 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKai Liu
Training-free Boost for Open-Vocabulary Object Detection with Confidence Aggregation
Apr 12, 2024
Open-vocabulary object detection (OVOD) aims at localizing and recognizing visual objects from novel classes unseen at the training time. Whereas, empirical studies reveal that advanced detectors generally assign lower scores to those novel instances, which are inadvertently suppressed during inference by commonly adopted greedy strategies like Non-Maximum Suppression (NMS), leading to sub-optimal detection performance for novel classes. This paper systematically investigates this problem with the commonly-adopted two-stage OVOD paradigm. Specifically, in the region-proposal stage, proposals that contain novel instances showcase lower objectness scores, since they are treated as background proposals during the training phase. Meanwhile, in the object-classification stage, novel objects share lower region-text similarities (i.e., classification scores) due to the biased visual-language alignment by seen training samples. To alleviate this problem, this paper introduces two advanced measures to adjust confidence scores and conserve erroneously dismissed objects: (1) a class-agnostic localization quality estimate via overlap degree of region/object proposals, and (2) a text-guided visual similarity estimate with proxy prototypes for novel classes. Integrated with adjusting techniques specifically designed for the region-proposal and object-classification stages, this paper derives the aggregated confidence estimate for the open-vocabulary object detection paradigm (AggDet). Our AggDet is a generic and training-free post-processing scheme, which consistently bolsters open-vocabulary detectors across model scales and architecture designs. For instance, AggDet receives 3.3% and 1.5% gains on OV-COCO and OV-LVIS benchmarks respectively, without any training cost.
Binomial Self-compensation for Motion Error in Dynamic 3D Scanning
Apr 10, 2024Phase shifting profilometry (PSP) is favored in high-precision 3D scanning due to its high accuracy, robustness, and pixel-wise property. However, a fundamental assumption of PSP that the object should remain static is violated in dynamic measurement, making PSP susceptible to object moving, resulting in ripple-like errors in the point clouds. We propose a pixel-wise and frame-wise loopable binomial self-compensation (BSC) algorithm to effectively and flexibly eliminate motion error in the four-step PSP. Our mathematical model demonstrates that by summing successive motion-affected phase frames weighted by binomial coefficients, motion error exponentially diminishes as the binomial order increases, accomplishing automatic error compensation through the motion-affected phase sequence, without the assistance of any intermediate variable. Extensive experiments show that our BSC outperforms the existing methods in reducing motion error, while achieving a depth map frame rate equal to the camera's acquisition rate (90 fps), enabling high-accuracy 3D reconstruction with a quasi-single-shot frame rate.
HoloVIC: Large-scale Dataset and Benchmark for Multi-Sensor Holographic Intersection and Vehicle-Infrastructure Cooperative
Mar 06, 2024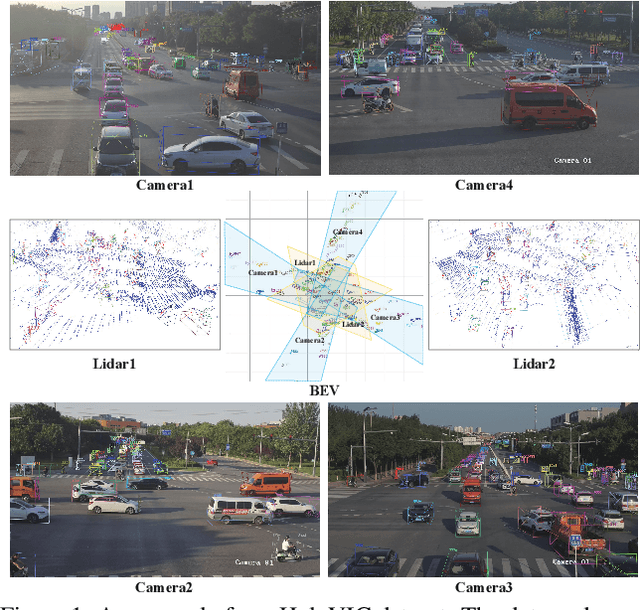
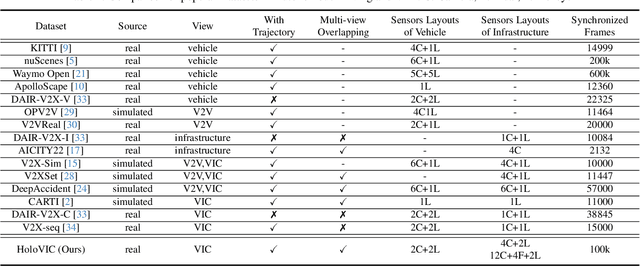
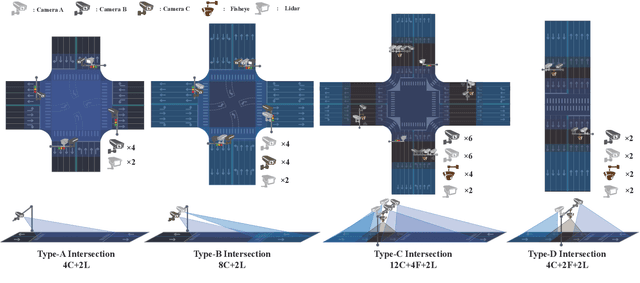

Vehicle-to-everything (V2X) is a popular topic in the field of Autonomous Driving in recent years. Vehicle-infrastructure cooperation (VIC) becomes one of the important research area. Due to the complexity of traffic conditions such as blind spots and occlusion, it greatly limits the perception capabilities of single-view roadside sensing systems. To further enhance the accuracy of roadside perception and provide better information to the vehicle side, in this paper, we constructed holographic intersections with various layouts to build a large-scale multi-sensor holographic vehicle-infrastructure cooperation dataset, called HoloVIC. Our dataset includes 3 different types of sensors (Camera, Lidar, Fisheye) and employs 4 sensor-layouts based on the different intersections. Each intersection is equipped with 6-18 sensors to capture synchronous data. While autonomous vehicles pass through these intersections for collecting VIC data. HoloVIC contains in total on 100k+ synchronous frames from different sensors. Additionally, we annotated 3D bounding boxes based on Camera, Fisheye, and Lidar. We also associate the IDs of the same objects across different devices and consecutive frames in sequence. Based on HoloVIC, we formulated four tasks to facilitate the development of related research. We also provide benchmarks for these tasks.
EasyQuant: An Efficient Data-free Quantization Algorithm for LLMs
Mar 05, 2024


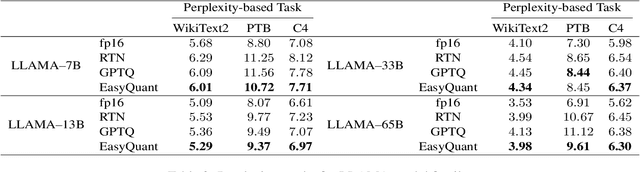
Large language models (LLMs) have proven to be very superior to conventional methods in various tasks. However, their expensive computations and high memory requirements are prohibitive for deployment. Model quantization is an effective method for reducing this overhead. The problem is that in most previous works, the quantized model was calibrated using few samples from the training data, which might affect the generalization of the quantized LLMs to unknown cases and tasks. Hence in this work, we explore an important question: Can we design a data-independent quantization method for LLMs to guarantee its generalization performance? In this work, we propose EasyQuant, a training-free and data-independent weight-only quantization algorithm for LLMs. Our observation indicates that two factors: outliers in the weight and quantization ranges, are essential for reducing the quantization error. Therefore, in EasyQuant, we leave the outliers (less than 1%) unchanged and optimize the quantization range to reduce the reconstruction error. With these methods, we surprisingly find that EasyQuant achieves comparable performance to the original model. Since EasyQuant does not depend on any training data, the generalization performance of quantized LLMs is safely guaranteed. Moreover, EasyQuant can be implemented in parallel so that the quantized model could be attained in a few minutes even for LLMs over 100B. To our best knowledge, we are the first work that achieves almost lossless quantization performance for LLMs under a data-independent setting and our algorithm runs over 10 times faster than the data-dependent methods.
INSIDE: LLMs' Internal States Retain the Power of Hallucination Detection
Feb 06, 2024Knowledge hallucination have raised widespread concerns for the security and reliability of deployed LLMs. Previous efforts in detecting hallucinations have been employed at logit-level uncertainty estimation or language-level self-consistency evaluation, where the semantic information is inevitably lost during the token-decoding procedure. Thus, we propose to explore the dense semantic information retained within LLMs' \textbf{IN}ternal \textbf{S}tates for halluc\textbf{I}nation \textbf{DE}tection (\textbf{INSIDE}). In particular, a simple yet effective \textbf{EigenScore} metric is proposed to better evaluate responses' self-consistency, which exploits the eigenvalues of responses' covariance matrix to measure the semantic consistency/diversity in the dense embedding space. Furthermore, from the perspective of self-consistent hallucination detection, a test time feature clipping approach is explored to truncate extreme activations in the internal states, which reduces overconfident generations and potentially benefits the detection of overconfident hallucinations. Extensive experiments and ablation studies are performed on several popular LLMs and question-answering (QA) benchmarks, showing the effectiveness of our proposal.
Optimal Parameter and Neuron Pruning for Out-of-Distribution Detection
Feb 04, 2024For a machine learning model deployed in real world scenarios, the ability of detecting out-of-distribution (OOD) samples is indispensable and challenging. Most existing OOD detection methods focused on exploring advanced training skills or training-free tricks to prevent the model from yielding overconfident confidence score for unknown samples. The training-based methods require expensive training cost and rely on OOD samples which are not always available, while most training-free methods can not efficiently utilize the prior information from the training data. In this work, we propose an \textbf{O}ptimal \textbf{P}arameter and \textbf{N}euron \textbf{P}runing (\textbf{OPNP}) approach, which aims to identify and remove those parameters and neurons that lead to over-fitting. The main method is divided into two steps. In the first step, we evaluate the sensitivity of the model parameters and neurons by averaging gradients over all training samples. In the second step, the parameters and neurons with exceptionally large or close to zero sensitivities are removed for prediction. Our proposal is training-free, compatible with other post-hoc methods, and exploring the information from all training data. Extensive experiments are performed on multiple OOD detection tasks and model architectures, showing that our proposed OPNP consistently outperforms the existing methods by a large margin.
* Accepted by NeurIPS 2023. 19 pages
Query-LIFE: Query-aware Language Image Fusion Embedding for E-Commerce Relevance
Nov 26, 2023Relevance module plays a fundamental role in e-commerce search as they are responsible for selecting relevant products from thousands of items based on user queries, thereby enhancing users experience and efficiency. The traditional approach models the relevance based product titles and queries, but the information in titles alone maybe insufficient to describe the products completely. A more general optimization approach is to further leverage product image information. In recent years, vision-language pre-training models have achieved impressive results in many scenarios, which leverage contrastive learning to map both textual and visual features into a joint embedding space. In e-commerce, a common practice is to fine-tune on the pre-trained model based on e-commerce data. However, the performance is sub-optimal because the vision-language pre-training models lack of alignment specifically designed for queries. In this paper, we propose a method called Query-LIFE (Query-aware Language Image Fusion Embedding) to address these challenges. Query-LIFE utilizes a query-based multimodal fusion to effectively incorporate the image and title based on the product types. Additionally, it employs query-aware modal alignment to enhance the accuracy of the comprehensive representation of products. Furthermore, we design GenFilt, which utilizes the generation capability of large models to filter out false negative samples and further improve the overall performance of the contrastive learning task in the model. Experiments have demonstrated that Query-LIFE outperforms existing baselines. We have conducted ablation studies and human evaluations to validate the effectiveness of each module within Query-LIFE. Moreover, Query-LIFE has been deployed on Miravia Search, resulting in improved both relevance and conversion efficiency.
Phase Guided Light Field for Spatial-Depth High Resolution 3D Imaging
Nov 17, 2023On 3D imaging, light field cameras typically are of single shot, and however, they heavily suffer from low spatial resolution and depth accuracy. In this paper, by employing an optical projector to project a group of single high-frequency phase-shifted sinusoid patterns, we propose a phase guided light field algorithm to significantly improve both the spatial and depth resolutions for off-the-shelf light field cameras. First, for correcting the axial aberrations caused by the main lens of our light field camera, we propose a deformed cone model to calibrate our structured light field system. Second, over wrapped phases computed from patterned images, we propose a stereo matching algorithm, i.e. phase guided sum of absolute difference, to robustly obtain the correspondence for each pair of neighbored two lenslets. Finally, by introducing a virtual camera according to the basic geometrical optics of light field imaging, we propose a reorganization strategy to reconstruct 3D point clouds with spatial-depth high resolution. Experimental results show that, compared with the state-of-the-art active light field methods, the proposed reconstructs 3D point clouds with a spatial resolution of 1280$\times$720 with factors 10$\times$ increased, while maintaining the same high depth resolution and needing merely a single group of high-frequency patterns.
A Spatial-Temporal Transformer based Framework For Human Pose Assessment And Correction in Education Scenarios
Nov 01, 2023Human pose assessment and correction play a crucial role in applications across various fields, including computer vision, robotics, sports analysis, healthcare, and entertainment. In this paper, we propose a Spatial-Temporal Transformer based Framework (STTF) for human pose assessment and correction in education scenarios such as physical exercises and science experiment. The framework comprising skeletal tracking, pose estimation, posture assessment, and posture correction modules to educate students with professional, quick-to-fix feedback. We also create a pose correction method to provide corrective feedback in the form of visual aids. We test the framework with our own dataset. It comprises (a) new recordings of five exercises, (b) existing recordings found on the internet of the same exercises, and (c) corrective feedback on the recordings by professional athletes and teachers. Results show that our model can effectively measure and comment on the quality of students' actions. The STTF leverages the power of transformer models to capture spatial and temporal dependencies in human poses, enabling accurate assessment and effective correction of students' movements.
E-Sparse: Boosting the Large Language Model Inference through Entropy-based N:M Sparsity
Oct 24, 2023Traditional pruning methods are known to be challenging to work in Large Language Models (LLMs) for Generative AI because of their unaffordable training process and large computational demands. For the first time, we introduce the information entropy of hidden state features into a pruning metric design, namely E-Sparse, to improve the accuracy of N:M sparsity on LLM. E-Sparse employs the information richness to leverage the channel importance, and further incorporates several novel techniques to put it into effect: (1) it introduces information entropy to enhance the significance of parameter weights and input feature norms as a novel pruning metric, and performs N:M sparsity without modifying the remaining weights. (2) it designs global naive shuffle and local block shuffle to quickly optimize the information distribution and adequately cope with the impact of N:M sparsity on LLMs' accuracy. E-Sparse is implemented as a Sparse-GEMM on FasterTransformer and runs on NVIDIA Ampere GPUs. Extensive experiments on the LLaMA family and OPT models show that E-Sparse can significantly speed up the model inference over the dense model (up to 1.53X) and obtain significant memory saving (up to 43.52%), with acceptable accuracy loss.