 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTingting Gao
MicroDreamer: Zero-shot 3D Generation in $\sim$20 Seconds by Score-based Iterative Reconstruction
Apr 30, 2024
Optimization-based approaches, such as score distillation sampling (SDS), show promise in zero-shot 3D generation but suffer from low efficiency, primarily due to the high number of function evaluations (NFEs) required for each sample. In this paper, we introduce score-based iterative reconstruction (SIR), an efficient and general algorithm for 3D generation with a multi-view score-based diffusion model. Given the images produced by the diffusion model, SIR reduces NFEs by repeatedly optimizing 3D parameters, unlike the single optimization in SDS, mimicking the 3D reconstruction process. With other improvements including optimization in the pixel space, we present an efficient approach called MicroDreamer that generally applies to various 3D representations and 3D generation tasks. In particular, retaining a comparable performance, MicroDreamer is 5-20 times faster than SDS in generating neural radiance field and takes about 20 seconds to generate meshes from 3D Gaussian splitting on a single A100 GPU, halving the time of the fastest zero-shot baseline, DreamGaussian. Our code is available at https://github.com/ML-GSAI/MicroDreamer.
DragAnything: Motion Control for Anything using Entity Representation
Mar 15, 2024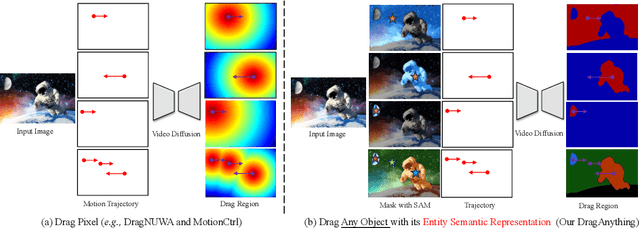

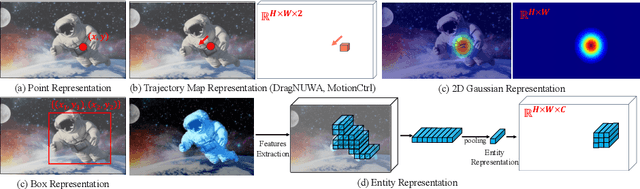

We introduce DragAnything, which utilizes a entity representation to achieve motion control for any object in controllable video generation. Comparison to existing motion control methods, DragAnything offers several advantages. Firstly, trajectory-based is more userfriendly for interaction, when acquiring other guidance signals (e.g., masks, depth maps) is labor-intensive. Users only need to draw a line (trajectory) during interaction. Secondly, our entity representation serves as an open-domain embedding capable of representing any object, enabling the control of motion for diverse entities, including background. Lastly, our entity representation allows simultaneous and distinct motion control for multiple objects. Extensive experiments demonstrate that our DragAnything achieves state-of-the-art performance for FVD, FID, and User Study, particularly in terms of object motion control, where our method surpasses the previous methods (e.g., DragNUWA) by 26% in human voting.
Paragraph-to-Image Generation with Information-Enriched Diffusion Model
Nov 29, 2023Text-to-image (T2I) models have recently experienced rapid development, achieving astonishing performance in terms of fidelity and textual alignment capabilities. However, given a long paragraph (up to 512 words), these generation models still struggle to achieve strong alignment and are unable to generate images depicting complex scenes. In this paper, we introduce an information-enriched diffusion model for paragraph-to-image generation task, termed ParaDiffusion, which delves into the transference of the extensive semantic comprehension capabilities of large language models to the task of image generation. At its core is using a large language model (e.g., Llama V2) to encode long-form text, followed by fine-tuning with LORA to alignthe text-image feature spaces in the generation task. To facilitate the training of long-text semantic alignment, we also curated a high-quality paragraph-image pair dataset, namely ParaImage. This dataset contains a small amount of high-quality, meticulously annotated data, and a large-scale synthetic dataset with long text descriptions being generated using a vision-language model. Experiments demonstrate that ParaDiffusion outperforms state-of-the-art models (SD XL, DeepFloyd IF) on ViLG-300 and ParaPrompts, achieving up to 15% and 45% human voting rate improvements for visual appeal and text faithfulness, respectively. The code and dataset will be released to foster community research on long-text alignment.
Domain Generalization via Shuffled Style Assembly for Face Anti-Spoofing
Mar 18, 2022
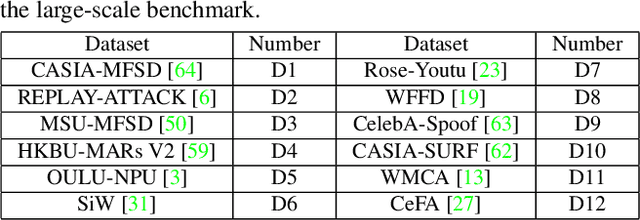
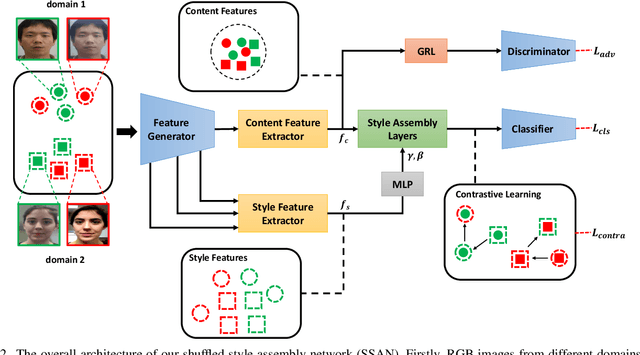
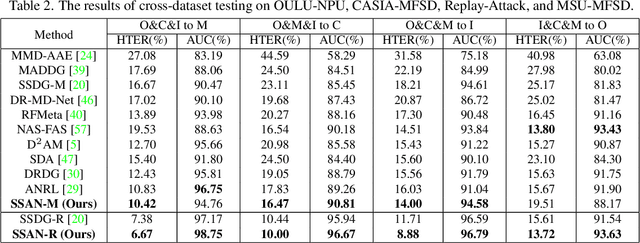
With diverse presentation attacks emerging continually, generalizable face anti-spoofing (FAS) has drawn growing attention. Most existing methods implement domain generalization (DG) on the complete representations. However, different image statistics may have unique properties for the FAS tasks. In this work, we separate the complete representation into content and style ones. A novel Shuffled Style Assembly Network (SSAN) is proposed to extract and reassemble different content and style features for a stylized feature space. Then, to obtain a generalized representation, a contrastive learning strategy is developed to emphasize liveness-related style information while suppress the domain-specific one. Finally, the representations of the correct assemblies are used to distinguish between living and spoofing during the inferring. On the other hand, despite the decent performance, there still exists a gap between academia and industry, due to the difference in data quantity and distribution. Thus, a new large-scale benchmark for FAS is built up to further evaluate the performance of algorithms in reality. Both qualitative and quantitative results on existing and proposed benchmarks demonstrate the effectiveness of our methods. The codes will be available at https://github.com/wangzhuo2019/SSAN.