 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLi Yu
From Optimization to Generalization: Fair Federated Learning against Quality Shift via Inter-Client Sharpness Matching
Apr 27, 2024
Due to escalating privacy concerns, federated learning has been recognized as a vital approach for training deep neural networks with decentralized medical data. In practice, it is challenging to ensure consistent imaging quality across various institutions, often attributed to equipment malfunctions affecting a minority of clients. This imbalance in image quality can cause the federated model to develop an inherent bias towards higher-quality images, thus posing a severe fairness issue. In this study, we pioneer the identification and formulation of this new fairness challenge within the context of the imaging quality shift. Traditional methods for promoting fairness in federated learning predominantly focus on balancing empirical risks across diverse client distributions. This strategy primarily facilitates fair optimization across different training data distributions, yet neglects the crucial aspect of generalization. To address this, we introduce a solution termed Federated learning with Inter-client Sharpness Matching (FedISM). FedISM enhances both local training and global aggregation by incorporating sharpness-awareness, aiming to harmonize the sharpness levels across clients for fair generalization. Our empirical evaluations, conducted using the widely-used ICH and ISIC 2019 datasets, establish FedISM's superiority over current state-of-the-art federated learning methods in promoting fairness. Code is available at https://github.com/wnn2000/FFL4MIA.
Unsupervised Anomaly Detection via Masked Diffusion Posterior Sampling
Apr 27, 2024Reconstruction-based methods have been commonly used for unsupervised anomaly detection, in which a normal image is reconstructed and compared with the given test image to detect and locate anomalies. Recently, diffusion models have shown promising applications for anomaly detection due to their powerful generative ability. However, these models lack strict mathematical support for normal image reconstruction and unexpectedly suffer from low reconstruction quality. To address these issues, this paper proposes a novel and highly-interpretable method named Masked Diffusion Posterior Sampling (MDPS). In MDPS, the problem of normal image reconstruction is mathematically modeled as multiple diffusion posterior sampling for normal images based on the devised masked noisy observation model and the diffusion-based normal image prior under Bayesian framework. Using a metric designed from pixel-level and perceptual-level perspectives, MDPS can effectively compute the difference map between each normal posterior sample and the given test image. Anomaly scores are obtained by averaging all difference maps for multiple posterior samples. Exhaustive experiments on MVTec and BTAD datasets demonstrate that MDPS can achieve state-of-the-art performance in normal image reconstruction quality as well as anomaly detection and localization.
Pointsoup: High-Performance and Extremely Low-Decoding-Latency Learned Geometry Codec for Large-Scale Point Cloud Scenes
Apr 21, 2024Despite considerable progress being achieved in point cloud geometry compression, there still remains a challenge in effectively compressing large-scale scenes with sparse surfaces. Another key challenge lies in reducing decoding latency, a crucial requirement in real-world application. In this paper, we propose Pointsoup, an efficient learning-based geometry codec that attains high-performance and extremely low-decoding-latency simultaneously. Inspired by conventional Trisoup codec, a point model-based strategy is devised to characterize local surfaces. Specifically, skin features are embedded from local windows via an attention-based encoder, and dilated windows are introduced as cross-scale priors to infer the distribution of quantized features in parallel. During decoding, features undergo fast refinement, followed by a folding-based point generator that reconstructs point coordinates with fairly fast speed. Experiments show that Pointsoup achieves state-of-the-art performance on multiple benchmarks with significantly lower decoding complexity, i.e., up to 90$\sim$160$\times$ faster than the G-PCCv23 Trisoup decoder on a comparatively low-end platform (e.g., one RTX 2080Ti). Furthermore, it offers variable-rate control with a single neural model (2.9MB), which is attractive for industrial practitioners.
Digital Twin Channel for 6G: Concepts, Architectures and Potential Applications
Mar 31, 2024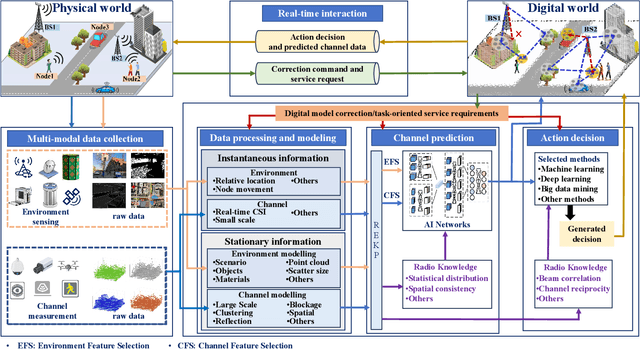

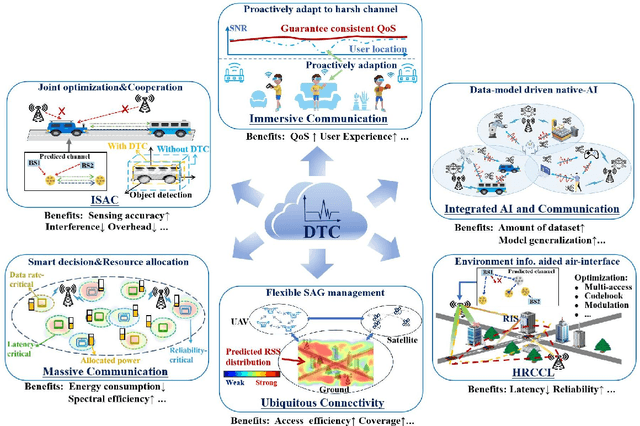
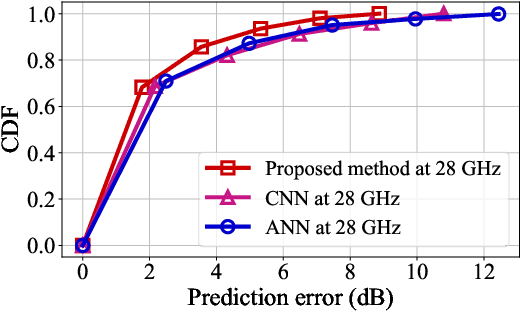
Digital twin channel (DTC) is the real-time mapping of a wireless channel from the physical world to the digital world, which is expected to provide significant performance enhancements for the sixth-generation (6G) air-interface design. In this work, we first define five evolution levels of channel twins with the progression of wireless communication. The fifth level, autonomous DTC, is elaborated with multi-dimensional factors such as methodology, characterization precision, and data category. Then, we provide detailed insights into the requirements and architecture of a complete DTC for 6G. Subsequently, a sensing-enhanced real-time channel prediction platform and experimental validations are exhibited. Finally, drawing from the vision of the 6G network, we explore the potential applications and the open issues in future DTC research.
SAMCT: Segment Any CT Allowing Labor-Free Task-Indicator Prompts
Mar 20, 2024
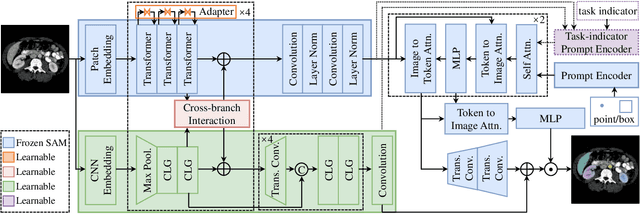
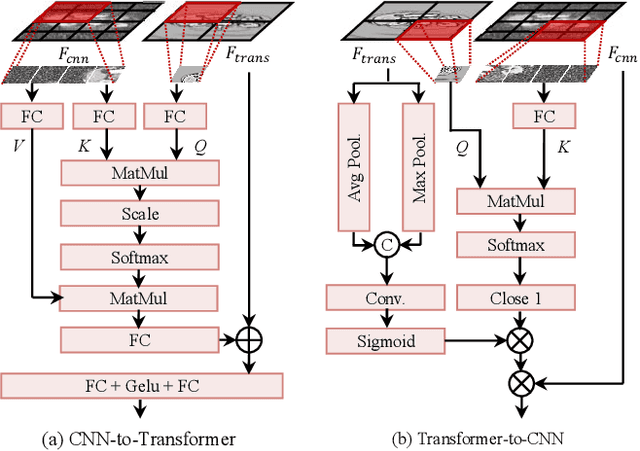

Segment anything model (SAM), a foundation model with superior versatility and generalization across diverse segmentation tasks, has attracted widespread attention in medical imaging. However, it has been proved that SAM would encounter severe performance degradation due to the lack of medical knowledge in training and local feature encoding. Though several SAM-based models have been proposed for tuning SAM in medical imaging, they still suffer from insufficient feature extraction and highly rely on high-quality prompts. In this paper, we construct a large CT dataset consisting of 1.1M CT images and 5M masks from public datasets and propose a powerful foundation model SAMCT allowing labor-free prompts. Specifically, based on SAM, SAMCT is further equipped with a U-shaped CNN image encoder, a cross-branch interaction module, and a task-indicator prompt encoder. The U-shaped CNN image encoder works in parallel with the ViT image encoder in SAM to supplement local features. Cross-branch interaction enhances the feature expression capability of the CNN image encoder and the ViT image encoder by exchanging global perception and local features from one to the other. The task-indicator prompt encoder is a plug-and-play component to effortlessly encode task-related indicators into prompt embeddings. In this way, SAMCT can work in an automatic manner in addition to the semi-automatic interactive strategy in SAM. Extensive experiments demonstrate the superiority of SAMCT against the state-of-the-art task-specific and SAM-based medical foundation models on various tasks. The code, data, and models are released at https://github.com/xianlin7/SAMCT.
Joint End-to-End Image Compression and Denoising: Leveraging Contrastive Learning and Multi-Scale Self-ONNs
Feb 08, 2024Noisy images are a challenge to image compression algorithms due to the inherent difficulty of compressing noise. As noise cannot easily be discerned from image details, such as high-frequency signals, its presence leads to extra bits needed for compression. Since the emerging learned image compression paradigm enables end-to-end optimization of codecs, recent efforts were made to integrate denoising into the compression model, relying on clean image features to guide denoising. However, these methods exhibit suboptimal performance under high noise levels, lacking the capability to generalize across diverse noise types. In this paper, we propose a novel method integrating a multi-scale denoiser comprising of Self Organizing Operational Neural Networks, for joint image compression and denoising. We employ contrastive learning to boost the network ability to differentiate noise from high frequency signal components, by emphasizing the correlation between noisy and clean counterparts. Experimental results demonstrate the effectiveness of the proposed method both in rate-distortion performance, and codec speed, outperforming the current state-of-the-art.
Panoramic Image Inpainting With Gated Convolution And Contextual Reconstruction Loss
Feb 05, 2024Deep learning-based methods have demonstrated encouraging results in tackling the task of panoramic image inpainting. However, it is challenging for existing methods to distinguish valid pixels from invalid pixels and find suitable references for corrupted areas, thus leading to artifacts in the inpainted results. In response to these challenges, we propose a panoramic image inpainting framework that consists of a Face Generator, a Cube Generator, a side branch, and two discriminators. We use the Cubemap Projection (CMP) format as network input. The generator employs gated convolutions to distinguish valid pixels from invalid ones, while a side branch is designed utilizing contextual reconstruction (CR) loss to guide the generators to find the most suitable reference patch for inpainting the missing region. The proposed method is compared with state-of-the-art (SOTA) methods on SUN360 Street View dataset in terms of PSNR and SSIM. Experimental results and ablation study demonstrate that the proposed method outperforms SOTA both quantitatively and qualitatively.
FedA3I: Annotation Quality-Aware Aggregation for Federated Medical Image Segmentation Against Heterogeneous Annotation Noise
Dec 20, 2023Federated learning (FL) has emerged as a promising paradigm for training segmentation models on decentralized medical data, owing to its privacy-preserving property. However, existing research overlooks the prevalent annotation noise encountered in real-world medical datasets, which limits the performance ceilings of FL. In this paper, we, for the first time, identify and tackle this problem. For problem formulation, we propose a contour evolution for modeling non-independent and identically distributed (Non-IID) noise across pixels within each client and then extend it to the case of multi-source data to form a heterogeneous noise model (\textit{i.e.}, Non-IID annotation noise across clients). For robust learning from annotations with such two-level Non-IID noise, we emphasize the importance of data quality in model aggregation, allowing high-quality clients to have a greater impact on FL. To achieve this, we propose \textbf{Fed}erated learning with \textbf{A}nnotation qu\textbf{A}lity-aware \textbf{A}ggregat\textbf{I}on, named \textbf{FedA$^3$I}, by introducing a quality factor based on client-wise noise estimation. Specifically, noise estimation at each client is accomplished through the Gaussian mixture model and then incorporated into model aggregation in a layer-wise manner to up-weight high-quality clients. Extensive experiments on two real-world medical image segmentation datasets demonstrate the superior performance of FedA$^3$I against the state-of-the-art approaches in dealing with cross-client annotation noise. The code is available at \color{blue}{https://github.com/wnn2000/FedAAAI}.
Exploration of visual prompt in Grounded pre-trained open-set detection
Dec 14, 2023Text prompts are crucial for generalizing pre-trained open-set object detection models to new categories. However, current methods for text prompts are limited as they require manual feedback when generalizing to new categories, which restricts their ability to model complex scenes, often leading to incorrect detection results. To address this limitation, we propose a novel visual prompt method that learns new category knowledge from a few labeled images, which generalizes the pre-trained detection model to the new category. To allow visual prompts to represent new categories adequately, we propose a statistical-based prompt construction module that is not limited by predefined vocabulary lengths, thus allowing more vectors to be used when representing categories. We further utilize the category dictionaries in the pre-training dataset to design task-specific similarity dictionaries, which make visual prompts more discriminative. We evaluate the method on the ODinW dataset and show that it outperforms existing prompt learning methods and performs more consistently in combinatorial inference.
Boosting Facial Action Unit Detection Through Jointly Learning Facial Landmark Detection and Domain Separation and Reconstruction
Oct 08, 2023Recently how to introduce large amounts of unlabeled facial images in the wild into supervised Facial Action Unit (AU) detection frameworks has become a challenging problem. In this paper, we propose a new AU detection framework where multi-task learning is introduced to jointly learn AU domain separation and reconstruction and facial landmark detection by sharing the parameters of homostructural facial extraction modules. In addition, we propose a new feature alignment scheme based on contrastive learning by simple projectors and an improved contrastive loss, which adds four additional intermediate supervisors to promote the feature reconstruction process. Experimental results on two benchmarks demonstrate our superiority against the state-of-the-art methods for AU detection in the wild.