 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeili Nie
Efficient Video Diffusion Models via Content-Frame Motion-Latent Decomposition
Mar 21, 2024
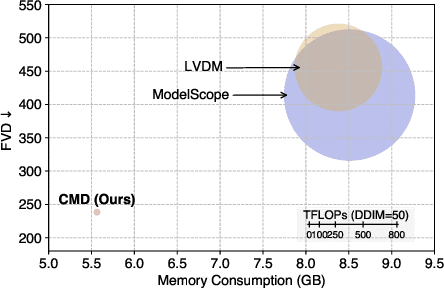
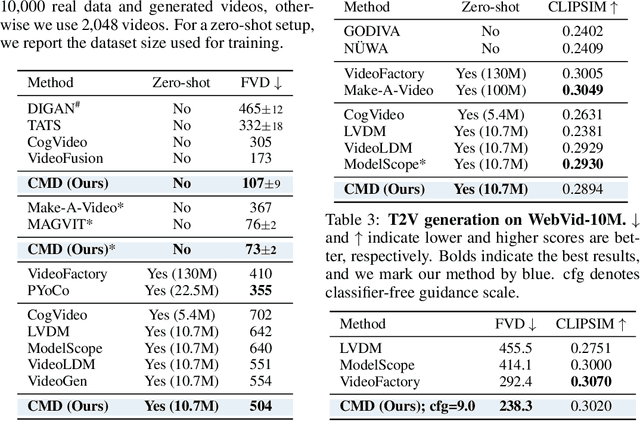
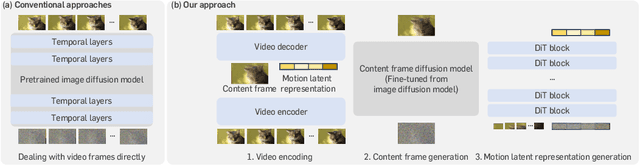
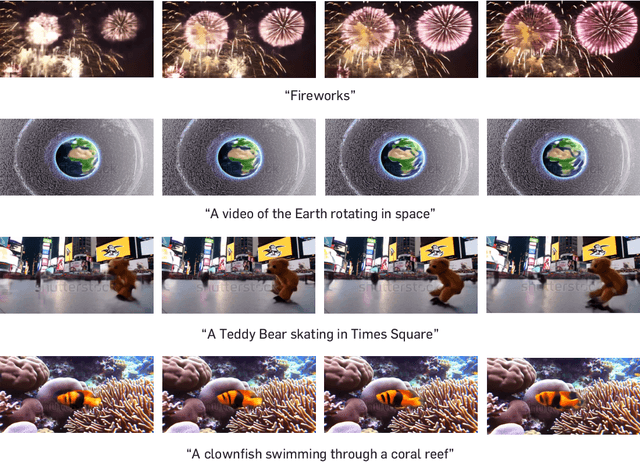
Video diffusion models have recently made great progress in generation quality, but are still limited by the high memory and computational requirements. This is because current video diffusion models often attempt to process high-dimensional videos directly. To tackle this issue, we propose content-motion latent diffusion model (CMD), a novel efficient extension of pretrained image diffusion models for video generation. Specifically, we propose an autoencoder that succinctly encodes a video as a combination of a content frame (like an image) and a low-dimensional motion latent representation. The former represents the common content, and the latter represents the underlying motion in the video, respectively. We generate the content frame by fine-tuning a pretrained image diffusion model, and we generate the motion latent representation by training a new lightweight diffusion model. A key innovation here is the design of a compact latent space that can directly utilizes a pretrained image diffusion model, which has not been done in previous latent video diffusion models. This leads to considerably better quality generation and reduced computational costs. For instance, CMD can sample a video 7.7$\times$ faster than prior approaches by generating a video of 512$\times$1024 resolution and length 16 in 3.1 seconds. Moreover, CMD achieves an FVD score of 212.7 on WebVid-10M, 27.3% better than the previous state-of-the-art of 292.4.
T-Stitch: Accelerating Sampling in Pre-Trained Diffusion Models with Trajectory Stitching
Feb 21, 2024Sampling from diffusion probabilistic models (DPMs) is often expensive for high-quality image generation and typically requires many steps with a large model. In this paper, we introduce sampling Trajectory Stitching T-Stitch, a simple yet efficient technique to improve the sampling efficiency with little or no generation degradation. Instead of solely using a large DPM for the entire sampling trajectory, T-Stitch first leverages a smaller DPM in the initial steps as a cheap drop-in replacement of the larger DPM and switches to the larger DPM at a later stage. Our key insight is that different diffusion models learn similar encodings under the same training data distribution and smaller models are capable of generating good global structures in the early steps. Extensive experiments demonstrate that T-Stitch is training-free, generally applicable for different architectures, and complements most existing fast sampling techniques with flexible speed and quality trade-offs. On DiT-XL, for example, 40% of the early timesteps can be safely replaced with a 10x faster DiT-S without performance drop on class-conditional ImageNet generation. We further show that our method can also be used as a drop-in technique to not only accelerate the popular pretrained stable diffusion (SD) models but also improve the prompt alignment of stylized SD models from the public model zoo. Code is released at https://github.com/NVlabs/T-Stitch
Unsupervised Discovery of Steerable Factors When Graph Deep Generative Models Are Entangled
Jan 29, 2024Deep generative models (DGMs) have been widely developed for graph data. However, much less investigation has been carried out on understanding the latent space of such pretrained graph DGMs. These understandings possess the potential to provide constructive guidelines for crucial tasks, such as graph controllable generation. Thus in this work, we are interested in studying this problem and propose GraphCG, a method for the unsupervised discovery of steerable factors in the latent space of pretrained graph DGMs. We first examine the representation space of three pretrained graph DGMs with six disentanglement metrics, and we observe that the pretrained representation space is entangled. Motivated by this observation, GraphCG learns the steerable factors via maximizing the mutual information between semantic-rich directions, where the controlled graph moving along the same direction will share the same steerable factors. We quantitatively verify that GraphCG outperforms four competitive baselines on two graph DGMs pretrained on two molecule datasets. Additionally, we qualitatively illustrate seven steerable factors learned by GraphCG on five pretrained DGMs over five graph datasets, including two for molecules and three for point clouds.
DeepSpeed4Science Initiative: Enabling Large-Scale Scientific Discovery through Sophisticated AI System Technologies
Oct 11, 2023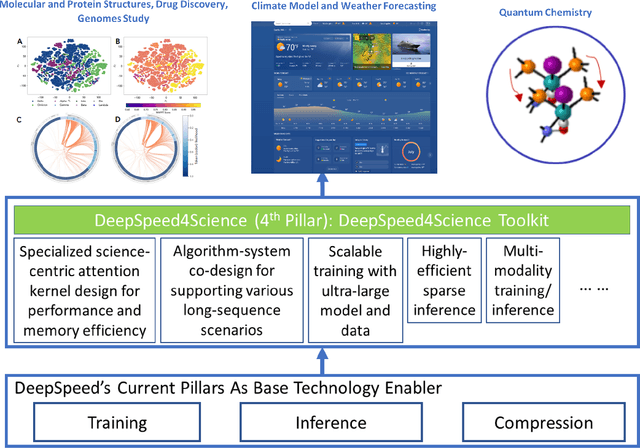

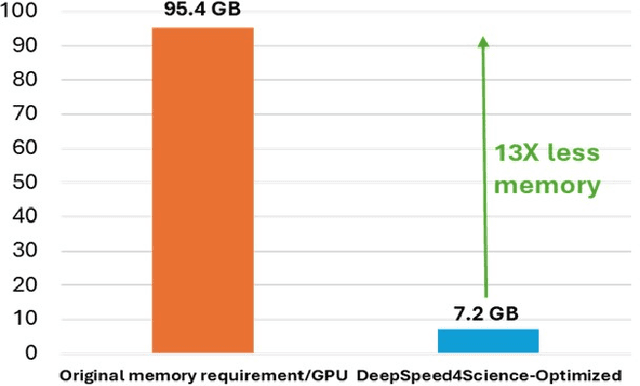
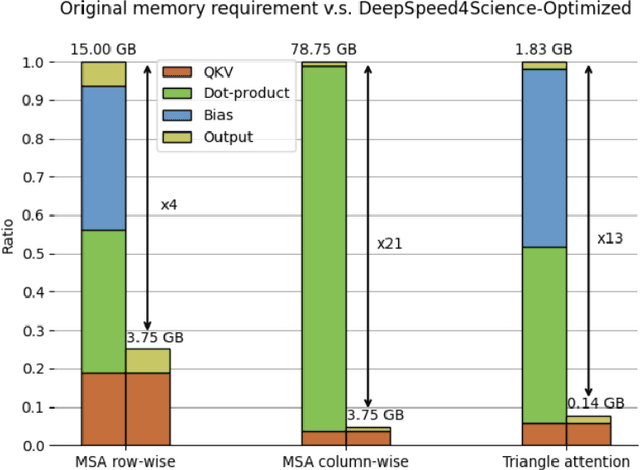
In the upcoming decade, deep learning may revolutionize the natural sciences, enhancing our capacity to model and predict natural occurrences. This could herald a new era of scientific exploration, bringing significant advancements across sectors from drug development to renewable energy. To answer this call, we present DeepSpeed4Science initiative (deepspeed4science.ai) which aims to build unique capabilities through AI system technology innovations to help domain experts to unlock today's biggest science mysteries. By leveraging DeepSpeed's current technology pillars (training, inference and compression) as base technology enablers, DeepSpeed4Science will create a new set of AI system technologies tailored for accelerating scientific discoveries by addressing their unique complexity beyond the common technical approaches used for accelerating generic large language models (LLMs). In this paper, we showcase the early progress we made with DeepSpeed4Science in addressing two of the critical system challenges in structural biology research.
Improving Generative Model-based Unfolding with Schrödinger Bridges
Aug 23, 2023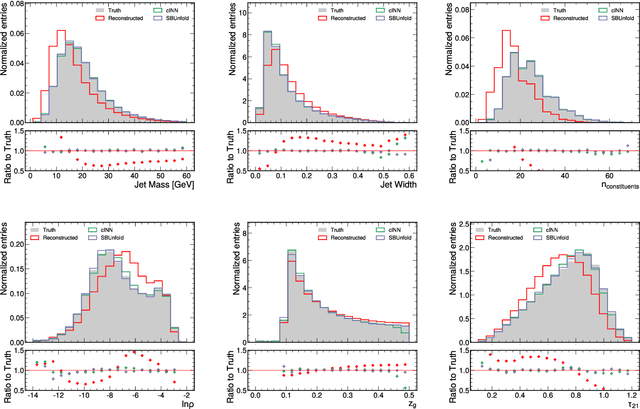
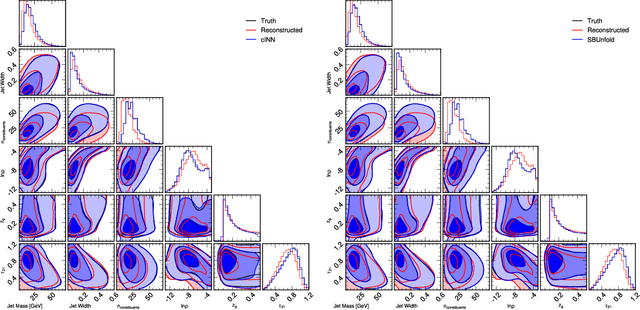
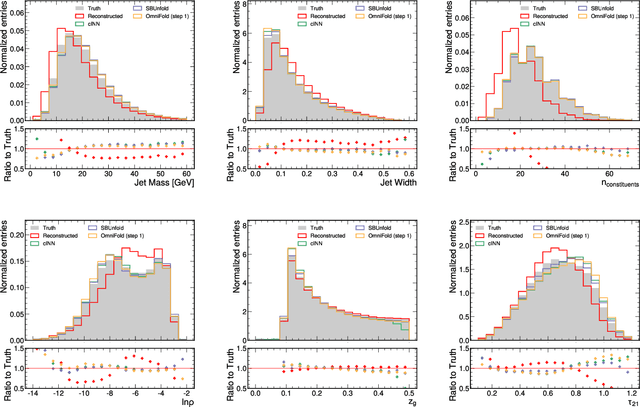
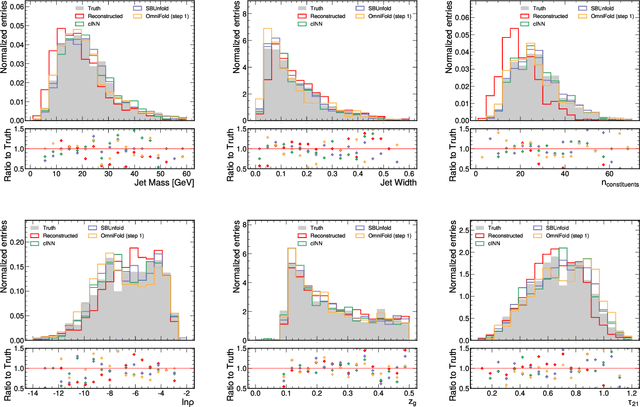
Machine learning-based unfolding has enabled unbinned and high-dimensional differential cross section measurements. Two main approaches have emerged in this research area: one based on discriminative models and one based on generative models. The main advantage of discriminative models is that they learn a small correction to a starting simulation while generative models scale better to regions of phase space with little data. We propose to use Schroedinger Bridges and diffusion models to create SBUnfold, an unfolding approach that combines the strengths of both discriminative and generative models. The key feature of SBUnfold is that its generative model maps one set of events into another without having to go through a known probability density as is the case for normalizing flows and standard diffusion models. We show that SBUnfold achieves excellent performance compared to state of the art methods on a synthetic Z+jets dataset.
Fast Training of Diffusion Models with Masked Transformers
Jun 15, 2023
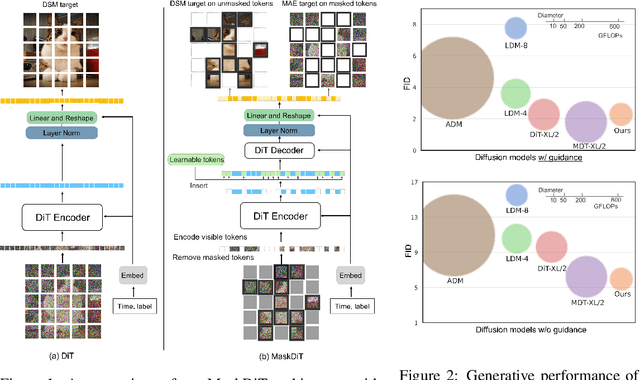
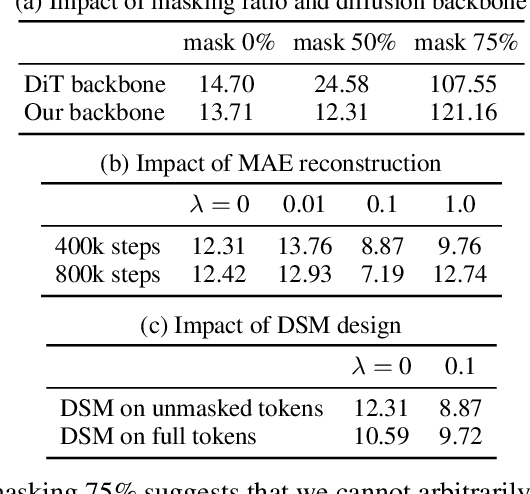

We propose an efficient approach to train large diffusion models with masked transformers. While masked transformers have been extensively explored for representation learning, their application to generative learning is less explored in the vision domain. Our work is the first to exploit masked training to reduce the training cost of diffusion models significantly. Specifically, we randomly mask out a high proportion (\emph{e.g.}, 50\%) of patches in diffused input images during training. For masked training, we introduce an asymmetric encoder-decoder architecture consisting of a transformer encoder that operates only on unmasked patches and a lightweight transformer decoder on full patches. To promote a long-range understanding of full patches, we add an auxiliary task of reconstructing masked patches to the denoising score matching objective that learns the score of unmasked patches. Experiments on ImageNet-256$\times$256 show that our approach achieves the same performance as the state-of-the-art Diffusion Transformer (DiT) model, using only 31\% of its original training time. Thus, our method allows for efficient training of diffusion models without sacrificing the generative performance.
Defending against Adversarial Audio via Diffusion Model
Mar 02, 2023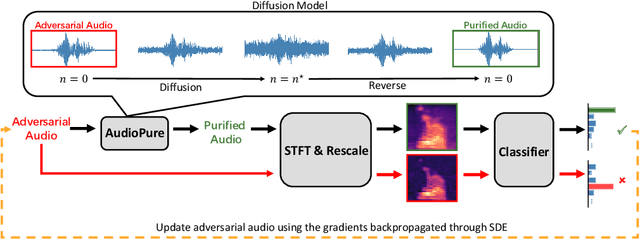

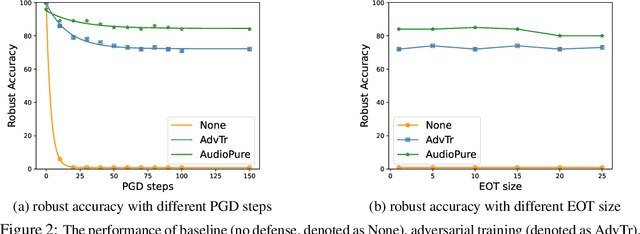

Deep learning models have been widely used in commercial acoustic systems in recent years. However, adversarial audio examples can cause abnormal behaviors for those acoustic systems, while being hard for humans to perceive. Various methods, such as transformation-based defenses and adversarial training, have been proposed to protect acoustic systems from adversarial attacks, but they are less effective against adaptive attacks. Furthermore, directly applying the methods from the image domain can lead to suboptimal results because of the unique properties of audio data. In this paper, we propose an adversarial purification-based defense pipeline, AudioPure, for acoustic systems via off-the-shelf diffusion models. Taking advantage of the strong generation ability of diffusion models, AudioPure first adds a small amount of noise to the adversarial audio and then runs the reverse sampling step to purify the noisy audio and recover clean audio. AudioPure is a plug-and-play method that can be directly applied to any pretrained classifier without any fine-tuning or re-training. We conduct extensive experiments on speech command recognition task to evaluate the robustness of AudioPure. Our method is effective against diverse adversarial attacks (e.g. $\mathcal{L}_2$ or $\mathcal{L}_\infty$-norm). It outperforms the existing methods under both strong adaptive white-box and black-box attacks bounded by $\mathcal{L}_2$ or $\mathcal{L}_\infty$-norm (up to +20\% in robust accuracy). Besides, we also evaluate the certified robustness for perturbations bounded by $\mathcal{L}_2$-norm via randomized smoothing. Our pipeline achieves a higher certified accuracy than baselines.
I$^2$SB: Image-to-Image Schrödinger Bridge
Feb 12, 2023

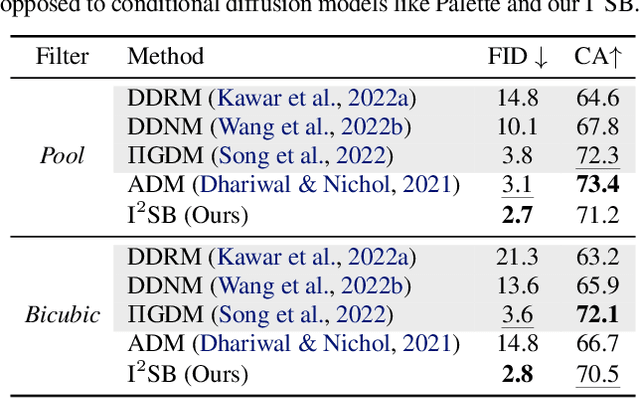
We propose Image-to-Image Schr\"odinger Bridge (I$^2$SB), a new class of conditional diffusion models that directly learn the nonlinear diffusion processes between two given distributions. These diffusion bridges are particularly useful for image restoration, as the degraded images are structurally informative priors for reconstructing the clean images. I$^2$SB belongs to a tractable class of Schr\"odinger bridge, the nonlinear extension to score-based models, whose marginal distributions can be computed analytically given boundary pairs. This results in a simulation-free framework for nonlinear diffusions, where the I$^2$SB training becomes scalable by adopting practical techniques used in standard diffusion models. We validate I$^2$SB in solving various image restoration tasks, including inpainting, super-resolution, deblurring, and JPEG restoration on ImageNet 256x256 and show that I$^2$SB surpasses standard conditional diffusion models with more interpretable generative processes. Moreover, I$^2$SB matches the performance of inverse methods that additionally require the knowledge of the corruption operators. Our work opens up new algorithmic opportunities for developing efficient nonlinear diffusion models on a large scale. scale. Project page: https://i2sb.github.io/
A Text-guided Protein Design Framework
Feb 09, 2023
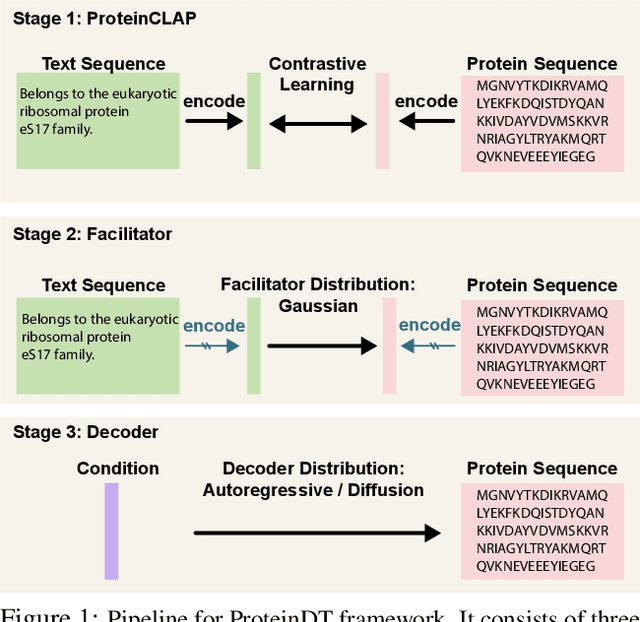

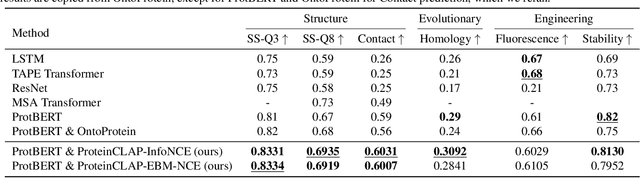
Current AI-assisted protein design mainly utilizes protein sequential and structural information. Meanwhile, there exists tremendous knowledge curated by humans in the text format describing proteins' high-level properties. Yet, whether the incorporation of such text data can help protein design tasks has not been explored. To bridge this gap, we propose ProteinDT, a multi-modal framework that leverages textual descriptions for protein design. ProteinDT consists of three subsequent steps: ProteinCLAP that aligns the representation of two modalities, a facilitator that generates the protein representation from the text modality, and a decoder that generates the protein sequences from the representation. To train ProteinDT, we construct a large dataset, SwissProtCLAP, with 441K text and protein pairs. We empirically verify the effectiveness of ProteinDT from three aspects: (1) consistently superior performance on four out of six protein property prediction benchmarks; (2) over 90% accuracy for text-guided protein generation; and (3) promising results for zero-shot text-guided protein editing.
Re-ViLM: Retrieval-Augmented Visual Language Model for Zero and Few-Shot Image Captioning
Feb 09, 2023
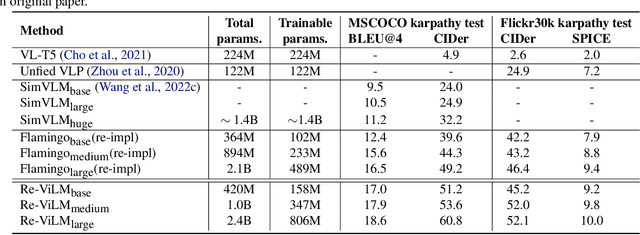
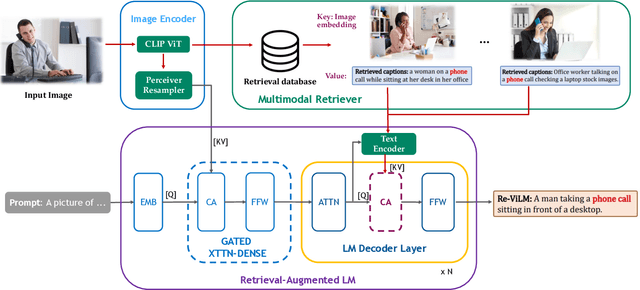
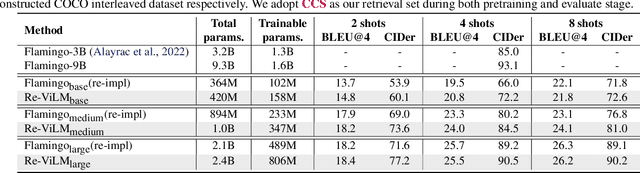
Augmenting pretrained language models (LMs) with a vision encoder (e.g., Flamingo) has obtained state-of-the-art results in image-to-text generation. However, these models store all the knowledge within their parameters, thus often requiring enormous model parameters to model the abundant visual concepts and very rich textual descriptions. Additionally, they are inefficient in incorporating new data, requiring a computational-expensive fine-tuning process. In this work, we introduce a Retrieval-augmented Visual Language Model, Re-ViLM, built upon the Flamingo, that supports retrieving the relevant knowledge from the external database for zero and in-context few-shot image-to-text generations. By storing certain knowledge explicitly in the external database, our approach reduces the number of model parameters and can easily accommodate new data during evaluation by simply updating the database. We also construct an interleaved image and text data that facilitates in-context few-shot learning capabilities. We demonstrate that Re-ViLM significantly boosts performance for image-to-text generation tasks, especially for zero-shot and few-shot generation in out-of-domain settings with 4 times less parameters compared with baseline methods.