 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMingfei Han
LongVLM: Efficient Long Video Understanding via Large Language Models
Apr 10, 2024
Empowered by Large Language Models (LLMs), recent advancements in VideoLLMs have driven progress in various video understanding tasks. These models encode video representations through pooling or query aggregation over a vast number of visual tokens, making computational and memory costs affordable. Despite successfully providing an overall comprehension of video content, existing VideoLLMs still face challenges in achieving detailed understanding in videos due to overlooking local information in long-term videos. To tackle this challenge, we introduce LongVLM, a straightforward yet powerful VideoLLM for long video understanding, building upon the observation that long videos often consist of sequential key events, complex actions, and camera movements. Our approach proposes to decompose long videos into multiple short-term segments and encode local features for each local segment via a hierarchical token merging module. These features are concatenated in temporal order to maintain the storyline across sequential short-term segments. Additionally, we propose to integrate global semantics into each local feature to enhance context understanding. In this way, we encode video representations that incorporate both local and global information, enabling the LLM to generate comprehensive responses for long-term videos. Experimental results on the VideoChatGPT benchmark and zero-shot video question-answering datasets demonstrate the superior capabilities of our model over the previous state-of-the-art methods. Qualitative examples demonstrate that our model produces more precise responses for long videos understanding. Code will be available at https://github.com/ziplab/LongVLM.
Video Recognition in Portrait Mode
Dec 21, 2023The creation of new datasets often presents new challenges for video recognition and can inspire novel ideas while addressing these challenges. While existing datasets mainly comprise landscape mode videos, our paper seeks to introduce portrait mode videos to the research community and highlight the unique challenges associated with this video format. With the growing popularity of smartphones and social media applications, recognizing portrait mode videos is becoming increasingly important. To this end, we have developed the first dataset dedicated to portrait mode video recognition, namely PortraitMode-400. The taxonomy of PortraitMode-400 was constructed in a data-driven manner, comprising 400 fine-grained categories, and rigorous quality assurance was implemented to ensure the accuracy of human annotations. In addition to the new dataset, we conducted a comprehensive analysis of the impact of video format (portrait mode versus landscape mode) on recognition accuracy and spatial bias due to the different formats. Furthermore, we designed extensive experiments to explore key aspects of portrait mode video recognition, including the choice of data augmentation, evaluation procedure, the importance of temporal information, and the role of audio modality. Building on the insights from our experimental results and the introduction of PortraitMode-400, our paper aims to inspire further research efforts in this emerging research area.
Shot2Story20K: A New Benchmark for Comprehensive Understanding of Multi-shot Videos
Dec 19, 2023A short clip of video may contain progression of multiple events and an interesting story line. A human need to capture both the event in every shot and associate them together to understand the story behind it. In this work, we present a new multi-shot video understanding benchmark Shot2Story20K with detailed shot-level captions and comprehensive video summaries. To facilitate better semantic understanding of videos, we provide captions for both visual signals and human narrations. We design several distinct tasks including single-shot video and narration captioning, multi-shot video summarization, and video retrieval with shot descriptions. Preliminary experiments show some challenges to generate a long and comprehensive video summary. Nevertheless, the generated imperfect summaries can already significantly boost the performance of existing video understanding tasks such as video question-answering, promoting an under-explored setting of video understanding with detailed summaries.
Generating Action-conditioned Prompts for Open-vocabulary Video Action Recognition
Dec 04, 2023Exploring open-vocabulary video action recognition is a promising venture, which aims to recognize previously unseen actions within any arbitrary set of categories. Existing methods typically adapt pretrained image-text models to the video domain, capitalizing on their inherent strengths in generalization. A common thread among such methods is the augmentation of visual embeddings with temporal information to improve the recognition of seen actions. Yet, they compromise with standard less-informative action descriptions, thus faltering when confronted with novel actions. Drawing inspiration from human cognitive processes, we argue that augmenting text embeddings with human prior knowledge is pivotal for open-vocabulary video action recognition. To realize this, we innovatively blend video models with Large Language Models (LLMs) to devise Action-conditioned Prompts. Specifically, we harness the knowledge in LLMs to produce a set of descriptive sentences that contain distinctive features for identifying given actions. Building upon this foundation, we further introduce a multi-modal action knowledge alignment mechanism to align concepts in video and textual knowledge encapsulated within the prompts. Extensive experiments on various video benchmarks, including zero-shot, few-shot, and base-to-novel generalization settings, demonstrate that our method not only sets new SOTA performance but also possesses excellent interpretability.
Mask Propagation for Efficient Video Semantic Segmentation
Oct 29, 2023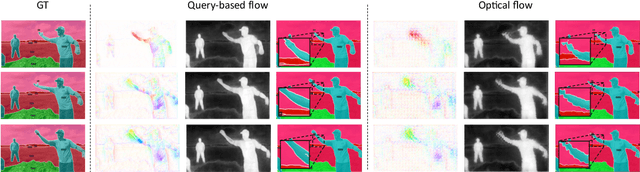
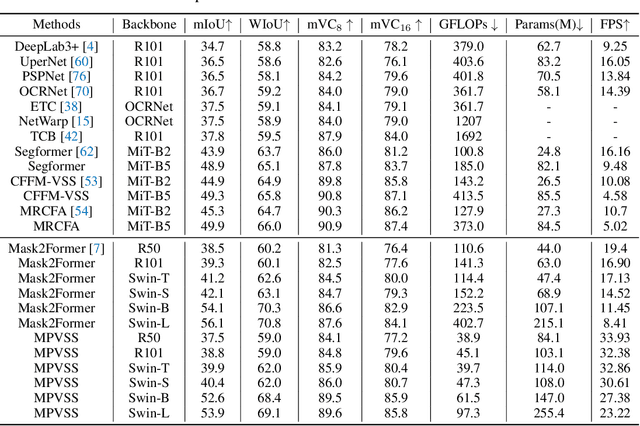
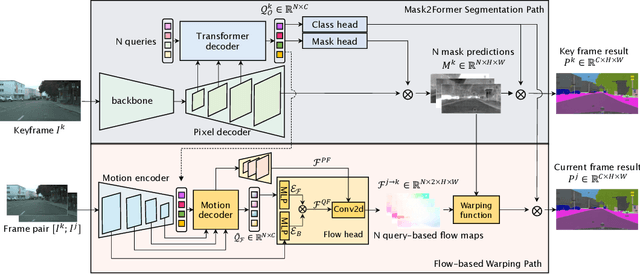
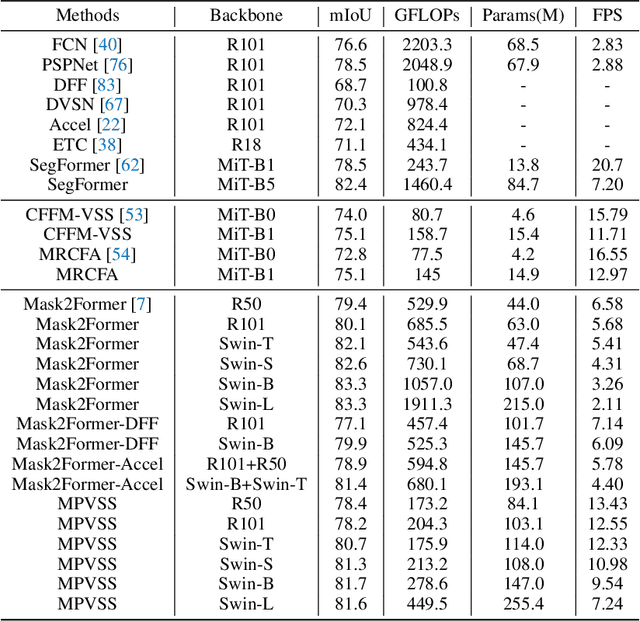
Video Semantic Segmentation (VSS) involves assigning a semantic label to each pixel in a video sequence. Prior work in this field has demonstrated promising results by extending image semantic segmentation models to exploit temporal relationships across video frames; however, these approaches often incur significant computational costs. In this paper, we propose an efficient mask propagation framework for VSS, called MPVSS. Our approach first employs a strong query-based image segmentor on sparse key frames to generate accurate binary masks and class predictions. We then design a flow estimation module utilizing the learned queries to generate a set of segment-aware flow maps, each associated with a mask prediction from the key frame. Finally, the mask-flow pairs are warped to serve as the mask predictions for the non-key frames. By reusing predictions from key frames, we circumvent the need to process a large volume of video frames individually with resource-intensive segmentors, alleviating temporal redundancy and significantly reducing computational costs. Extensive experiments on VSPW and Cityscapes demonstrate that our mask propagation framework achieves SOTA accuracy and efficiency trade-offs. For instance, our best model with Swin-L backbone outperforms the SOTA MRCFA using MiT-B5 by 4.0% mIoU, requiring only 26% FLOPs on the VSPW dataset. Moreover, our framework reduces up to 4x FLOPs compared to the per-frame Mask2Former baseline with only up to 2% mIoU degradation on the Cityscapes validation set. Code is available at https://github.com/ziplab/MPVSS.
An Efficient Spatio-Temporal Pyramid Transformer for Action Detection
Jul 21, 2022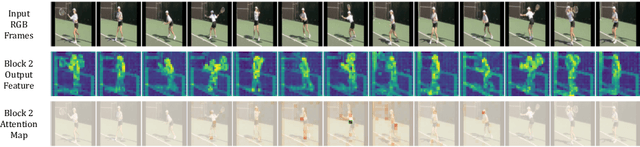

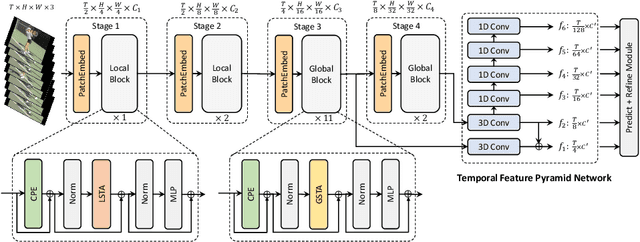
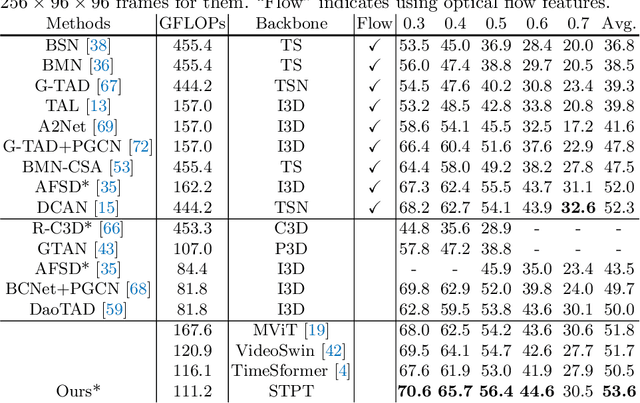
The task of action detection aims at deducing both the action category and localization of the start and end moment for each action instance in a long, untrimmed video. While vision Transformers have driven the recent advances in video understanding, it is non-trivial to design an efficient architecture for action detection due to the prohibitively expensive self-attentions over a long sequence of video clips. To this end, we present an efficient hierarchical Spatio-Temporal Pyramid Transformer (STPT) for action detection, building upon the fact that the early self-attention layers in Transformers still focus on local patterns. Specifically, we propose to use local window attention to encode rich local spatio-temporal representations in the early stages while applying global attention modules to capture long-term space-time dependencies in the later stages. In this way, our STPT can encode both locality and dependency with largely reduced redundancy, delivering a promising trade-off between accuracy and efficiency. For example, with only RGB input, the proposed STPT achieves 53.6% mAP on THUMOS14, surpassing I3D+AFSD RGB model by over 10% and performing favorably against state-of-the-art AFSD that uses additional flow features with 31% fewer GFLOPs, which serves as an effective and efficient end-to-end Transformer-based framework for action detection.
Dual-AI: Dual-path Actor Interaction Learning for Group Activity Recognition
Apr 06, 2022



Learning spatial-temporal relation among multiple actors is crucial for group activity recognition. Different group activities often show the diversified interactions between actors in the video. Hence, it is often difficult to model complex group activities from a single view of spatial-temporal actor evolution. To tackle this problem, we propose a distinct Dual-path Actor Interaction (DualAI) framework, which flexibly arranges spatial and temporal transformers in two complementary orders, enhancing actor relations by integrating merits from different spatiotemporal paths. Moreover, we introduce a novel Multi-scale Actor Contrastive Loss (MAC-Loss) between two interactive paths of Dual-AI. Via self-supervised actor consistency in both frame and video levels, MAC-Loss can effectively distinguish individual actor representations to reduce action confusion among different actors. Consequently, our Dual-AI can boost group activity recognition by fusing such discriminative features of different actors. To evaluate the proposed approach, we conduct extensive experiments on the widely used benchmarks, including Volleyball, Collective Activity, and NBA datasets. The proposed Dual-AI achieves state-of-the-art performance on all these datasets. It is worth noting the proposed Dual-AI with 50% training data outperforms a number of recent approaches with 100% training data. This confirms the generalization power of Dual-AI for group activity recognition, even under the challenging scenarios of limited supervision.