 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZizheng Pan
T-Stitch: Accelerating Sampling in Pre-Trained Diffusion Models with Trajectory Stitching
Feb 21, 2024
Sampling from diffusion probabilistic models (DPMs) is often expensive for high-quality image generation and typically requires many steps with a large model. In this paper, we introduce sampling Trajectory Stitching T-Stitch, a simple yet efficient technique to improve the sampling efficiency with little or no generation degradation. Instead of solely using a large DPM for the entire sampling trajectory, T-Stitch first leverages a smaller DPM in the initial steps as a cheap drop-in replacement of the larger DPM and switches to the larger DPM at a later stage. Our key insight is that different diffusion models learn similar encodings under the same training data distribution and smaller models are capable of generating good global structures in the early steps. Extensive experiments demonstrate that T-Stitch is training-free, generally applicable for different architectures, and complements most existing fast sampling techniques with flexible speed and quality trade-offs. On DiT-XL, for example, 40% of the early timesteps can be safely replaced with a 10x faster DiT-S without performance drop on class-conditional ImageNet generation. We further show that our method can also be used as a drop-in technique to not only accelerate the popular pretrained stable diffusion (SD) models but also improve the prompt alignment of stylized SD models from the public model zoo. Code is released at https://github.com/NVlabs/T-Stitch
Efficient Stitchable Task Adaptation
Nov 29, 2023
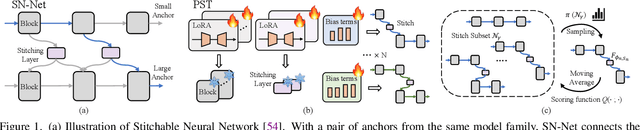
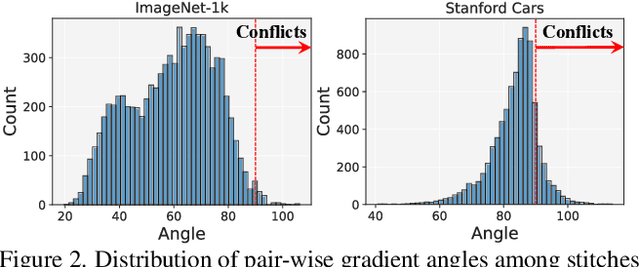

The paradigm of pre-training and fine-tuning has laid the foundation for deploying deep learning models. However, most fine-tuning methods are designed to meet a specific resource budget. Recently, considering diverse deployment scenarios with various resource budgets, stitchable neural network (SN-Net) is introduced to quickly obtain numerous new networks (stitches) from the pre-trained models (anchors) in a model family via model stitching. Although promising, SN-Net confronts new challenges when adapting it to new target domains, including huge memory and storage requirements and a long and sub-optimal multistage adaptation process. In this work, we present a novel framework, Efficient Stitchable Task Adaptation (ESTA), to efficiently produce a palette of fine-tuned models that adhere to diverse resource constraints. Specifically, we first tailor parameter-efficient fine-tuning to share low-rank updates among the stitches while maintaining independent bias terms. In this way, we largely reduce fine-tuning memory burdens and mitigate the interference among stitches that arises in task adaptation. Furthermore, we streamline a simple yet effective one-stage deployment pipeline, which estimates the important stitches to deploy with training-time gradient statistics. By assigning higher sampling probabilities to important stitches, we also get a boosted Pareto frontier. Extensive experiments on 25 downstream visual recognition tasks demonstrate that our ESTA is capable of generating stitches with smooth accuracy-efficiency trade-offs and surpasses the direct SN-Net adaptation by remarkable margins with significantly lower training time and fewer trainable parameters. Furthermore, we demonstrate the flexibility and scalability of our ESTA framework by stitching LLMs from LLaMA family, obtaining chatbot stitches of assorted sizes.
Stitched ViTs are Flexible Vision Backbones
Jun 30, 2023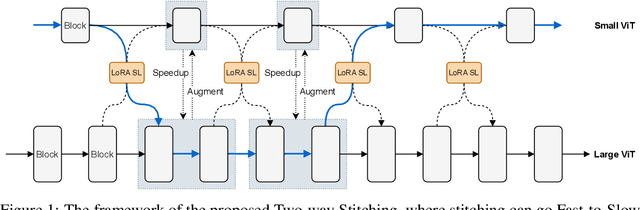

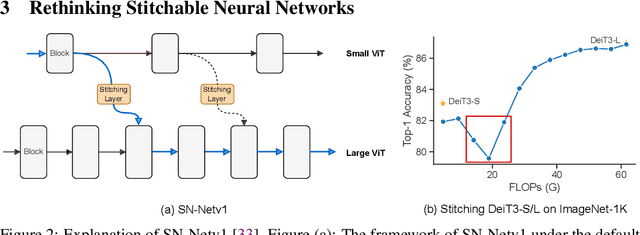
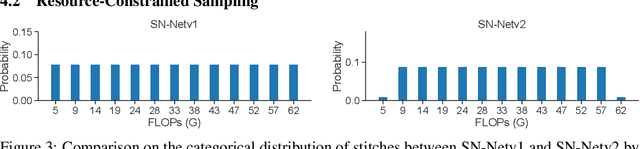
Large pretrained plain vision Transformers (ViTs) have been the workhorse for many downstream tasks. However, existing works utilizing off-the-shelf ViTs are inefficient in terms of training and deployment, because adopting ViTs with individual sizes requires separate training and is restricted by fixed performance-efficiency trade-offs. In this paper, we are inspired by stitchable neural networks, which is a new framework that cheaply produces a single model that covers rich subnetworks by stitching pretrained model families, supporting diverse performance-efficiency trade-offs at runtime. Building upon this foundation, we introduce SN-Netv2, a systematically improved model stitching framework to facilitate downstream task adaptation. Specifically, we first propose a Two-way stitching scheme to enlarge the stitching space. We then design a resource-constrained sampling strategy that takes into account the underlying FLOPs distributions in the space for improved sampling. Finally, we observe that learning stitching layers is a low-rank update, which plays an essential role on downstream tasks to stabilize training and ensure a good Pareto frontier. With extensive experiments on ImageNet-1K, ADE20K, COCO-Stuff-10K, NYUv2 and COCO-2017, SN-Netv2 demonstrates strong ability to serve as a flexible vision backbone, achieving great advantages in both training efficiency and adaptation. Code will be released at https://github.com/ziplab/SN-Netv2.
Stitchable Neural Networks
Feb 15, 2023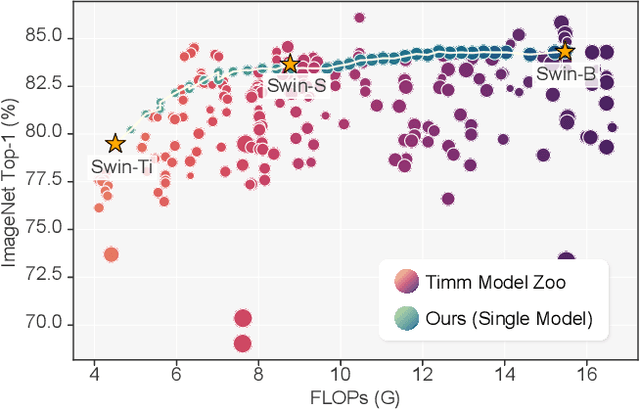
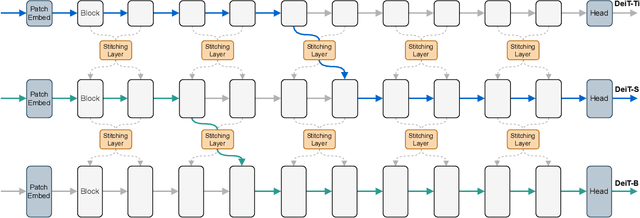
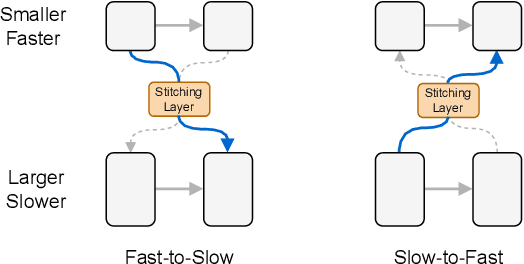
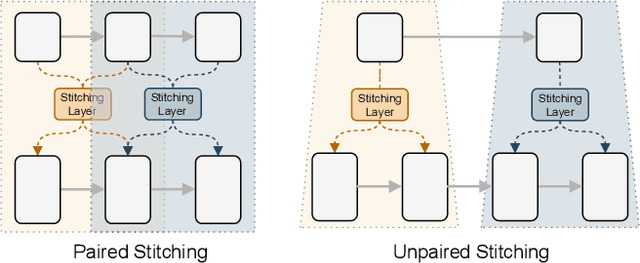
The public model zoo containing enormous powerful pretrained model families (e.g., ResNet/DeiT) has reached an unprecedented scope than ever, which significantly contributes to the success of deep learning. As each model family consists of pretrained models with diverse scales (e.g., DeiT-Ti/S/B), it naturally arises a fundamental question of how to efficiently assemble these readily available models in a family for dynamic accuracy-efficiency trade-offs at runtime. To this end, we present Stitchable Neural Networks (SN-Net), a novel scalable and efficient framework for model deployment which cheaply produces numerous networks with different complexity and performance trade-offs given a family of pretrained neural networks, which we call anchors. Specifically, SN-Net splits the anchors across the blocks/layers and then stitches them together with simple stitching layers to map the activations from one anchor to another. With only a few epochs of training, SN-Net effectively interpolates between the performance of anchors with varying scales. At runtime, SN-Net can instantly adapt to dynamic resource constraints by switching the stitching positions. Extensive experiments on ImageNet classification demonstrate that SN-Net can obtain on-par or even better performance than many individually trained networks while supporting diverse deployment scenarios. For example, by stitching Swin Transformers, we challenge hundreds of models in Timm model zoo with a single network. We believe this new elastic model framework can serve as a strong baseline for further research in wider communities.
A Survey on Efficient Training of Transformers
Feb 02, 2023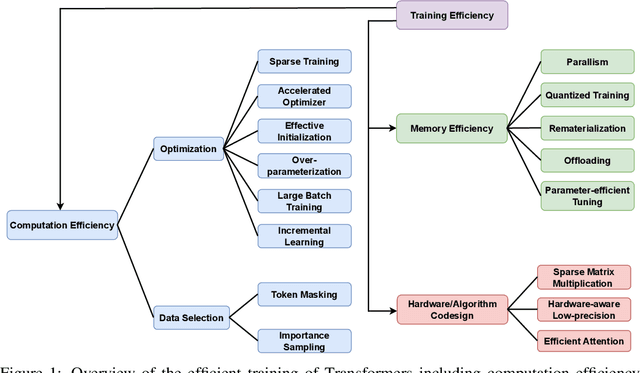
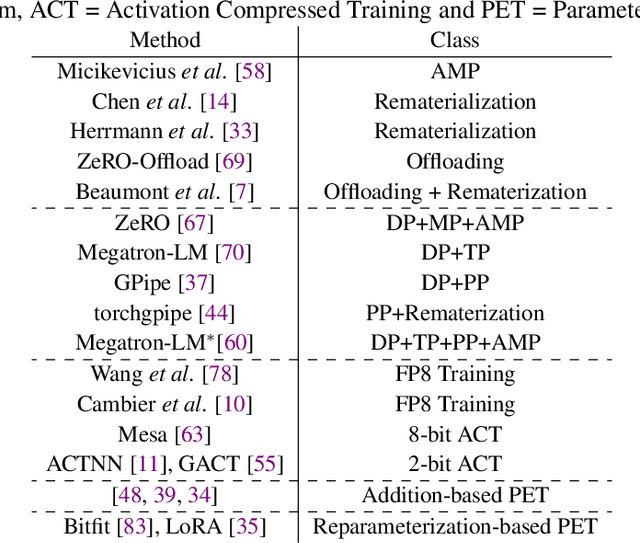
Recent advances in Transformers have come with a huge requirement on computing resources, highlighting the importance of developing efficient training techniques to make Transformer training faster, at lower cost, and to higher accuracy by the efficient use of computation and memory resources. This survey provides the first systematic overview of the efficient training of Transformers, covering the recent progress in acceleration arithmetic and hardware, with a focus on the former. We analyze and compare methods that save computation and memory costs for intermediate tensors during training, together with techniques on hardware/algorithm co-design. We finally discuss challenges and promising areas for future research.
EcoFormer: Energy-Saving Attention with Linear Complexity
Sep 19, 2022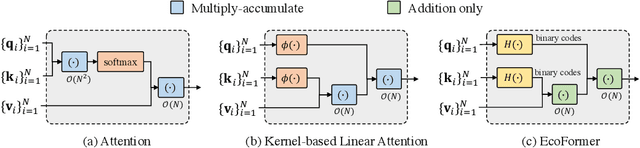

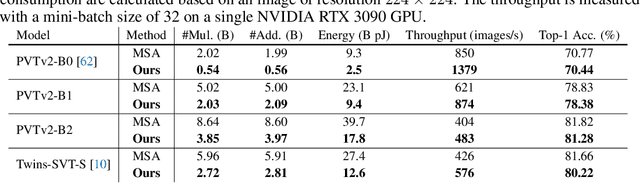
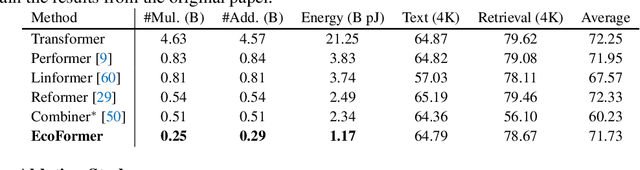
Transformer is a transformative framework that models sequential data and has achieved remarkable performance on a wide range of tasks, but with high computational and energy cost. To improve its efficiency, a popular choice is to compress the models via binarization which constrains the floating-point values into binary ones to save resource consumption owing to cheap bitwise operations significantly. However, existing binarization methods only aim at minimizing the information loss for the input distribution statistically, while ignoring the pairwise similarity modeling at the core of the attention mechanism. To this end, we propose a new binarization paradigm customized to high-dimensional softmax attention via kernelized hashing, called EcoFormer, to map the original queries and keys into low-dimensional binary codes in Hamming space. The kernelized hash functions are learned to match the ground-truth similarity relations extracted from the attention map in a self-supervised way. Based on the equivalence between the inner product of binary codes and the Hamming distance as well as the associative property of matrix multiplication, we can approximate the attention in linear complexity by expressing it as a dot-product of binary codes. Moreover, the compact binary representations of queries and keys enable us to replace most of the expensive multiply-accumulate operations in attention with simple accumulations to save considerable on-chip energy footprint on edge devices. Extensive experiments on both vision and language tasks show that EcoFormer consistently achieves comparable performance with standard attentions while consuming much fewer resources. For example, based on PVTv2-B0 and ImageNet-1K, Ecoformer achieves a 73% energy footprint reduction with only a 0.33% performance drop compared to the standard attention. Code is available at https://github.com/ziplab/EcoFormer.
An Efficient Spatio-Temporal Pyramid Transformer for Action Detection
Jul 21, 2022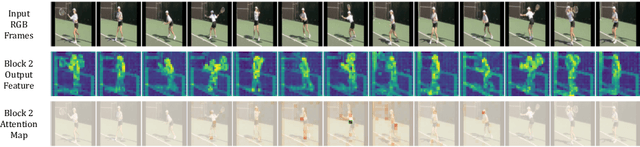

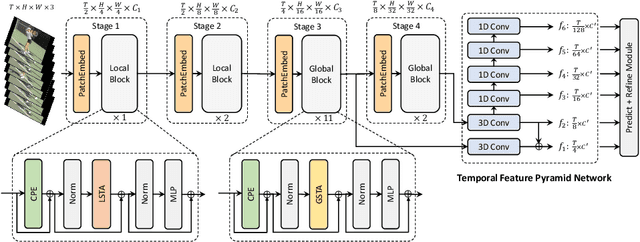
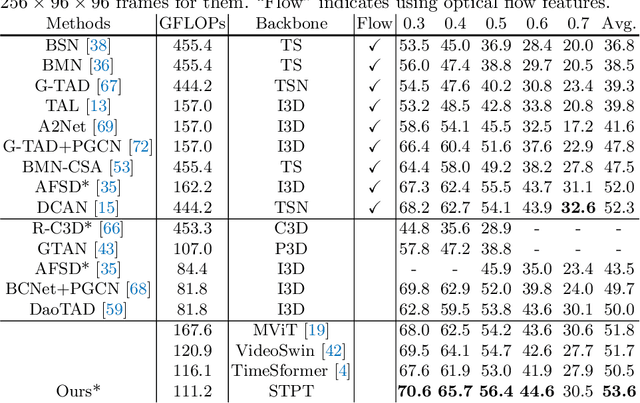
The task of action detection aims at deducing both the action category and localization of the start and end moment for each action instance in a long, untrimmed video. While vision Transformers have driven the recent advances in video understanding, it is non-trivial to design an efficient architecture for action detection due to the prohibitively expensive self-attentions over a long sequence of video clips. To this end, we present an efficient hierarchical Spatio-Temporal Pyramid Transformer (STPT) for action detection, building upon the fact that the early self-attention layers in Transformers still focus on local patterns. Specifically, we propose to use local window attention to encode rich local spatio-temporal representations in the early stages while applying global attention modules to capture long-term space-time dependencies in the later stages. In this way, our STPT can encode both locality and dependency with largely reduced redundancy, delivering a promising trade-off between accuracy and efficiency. For example, with only RGB input, the proposed STPT achieves 53.6% mAP on THUMOS14, surpassing I3D+AFSD RGB model by over 10% and performing favorably against state-of-the-art AFSD that uses additional flow features with 31% fewer GFLOPs, which serves as an effective and efficient end-to-end Transformer-based framework for action detection.
Fast Vision Transformers with HiLo Attention
May 26, 2022
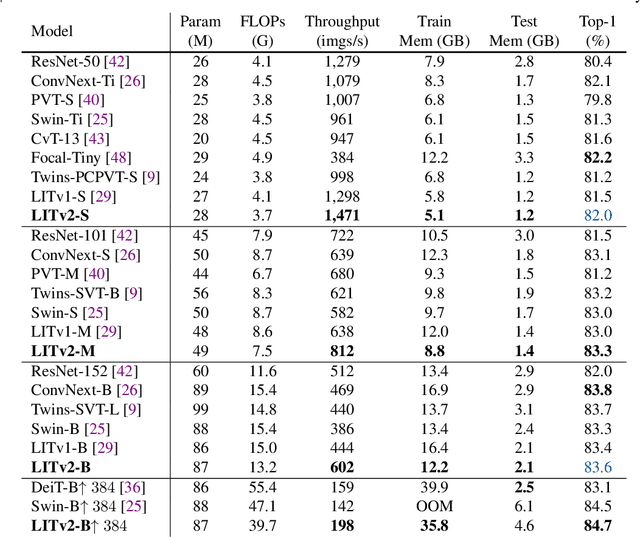
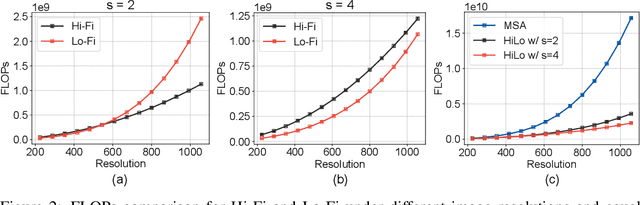

Vision Transformers (ViTs) have triggered the most recent and significant breakthroughs in computer vision. Their efficient designs are mostly guided by the indirect metric of computational complexity, i.e., FLOPs, which however has a clear gap with the direct metric such as throughput. Thus, we propose to use the direct speed evaluation on the target platform as the design principle for efficient ViTs. Particularly, we introduce LITv2, a simple and effective ViT which performs favourably against the existing state-of-the-art methods across a spectrum of different model sizes with faster speed. At the core of LITv2 is a novel self-attention mechanism, which we dub HiLo. HiLo is inspired by the insight that high frequencies in an image capture local fine details and low frequencies focus on global structures, whereas a multi-head self-attention layer neglects the characteristic of different frequencies. Therefore, we propose to disentangle the high/low frequency patterns in an attention layer by separating the heads into two groups, where one group encodes high frequencies via self-attention within each local window, and another group performs the attention to model the global relationship between the average-pooled low-frequency keys from each window and each query position in the input feature map. Benefit from the efficient design for both groups, we show that HiLo is superior to the existing attention mechanisms by comprehensively benchmarking on FLOPs, speed and memory consumption on GPUs. Powered by HiLo, LITv2 serves as a strong backbone for mainstream vision tasks including image classification, dense detection and segmentation. Code is available at https://github.com/zip-group/LITv2.
Dynamic Focus-aware Positional Queries for Semantic Segmentation
Apr 04, 2022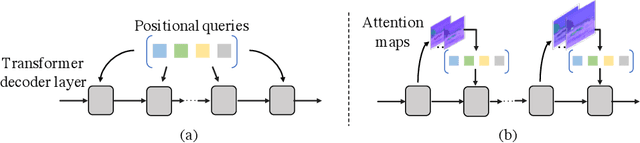
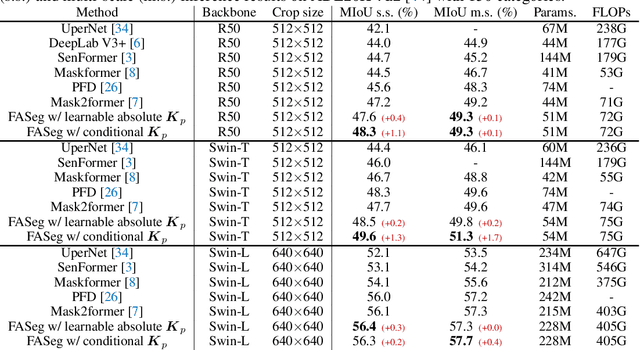
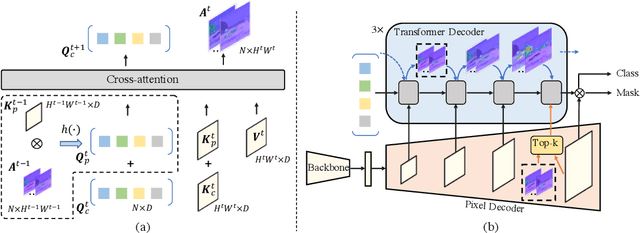
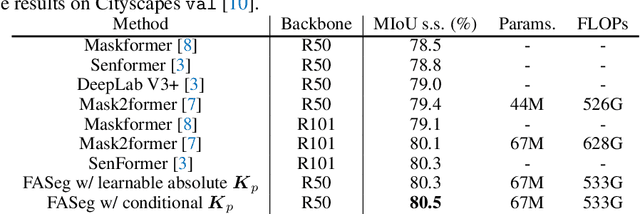
Most of the latest top semantic segmentation approaches are based on vision Transformers, particularly DETR-like frameworks, which employ a set of queries in the Transformer decoder. Each query is composed of a content query that preserves semantic information and a positional query that provides positional guidance for aggregating the query-specific context. However, the positional queries in the Transformer decoder layers are typically represented as fixed learnable weights, which often encode dataset statistics for segments and can be inaccurate for individual samples. Therefore, in this paper, we propose to generate positional queries dynamically conditioned on the cross-attention scores and the localization information of the preceding layer. By doing so, each query is aware of its previous focus, thus providing more accurate positional guidance and encouraging the cross-attention consistency across the decoder layers. In addition, we also propose an efficient way to deal with high-resolution cross-attention by dynamically determining the contextual tokens based on the low-resolution cross-attention maps to perform local relation aggregation. Our overall framework termed FASeg (Focus-Aware semantic Segmentation) provides a simple yet effective solution for semantic segmentation. Extensive experiments on ADE20K and Cityscapes show that our FASeg achieves state-of-the-art performance, e.g., obtaining 48.3% and 49.6% mIoU respectively for single-scale inference on ADE20K validation set with ResNet-50 and Swin-T backbones, and barely increases the computation consumption from Mask2former. Source code will be made publicly available at https://github.com/zip-group/FASeg.
Pruning Self-attentions into Convolutional Layers in Single Path
Nov 23, 2021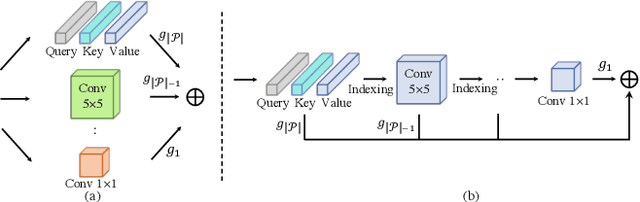
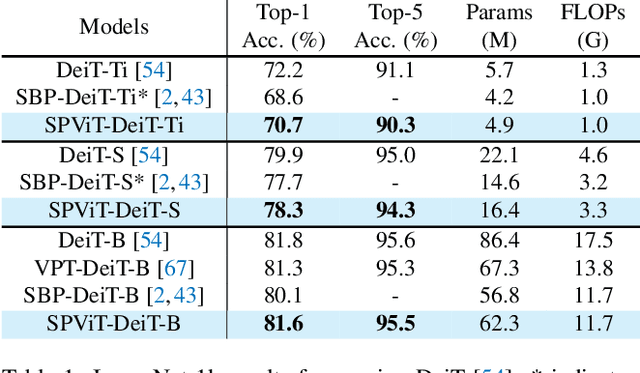

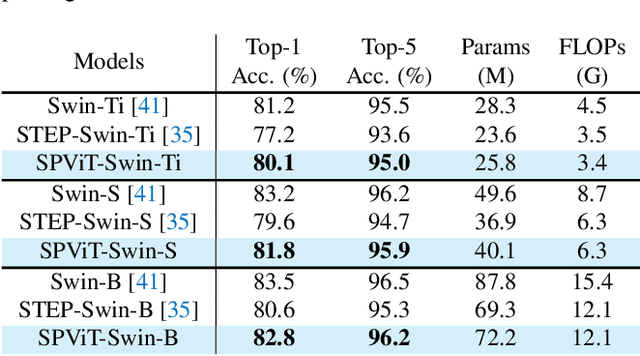
Vision Transformers (ViTs) have achieved impressive performance over various computer vision tasks. However, modeling global correlations with multi-head self-attention (MSA) layers leads to two widely recognized issues: the massive computational resource consumption and the lack of intrinsic inductive bias for modeling local visual patterns. One unified solution is to search whether to replace some MSA layers with convolution-like inductive biases that are computationally efficient via neural architecture search (NAS) based pruning methods. However, maintaining MSA and different candidate convolutional operations as separate trainable paths gives rise to expensive search cost and challenging optimization. Instead, we propose a novel weight-sharing scheme between MSA and convolutional operations and cast the search problem as finding which subset of parameters to use in each MSA layer. The weight-sharing scheme further allows us to devise an automatic Single-Path Vision Transformer pruning method (SPViT) to quickly prune the pre-trained ViTs into accurate and compact hybrid models with significantly reduced search cost, given target efficiency constraints. We conduct extensive experiments on two representative ViT models showing our method achieves a favorable accuracy-efficiency trade-off. Code is available at https://github.com/zhuang-group/SPViT.