 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMichal Yemini
Clipped SGD Algorithms for Privacy Preserving Performative Prediction: Bias Amplification and Remedies
Apr 17, 2024
Clipped stochastic gradient descent (SGD) algorithms are among the most popular algorithms for privacy preserving optimization that reduces the leakage of users' identity in model training. This paper studies the convergence properties of these algorithms in a performative prediction setting, where the data distribution may shift due to the deployed prediction model. For example, the latter is caused by strategical users during the training of loan policy for banks. Our contributions are two-fold. First, we show that the straightforward implementation of a projected clipped SGD (PCSGD) algorithm may converge to a biased solution compared to the performative stable solution. We quantify the lower and upper bound for the magnitude of the bias and demonstrate a bias amplification phenomenon where the bias grows with the sensitivity of the data distribution. Second, we suggest two remedies to the bias amplification effect. The first one utilizes an optimal step size design for PCSGD that takes the privacy guarantee into account. The second one uses the recently proposed DiceSGD algorithm [Zhang et al., 2024]. We show that the latter can successfully remove the bias and converge to the performative stable solution. Numerical experiments verify our analysis.
The Role of Confidence for Trust-based Resilient Consensus (Extended Version)
Apr 11, 2024We consider a multi-agent system where agents aim to achieve a consensus despite interactions with malicious agents that communicate misleading information. Physical channels supporting communication in cyberphysical systems offer attractive opportunities to detect malicious agents, nevertheless, trustworthiness indications coming from the channel are subject to uncertainty and need to be treated with this in mind. We propose a resilient consensus protocol that incorporates trust observations from the channel and weighs them with a parameter that accounts for how confident an agent is regarding its understanding of the legitimacy of other agents in the network, with no need for the initial observation window $T_0$ that has been utilized in previous works. Analytical and numerical results show that (i) our protocol achieves a resilient consensus in the presence of malicious agents and (ii) the steady-state deviation from nominal consensus can be minimized by a suitable choice of the confidence parameter that depends on the statistics of trust observations.
How Physicality Enables Trust: A New Era of Trust-Centered Cyberphysical Systems
Nov 13, 2023Multi-agent cyberphysical systems enable new capabilities in efficiency, resilience, and security. The unique characteristics of these systems prompt a reevaluation of their security concepts, including their vulnerabilities, and mechanisms to mitigate these vulnerabilities. This survey paper examines how advancement in wireless networking, coupled with the sensing and computing in cyberphysical systems, can foster novel security capabilities. This study delves into three main themes related to securing multi-agent cyberphysical systems. First, we discuss the threats that are particularly relevant to multi-agent cyberphysical systems given the potential lack of trust between agents. Second, we present prospects for sensing, contextual awareness, and authentication, enabling the inference and measurement of ``inter-agent trust" for these systems. Third, we elaborate on the application of quantifiable trust notions to enable ``resilient coordination," where ``resilient" signifies sustained functionality amid attacks on multiagent cyberphysical systems. We refer to the capability of cyberphysical systems to self-organize, and coordinate to achieve a task as autonomy. This survey unveils the cyberphysical character of future interconnected systems as a pivotal catalyst for realizing robust, trust-centered autonomy in tomorrow's world.
Exploiting Trust for Resilient Hypothesis Testing with Malicious Robots (evolved version)
Mar 07, 2023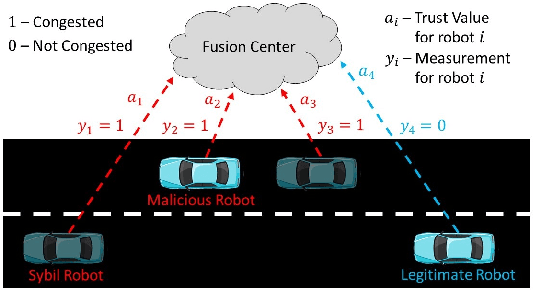

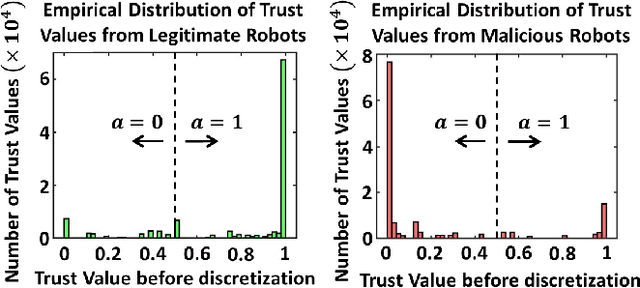
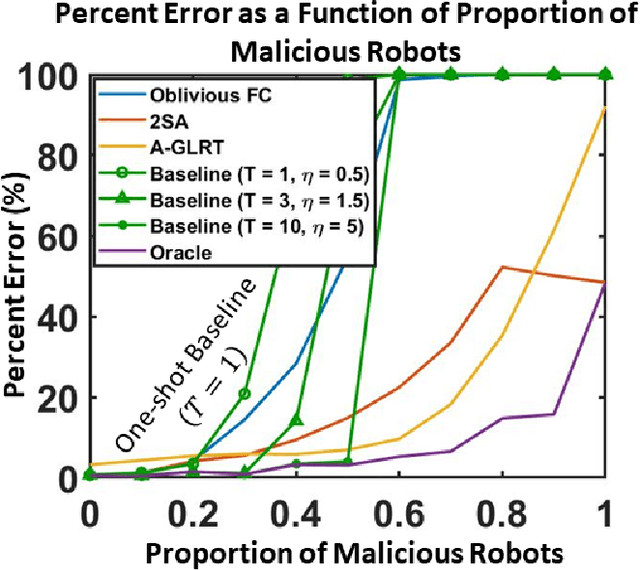
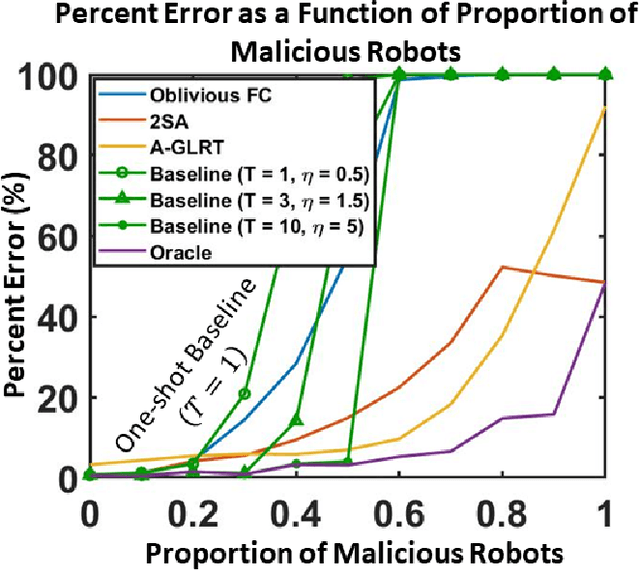
We develop a resilient binary hypothesis testing framework for decision making in adversarial multi-robot crowdsensing tasks. This framework exploits stochastic trust observations between robots to arrive at tractable, resilient decision making at a centralized Fusion Center (FC) even when i) there exist malicious robots in the network and their number may be larger than the number of legitimate robots, and ii) the FC uses one-shot noisy measurements from all robots. We derive two algorithms to achieve this. The first is the Two Stage Approach (2SA) that estimates the legitimacy of robots based on received trust observations, and provably minimizes the probability of detection error in the worst-case malicious attack. Here, the proportion of malicious robots is known but arbitrary. For the case of an unknown proportion of malicious robots, we develop the Adversarial Generalized Likelihood Ratio Test (A-GLRT) that uses both the reported robot measurements and trust observations to estimate the trustworthiness of robots, their reporting strategy, and the correct hypothesis simultaneously. We exploit special problem structure to show that this approach remains computationally tractable despite several unknown problem parameters. We deploy both algorithms in a hardware experiment where a group of robots conducts crowdsensing of traffic conditions on a mock-up road network similar in spirit to Google Maps, subject to a Sybil attack. We extract the trust observations for each robot from actual communication signals which provide statistical information on the uniqueness of the sender. We show that even when the malicious robots are in the majority, the FC can reduce the probability of detection error to 30.5% and 29% for the 2SA and the A-GLRT respectively.
Collaborative Mean Estimation over Intermittently Connected Networks with Peer-To-Peer Privacy
Feb 28, 2023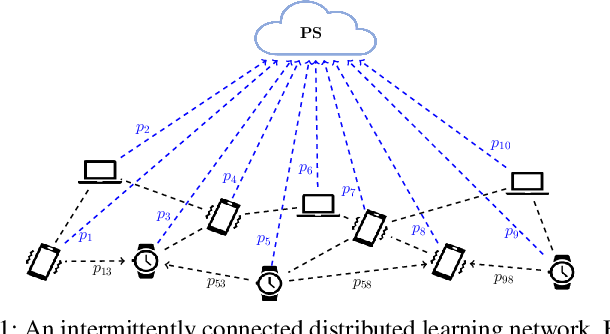
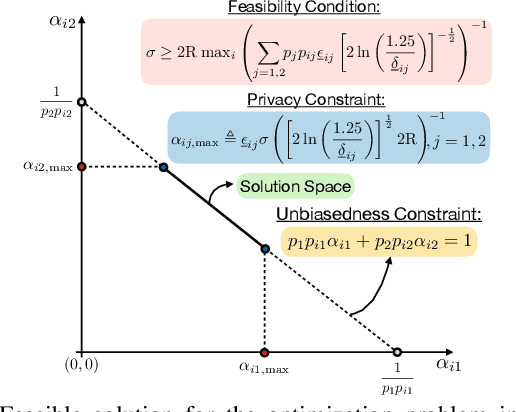
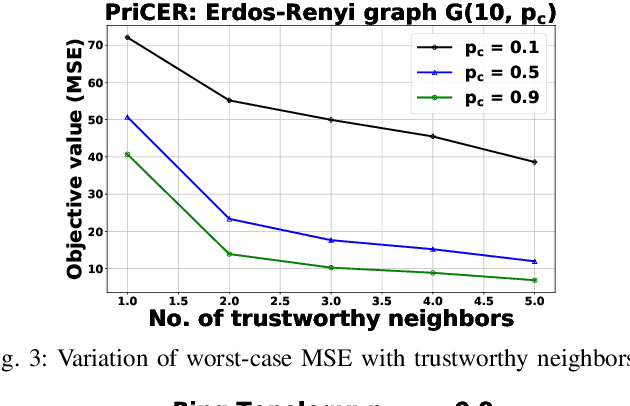
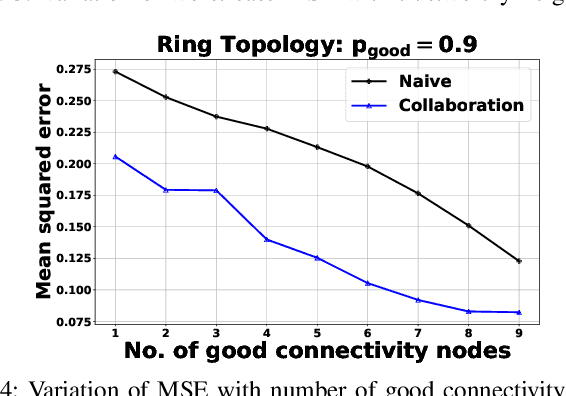
This work considers the problem of Distributed Mean Estimation (DME) over networks with intermittent connectivity, where the goal is to learn a global statistic over the data samples localized across distributed nodes with the help of a central server. To mitigate the impact of intermittent links, nodes can collaborate with their neighbors to compute local consensus which they forward to the central server. In such a setup, the communications between any pair of nodes must satisfy local differential privacy constraints. We study the tradeoff between collaborative relaying and privacy leakage due to the additional data sharing among nodes and, subsequently, propose a novel differentially private collaborative algorithm for DME to achieve the optimal tradeoff. Finally, we present numerical simulations to substantiate our theoretical findings.
Resilient Distributed Optimization for Multi-Agent Cyberphysical Systems
Dec 05, 2022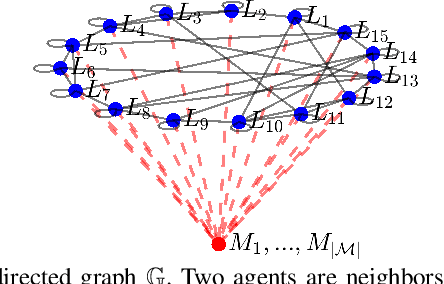
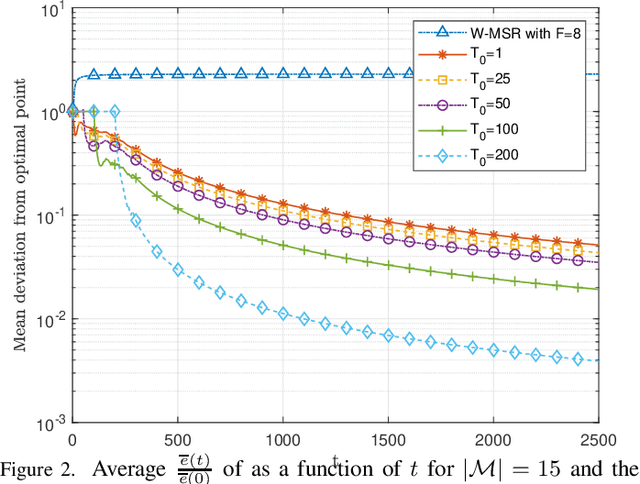
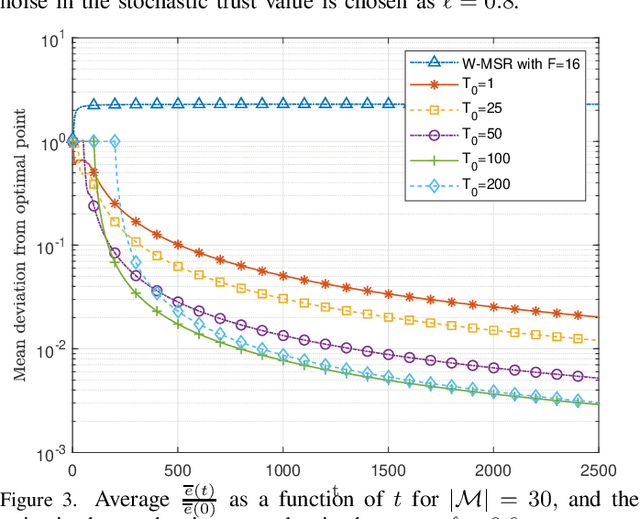
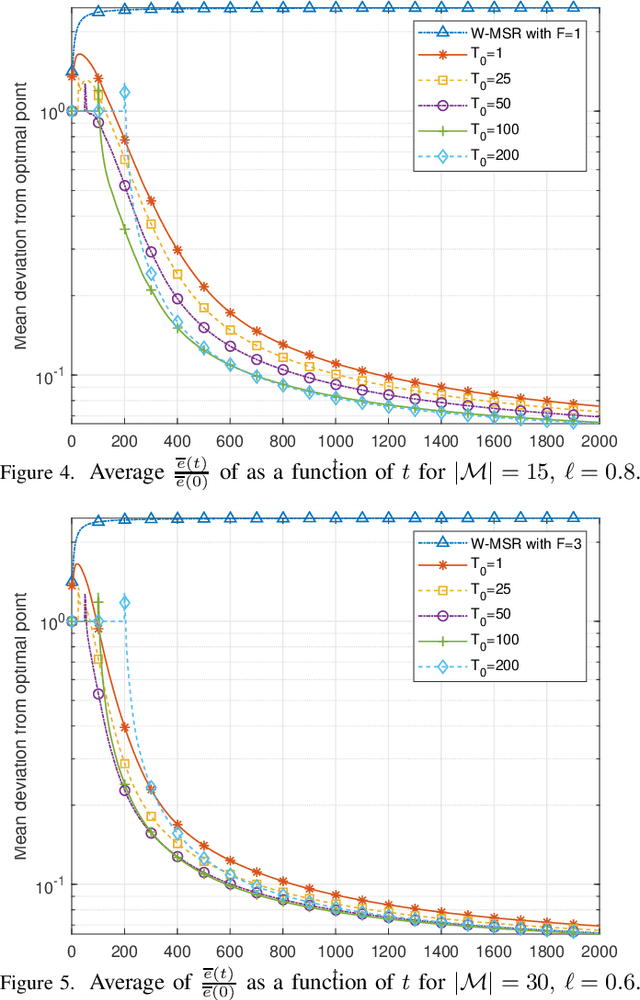
Enhancing resilience in distributed networks in the face of malicious agents is an important problem for which many key theoretical results and applications require further development and characterization. This work focuses on the problem of distributed optimization in multi-agent cyberphysical systems, where a legitimate agent's dynamic is influenced both by the values it receives from potentially malicious neighboring agents, and by its own self-serving target function. We develop a new algorithmic and analytical framework to achieve resilience for the class of problems where stochastic values of trust between agents exist and can be exploited. In this case we show that convergence to the true global optimal point can be recovered, both in mean and almost surely, even in the presence of malicious agents. Furthermore, we provide expected convergence rate guarantees in the form of upper bounds on the expected squared distance to the optimal value. Finally, we present numerical results that validate the analytical convergence guarantees we present in this paper even when the malicious agents compose the majority of agents in the network.
Exploiting Trust for Resilient Hypothesis Testing with Malicious Robots
Sep 25, 2022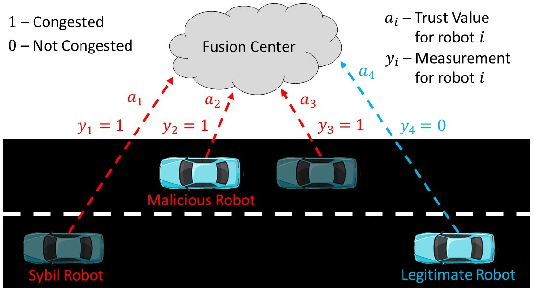

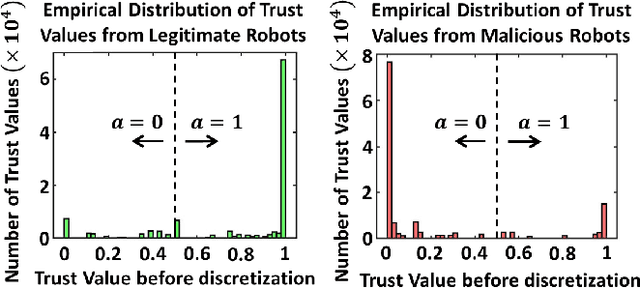
We develop a resilient binary hypothesis testing framework for decision making in adversarial multi-robot crowdsensing tasks. This framework exploits stochastic trust observations between robots to arrive at tractable, resilient decision making at a centralized Fusion Center (FC) even when i) there exist malicious robots in the network and their number may be larger than the number of legitimate robots, and ii) the FC uses one-shot noisy measurements from all robots. We derive two algorithms to achieve this. The first is the Two Stage Approach (2SA) that estimates the legitimacy of robots based on received trust observations, and provably minimizes the probability of detection error in the worst-case malicious attack. Here, the proportion of malicious robots is known but arbitrary. For the case of an unknown proportion of malicious robots, we develop the Adversarial Generalized Likelihood Ratio Test (A-GLRT) that uses both the reported robot measurements and trust observations to estimate the trustworthiness of robots, their reporting strategy, and the correct hypothesis simultaneously. We exploit special problem structure to show that this approach remains computationally tractable despite several unknown problem parameters. We deploy both algorithms in a hardware experiment where a group of robots conducts crowdsensing of traffic conditions on a mock-up road network similar in spirit to Google Maps, subject to a Sybil attack. We extract the trust observations for each robot from actual communication signals which provide statistical information on the uniqueness of the sender. We show that even when the malicious robots are in the majority, the FC can reduce the probability of detection error to 30.5% and 29% for the 2SA and the A-GLRT respectively.
Multi-Armed Bandits with Self-Information Rewards
Sep 06, 2022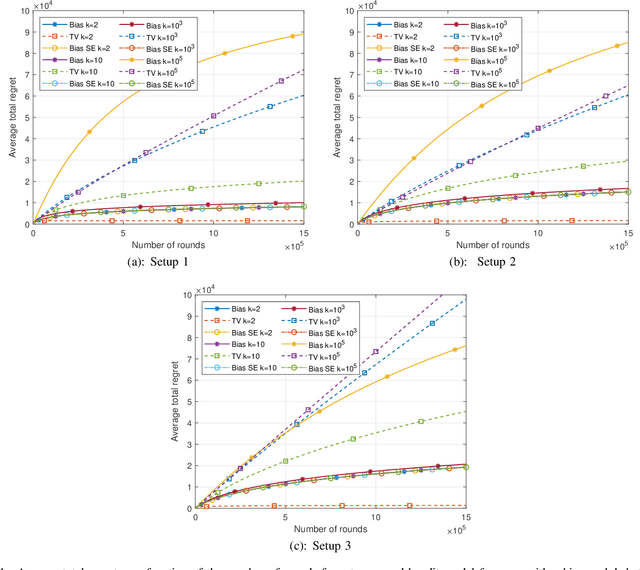
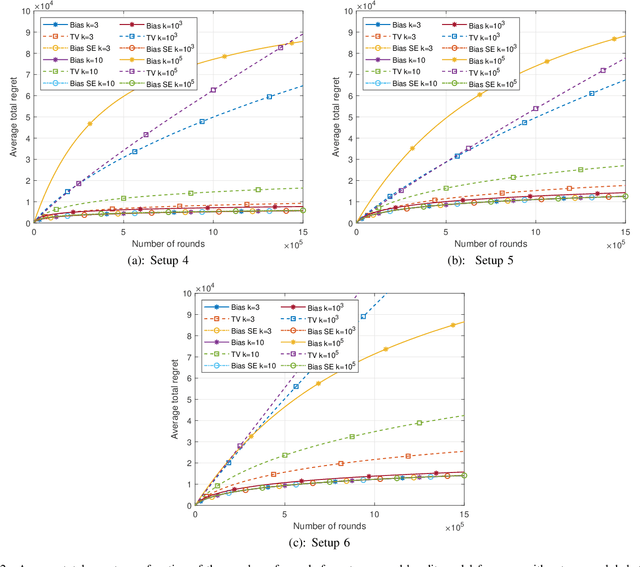
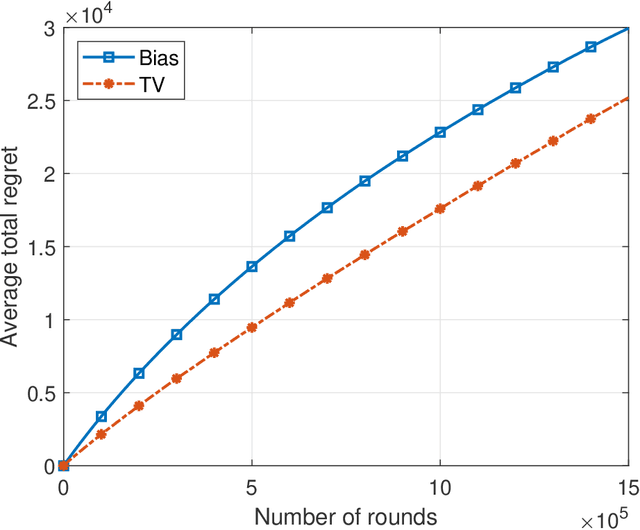
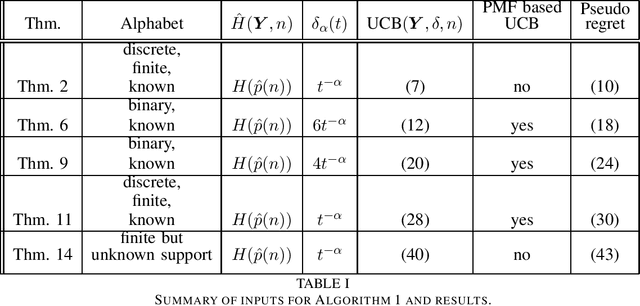
This paper introduces the informational multi-armed bandit (IMAB) model in which at each round, a player chooses an arm, observes a symbol, and receives an unobserved reward in the form of the symbol's self-information. Thus, the expected reward of an arm is the Shannon entropy of the probability mass function of the source that generates its symbols. The player aims to maximize the expected total reward associated with the entropy values of the arms played. Under the assumption that the alphabet size is known, two UCB-based algorithms are proposed for the IMAB model which consider the biases of the plug-in entropy estimator. The first algorithm optimistically corrects the bias term in the entropy estimation. The second algorithm relies on data-dependent confidence intervals that adapt to sources with small entropy values. Performance guarantees are provided by upper bounding the expected regret of each of the algorithms. Furthermore, in the Bernoulli case, the asymptotic behavior of these algorithms is compared to the Lai-Robbins lower bound for the pseudo regret. Additionally, under the assumption that the \textit{exact} alphabet size is unknown, and instead the player only knows a loose upper bound on it, a UCB-based algorithm is proposed, in which the player aims to reduce the regret caused by the unknown alphabet size in a finite time regime. Numerical results illustrating the expected regret of the algorithms presented in the paper are provided.
Semi-Decentralized Federated Learning with Collaborative Relaying
May 23, 2022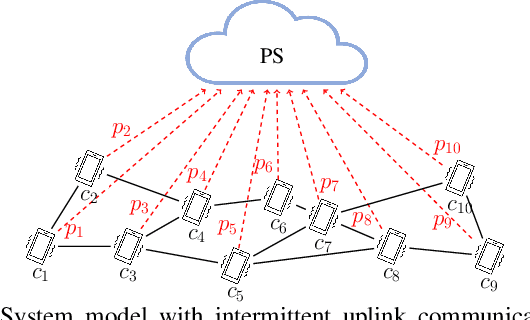
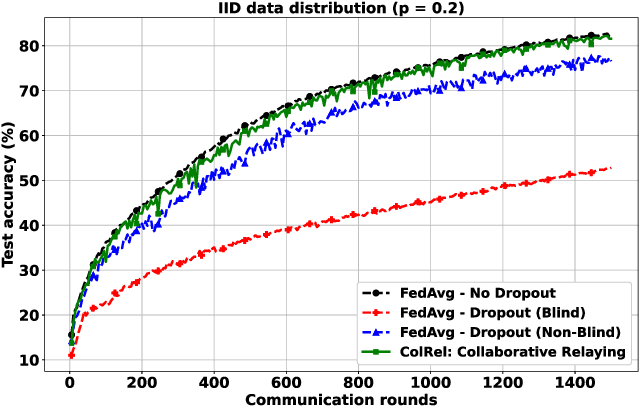
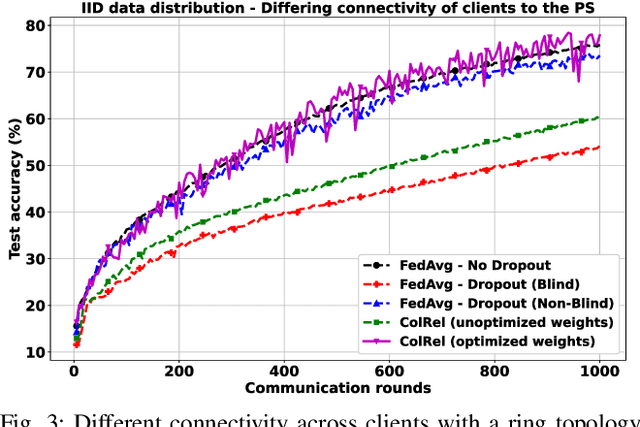
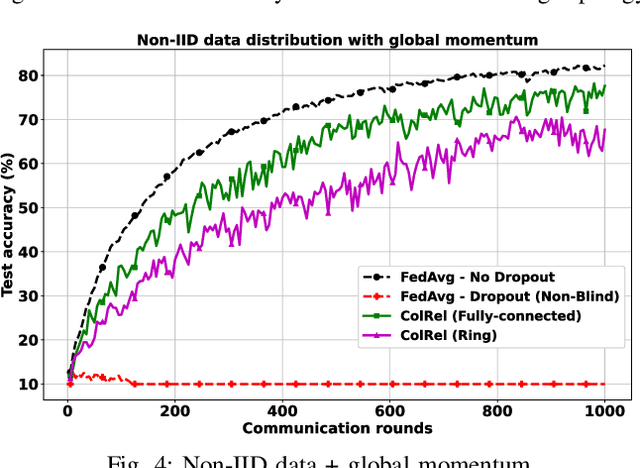
We present a semi-decentralized federated learning algorithm wherein clients collaborate by relaying their neighbors' local updates to a central parameter server (PS). At every communication round to the PS, each client computes a local consensus of the updates from its neighboring clients and eventually transmits a weighted average of its own update and those of its neighbors to the PS. We appropriately optimize these averaging weights to ensure that the global update at the PS is unbiased and to reduce the variance of the global update at the PS, consequently improving the rate of convergence. Numerical simulations substantiate our theoretical claims and demonstrate settings with intermittent connectivity between the clients and the PS, where our proposed algorithm shows an improved convergence rate and accuracy in comparison with the federated averaging algorithm.
Restless Multi-Armed Bandits under Exogenous Global Markov Process
Feb 28, 2022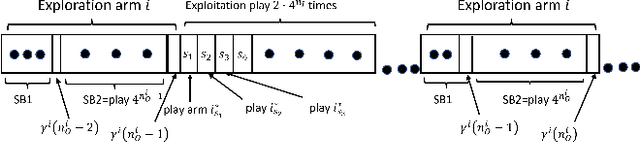
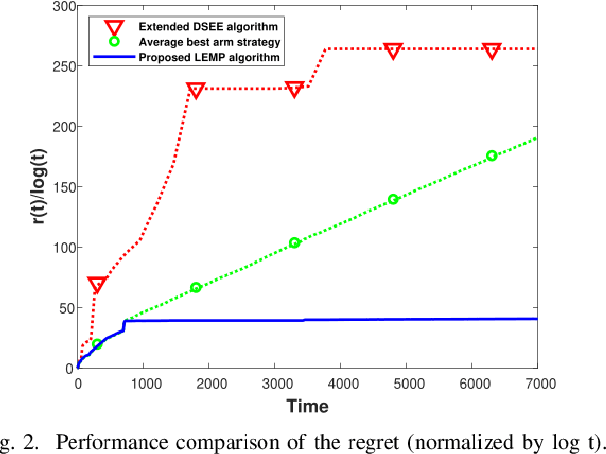
We consider an extension to the restless multi-armed bandit (RMAB) problem with unknown arm dynamics, where an unknown exogenous global Markov process governs the rewards distribution of each arm. Under each global state, the rewards process of each arm evolves according to an unknown Markovian rule, which is non-identical among different arms. At each time, a player chooses an arm out of N arms to play, and receives a random reward from a finite set of reward states. The arms are restless, that is, their local state evolves regardless of the player's actions. The objective is an arm-selection policy that minimizes the regret, defined as the reward loss with respect to a player that knows the dynamics of the problem, and plays at each time t the arm that maximizes the expected immediate value. We develop the Learning under Exogenous Markov Process (LEMP) algorithm, that achieves a logarithmic regret order with time, and a finite-sample bound on the regret is established. Simulation results support the theoretical study and demonstrate strong performances of LEMP.