 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHeng Wang
HQ-Edit: A High-Quality Dataset for Instruction-based Image Editing
Apr 15, 2024
This study introduces HQ-Edit, a high-quality instruction-based image editing dataset with around 200,000 edits. Unlike prior approaches relying on attribute guidance or human feedback on building datasets, we devise a scalable data collection pipeline leveraging advanced foundation models, namely GPT-4V and DALL-E 3. To ensure its high quality, diverse examples are first collected online, expanded, and then used to create high-quality diptychs featuring input and output images with detailed text prompts, followed by precise alignment ensured through post-processing. In addition, we propose two evaluation metrics, Alignment and Coherence, to quantitatively assess the quality of image edit pairs using GPT-4V. HQ-Edits high-resolution images, rich in detail and accompanied by comprehensive editing prompts, substantially enhance the capabilities of existing image editing models. For example, an HQ-Edit finetuned InstructPix2Pix can attain state-of-the-art image editing performance, even surpassing those models fine-tuned with human-annotated data. The project page is https://thefllood.github.io/HQEdit_web.
Digital Twin Channel for 6G: Concepts, Architectures and Potential Applications
Mar 31, 2024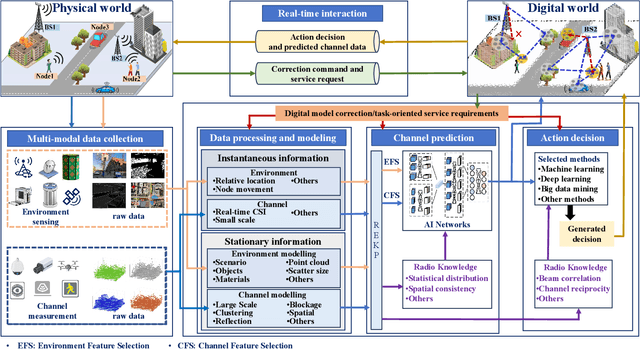

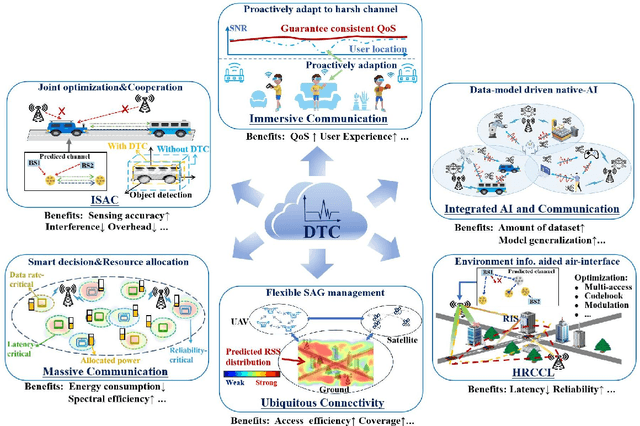
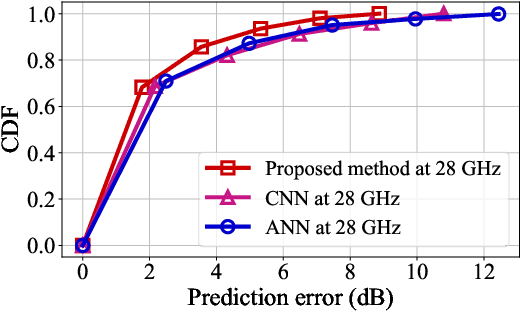
Digital twin channel (DTC) is the real-time mapping of a wireless channel from the physical world to the digital world, which is expected to provide significant performance enhancements for the sixth-generation (6G) air-interface design. In this work, we first define five evolution levels of channel twins with the progression of wireless communication. The fifth level, autonomous DTC, is elaborated with multi-dimensional factors such as methodology, characterization precision, and data category. Then, we provide detailed insights into the requirements and architecture of a complete DTC for 6G. Subsequently, a sensing-enhanced real-time channel prediction platform and experimental validations are exhibited. Finally, drawing from the vision of the 6G network, we explore the potential applications and the open issues in future DTC research.
MMoE: Robust Spoiler Detection with Multi-modal Information and Domain-aware Mixture-of-Experts
Mar 14, 2024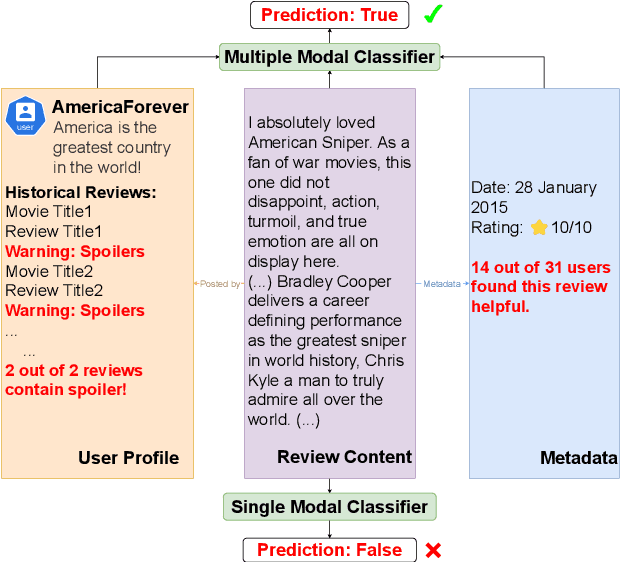
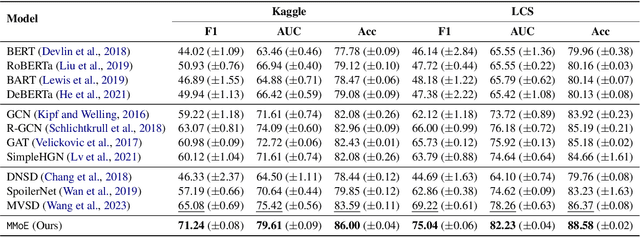
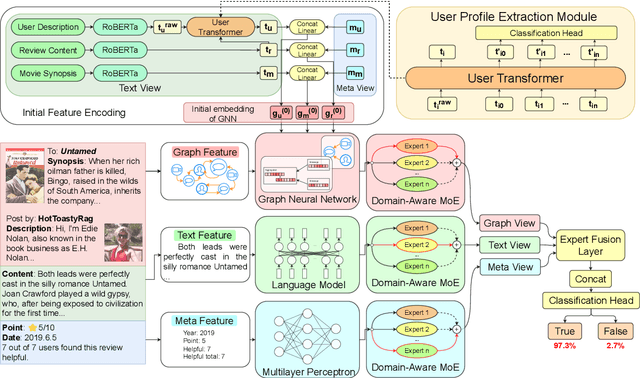
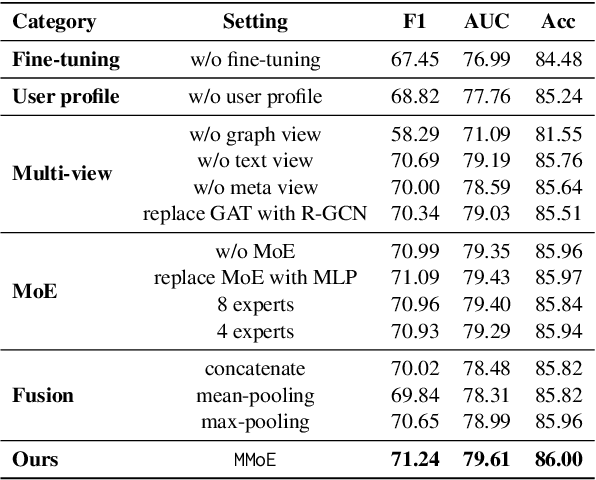
Online movie review websites are valuable for information and discussion about movies. However, the massive spoiler reviews detract from the movie-watching experience, making spoiler detection an important task. Previous methods simply focus on reviews' text content, ignoring the heterogeneity of information in the platform. For instance, the metadata and the corresponding user's information of a review could be helpful. Besides, the spoiler language of movie reviews tends to be genre-specific, thus posing a domain generalization challenge for existing methods. To this end, we propose MMoE, a multi-modal network that utilizes information from multiple modalities to facilitate robust spoiler detection and adopts Mixture-of-Experts to enhance domain generalization. MMoE first extracts graph, text, and meta feature from the user-movie network, the review's textual content, and the review's metadata respectively. To handle genre-specific spoilers, we then adopt Mixture-of-Experts architecture to process information in three modalities to promote robustness. Finally, we use an expert fusion layer to integrate the features from different perspectives and make predictions based on the fused embedding. Experiments demonstrate that MMoE achieves state-of-the-art performance on two widely-used spoiler detection datasets, surpassing previous SOTA methods by 2.56% and 8.41% in terms of accuracy and F1-score. Further experiments also demonstrate MMoE's superiority in robustness and generalization.
Hy-DAT: A Tool to Address Hydropower Modeling Gaps Using Interdependency, Efficiency Curves, and Unit Dispatch Models
Mar 05, 2024As the power system continues to be flooded with intermittent resources, it becomes more important to accurately assess the role of hydro and its impact on the power grid. While hydropower generation has been studied for decades, dependency of power generation on water availability and constraints in hydro operation are not well represented in power system models used in the planning and operation of large-scale interconnection studies. There are still multiple modeling gaps that need to be addressed; if not, they can lead to inaccurate operation and planning reliability studies, and consequently to unintentional load shedding or even blackouts. As a result, it is very important that hydropower is represented correctly in both steady-state and dynamic power system studies. In this paper, we discuss the development and use of the Hydrological Dispatch and Analysis Tool (Hy-DAT) as an interactive graphical user interface, that uses a novel methodology to address the hydropower modeling gaps like water availability and interdependency using a database and algorithms to generate accurate representative models for power system simulation.
Finetuned Multimodal Language Models Are High-Quality Image-Text Data Filters
Mar 05, 2024
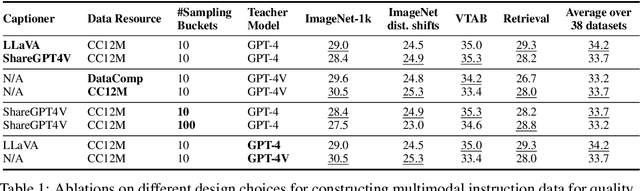
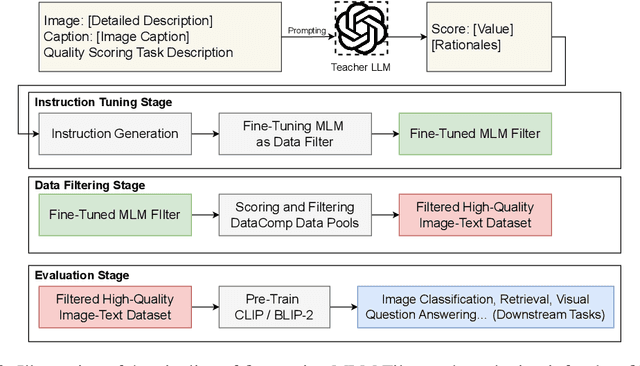
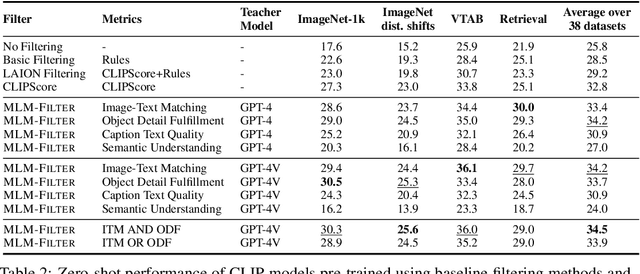
We propose a novel framework for filtering image-text data by leveraging fine-tuned Multimodal Language Models (MLMs). Our approach outperforms predominant filtering methods (e.g., CLIPScore) via integrating the recent advances in MLMs. We design four distinct yet complementary metrics to holistically measure the quality of image-text data. A new pipeline is established to construct high-quality instruction data for fine-tuning MLMs as data filters. Comparing with CLIPScore, our MLM filters produce more precise and comprehensive scores that directly improve the quality of filtered data and boost the performance of pre-trained models. We achieve significant improvements over CLIPScore on popular foundation models (i.e., CLIP and BLIP2) and various downstream tasks. Our MLM filter can generalize to different models and tasks, and be used as a drop-in replacement for CLIPScore. An additional ablation study is provided to verify our design choices for the MLM filter.
DELL: Generating Reactions and Explanations for LLM-Based Misinformation Detection
Feb 16, 2024Large language models are limited by challenges in factuality and hallucinations to be directly employed off-the-shelf for judging the veracity of news articles, where factual accuracy is paramount. In this work, we propose DELL that identifies three key stages in misinformation detection where LLMs could be incorporated as part of the pipeline: 1) LLMs could \emph{generate news reactions} to represent diverse perspectives and simulate user-news interaction networks; 2) LLMs could \emph{generate explanations} for proxy tasks (e.g., sentiment, stance) to enrich the contexts of news articles and produce experts specializing in various aspects of news understanding; 3) LLMs could \emph{merge task-specific experts} and provide an overall prediction by incorporating the predictions and confidence scores of varying experts. Extensive experiments on seven datasets with three LLMs demonstrate that DELL outperforms state-of-the-art baselines by up to 16.8\% in macro f1-score. Further analysis reveals that the generated reactions and explanations are greatly helpful in misinformation detection, while our proposed LLM-guided expert merging helps produce better-calibrated predictions.
Video Recognition in Portrait Mode
Dec 21, 2023The creation of new datasets often presents new challenges for video recognition and can inspire novel ideas while addressing these challenges. While existing datasets mainly comprise landscape mode videos, our paper seeks to introduce portrait mode videos to the research community and highlight the unique challenges associated with this video format. With the growing popularity of smartphones and social media applications, recognizing portrait mode videos is becoming increasingly important. To this end, we have developed the first dataset dedicated to portrait mode video recognition, namely PortraitMode-400. The taxonomy of PortraitMode-400 was constructed in a data-driven manner, comprising 400 fine-grained categories, and rigorous quality assurance was implemented to ensure the accuracy of human annotations. In addition to the new dataset, we conducted a comprehensive analysis of the impact of video format (portrait mode versus landscape mode) on recognition accuracy and spatial bias due to the different formats. Furthermore, we designed extensive experiments to explore key aspects of portrait mode video recognition, including the choice of data augmentation, evaluation procedure, the importance of temporal information, and the role of audio modality. Building on the insights from our experimental results and the introduction of PortraitMode-400, our paper aims to inspire further research efforts in this emerging research area.
Shot2Story20K: A New Benchmark for Comprehensive Understanding of Multi-shot Videos
Dec 19, 2023A short clip of video may contain progression of multiple events and an interesting story line. A human need to capture both the event in every shot and associate them together to understand the story behind it. In this work, we present a new multi-shot video understanding benchmark Shot2Story20K with detailed shot-level captions and comprehensive video summaries. To facilitate better semantic understanding of videos, we provide captions for both visual signals and human narrations. We design several distinct tasks including single-shot video and narration captioning, multi-shot video summarization, and video retrieval with shot descriptions. Preliminary experiments show some challenges to generate a long and comprehensive video summary. Nevertheless, the generated imperfect summaries can already significantly boost the performance of existing video understanding tasks such as video question-answering, promoting an under-explored setting of video understanding with detailed summaries.
Vista-LLaMA: Reliable Video Narrator via Equal Distance to Visual Tokens
Dec 12, 2023Recent advances in large video-language models have displayed promising outcomes in video comprehension. Current approaches straightforwardly convert video into language tokens and employ large language models for multi-modal tasks. However, this method often leads to the generation of irrelevant content, commonly known as "hallucination", as the length of the text increases and the impact of the video diminishes. To address this problem, we propose Vista-LLaMA, a novel framework that maintains the consistent distance between all visual tokens and any language tokens, irrespective of the generated text length. Vista-LLaMA omits relative position encoding when determining attention weights between visual and text tokens, retaining the position encoding for text and text tokens. This amplifies the effect of visual tokens on text generation, especially when the relative distance is longer between visual and text tokens. The proposed attention mechanism significantly reduces the chance of producing irrelevant text related to the video content. Furthermore, we present a sequential visual projector that projects the current video frame into tokens of language space with the assistance of the previous frame. This approach not only captures the temporal relationship within the video, but also allows less visual tokens to encompass the entire video. Our approach significantly outperforms various previous methods (e.g., Video-ChatGPT, MovieChat) on four challenging open-ended video question answering benchmarks. We reach an accuracy of 60.7 on the zero-shot NExT-QA and 60.5 on the zero-shot MSRVTT-QA, setting a new state-of-the-art performance. This project is available at https://jinxxian.github.io/Vista-LLaMA.
InfiMM-Eval: Complex Open-Ended Reasoning Evaluation For Multi-Modal Large Language Models
Dec 04, 2023Multi-modal Large Language Models (MLLMs) are increasingly prominent in the field of artificial intelligence. These models not only excel in traditional vision-language tasks but also demonstrate impressive performance in contemporary multi-modal benchmarks. Although many of these benchmarks attempt to holistically evaluate MLLMs, they typically concentrate on basic reasoning tasks, often yielding only simple yes/no or multi-choice responses. These methods naturally lead to confusion and difficulties in conclusively determining the reasoning capabilities of MLLMs. To mitigate this issue, we manually curate a benchmark dataset specifically designed for MLLMs, with a focus on complex reasoning tasks. Our benchmark comprises three key reasoning categories: deductive, abductive, and analogical reasoning. The queries in our dataset are intentionally constructed to engage the reasoning capabilities of MLLMs in the process of generating answers. For a fair comparison across various MLLMs, we incorporate intermediate reasoning steps into our evaluation criteria. In instances where an MLLM is unable to produce a definitive answer, its reasoning ability is evaluated by requesting intermediate reasoning steps. If these steps align with our manual annotations, appropriate scores are assigned. This evaluation scheme resembles methods commonly used in human assessments, such as exams or assignments, and represents what we consider a more effective assessment technique compared with existing benchmarks. We evaluate a selection of representative MLLMs using this rigorously developed open-ended multi-step elaborate reasoning benchmark, designed to challenge and accurately measure their reasoning capabilities. The code and data will be released at https://infimm.github.io/InfiMM-Eval/