 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHang Liu
Quadruped robot traversing 3D complex environments with limited perception
Apr 30, 2024
Traversing 3-D complex environments has always been a significant challenge for legged locomotion. Existing methods typically rely on external sensors such as vision and lidar to preemptively react to obstacles by acquiring environmental information. However, in scenarios like nighttime or dense forests, external sensors often fail to function properly, necessitating robots to rely on proprioceptive sensors to perceive diverse obstacles in the environment and respond promptly. This task is undeniably challenging. Our research finds that methods based on collision detection can enhance a robot's perception of environmental obstacles. In this work, we propose an end-to-end learning-based quadruped robot motion controller that relies solely on proprioceptive sensing. This controller can accurately detect, localize, and agilely respond to collisions in unknown and complex 3D environments, thereby improving the robot's traversability in complex environments. We demonstrate in both simulation and real-world experiments that our method enables quadruped robots to successfully traverse challenging obstacles in various complex environments.
FCNCP: A Coupled Nonnegative CANDECOMP/PARAFAC Decomposition Based on Federated Learning
Apr 18, 2024In the field of brain science, data sharing across servers is becoming increasingly challenging due to issues such as industry competition, privacy security, and administrative procedure policies and regulations. Therefore, there is an urgent need to develop new methods for data analysis and processing that enable scientific collaboration without data sharing. In view of this, this study proposes to study and develop a series of efficient non-negative coupled tensor decomposition algorithm frameworks based on federated learning called FCNCP for the EEG data arranged on different servers. It combining the good discriminative performance of tensor decomposition in high-dimensional data representation and decomposition, the advantages of coupled tensor decomposition in cross-sample tensor data analysis, and the features of federated learning for joint modelling in distributed servers. The algorithm utilises federation learning to establish coupling constraints for data distributed across different servers. In the experiments, firstly, simulation experiments are carried out using simulated data, and stable and consistent decomposition results are obtained, which verify the effectiveness of the proposed algorithms in this study. Then the FCNCP algorithm was utilised to decompose the fifth-order event-related potential (ERP) tensor data collected by applying proprioceptive stimuli on the left and right hands. It was found that contralateral stimulation induced more symmetrical components in the activation areas of the left and right hemispheres. The conclusions drawn are consistent with the interpretations of related studies in cognitive neuroscience, demonstrating that the method can efficiently process higher-order EEG data and that some key hidden information can be preserved.
Tao: Re-Thinking DL-based Microarchitecture Simulation
Apr 16, 2024Microarchitecture simulators are indispensable tools for microarchitecture designers to validate, estimate, and optimize new hardware that meets specific design requirements. While the quest for a fast, accurate and detailed microarchitecture simulation has been ongoing for decades, existing simulators excel and fall short at different aspects: (i) Although execution-driven simulation is accurate and detailed, it is extremely slow and requires expert-level experience to design. (ii) Trace-driven simulation reuses the execution traces in pursuit of fast simulation but faces accuracy concerns and fails to achieve significant speedup. (iii) Emerging deep learning (DL)-based simulations are remarkably fast and have acceptable accuracy but fail to provide adequate low-level microarchitectural performance metrics crucial for microarchitectural bottleneck analysis. Additionally, they introduce substantial overheads from trace regeneration and model re-training when simulating a new microarchitecture. Re-thinking the advantages and limitations of the aforementioned simulation paradigms, this paper introduces TAO that redesigns the DL-based simulation with three primary contributions: First, we propose a new training dataset design such that the subsequent simulation only needs functional trace as inputs, which can be rapidly generated and reused across microarchitectures. Second, we redesign the input features and the DL model using self-attention to support predicting various performance metrics. Third, we propose techniques to train a microarchitecture agnostic embedding layer that enables fast transfer learning between different microarchitectural configurations and reduces the re-training overhead of conventional DL-based simulators. Our extensive evaluation shows {\ours} can reduce the overall training and simulation time by 18.06x over the state-of-the-art DL-based endeavors.
* Published in POMACS and SIGMETRICS'24
Zero-Space Cost Fault Tolerance for Transformer-based Language Models on ReRAM
Jan 22, 2024Resistive Random Access Memory (ReRAM) has emerged as a promising platform for deep neural networks (DNNs) due to its support for parallel in-situ matrix-vector multiplication. However, hardware failures, such as stuck-at-fault defects, can result in significant prediction errors during model inference. While additional crossbars can be used to address these failures, they come with storage overhead and are not efficient in terms of space, energy, and cost. In this paper, we propose a fault protection mechanism that incurs zero space cost. Our approach includes: 1) differentiable structure pruning of rows and columns to reduce model redundancy, 2) weight duplication and voting for robust output, and 3) embedding duplicated most significant bits (MSBs) into the model weight. We evaluate our method on nine tasks of the GLUE benchmark with the BERT model, and experimental results prove its effectiveness.
MALCOM-PSGD: Inexact Proximal Stochastic Gradient Descent for Communication-Efficient Decentralized Machine Learning
Nov 09, 2023Recent research indicates that frequent model communication stands as a major bottleneck to the efficiency of decentralized machine learning (ML), particularly for large-scale and over-parameterized neural networks (NNs). In this paper, we introduce MALCOM-PSGD, a new decentralized ML algorithm that strategically integrates gradient compression techniques with model sparsification. MALCOM-PSGD leverages proximal stochastic gradient descent to handle the non-smoothness resulting from the $\ell_1$ regularization in model sparsification. Furthermore, we adapt vector source coding and dithering-based quantization for compressed gradient communication of sparsified models. Our analysis shows that decentralized proximal stochastic gradient descent with compressed communication has a convergence rate of $\mathcal{O}\left(\ln(t)/\sqrt{t}\right)$ assuming a diminishing learning rate and where $t$ denotes the number of iterations. Numerical results verify our theoretical findings and demonstrate that our method reduces communication costs by approximately $75\%$ when compared to the state-of-the-art method.
EmojiLM: Modeling the New Emoji Language
Nov 03, 2023With the rapid development of the internet, online social media welcomes people with different backgrounds through its diverse content. The increasing usage of emoji becomes a noticeable trend thanks to emoji's rich information beyond cultural or linguistic borders. However, the current study on emojis is limited to single emoji prediction and there are limited data resources available for further study of the interesting linguistic phenomenon. To this end, we synthesize a large text-emoji parallel corpus, Text2Emoji, from a large language model. Based on the parallel corpus, we distill a sequence-to-sequence model, EmojiLM, which is specialized in the text-emoji bidirectional translation. Extensive experiments on public benchmarks and human evaluation demonstrate that our proposed model outperforms strong baselines and the parallel corpus benefits emoji-related downstream tasks.
DeepSpeed4Science Initiative: Enabling Large-Scale Scientific Discovery through Sophisticated AI System Technologies
Oct 11, 2023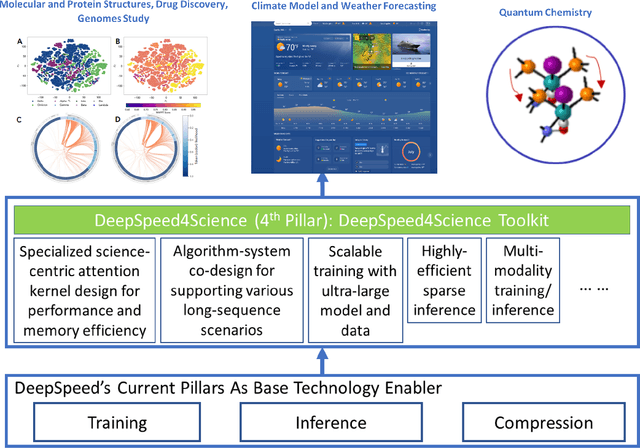

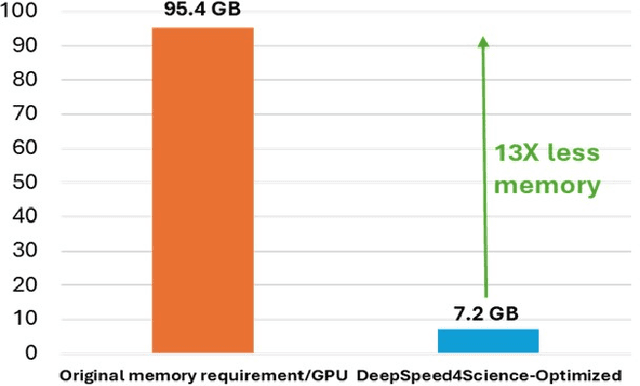
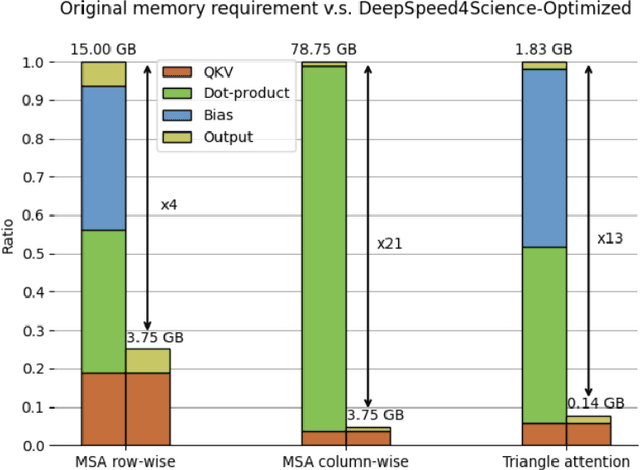
In the upcoming decade, deep learning may revolutionize the natural sciences, enhancing our capacity to model and predict natural occurrences. This could herald a new era of scientific exploration, bringing significant advancements across sectors from drug development to renewable energy. To answer this call, we present DeepSpeed4Science initiative (deepspeed4science.ai) which aims to build unique capabilities through AI system technology innovations to help domain experts to unlock today's biggest science mysteries. By leveraging DeepSpeed's current technology pillars (training, inference and compression) as base technology enablers, DeepSpeed4Science will create a new set of AI system technologies tailored for accelerating scientific discoveries by addressing their unique complexity beyond the common technical approaches used for accelerating generic large language models (LLMs). In this paper, we showcase the early progress we made with DeepSpeed4Science in addressing two of the critical system challenges in structural biology research.
Tango: rethinking quantization for graph neural network training on GPUs
Aug 02, 2023Graph Neural Networks (GNNs) are becoming increasingly popular due to their superior performance in critical graph-related tasks. While quantization is widely used to accelerate GNN computation, quantized training faces unprecedented challenges. Current quantized GNN training systems often have longer training times than their full-precision counterparts for two reasons: (i) addressing the accuracy challenge leads to excessive overhead, and (ii) the optimization potential exposed by quantization is not adequately leveraged. This paper introduces Tango which re-thinks quantization challenges and opportunities for graph neural network training on GPUs with three contributions: Firstly, we introduce efficient rules to maintain accuracy during quantized GNN training. Secondly, we design and implement quantization-aware primitives and inter-primitive optimizations that can speed up GNN training. Finally, we integrate Tango with the popular Deep Graph Library (DGL) system and demonstrate its superior performance over state-of-the-art approaches on various GNN models and datasets.
Blind Graph Matching Using Graph Signals
Jun 27, 2023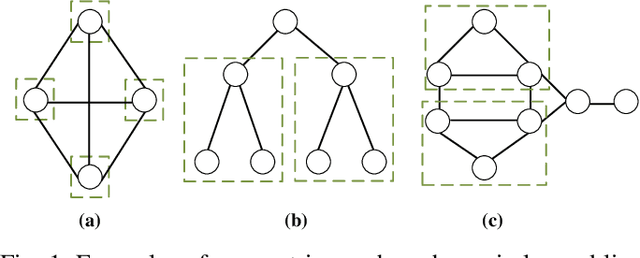
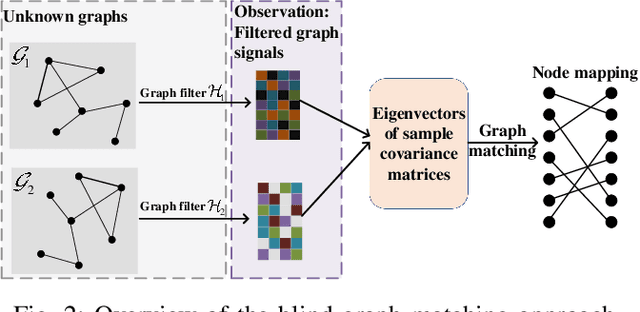
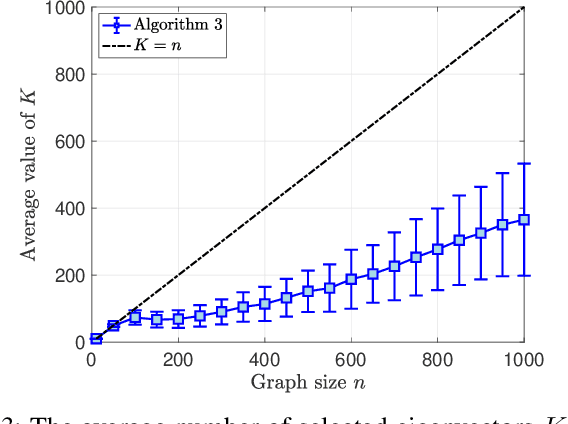
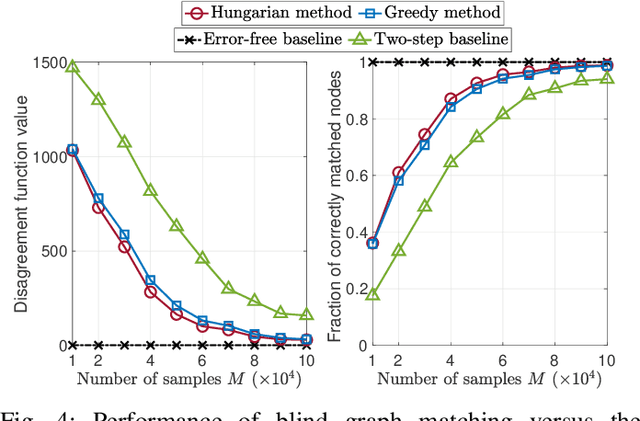
Classical graph matching aims to find a node correspondence between two unlabeled graphs of known topologies. This problem has a wide range of applications, from matching identities in social networks to identifying similar biological network functions across species. However, when the underlying graphs are unknown, the use of conventional graph matching methods requires inferring the graph topologies first, a process that is highly sensitive to observation errors. In this paper, we tackle the blind graph matching problem with unknown underlying graphs directly using observations of graph signals, which are generated from graph filters applied to graph signal excitations. We propose to construct sample covariance matrices from the observed signals and match the nodes based on the selected sample eigenvectors. Our analysis shows that the blind matching outcome converges to the result obtained with known graph topologies when the signal sampling size is large and the signal noise is small. Numerical results showcase the performance improvement of the proposed algorithm compared to matching two estimated underlying graphs learned from the graph signals.
Differentially Private Over-the-Air Federated Learning Over MIMO Fading Channels
Jun 19, 2023
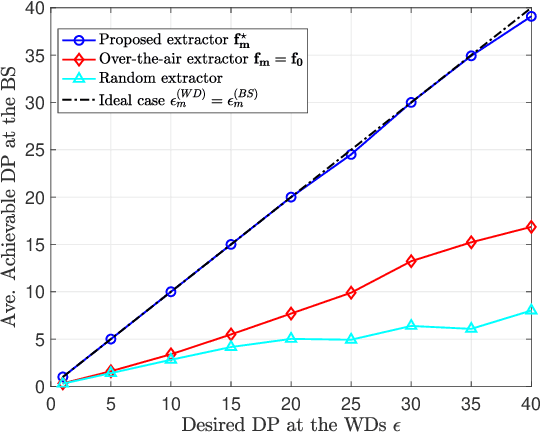
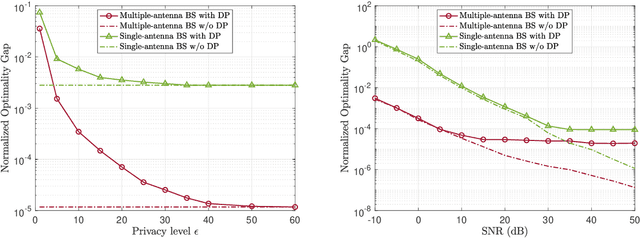
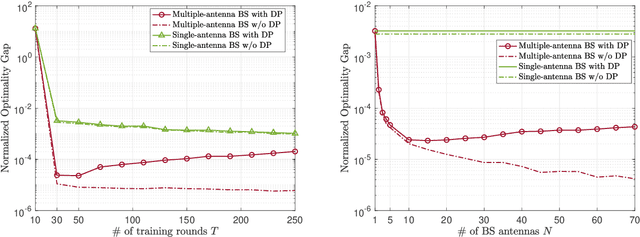
Federated learning (FL) enables edge devices to collaboratively train machine learning models, with model communication replacing direct data uploading. While over-the-air model aggregation improves communication efficiency, uploading models to an edge server over wireless networks can pose privacy risks. Differential privacy (DP) is a widely used quantitative technique to measure statistical data privacy in FL. Previous research has focused on over-the-air FL with a single-antenna server, leveraging communication noise to enhance user-level DP. This approach achieves the so-called "free DP" by controlling transmit power rather than introducing additional DP-preserving mechanisms at devices, such as adding artificial noise. In this paper, we study differentially private over-the-air FL over a multiple-input multiple-output (MIMO) fading channel. We show that FL model communication with a multiple-antenna server amplifies privacy leakage as the multiple-antenna server employs separate receive combining for model aggregation and information inference. Consequently, relying solely on communication noise, as done in the multiple-input single-output system, cannot meet high privacy requirements, and a device-side privacy-preserving mechanism is necessary for optimal DP design. We analyze the learning convergence and privacy loss of the studied FL system and propose a transceiver design algorithm based on alternating optimization. Numerical results demonstrate that the proposed method achieves a better privacy-learning trade-off compared to prior work.