 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYongfei Liu
ViTAR: Vision Transformer with Any Resolution
Mar 28, 2024
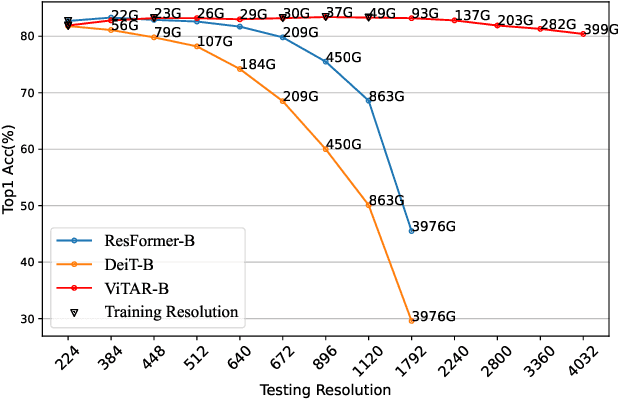
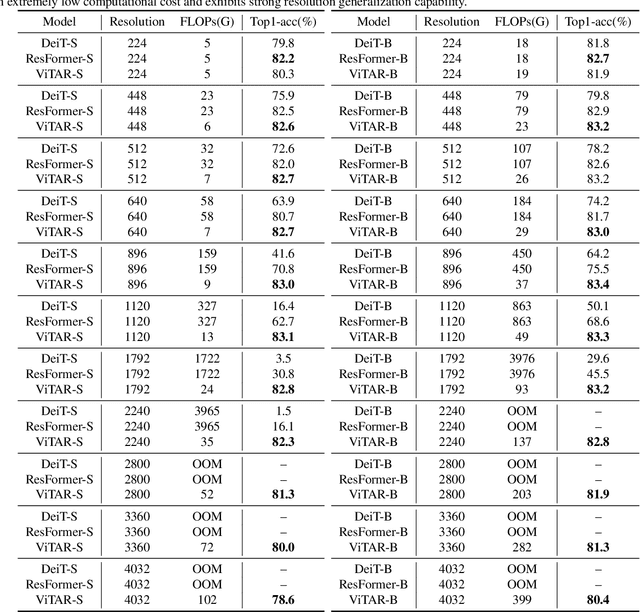
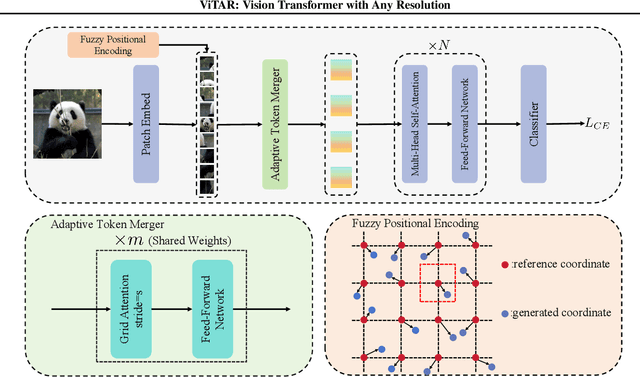
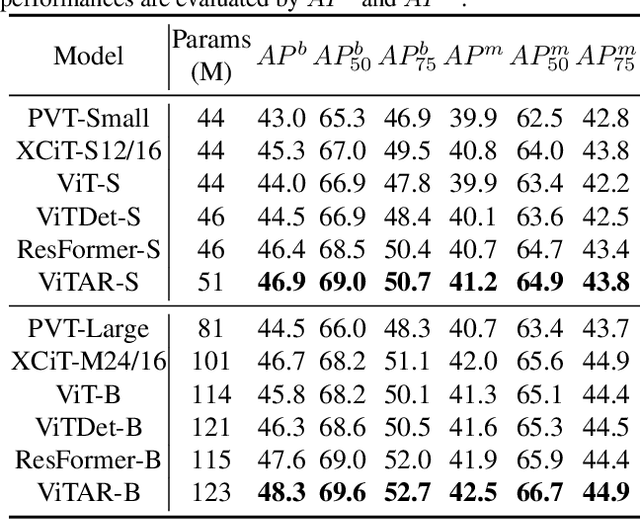
This paper tackles a significant challenge faced by Vision Transformers (ViTs): their constrained scalability across different image resolutions. Typically, ViTs experience a performance decline when processing resolutions different from those seen during training. Our work introduces two key innovations to address this issue. Firstly, we propose a novel module for dynamic resolution adjustment, designed with a single Transformer block, specifically to achieve highly efficient incremental token integration. Secondly, we introduce fuzzy positional encoding in the Vision Transformer to provide consistent positional awareness across multiple resolutions, thereby preventing overfitting to any single training resolution. Our resulting model, ViTAR (Vision Transformer with Any Resolution), demonstrates impressive adaptability, achieving 83.3\% top-1 accuracy at a 1120x1120 resolution and 80.4\% accuracy at a 4032x4032 resolution, all while reducing computational costs. ViTAR also shows strong performance in downstream tasks such as instance and semantic segmentation and can easily combined with self-supervised learning techniques like Masked AutoEncoder. Our work provides a cost-effective solution for enhancing the resolution scalability of ViTs, paving the way for more versatile and efficient high-resolution image processing.
InfiMM-HD: A Leap Forward in High-Resolution Multimodal Understanding
Mar 03, 2024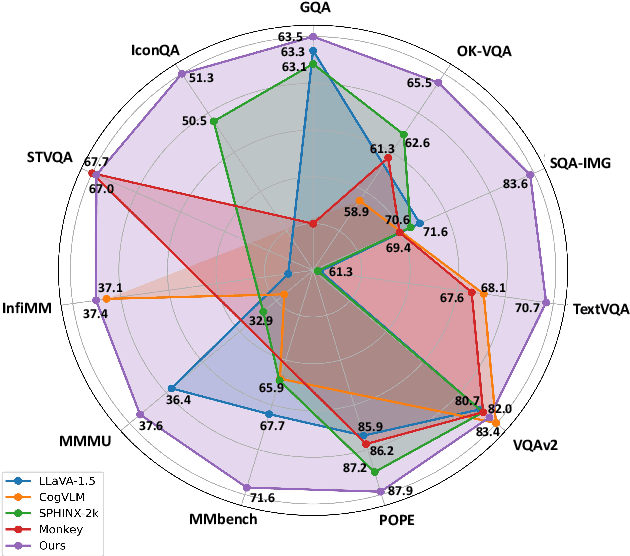
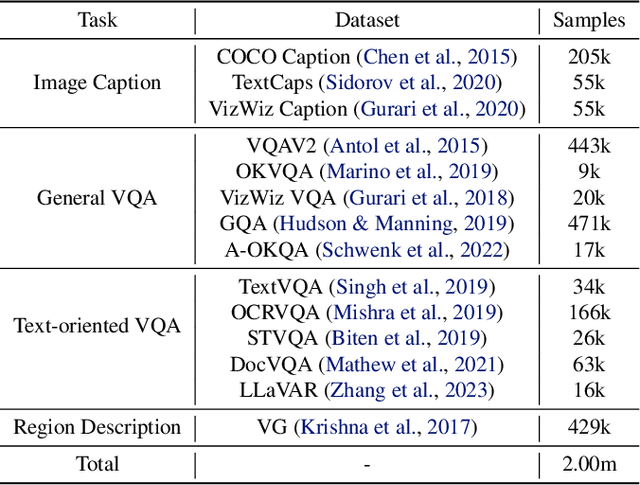

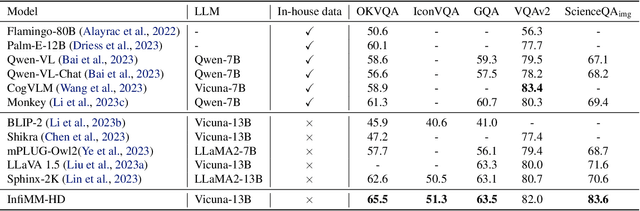
Multimodal Large Language Models (MLLMs) have experienced significant advancements recently. Nevertheless, challenges persist in the accurate recognition and comprehension of intricate details within high-resolution images. Despite being indispensable for the development of robust MLLMs, this area remains underinvestigated. To tackle this challenge, our work introduces InfiMM-HD, a novel architecture specifically designed for processing images of different resolutions with low computational overhead. This innovation facilitates the enlargement of MLLMs to higher-resolution capabilities. InfiMM-HD incorporates a cross-attention module and visual windows to reduce computation costs. By integrating this architectural design with a four-stage training pipeline, our model attains improved visual perception efficiently and cost-effectively. Empirical study underscores the robustness and effectiveness of InfiMM-HD, opening new avenues for exploration in related areas. Codes and models can be found at https://huggingface.co/Infi-MM/infimm-hd
Exploring the Reasoning Abilities of Multimodal Large Language Models (MLLMs): A Comprehensive Survey on Emerging Trends in Multimodal Reasoning
Jan 18, 2024Strong Artificial Intelligence (Strong AI) or Artificial General Intelligence (AGI) with abstract reasoning ability is the goal of next-generation AI. Recent advancements in Large Language Models (LLMs), along with the emerging field of Multimodal Large Language Models (MLLMs), have demonstrated impressive capabilities across a wide range of multimodal tasks and applications. Particularly, various MLLMs, each with distinct model architectures, training data, and training stages, have been evaluated across a broad range of MLLM benchmarks. These studies have, to varying degrees, revealed different aspects of the current capabilities of MLLMs. However, the reasoning abilities of MLLMs have not been systematically investigated. In this survey, we comprehensively review the existing evaluation protocols of multimodal reasoning, categorize and illustrate the frontiers of MLLMs, introduce recent trends in applications of MLLMs on reasoning-intensive tasks, and finally discuss current practices and future directions. We believe our survey establishes a solid base and sheds light on this important topic, multimodal reasoning.
InfiMM-Eval: Complex Open-Ended Reasoning Evaluation For Multi-Modal Large Language Models
Dec 04, 2023Multi-modal Large Language Models (MLLMs) are increasingly prominent in the field of artificial intelligence. These models not only excel in traditional vision-language tasks but also demonstrate impressive performance in contemporary multi-modal benchmarks. Although many of these benchmarks attempt to holistically evaluate MLLMs, they typically concentrate on basic reasoning tasks, often yielding only simple yes/no or multi-choice responses. These methods naturally lead to confusion and difficulties in conclusively determining the reasoning capabilities of MLLMs. To mitigate this issue, we manually curate a benchmark dataset specifically designed for MLLMs, with a focus on complex reasoning tasks. Our benchmark comprises three key reasoning categories: deductive, abductive, and analogical reasoning. The queries in our dataset are intentionally constructed to engage the reasoning capabilities of MLLMs in the process of generating answers. For a fair comparison across various MLLMs, we incorporate intermediate reasoning steps into our evaluation criteria. In instances where an MLLM is unable to produce a definitive answer, its reasoning ability is evaluated by requesting intermediate reasoning steps. If these steps align with our manual annotations, appropriate scores are assigned. This evaluation scheme resembles methods commonly used in human assessments, such as exams or assignments, and represents what we consider a more effective assessment technique compared with existing benchmarks. We evaluate a selection of representative MLLMs using this rigorously developed open-ended multi-step elaborate reasoning benchmark, designed to challenge and accurately measure their reasoning capabilities. The code and data will be released at https://infimm.github.io/InfiMM-Eval/
Improving In-Context Learning in Diffusion Models with Visual Context-Modulated Prompts
Dec 03, 2023In light of the remarkable success of in-context learning in large language models, its potential extension to the vision domain, particularly with visual foundation models like Stable Diffusion, has sparked considerable interest. Existing approaches in visual in-context learning frequently face hurdles such as expensive pretraining, limiting frameworks, inadequate visual comprehension, and limited adaptability to new tasks. In response to these challenges, we introduce improved Prompt Diffusion (iPromptDiff) in this study. iPromptDiff integrates an end-to-end trained vision encoder that converts visual context into an embedding vector. This vector is subsequently used to modulate the token embeddings of text prompts. We show that a diffusion-based vision foundation model, when equipped with this visual context-modulated text guidance and a standard ControlNet structure, exhibits versatility and robustness across a variety of training tasks and excels in in-context learning for novel vision tasks, such as normal-to-image or image-to-line transformations. The effectiveness of these capabilities relies heavily on a deep visual understanding, which is achieved through relevant visual demonstrations processed by our proposed in-context learning architecture.
Reason out Your Layout: Evoking the Layout Master from Large Language Models for Text-to-Image Synthesis
Nov 28, 2023Recent advancements in text-to-image (T2I) generative models have shown remarkable capabilities in producing diverse and imaginative visuals based on text prompts. Despite the advancement, these diffusion models sometimes struggle to translate the semantic content from the text into images entirely. While conditioning on the layout has shown to be effective in improving the compositional ability of T2I diffusion models, they typically require manual layout input. In this work, we introduce a novel approach to improving T2I diffusion models using Large Language Models (LLMs) as layout generators. Our method leverages the Chain-of-Thought prompting of LLMs to interpret text and generate spatially reasonable object layouts. The generated layout is then used to enhance the generated images' composition and spatial accuracy. Moreover, we propose an efficient adapter based on a cross-attention mechanism, which explicitly integrates the layout information into the stable diffusion models. Our experiments demonstrate significant improvements in image quality and layout accuracy, showcasing the potential of LLMs in augmenting generative image models.
Grounded Image Text Matching with Mismatched Relation Reasoning
Aug 04, 2023



This paper introduces Grounded Image Text Matching with Mismatched Relation (GITM-MR), a novel visual-linguistic joint task that evaluates the relation understanding capabilities of transformer-based pre-trained models. GITM-MR requires a model to first determine if an expression describes an image, then localize referred objects or ground the mismatched parts of the text. We provide a benchmark for evaluating pre-trained models on this task, with a focus on the challenging settings of limited data and out-of-distribution sentence lengths. Our evaluation demonstrates that pre-trained models lack data efficiency and length generalization ability. To address this, we propose the Relation-sensitive Correspondence Reasoning Network (RCRN), which incorporates relation-aware reasoning via bi-directional message propagation guided by language structure. RCRN can be interpreted as a modular program and delivers strong performance in both length generalization and data efficiency.
HOICLIP: Efficient Knowledge Transfer for HOI Detection with Vision-Language Models
Mar 29, 2023



Human-Object Interaction (HOI) detection aims to localize human-object pairs and recognize their interactions. Recently, Contrastive Language-Image Pre-training (CLIP) has shown great potential in providing interaction prior for HOI detectors via knowledge distillation. However, such approaches often rely on large-scale training data and suffer from inferior performance under few/zero-shot scenarios. In this paper, we propose a novel HOI detection framework that efficiently extracts prior knowledge from CLIP and achieves better generalization. In detail, we first introduce a novel interaction decoder to extract informative regions in the visual feature map of CLIP via a cross-attention mechanism, which is then fused with the detection backbone by a knowledge integration block for more accurate human-object pair detection. In addition, prior knowledge in CLIP text encoder is leveraged to generate a classifier by embedding HOI descriptions. To distinguish fine-grained interactions, we build a verb classifier from training data via visual semantic arithmetic and a lightweight verb representation adapter. Furthermore, we propose a training-free enhancement to exploit global HOI predictions from CLIP. Extensive experiments demonstrate that our method outperforms the state of the art by a large margin on various settings, e.g. +4.04 mAP on HICO-Det. The source code is available in https://github.com/Artanic30/HOICLIP.
Weakly-supervised HOI Detection via Prior-guided Bi-level Representation Learning
Mar 02, 2023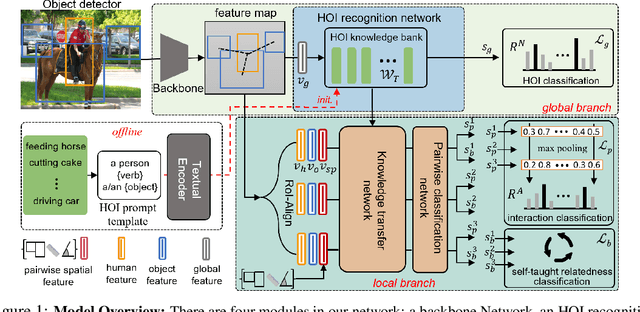


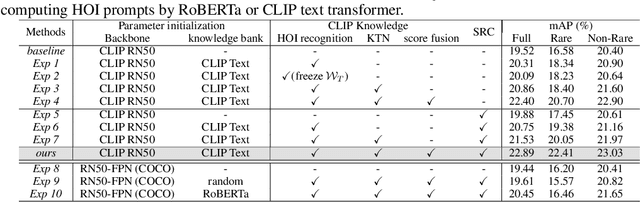
Human object interaction (HOI) detection plays a crucial role in human-centric scene understanding and serves as a fundamental building-block for many vision tasks. One generalizable and scalable strategy for HOI detection is to use weak supervision, learning from image-level annotations only. This is inherently challenging due to ambiguous human-object associations, large search space of detecting HOIs and highly noisy training signal. A promising strategy to address those challenges is to exploit knowledge from large-scale pretrained models (e.g., CLIP), but a direct knowledge distillation strategy~\citep{liao2022gen} does not perform well on the weakly-supervised setting. In contrast, we develop a CLIP-guided HOI representation capable of incorporating the prior knowledge at both image level and HOI instance level, and adopt a self-taught mechanism to prune incorrect human-object associations. Experimental results on HICO-DET and V-COCO show that our method outperforms the previous works by a sizable margin, showing the efficacy of our HOI representation.
VL-InterpreT: An Interactive Visualization Tool for Interpreting Vision-Language Transformers
Mar 30, 2022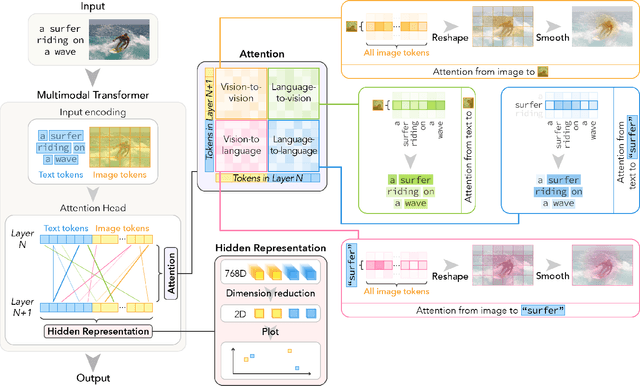



Breakthroughs in transformer-based models have revolutionized not only the NLP field, but also vision and multimodal systems. However, although visualization and interpretability tools have become available for NLP models, internal mechanisms of vision and multimodal transformers remain largely opaque. With the success of these transformers, it is increasingly critical to understand their inner workings, as unraveling these black-boxes will lead to more capable and trustworthy models. To contribute to this quest, we propose VL-InterpreT, which provides novel interactive visualizations for interpreting the attentions and hidden representations in multimodal transformers. VL-InterpreT is a task agnostic and integrated tool that (1) tracks a variety of statistics in attention heads throughout all layers for both vision and language components, (2) visualizes cross-modal and intra-modal attentions through easily readable heatmaps, and (3) plots the hidden representations of vision and language tokens as they pass through the transformer layers. In this paper, we demonstrate the functionalities of VL-InterpreT through the analysis of KD-VLP, an end-to-end pretraining vision-language multimodal transformer-based model, in the tasks of Visual Commonsense Reasoning (VCR) and WebQA, two visual question answering benchmarks. Furthermore, we also present a few interesting findings about multimodal transformer behaviors that were learned through our tool.