 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHung Le
Enhancing Length Extrapolation in Sequential Models with Pointer-Augmented Neural Memory
Apr 18, 2024
We propose Pointer-Augmented Neural Memory (PANM) to help neural networks understand and apply symbol processing to new, longer sequences of data. PANM integrates an external neural memory that uses novel physical addresses and pointer manipulation techniques to mimic human and computer symbol processing abilities. PANM facilitates pointer assignment, dereference, and arithmetic by explicitly using physical pointers to access memory content. Remarkably, it can learn to perform these operations through end-to-end training on sequence data, powering various sequential models. Our experiments demonstrate PANM's exceptional length extrapolating capabilities and improved performance in tasks that require symbol processing, such as algorithmic reasoning and Dyck language recognition. PANM helps Transformer achieve up to 100% generalization accuracy in compositional learning tasks and significantly better results in mathematical reasoning, question answering and machine translation tasks.
Automatic Prompt Selection for Large Language Models
Apr 03, 2024Large Language Models (LLMs) can perform various natural language processing tasks with suitable instruction prompts. However, designing effective prompts manually is challenging and time-consuming. Existing methods for automatic prompt optimization either lack flexibility or efficiency. In this paper, we propose an effective approach to automatically select the optimal prompt for a given input from a finite set of synthetic candidate prompts. Our approach consists of three steps: (1) clustering the training data and generating candidate prompts for each cluster using an LLM-based prompt generator; (2) synthesizing a dataset of input-prompt-output tuples for training a prompt evaluator to rank the prompts based on their relevance to the input; (3) using the prompt evaluator to select the best prompt for a new input at test time. Our approach balances prompt generality-specificity and eliminates the need for resource-intensive training and inference. It demonstrates competitive performance on zero-shot question-answering datasets: GSM8K, MultiArith, and AQuA.
Variational Flow Models: Flowing in Your Style
Feb 05, 2024We introduce a variational inference interpretation for models of "posterior flows" - generalizations of "probability flows" to a broader class of stochastic processes not necessarily diffusion processes. We coin the resulting models as "Variational Flow Models". Additionally, we propose a systematic training-free method to transform the posterior flow of a "linear" stochastic process characterized by the equation Xt = at * X0 + st * X1 into a straight constant-speed (SC) flow, reminiscent of Rectified Flow. This transformation facilitates fast sampling along the original posterior flow without training a new model of the SC flow. The flexibility of our approach allows us to extend our transformation to inter-convert two posterior flows from distinct "linear" stochastic processes. Moreover, we can easily integrate high-order numerical solvers into the transformed SC flow, further enhancing sampling accuracy and efficiency. Rigorous theoretical analysis and extensive experimental results substantiate the advantages of our framework.
Revisiting the Dataset Bias Problem from a Statistical Perspective
Feb 05, 2024In this paper, we study the "dataset bias" problem from a statistical standpoint, and identify the main cause of the problem as the strong correlation between a class attribute u and a non-class attribute b in the input x, represented by p(u|b) differing significantly from p(u). Since p(u|b) appears as part of the sampling distributions in the standard maximum log-likelihood (MLL) objective, a model trained on a biased dataset via MLL inherently incorporates such correlation into its parameters, leading to poor generalization to unbiased test data. From this observation, we propose to mitigate dataset bias via either weighting the objective of each sample n by \frac{1}{p(u_{n}|b_{n})} or sampling that sample with a weight proportional to \frac{1}{p(u_{n}|b_{n})}. While both methods are statistically equivalent, the former proves more stable and effective in practice. Additionally, we establish a connection between our debiasing approach and causal reasoning, reinforcing our method's theoretical foundation. However, when the bias label is unavailable, computing p(u|b) exactly is difficult. To overcome this challenge, we propose to approximate \frac{1}{p(u|b)} using a biased classifier trained with "bias amplification" losses. Extensive experiments on various biased datasets demonstrate the superiority of our method over existing debiasing techniques in most settings, validating our theoretical analysis.
Moonshot: Towards Controllable Video Generation and Editing with Multimodal Conditions
Jan 03, 2024Most existing video diffusion models (VDMs) are limited to mere text conditions. Thereby, they are usually lacking in control over visual appearance and geometry structure of the generated videos. This work presents Moonshot, a new video generation model that conditions simultaneously on multimodal inputs of image and text. The model builts upon a core module, called multimodal video block (MVB), which consists of conventional spatialtemporal layers for representing video features, and a decoupled cross-attention layer to address image and text inputs for appearance conditioning. In addition, we carefully design the model architecture such that it can optionally integrate with pre-trained image ControlNet modules for geometry visual conditions, without needing of extra training overhead as opposed to prior methods. Experiments show that with versatile multimodal conditioning mechanisms, Moonshot demonstrates significant improvement on visual quality and temporal consistency compared to existing models. In addition, the model can be easily repurposed for a variety of generative applications, such as personalized video generation, image animation and video editing, unveiling its potential to serve as a fundamental architecture for controllable video generation. Models will be made public on https://github.com/salesforce/LAVIS.
SurvTimeSurvival: Survival Analysis On The Patient With Multiple Visits/Records
Nov 16, 2023The accurate prediction of survival times for patients with severe diseases remains a critical challenge despite recent advances in artificial intelligence. This study introduces "SurvTimeSurvival: Survival Analysis On Patients With Multiple Visits/Records", utilizing the Transformer model to not only handle the complexities of time-varying covariates but also covariates data. We also tackle the data sparsity issue common to survival analysis datasets by integrating synthetic data generation into the learning process of our model. We show that our method outperforms state-of-the-art deep learning approaches on both covariates and time-varying covariates datasets. Our approach aims not only to enhance the understanding of individual patient survival trajectories across various medical conditions, thereby improving prediction accuracy, but also to play a pivotal role in designing clinical trials and creating new treatments.
CodeChain: Towards Modular Code Generation Through Chain of Self-revisions with Representative Sub-modules
Oct 13, 2023Large Language Models (LLMs) have already become quite proficient at solving simpler programming tasks like those in HumanEval or MBPP benchmarks. However, solving more complex and competitive programming tasks is still quite challenging for these models - possibly due to their tendency to generate solutions as monolithic code blocks instead of decomposing them into logical sub-tasks and sub-modules. On the other hand, experienced programmers instinctively write modularized code with abstraction for solving complex tasks, often reusing previously developed modules. To address this gap, we propose CodeChain, a novel framework for inference that elicits modularized code generation through a chain of self-revisions, each being guided by some representative sub-modules generated in previous iterations. Concretely, CodeChain first instructs the LLM to generate modularized codes through chain-of-thought prompting. Then it applies a chain of self-revisions by iterating the two steps: 1) extracting and clustering the generated sub-modules and selecting the cluster representatives as the more generic and re-usable implementations, and 2) augmenting the original chain-of-thought prompt with these selected module-implementations and instructing the LLM to re-generate new modularized solutions. We find that by naturally encouraging the LLM to reuse the previously developed and verified sub-modules, CodeChain can significantly boost both modularity as well as correctness of the generated solutions, achieving relative pass@1 improvements of 35% on APPS and 76% on CodeContests. It is shown to be effective on both OpenAI LLMs as well as open-sourced LLMs like WizardCoder. We also conduct comprehensive ablation studies with different methods of prompting, number of clusters, model sizes, program qualities, etc., to provide useful insights that underpin CodeChain's success.
Universal Graph Continual Learning
Aug 27, 2023

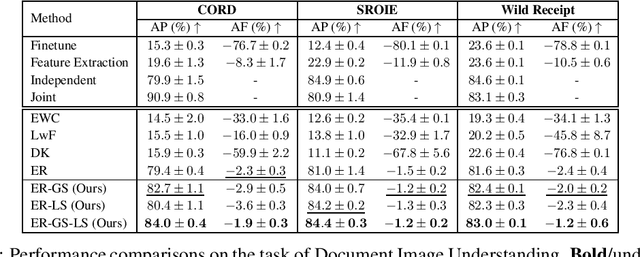
We address catastrophic forgetting issues in graph learning as incoming data transits from one to another graph distribution. Whereas prior studies primarily tackle one setting of graph continual learning such as incremental node classification, we focus on a universal approach wherein each data point in a task can be a node or a graph, and the task varies from node to graph classification. We propose a novel method that enables graph neural networks to excel in this universal setting. Our approach perseveres knowledge about past tasks through a rehearsal mechanism that maintains local and global structure consistency across the graphs. We benchmark our method against various continual learning baselines in real-world graph datasets and achieve significant improvement in average performance and forgetting across tasks.
LaGR-SEQ: Language-Guided Reinforcement Learning with Sample-Efficient Querying
Aug 21, 2023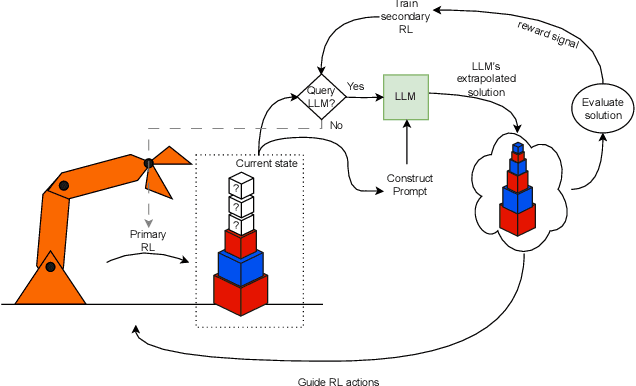
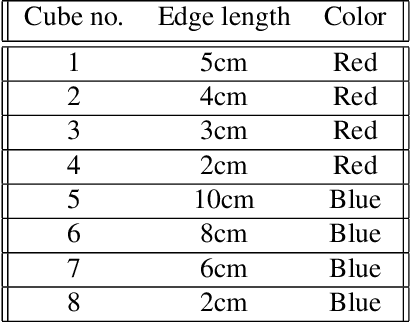
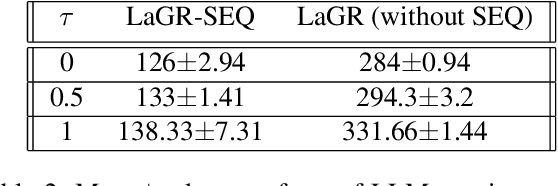
Large language models (LLMs) have recently demonstrated their impressive ability to provide context-aware responses via text. This ability could potentially be used to predict plausible solutions in sequential decision making tasks pertaining to pattern completion. For example, by observing a partial stack of cubes, LLMs can predict the correct sequence in which the remaining cubes should be stacked by extrapolating the observed patterns (e.g., cube sizes, colors or other attributes) in the partial stack. In this work, we introduce LaGR (Language-Guided Reinforcement learning), which uses this predictive ability of LLMs to propose solutions to tasks that have been partially completed by a primary reinforcement learning (RL) agent, in order to subsequently guide the latter's training. However, as RL training is generally not sample-efficient, deploying this approach would inherently imply that the LLM be repeatedly queried for solutions; a process that can be expensive and infeasible. To address this issue, we introduce SEQ (sample efficient querying), where we simultaneously train a secondary RL agent to decide when the LLM should be queried for solutions. Specifically, we use the quality of the solutions emanating from the LLM as the reward to train this agent. We show that our proposed framework LaGR-SEQ enables more efficient primary RL training, while simultaneously minimizing the number of queries to the LLM. We demonstrate our approach on a series of tasks and highlight the advantages of our approach, along with its limitations and potential future research directions.
Intrinsic Motivation via Surprise Memory
Aug 09, 2023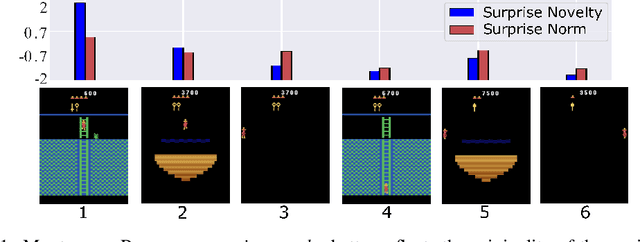

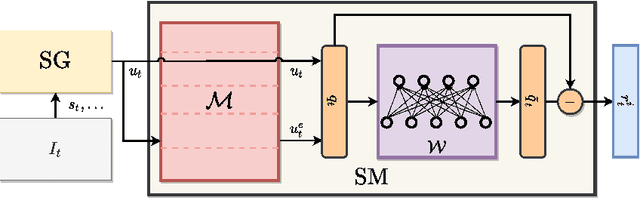
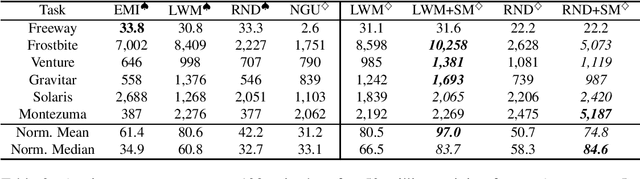
We present a new computing model for intrinsic rewards in reinforcement learning that addresses the limitations of existing surprise-driven explorations. The reward is the novelty of the surprise rather than the surprise norm. We estimate the surprise novelty as retrieval errors of a memory network wherein the memory stores and reconstructs surprises. Our surprise memory (SM) augments the capability of surprise-based intrinsic motivators, maintaining the agent's interest in exciting exploration while reducing unwanted attraction to unpredictable or noisy observations. Our experiments demonstrate that the SM combined with various surprise predictors exhibits efficient exploring behaviors and significantly boosts the final performance in sparse reward environments, including Noisy-TV, navigation and challenging Atari games.