 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDavid Junhao Zhang
DragAnything: Motion Control for Anything using Entity Representation
Mar 15, 2024
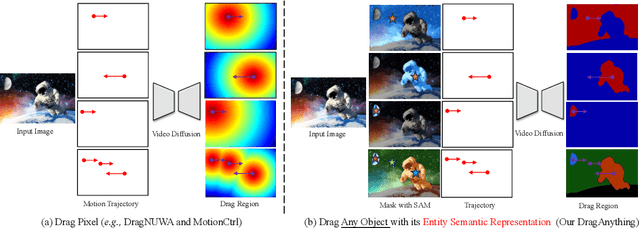

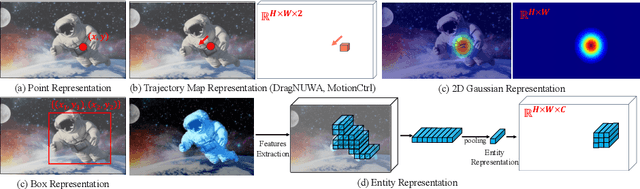

We introduce DragAnything, which utilizes a entity representation to achieve motion control for any object in controllable video generation. Comparison to existing motion control methods, DragAnything offers several advantages. Firstly, trajectory-based is more userfriendly for interaction, when acquiring other guidance signals (e.g., masks, depth maps) is labor-intensive. Users only need to draw a line (trajectory) during interaction. Secondly, our entity representation serves as an open-domain embedding capable of representing any object, enabling the control of motion for diverse entities, including background. Lastly, our entity representation allows simultaneous and distinct motion control for multiple objects. Extensive experiments demonstrate that our DragAnything achieves state-of-the-art performance for FVD, FID, and User Study, particularly in terms of object motion control, where our method surpasses the previous methods (e.g., DragNUWA) by 26% in human voting.
Towards A Better Metric for Text-to-Video Generation
Jan 15, 2024Generative models have demonstrated remarkable capability in synthesizing high-quality text, images, and videos. For video generation, contemporary text-to-video models exhibit impressive capabilities, crafting visually stunning videos. Nonetheless, evaluating such videos poses significant challenges. Current research predominantly employs automated metrics such as FVD, IS, and CLIP Score. However, these metrics provide an incomplete analysis, particularly in the temporal assessment of video content, thus rendering them unreliable indicators of true video quality. Furthermore, while user studies have the potential to reflect human perception accurately, they are hampered by their time-intensive and laborious nature, with outcomes that are often tainted by subjective bias. In this paper, we investigate the limitations inherent in existing metrics and introduce a novel evaluation pipeline, the Text-to-Video Score (T2VScore). This metric integrates two pivotal criteria: (1) Text-Video Alignment, which scrutinizes the fidelity of the video in representing the given text description, and (2) Video Quality, which evaluates the video's overall production caliber with a mixture of experts. Moreover, to evaluate the proposed metrics and facilitate future improvements on them, we present the TVGE dataset, collecting human judgements of 2,543 text-to-video generated videos on the two criteria. Experiments on the TVGE dataset demonstrate the superiority of the proposed T2VScore on offering a better metric for text-to-video generation.
Moonshot: Towards Controllable Video Generation and Editing with Multimodal Conditions
Jan 03, 2024Most existing video diffusion models (VDMs) are limited to mere text conditions. Thereby, they are usually lacking in control over visual appearance and geometry structure of the generated videos. This work presents Moonshot, a new video generation model that conditions simultaneously on multimodal inputs of image and text. The model builts upon a core module, called multimodal video block (MVB), which consists of conventional spatialtemporal layers for representing video features, and a decoupled cross-attention layer to address image and text inputs for appearance conditioning. In addition, we carefully design the model architecture such that it can optionally integrate with pre-trained image ControlNet modules for geometry visual conditions, without needing of extra training overhead as opposed to prior methods. Experiments show that with versatile multimodal conditioning mechanisms, Moonshot demonstrates significant improvement on visual quality and temporal consistency compared to existing models. In addition, the model can be easily repurposed for a variety of generative applications, such as personalized video generation, image animation and video editing, unveiling its potential to serve as a fundamental architecture for controllable video generation. Models will be made public on https://github.com/salesforce/LAVIS.
VideoSwap: Customized Video Subject Swapping with Interactive Semantic Point Correspondence
Dec 05, 2023Current diffusion-based video editing primarily focuses on structure-preserved editing by utilizing various dense correspondences to ensure temporal consistency and motion alignment. However, these approaches are often ineffective when the target edit involves a shape change. To embark on video editing with shape change, we explore customized video subject swapping in this work, where we aim to replace the main subject in a source video with a target subject having a distinct identity and potentially different shape. In contrast to previous methods that rely on dense correspondences, we introduce the VideoSwap framework that exploits semantic point correspondences, inspired by our observation that only a small number of semantic points are necessary to align the subject's motion trajectory and modify its shape. We also introduce various user-point interactions (\eg, removing points and dragging points) to address various semantic point correspondence. Extensive experiments demonstrate state-of-the-art video subject swapping results across a variety of real-world videos.
MotionDirector: Motion Customization of Text-to-Video Diffusion Models
Oct 12, 2023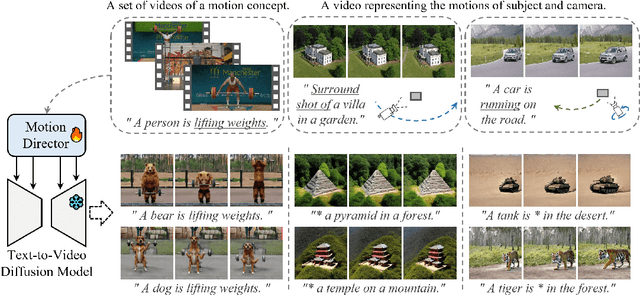
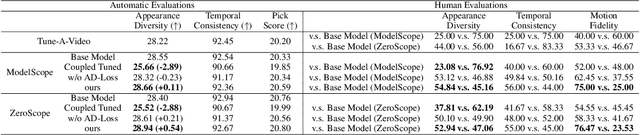


Large-scale pre-trained diffusion models have exhibited remarkable capabilities in diverse video generations. Given a set of video clips of the same motion concept, the task of Motion Customization is to adapt existing text-to-video diffusion models to generate videos with this motion. For example, generating a video with a car moving in a prescribed manner under specific camera movements to make a movie, or a video illustrating how a bear would lift weights to inspire creators. Adaptation methods have been developed for customizing appearance like subject or style, yet unexplored for motion. It is straightforward to extend mainstream adaption methods for motion customization, including full model tuning, parameter-efficient tuning of additional layers, and Low-Rank Adaptions (LoRAs). However, the motion concept learned by these methods is often coupled with the limited appearances in the training videos, making it difficult to generalize the customized motion to other appearances. To overcome this challenge, we propose MotionDirector, with a dual-path LoRAs architecture to decouple the learning of appearance and motion. Further, we design a novel appearance-debiased temporal loss to mitigate the influence of appearance on the temporal training objective. Experimental results show the proposed method can generate videos of diverse appearances for the customized motions. Our method also supports various downstream applications, such as the mixing of different videos with their appearance and motion respectively, and animating a single image with customized motions. Our code and model weights will be released.
Show-1: Marrying Pixel and Latent Diffusion Models for Text-to-Video Generation
Sep 27, 2023



Significant advancements have been achieved in the realm of large-scale pre-trained text-to-video Diffusion Models (VDMs). However, previous methods either rely solely on pixel-based VDMs, which come with high computational costs, or on latent-based VDMs, which often struggle with precise text-video alignment. In this paper, we are the first to propose a hybrid model, dubbed as Show-1, which marries pixel-based and latent-based VDMs for text-to-video generation. Our model first uses pixel-based VDMs to produce a low-resolution video of strong text-video correlation. After that, we propose a novel expert translation method that employs the latent-based VDMs to further upsample the low-resolution video to high resolution. Compared to latent VDMs, Show-1 can produce high-quality videos of precise text-video alignment; Compared to pixel VDMs, Show-1 is much more efficient (GPU memory usage during inference is 15G vs 72G). We also validate our model on standard video generation benchmarks. Our code and model weights are publicly available at \url{https://github.com/showlab/Show-1}.
Dataset Condensation via Generative Model
Sep 14, 2023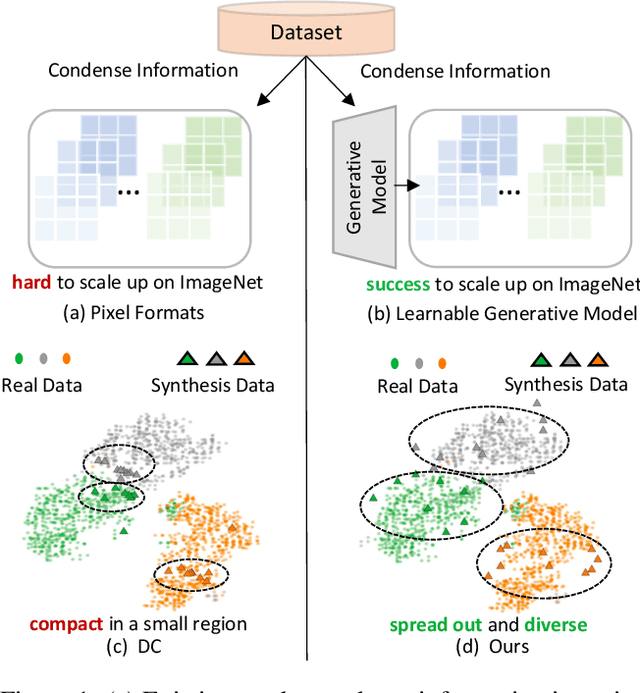

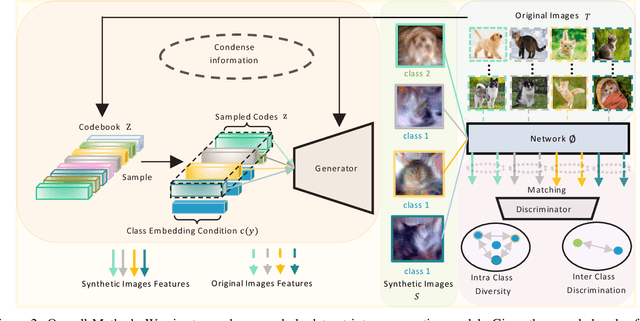
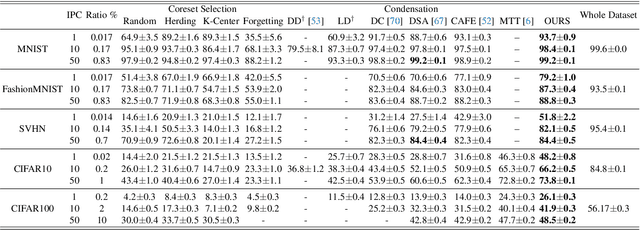
Dataset condensation aims to condense a large dataset with a lot of training samples into a small set. Previous methods usually condense the dataset into the pixels format. However, it suffers from slow optimization speed and large number of parameters to be optimized. When increasing image resolutions and classes, the number of learnable parameters grows accordingly, prohibiting condensation methods from scaling up to large datasets with diverse classes. Moreover, the relations among condensed samples have been neglected and hence the feature distribution of condensed samples is often not diverse. To solve these problems, we propose to condense the dataset into another format, a generative model. Such a novel format allows for the condensation of large datasets because the size of the generative model remains relatively stable as the number of classes or image resolution increases. Furthermore, an intra-class and an inter-class loss are proposed to model the relation of condensed samples. Intra-class loss aims to create more diverse samples for each class by pushing each sample away from the others of the same class. Meanwhile, inter-class loss increases the discriminability of samples by widening the gap between the centers of different classes. Extensive comparisons with state-of-the-art methods and our ablation studies confirm the effectiveness of our method and its individual component. To our best knowledge, we are the first to successfully conduct condensation on ImageNet-1k.
Free-ATM: Exploring Unsupervised Learning on Diffusion-Generated Images with Free Attention Masks
Aug 13, 2023


Despite the rapid advancement of unsupervised learning in visual representation, it requires training on large-scale datasets that demand costly data collection, and pose additional challenges due to concerns regarding data privacy. Recently, synthetic images generated by text-to-image diffusion models, have shown great potential for benefiting image recognition. Although promising, there has been inadequate exploration dedicated to unsupervised learning on diffusion-generated images. To address this, we start by uncovering that diffusion models' cross-attention layers inherently provide annotation-free attention masks aligned with corresponding text inputs on generated images. We then investigate the problems of three prevalent unsupervised learning techniques ( i.e., contrastive learning, masked modeling, and vision-language pretraining) and introduce customized solutions by fully exploiting the aforementioned free attention masks. Our approach is validated through extensive experiments that show consistent improvements in baseline models across various downstream tasks, including image classification, detection, segmentation, and image-text retrieval. By utilizing our method, it is possible to close the performance gap between unsupervised pretraining on synthetic data and real-world scenarios.
Too Large; Data Reduction for Vision-Language Pre-Training
Jun 01, 2023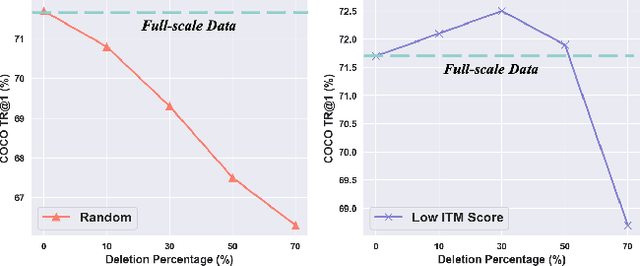

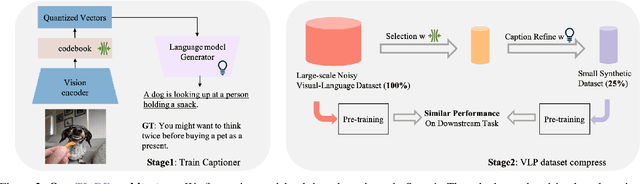

This paper examines the problems of severe image-text misalignment and high redundancy in the widely-used large-scale Vision-Language Pre-Training (VLP) datasets. To address these issues, we propose an efficient and straightforward Vision-Language learning algorithm called TL;DR, which aims to compress the existing large VLP data into a small, high-quality set. Our approach consists of two major steps. First, a codebook-based encoder-decoder captioner is developed to select representative samples. Second, a new caption is generated to complement the original captions for selected samples, mitigating the text-image misalignment problem while maintaining uniqueness. As the result, TL;DR enables us to reduce the large dataset into a small set of high-quality data, which can serve as an alternative pre-training dataset. This algorithm significantly speeds up the time-consuming pretraining process. Specifically, TL;DR can compress the mainstream VLP datasets at a high ratio, e.g., reduce well-cleaned CC3M dataset from 2.82M to 0.67M ($\sim$24\%) and noisy YFCC15M from 15M to 2.5M ($\sim$16.7\%). Extensive experiments with three popular VLP models over seven downstream tasks show that VLP model trained on the compressed dataset provided by TL;DR can perform similar or even better results compared with training on the full-scale dataset. The code will be made available at \url{https://github.com/showlab/data-centric.vlp}.
Making Vision Transformers Efficient from A Token Sparsification View
Mar 30, 2023
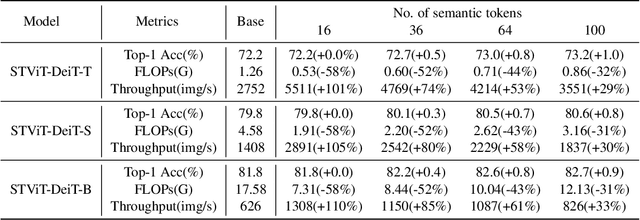
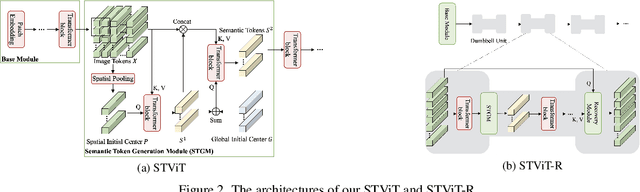
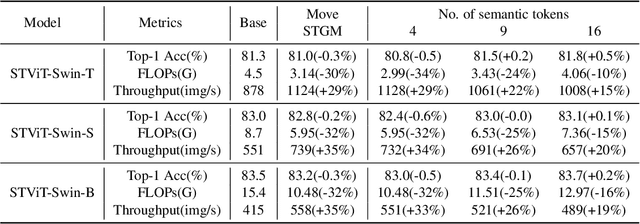
The quadratic computational complexity to the number of tokens limits the practical applications of Vision Transformers (ViTs). Several works propose to prune redundant tokens to achieve efficient ViTs. However, these methods generally suffer from (i) dramatic accuracy drops, (ii) application difficulty in the local vision transformer, and (iii) non-general-purpose networks for downstream tasks. In this work, we propose a novel Semantic Token ViT (STViT), for efficient global and local vision transformers, which can also be revised to serve as backbone for downstream tasks. The semantic tokens represent cluster centers, and they are initialized by pooling image tokens in space and recovered by attention, which can adaptively represent global or local semantic information. Due to the cluster properties, a few semantic tokens can attain the same effect as vast image tokens, for both global and local vision transformers. For instance, only 16 semantic tokens on DeiT-(Tiny,Small,Base) can achieve the same accuracy with more than 100% inference speed improvement and nearly 60% FLOPs reduction; on Swin-(Tiny,Small,Base), we can employ 16 semantic tokens in each window to further speed it up by around 20% with slight accuracy increase. Besides great success in image classification, we also extend our method to video recognition. In addition, we design a STViT-R(ecover) network to restore the detailed spatial information based on the STViT, making it work for downstream tasks, which is powerless for previous token sparsification methods. Experiments demonstrate that our method can achieve competitive results compared to the original networks in object detection and instance segmentation, with over 30% FLOPs reduction for backbone. Code is available at http://github.com/changsn/STViT-R