 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLi-Ping Liu
Reason out Your Layout: Evoking the Layout Master from Large Language Models for Text-to-Image Synthesis
Nov 28, 2023
Recent advancements in text-to-image (T2I) generative models have shown remarkable capabilities in producing diverse and imaginative visuals based on text prompts. Despite the advancement, these diffusion models sometimes struggle to translate the semantic content from the text into images entirely. While conditioning on the layout has shown to be effective in improving the compositional ability of T2I diffusion models, they typically require manual layout input. In this work, we introduce a novel approach to improving T2I diffusion models using Large Language Models (LLMs) as layout generators. Our method leverages the Chain-of-Thought prompting of LLMs to interpret text and generate spatially reasonable object layouts. The generated layout is then used to enhance the generated images' composition and spatial accuracy. Moreover, we propose an efficient adapter based on a cross-attention mechanism, which explicitly integrates the layout information into the stable diffusion models. Our experiments demonstrate significant improvements in image quality and layout accuracy, showcasing the potential of LLMs in augmenting generative image models.
Bayesian Conditional Diffusion Models for Versatile Spatiotemporal Turbulence Generation
Nov 14, 2023Turbulent flows have historically presented formidable challenges to predictive computational modeling. Traditional numerical simulations often require vast computational resources, making them infeasible for numerous engineering applications. As an alternative, deep learning-based surrogate models have emerged, offering data-drive solutions. However, these are typically constructed within deterministic settings, leading to shortfall in capturing the innate chaotic and stochastic behaviors of turbulent dynamics. We introduce a novel generative framework grounded in probabilistic diffusion models for versatile generation of spatiotemporal turbulence. Our method unifies both unconditional and conditional sampling strategies within a Bayesian framework, which can accommodate diverse conditioning scenarios, including those with a direct differentiable link between specified conditions and generated unsteady flow outcomes, and scenarios lacking such explicit correlations. A notable feature of our approach is the method proposed for long-span flow sequence generation, which is based on autoregressive gradient-based conditional sampling, eliminating the need for cumbersome retraining processes. We showcase the versatile turbulence generation capability of our framework through a suite of numerical experiments, including: 1) the synthesis of LES simulated instantaneous flow sequences from URANS inputs; 2) holistic generation of inhomogeneous, anisotropic wall-bounded turbulence, whether from given initial conditions, prescribed turbulence statistics, or entirely from scratch; 3) super-resolved generation of high-speed turbulent boundary layer flows from low-resolution data across a range of input resolutions. Collectively, our numerical experiments highlight the merit and transformative potential of the proposed methods, making a significant advance in the field of turbulence generation.
EDGE++: Improved Training and Sampling of EDGE
Oct 28, 2023Recently developed deep neural models like NetGAN, CELL, and Variational Graph Autoencoders have made progress but face limitations in replicating key graph statistics on generating large graphs. Diffusion-based methods have emerged as promising alternatives, however, most of them present challenges in computational efficiency and generative performance. EDGE is effective at modeling large networks, but its current denoising approach can be inefficient, often leading to wasted computational resources and potential mismatches in its generation process. In this paper, we propose enhancements to the EDGE model to address these issues. Specifically, we introduce a degree-specific noise schedule that optimizes the number of active nodes at each timestep, significantly reducing memory consumption. Additionally, we present an improved sampling scheme that fine-tunes the generative process, allowing for better control over the similarity between the synthesized and the true network. Our experimental results demonstrate that the proposed modifications not only improve the efficiency but also enhance the accuracy of the generated graphs, offering a robust and scalable solution for graph generation tasks.
On Separate Normalization in Self-supervised Transformers
Sep 22, 2023

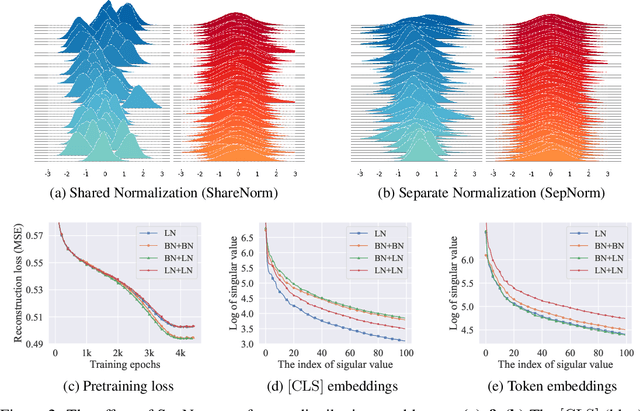
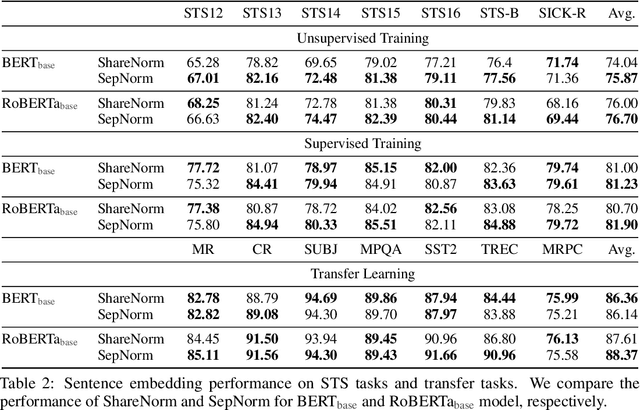
Self-supervised training methods for transformers have demonstrated remarkable performance across various domains. Previous transformer-based models, such as masked autoencoders (MAE), typically utilize a single normalization layer for both the [CLS] symbol and the tokens. We propose in this paper a simple modification that employs separate normalization layers for the tokens and the [CLS] symbol to better capture their distinct characteristics and enhance downstream task performance. Our method aims to alleviate the potential negative effects of using the same normalization statistics for both token types, which may not be optimally aligned with their individual roles. We empirically show that by utilizing a separate normalization layer, the [CLS] embeddings can better encode the global contextual information and are distributed more uniformly in its anisotropic space. When replacing the conventional normalization layer with the two separate layers, we observe an average 2.7% performance improvement over the image, natural language, and graph domains.
Kriging Convolutional Networks
Jun 15, 2023

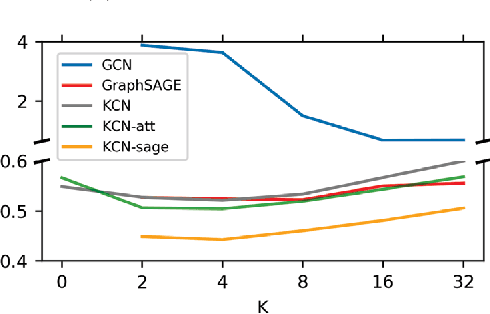

Spatial interpolation is a class of estimation problems where locations with known values are used to estimate values at other locations, with an emphasis on harnessing spatial locality and trends. Traditional Kriging methods have strong Gaussian assumptions, and as a result, often fail to capture complexities within the data. Inspired by the recent progress of graph neural networks, we introduce Kriging Convolutional Networks (KCN), a method of combining the advantages of Graph Convolutional Networks (GCN) and Kriging. Compared to standard GCNs, KCNs make direct use of neighboring observations when generating predictions. KCNs also contain the Kriging method as a specific configuration. We further improve the model's performance by adding attention. Empirically, we show that this model outperforms GCNs and Kriging in several applications. The implementation of KCN using PyTorch is publicized at the GitHub repository: https://github.com/tufts-ml/kcn-torch.
Graph-Based Model-Agnostic Data Subsampling for Recommendation Systems
May 25, 2023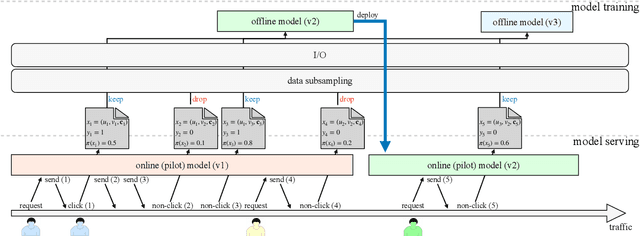
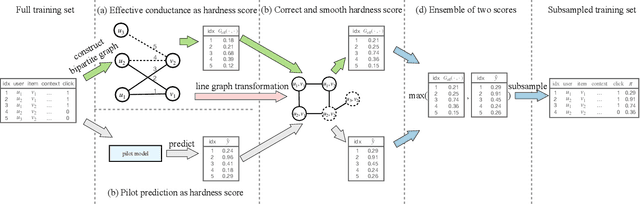

Data subsampling is widely used to speed up the training of large-scale recommendation systems. Most subsampling methods are model-based and often require a pre-trained pilot model to measure data importance via e.g. sample hardness. However, when the pilot model is misspecified, model-based subsampling methods deteriorate. Since model misspecification is persistent in real recommendation systems, we instead propose model-agnostic data subsampling methods by only exploring input data structure represented by graphs. Specifically, we study the topology of the user-item graph to estimate the importance of each user-item interaction (an edge in the user-item graph) via graph conductance, followed by a propagation step on the network to smooth out the estimated importance value. Since our proposed method is model-agnostic, we can marry the merits of both model-agnostic and model-based subsampling methods. Empirically, we show that combing the two consistently improves over any single method on the used datasets. Experimental results on KuaiRec and MIND datasets demonstrate that our proposed methods achieve superior results compared to baseline approaches.
Efficient and Degree-Guided Graph Generation via Discrete Diffusion Modeling
May 09, 2023

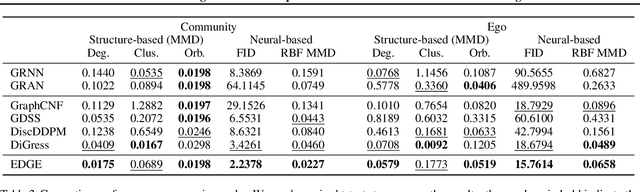
Diffusion-based generative graph models have been proven effective in generating high-quality small graphs. However, they need to be more scalable for generating large graphs containing thousands of nodes desiring graph statistics. In this work, we propose EDGE, a new diffusion-based generative graph model that addresses generative tasks with large graphs. To improve computation efficiency, we encourage graph sparsity by using a discrete diffusion process that randomly removes edges at each time step and finally obtains an empty graph. EDGE only focuses on a portion of nodes in the graph at each denoising step. It makes much fewer edge predictions than previous diffusion-based models. Moreover, EDGE admits explicitly modeling the node degrees of the graphs, further improving the model performance. The empirical study shows that EDGE is much more efficient than competing methods and can generate large graphs with thousands of nodes. It also outperforms baseline models in generation quality: graphs generated by our approach have more similar graph statistics to those of the training graphs.
PatchGT: Transformer over Non-trainable Clusters for Learning Graph Representations
Nov 26, 2022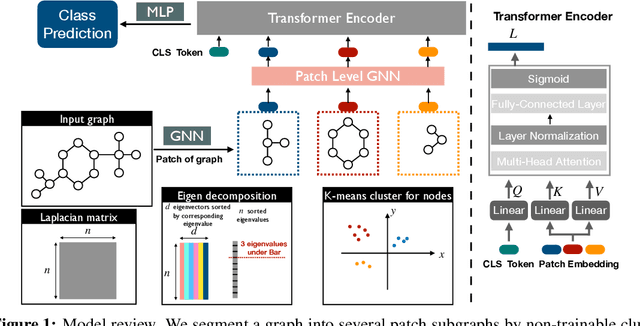


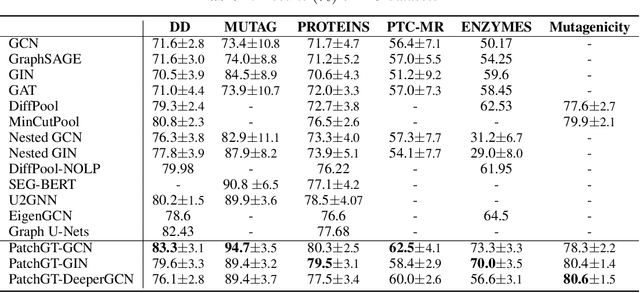
Recently the Transformer structure has shown good performances in graph learning tasks. However, these Transformer models directly work on graph nodes and may have difficulties learning high-level information. Inspired by the vision transformer, which applies to image patches, we propose a new Transformer-based graph neural network: Patch Graph Transformer (PatchGT). Unlike previous transformer-based models for learning graph representations, PatchGT learns from non-trainable graph patches, not from nodes directly. It can help save computation and improve the model performance. The key idea is to segment a graph into patches based on spectral clustering without any trainable parameters, with which the model can first use GNN layers to learn patch-level representations and then use Transformer to obtain graph-level representations. The architecture leverages the spectral information of graphs and combines the strengths of GNNs and Transformers. Further, we show the limitations of previous hierarchical trainable clusters theoretically and empirically. We also prove the proposed non-trainable spectral clustering method is permutation invariant and can help address the information bottlenecks in the graph. PatchGT achieves higher expressiveness than 1-WL-type GNNs, and the empirical study shows that PatchGT achieves competitive performances on benchmark datasets and provides interpretability to its predictions. The implementation of our algorithm is released at our Github repo: https://github.com/tufts-ml/PatchGT.
Towards Accurate Subgraph Similarity Computation via Neural Graph Pruning
Oct 19, 2022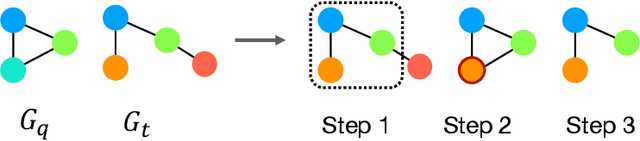
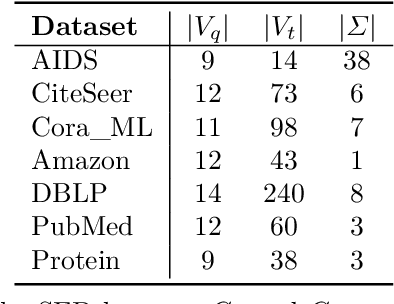
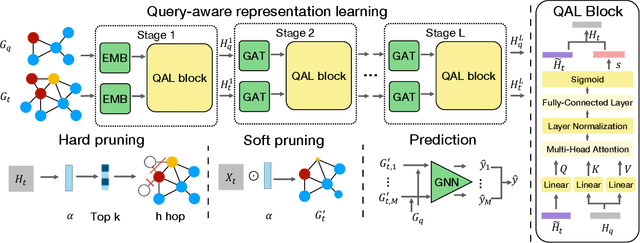

Subgraph similarity search, one of the core problems in graph search, concerns whether a target graph approximately contains a query graph. The problem is recently touched by neural methods. However, current neural methods do not consider pruning the target graph, though pruning is critically important in traditional calculations of subgraph similarities. One obstacle to applying pruning in neural methods is {the discrete property of pruning}. In this work, we convert graph pruning to a problem of node relabeling and then relax it to a differentiable problem. Based on this idea, we further design a novel neural network to approximate a type of subgraph distance: the subgraph edit distance (SED). {In particular, we construct the pruning component using a neural structure, and the entire model can be optimized end-to-end.} In the design of the model, we propose an attention mechanism to leverage the information about the query graph and guide the pruning of the target graph. Moreover, we develop a multi-head pruning strategy such that the model can better explore multiple ways of pruning the target graph. The proposed model establishes new state-of-the-art results across seven benchmark datasets. Extensive analysis of the model indicates that the proposed model can reasonably prune the target graph for SED computation. The implementation of our algorithm is released at our Github repo: https://github.com/tufts-ml/Prune4SED.
Predicting Physics in Mesh-reduced Space with Temporal Attention
Jan 22, 2022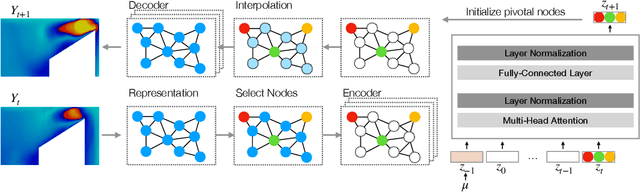

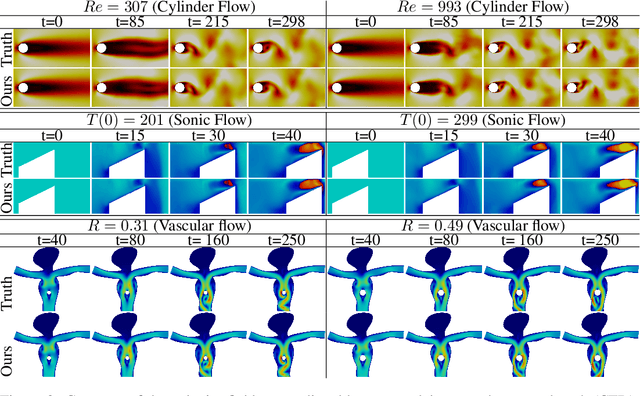

Graph-based next-step prediction models have recently been very successful in modeling complex high-dimensional physical systems on irregular meshes. However, due to their short temporal attention span, these models suffer from error accumulation and drift. In this paper, we propose a new method that captures long-term dependencies through a transformer-style temporal attention model. We introduce an encoder-decoder structure to summarize features and create a compact mesh representation of the system state, to allow the temporal model to operate on a low-dimensional mesh representations in a memory efficient manner. Our method outperforms a competitive GNN baseline on several complex fluid dynamics prediction tasks, from sonic shocks to vascular flow. We demonstrate stable rollouts without the need for training noise and show perfectly phase-stable predictions even for very long sequences. More broadly, we believe our approach paves the way to bringing the benefits of attention-based sequence models to solving high-dimensional complex physics tasks.