 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHoi-To Wai
Clipped SGD Algorithms for Privacy Preserving Performative Prediction: Bias Amplification and Remedies
Apr 17, 2024
Clipped stochastic gradient descent (SGD) algorithms are among the most popular algorithms for privacy preserving optimization that reduces the leakage of users' identity in model training. This paper studies the convergence properties of these algorithms in a performative prediction setting, where the data distribution may shift due to the deployed prediction model. For example, the latter is caused by strategical users during the training of loan policy for banks. Our contributions are two-fold. First, we show that the straightforward implementation of a projected clipped SGD (PCSGD) algorithm may converge to a biased solution compared to the performative stable solution. We quantify the lower and upper bound for the magnitude of the bias and demonstrate a bias amplification phenomenon where the bias grows with the sensitivity of the data distribution. Second, we suggest two remedies to the bias amplification effect. The first one utilizes an optimal step size design for PCSGD that takes the privacy guarantee into account. The second one uses the recently proposed DiceSGD algorithm [Zhang et al., 2024]. We show that the latter can successfully remove the bias and converge to the performative stable solution. Numerical experiments verify our analysis.
EMC$^2$: Efficient MCMC Negative Sampling for Contrastive Learning with Global Convergence
Apr 16, 2024A key challenge in contrastive learning is to generate negative samples from a large sample set to contrast with positive samples, for learning better encoding of the data. These negative samples often follow a softmax distribution which are dynamically updated during the training process. However, sampling from this distribution is non-trivial due to the high computational costs in computing the partition function. In this paper, we propose an Efficient Markov Chain Monte Carlo negative sampling method for Contrastive learning (EMC$^2$). We follow the global contrastive learning loss as introduced in SogCLR, and propose EMC$^2$ which utilizes an adaptive Metropolis-Hastings subroutine to generate hardness-aware negative samples in an online fashion during the optimization. We prove that EMC$^2$ finds an $\mathcal{O}(1/\sqrt{T})$-stationary point of the global contrastive loss in $T$ iterations. Compared to prior works, EMC$^2$ is the first algorithm that exhibits global convergence (to stationarity) regardless of the choice of batch size while exhibiting low computation and memory cost. Numerical experiments validate that EMC$^2$ is effective with small batch training and achieves comparable or better performance than baseline algorithms. We report the results for pre-training image encoders on STL-10 and Imagenet-100.
Linear Speedup of Incremental Aggregated Gradient Methods on Streaming Data
Sep 10, 2023
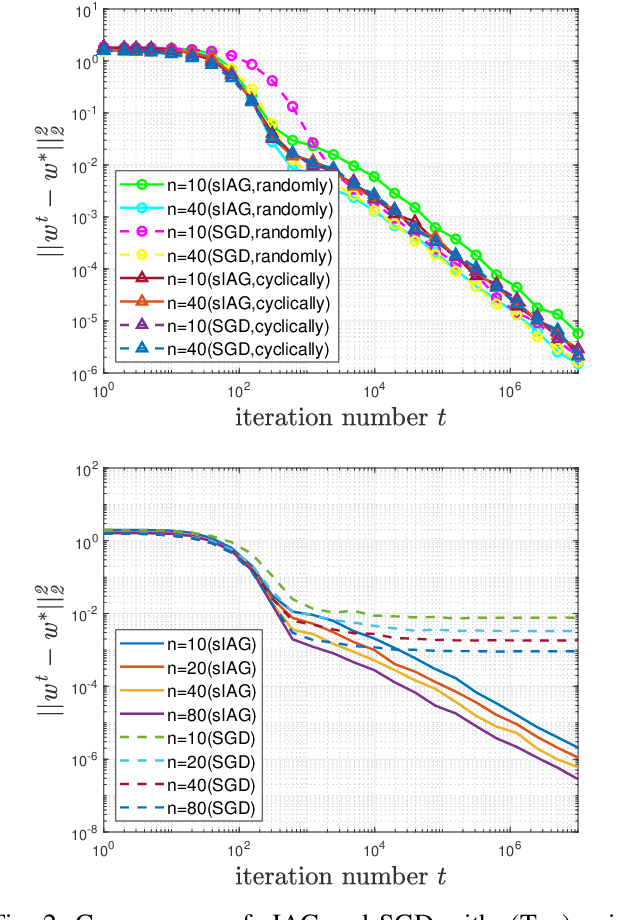
This paper considers a type of incremental aggregated gradient (IAG) method for large-scale distributed optimization. The IAG method is well suited for the parameter server architecture as the latter can easily aggregate potentially staled gradients contributed by workers. Although the convergence of IAG in the case of deterministic gradient is well known, there are only a few results for the case of its stochastic variant based on streaming data. Considering strongly convex optimization, this paper shows that the streaming IAG method achieves linear speedup when the workers are updating frequently enough, even if the data sample distribution across workers are heterogeneous. We show that the expected squared distance to optimal solution decays at O((1+T)/(nt)), where $n$ is the number of workers, t is the iteration number, and T/n is the update frequency of workers. Our analysis involves careful treatments of the conditional expectations with staled gradients and a recursive system with both delayed and noise terms, which are new to the analysis of IAG-type algorithms. Numerical results are presented to verify our findings.
* 8 pages, 3 figures
Blind Graph Matching Using Graph Signals
Jun 27, 2023
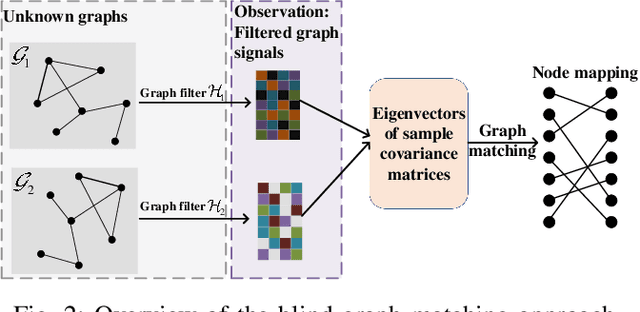
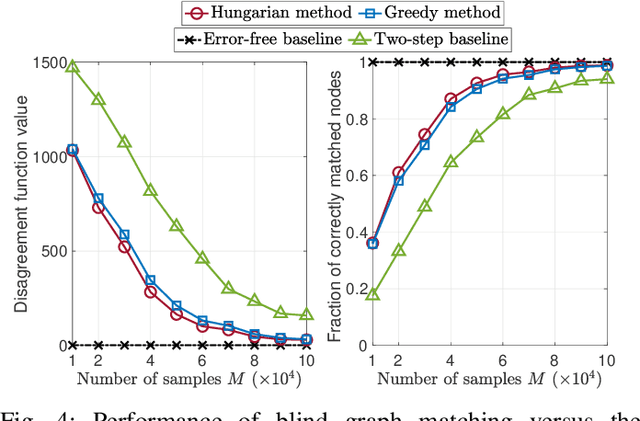
Classical graph matching aims to find a node correspondence between two unlabeled graphs of known topologies. This problem has a wide range of applications, from matching identities in social networks to identifying similar biological network functions across species. However, when the underlying graphs are unknown, the use of conventional graph matching methods requires inferring the graph topologies first, a process that is highly sensitive to observation errors. In this paper, we tackle the blind graph matching problem with unknown underlying graphs directly using observations of graph signals, which are generated from graph filters applied to graph signal excitations. We propose to construct sample covariance matrices from the observed signals and match the nodes based on the selected sample eigenvectors. Our analysis shows that the blind matching outcome converges to the result obtained with known graph topologies when the signal sampling size is large and the signal noise is small. Numerical results showcase the performance improvement of the proposed algorithm compared to matching two estimated underlying graphs learned from the graph signals.
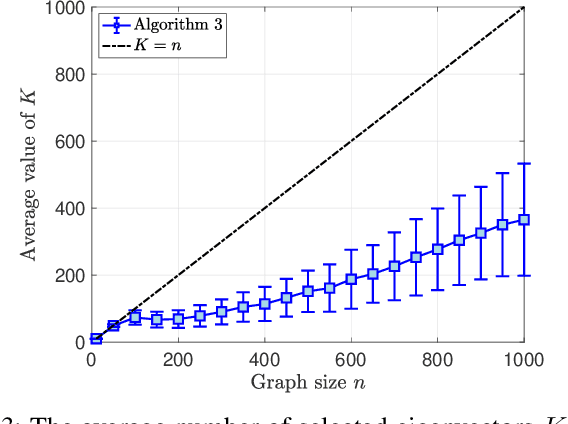
Detecting Low Pass Graph Signals via Spectral Pattern: Sampling Complexity and Applications
Jun 02, 2023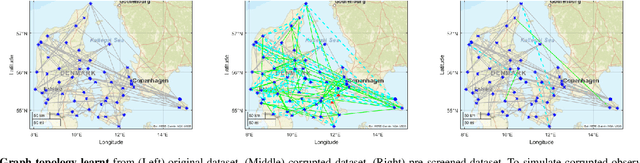
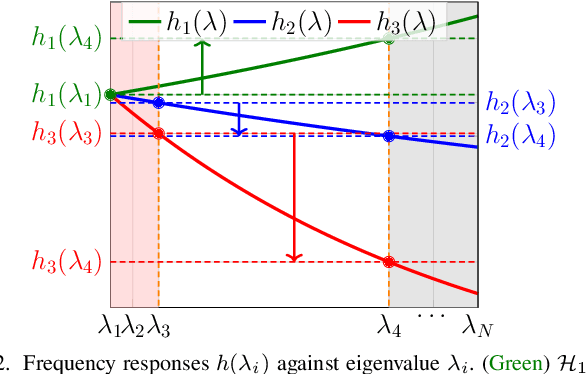
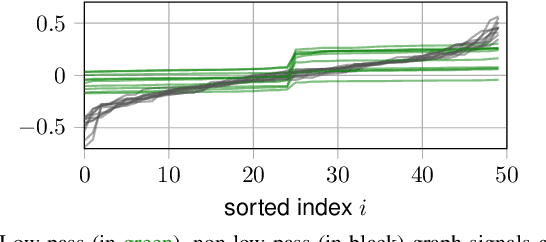
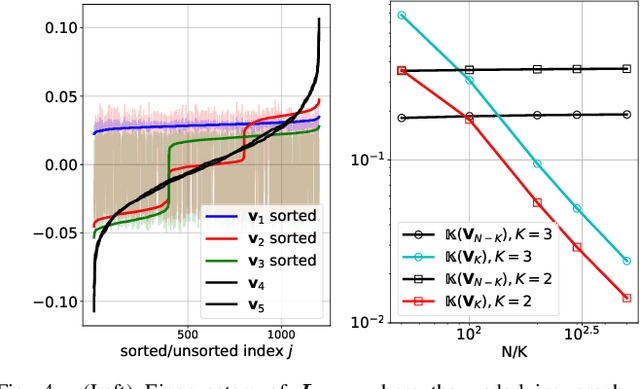
This paper proposes a blind detection problem for low pass graph signals. Without assuming knowledge of the graph topology in advance, we aim to detect if a set of graph signal observations are generated from a low pass graph filter. Our problem is motivated by the widely adopted assumption of low pass (a.k.a.~smooth) signals required by many existing works in graph signal processing (GSP), as well as the longstanding problem of network dynamics identification. Focusing on detecting low pass graph signals whose cutoff frequency coincides with the number of clusters present, our key idea is to develop blind detector leveraging the unique spectral pattern exhibited by low pass graph signals. We analyze the sample complexity of these detectors considering the effects of graph filter's properties, random delays. We show novel applications of the blind detector on robustifying graph learning, identifying antagonistic ties in opinion dynamics, and detecting anomalies in power systems. Numerical experiments validate our findings.
Clustering of Time-Varying Graphs Based on Temporal Label Smoothness
May 11, 2023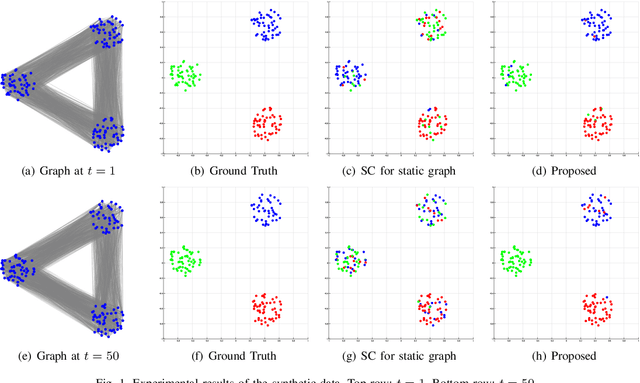
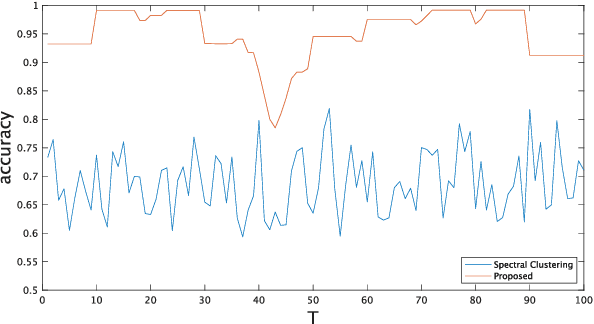
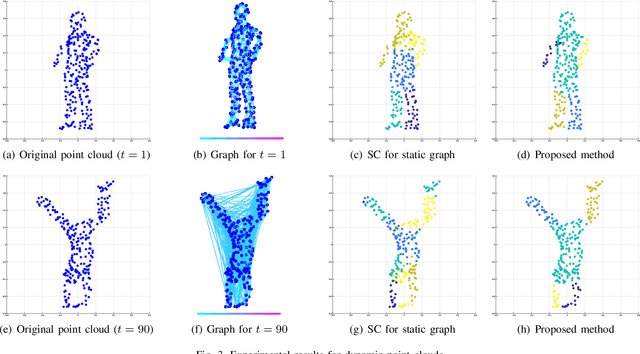
We propose a node clustering method for time-varying graphs based on the assumption that the cluster labels are changed smoothly over time. Clustering is one of the fundamental tasks in many science and engineering fields including signal processing, machine learning, and data mining. Although most existing studies focus on the clustering of nodes in static graphs, we often encounter time-varying graphs for time-series data, e.g., social networks, brain functional connectivity, and point clouds. In this paper, we formulate a node clustering of time-varying graphs as an optimization problem based on spectral clustering, with a smoothness constraint of the node labels. We solve the problem with a primal-dual splitting algorithm. Experiments on synthetic and real-world time-varying graphs are performed to validate the effectiveness of the proposed approach.
Stochastic Approximation Beyond Gradient for Signal Processing and Machine Learning
Feb 22, 2023
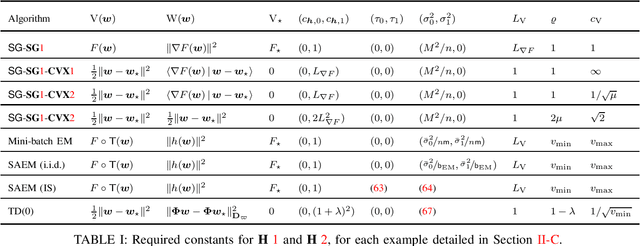

Stochastic approximation (SA) is a classical algorithm that has had since the early days a huge impact on signal processing, and nowadays on machine learning, due to the necessity to deal with a large amount of data observed with uncertainties. An exemplar special case of SA pertains to the popular stochastic (sub)gradient algorithm which is the working horse behind many important applications. A lesser-known fact is that the SA scheme also extends to non-stochastic-gradient algorithms such as compressed stochastic gradient, stochastic expectation-maximization, and a number of reinforcement learning algorithms. The aim of this article is to overview and introduce the non-stochastic-gradient perspectives of SA to the signal processing and machine learning audiences through presenting a design guideline of SA algorithms backed by theories. Our central theme is to propose a general framework that unifies existing theories of SA, including its non-asymptotic and asymptotic convergence results, and demonstrate their applications on popular non-stochastic-gradient algorithms. We build our analysis framework based on classes of Lyapunov functions that satisfy a variety of mild conditions. We draw connections between non-stochastic-gradient algorithms and scenarios when the Lyapunov function is smooth, convex, or strongly convex. Using the said framework, we illustrate the convergence properties of the non-stochastic-gradient algorithms using concrete examples. Extensions to the emerging variance reduction techniques for improved sample complexity will also be discussed.
Product Graph Learning from Multi-attribute Graph Signals with Inter-layer Coupling
Nov 02, 2022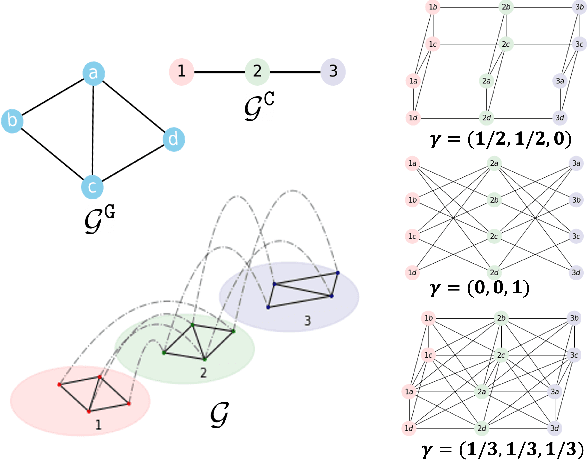
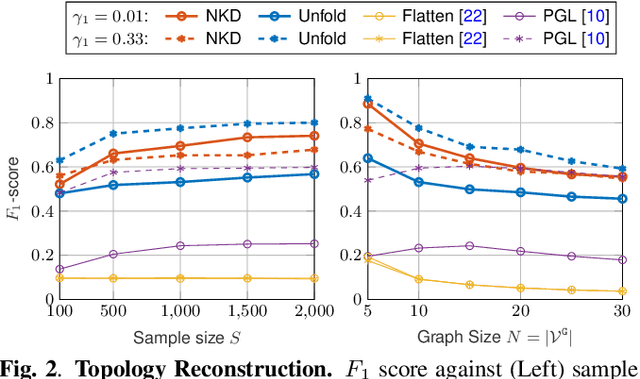
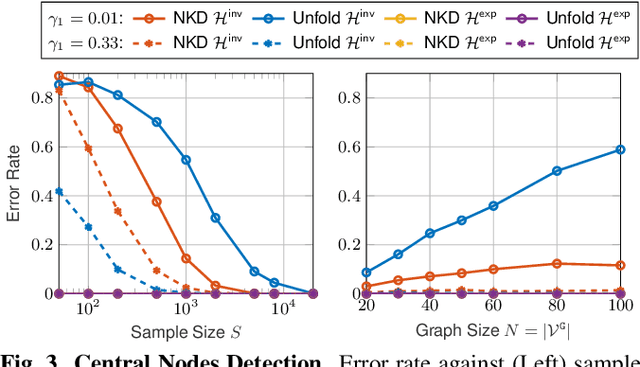
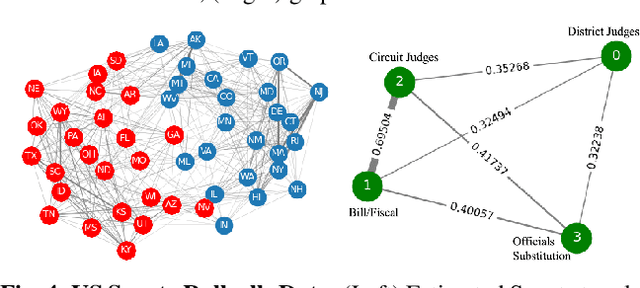
This paper considers learning a product graph from multi-attribute graph signals. Our work is motivated by the widespread presence of multilayer networks that feature interactions within and across graph layers. Focusing on a product graph setting with homogeneous layers, we propose a bivariate polynomial graph filter model. We then consider the topology inference problems thru adapting existing spectral methods. We propose two solutions for the required spectral estimation step: a simplified solution via unfolding the multi-attribute data into matrices, and an exact solution via nearest Kronecker product decomposition (NKD). Interestingly, we show that strong inter-layer coupling can degrade the performance of the unfolding solution while the NKD solution is robust to inter-layer coupling effects. Numerical experiments show efficacy of our methods.
Online Inference for Mixture Model of Streaming Graph Signals with Non-White Excitation
Jul 28, 2022
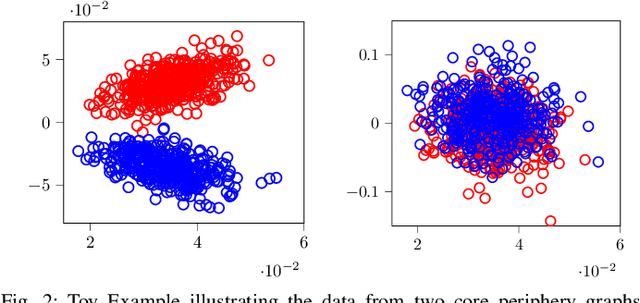
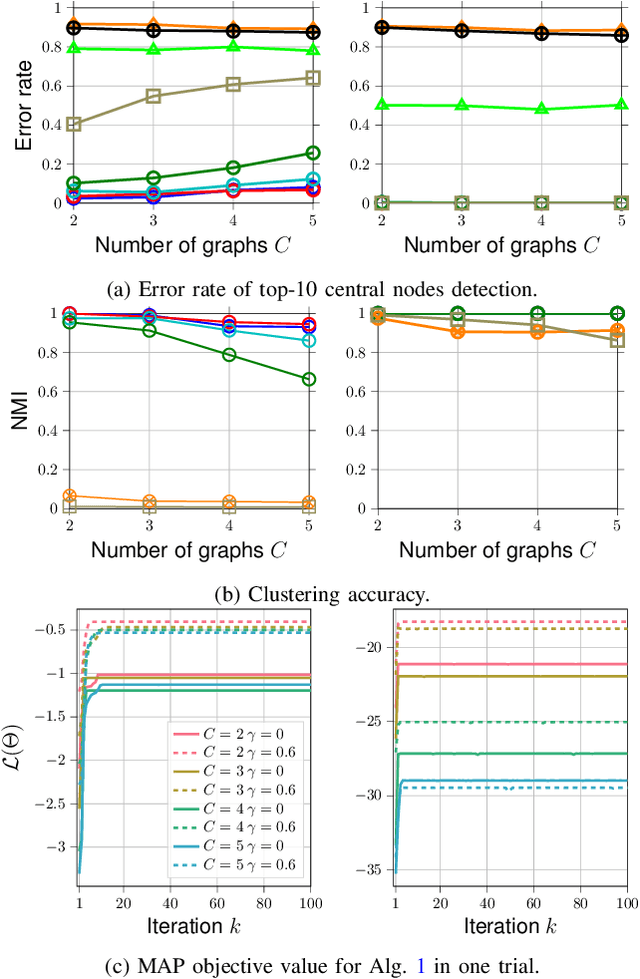
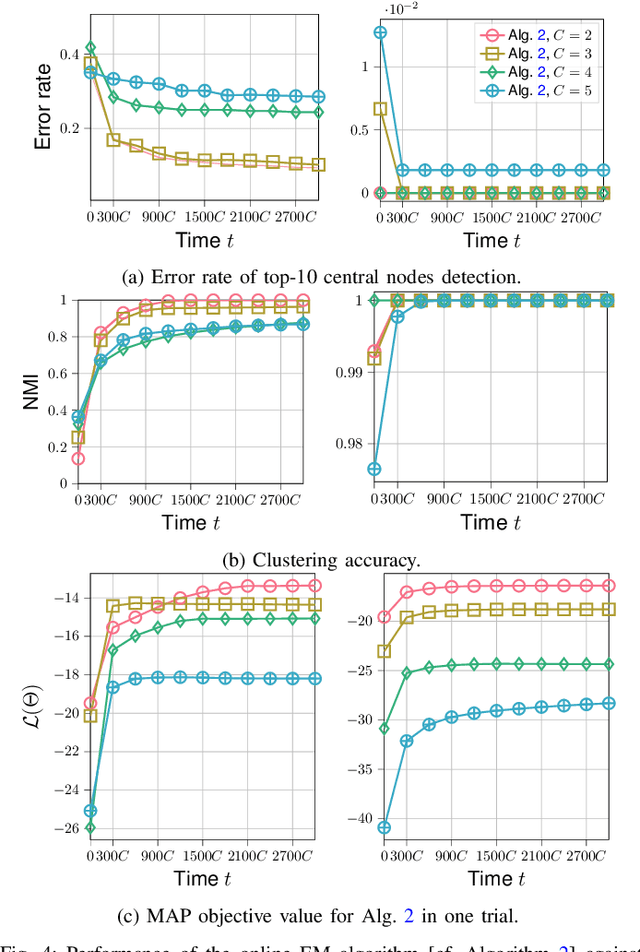
This paper considers a joint multi-graph inference and clustering problem for simultaneous inference of node centrality and association of graph signals with their graphs. We study a mixture model of filtered low pass graph signals with possibly non-white and low-rank excitation. While the mixture model is motivated from practical scenarios, it presents significant challenges to prior graph learning methods. As a remedy, we consider an inference problem focusing on the node centrality of graphs. We design an expectation-maximization (EM) algorithm with a unique low-rank plus sparse prior derived from low pass signal property. We propose a novel online EM algorithm for inference from streaming data. As an example, we extend the online algorithm to detect if the signals are generated from an abnormal graph. We show that the proposed algorithms converge to a stationary point of the maximum-a-posterior (MAP) problem. Numerical experiments support our analysis.
DoCoM-SGT: Doubly Compressed Momentum-assisted Stochastic Gradient Tracking Algorithm for Communication Efficient Decentralized Learning
Feb 01, 2022This paper proposes the Doubly Compressed Momentum-assisted Stochastic Gradient Tracking algorithm (DoCoM-SGT) for communication efficient decentralized learning. DoCoM-SGT utilizes two compression steps per communication round as the algorithm tracks simultaneously the averaged iterate and stochastic gradient. Furthermore, DoCoM-SGT incorporates a momentum based technique for reducing variances in the gradient estimates. We show that DoCoM-SGT finds a solution $\bar{\theta}$ in $T$ iterations satisfying $\mathbb{E} [ \| \nabla f(\bar{\theta}) \|^2 ] = {\cal O}( 1 / T^{2/3} )$ for non-convex objective functions; and we provide competitive convergence rate guarantees for other function classes. Numerical experiments on synthetic and real datasets validate the efficacy of our algorithm.