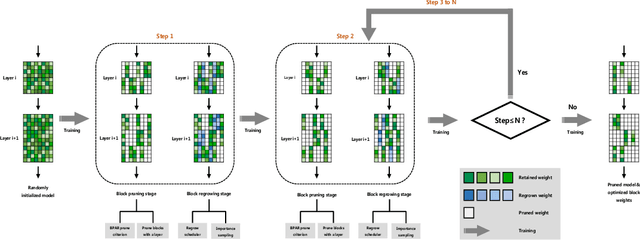
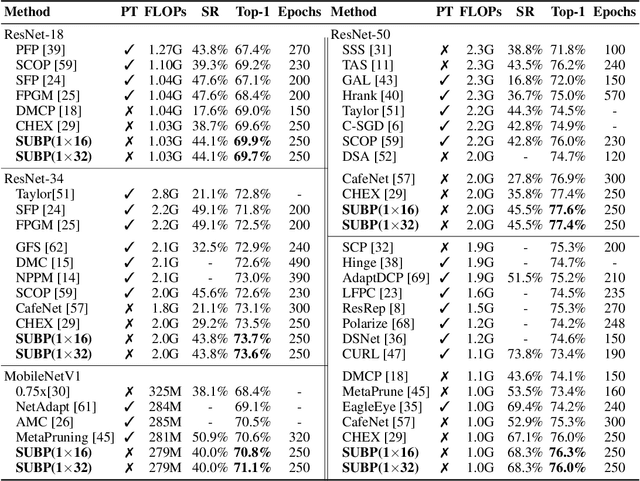
The study of sparsity in Convolutional Neural Networks (CNNs) has become widespread to compress and accelerate models in environments with limited resources. By constraining N consecutive weights along the output channel to be group-wise non-zero, the recent network with 1$\times$N sparsity has received tremendous popularity for its three outstanding advantages: 1) A large amount of storage space saving by a \emph{Block Sparse Row} matrix. 2) Excellent performance at a high sparsity. 3) Significant speedups on CPUs with Advanced Vector Extensions. Recent work requires selecting and fine-tuning 1$\times$N sparse weights based on dense pre-trained weights, leading to the problems such as expensive training cost and memory access, sub-optimal model quality, as well as unbalanced workload across threads (different sparsity across output channels). To overcome them, this paper proposes a novel \emph{\textbf{S}oft \textbf{U}niform \textbf{B}lock \textbf{P}runing} (SUBP) approach to train a uniform 1$\times$N sparse structured network from scratch. Specifically, our approach tends to repeatedly allow pruned blocks to regrow to the network based on block angular redundancy and importance sampling in a uniform manner throughout the training process. It not only makes the model less dependent on pre-training, reduces the model redundancy and the risk of pruning the important blocks permanently but also achieves balanced workload. Empirically, on ImageNet, comprehensive experiments across various CNN architectures show that our SUBP consistently outperforms existing 1$\times$N and structured sparsity methods based on pre-trained models or training from scratch. Source codes and models are available at \url{https://github.com/JingyangXiang/SUBP}.
PSDiff: Diffusion Model for Person Search with Iterative and Collaborative Refinement
Sep 20, 2023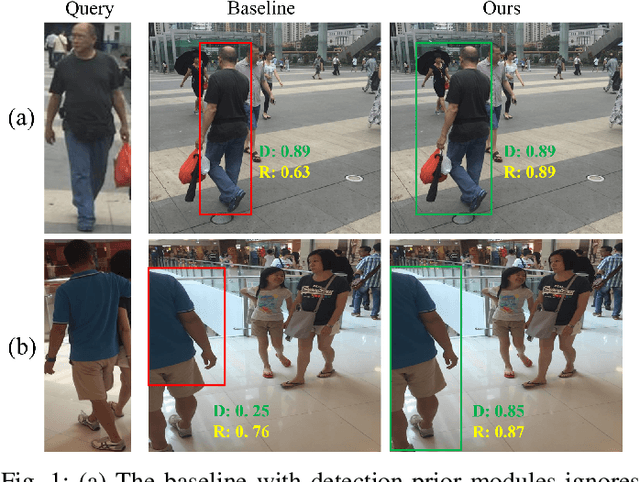
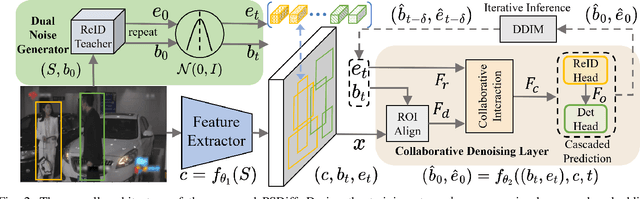
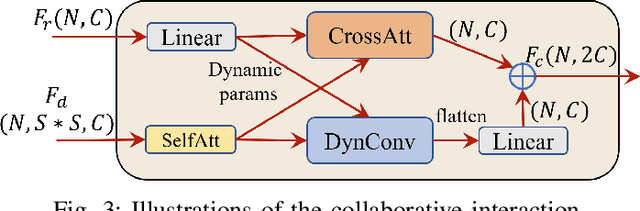
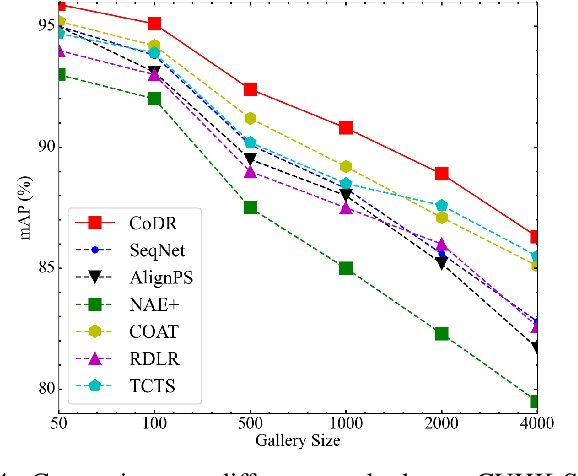
Dominant Person Search methods aim to localize and recognize query persons in a unified network, which jointly optimizes two sub-tasks, \ie, detection and Re-IDentification (ReID). Despite significant progress, two major challenges remain: 1) Detection-prior modules in previous methods are suboptimal for the ReID task. 2) The collaboration between two sub-tasks is ignored. To alleviate these issues, we present a novel Person Search framework based on the Diffusion model, PSDiff. PSDiff formulates the person search as a dual denoising process from noisy boxes and ReID embeddings to ground truths. Unlike existing methods that follow the Detection-to-ReID paradigm, our denoising paradigm eliminates detection-prior modules to avoid the local-optimum of the ReID task. Following the new paradigm, we further design a new Collaborative Denoising Layer (CDL) to optimize detection and ReID sub-tasks in an iterative and collaborative way, which makes two sub-tasks mutually beneficial. Extensive experiments on the standard benchmarks show that PSDiff achieves state-of-the-art performance with fewer parameters and elastic computing overhead.