 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJieping Ye
Robust Preference Optimization with Provable Noise Tolerance for LLMs
Apr 05, 2024
The preference alignment aims to enable large language models (LLMs) to generate responses that conform to human values, which is essential for developing general AI systems. Ranking-based methods -- a promising class of alignment approaches -- learn human preferences from datasets containing response pairs by optimizing the log-likelihood margins between preferred and dis-preferred responses. However, due to the inherent differences in annotators' preferences, ranking labels of comparisons for response pairs are unavoidably noisy. This seriously hurts the reliability of existing ranking-based methods. To address this problem, we propose a provably noise-tolerant preference alignment method, namely RObust Preference Optimization (ROPO). To the best of our knowledge, ROPO is the first preference alignment method with noise-tolerance guarantees. The key idea of ROPO is to dynamically assign conservative gradient weights to response pairs with high label uncertainty, based on the log-likelihood margins between the responses. By effectively suppressing the gradients of noisy samples, our weighting strategy ensures that the expected risk has the same gradient direction independent of the presence and proportion of noise. Experiments on three open-ended text generation tasks with four base models ranging in size from 2.8B to 13B demonstrate that ROPO significantly outperforms existing ranking-based methods.
Learning Neural Volumetric Pose Features for Camera Localization
Mar 19, 2024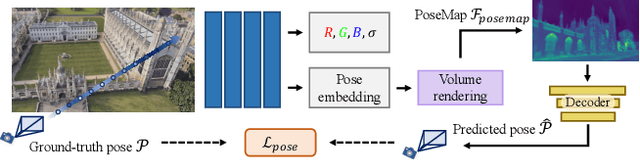

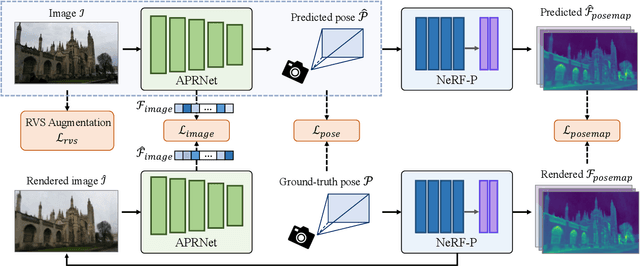
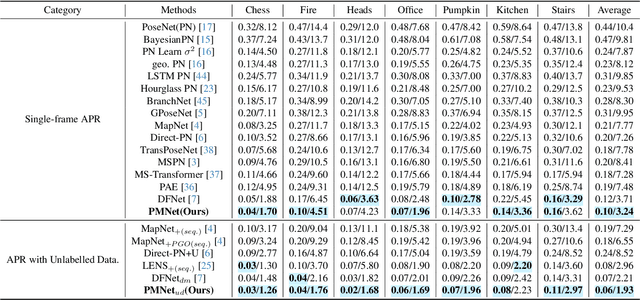
We introduce a novel neural volumetric pose feature, termed PoseMap, designed to enhance camera localization by encapsulating the information between images and the associated camera poses. Our framework leverages an Absolute Pose Regression (APR) architecture, together with an augmented NeRF module. This integration not only facilitates the generation of novel views to enrich the training dataset but also enables the learning of effective pose features. Additionally, we extend our architecture for self-supervised online alignment, allowing our method to be used and fine-tuned for unlabelled images within a unified framework. Experiments demonstrate that our method achieves 14.28% and 20.51% performance gain on average in indoor and outdoor benchmark scenes, outperforming existing APR methods with state-of-the-art accuracy.
MiM-ISTD: Mamba-in-Mamba for Efficient Infrared Small Target Detection
Mar 08, 2024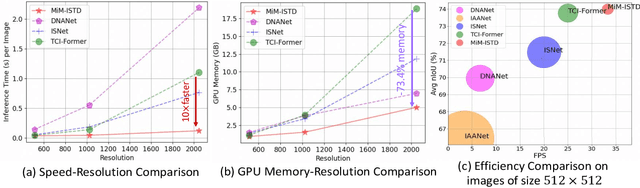
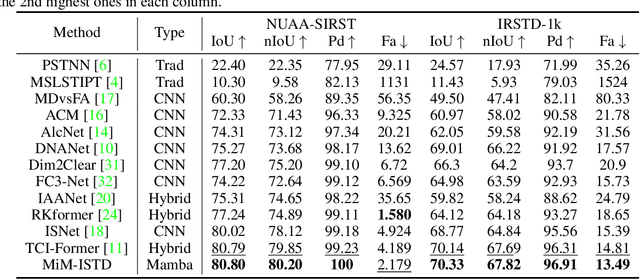
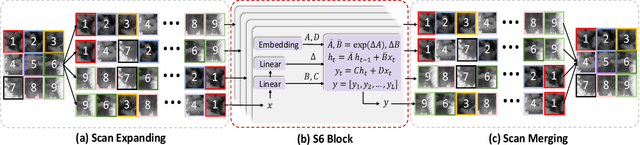
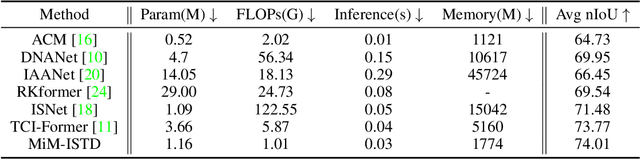
Recently, infrared small target detection (ISTD) has made significant progress, thanks to the development of basic models. Specifically, the structures combining convolutional networks with transformers can successfully extract both local and global features. However, the disadvantage of the transformer is also inherited, i.e., the quadratic computational complexity to the length of the sequence. Inspired by the recent basic model with linear complexity for long-distance modeling, called Mamba, we explore the potential of this state space model for ISTD task in terms of effectiveness and efficiency in the paper. However, directly applying Mamba achieves poor performance since local features, which are critical to detecting small targets, cannot be fully exploited. Instead, we tailor a Mamba-in-Mamba (MiM-ISTD) structure for efficient ISTD. Specifically, we treat the local patches as "visual sentences" and use the Outer Mamba to explore the global information. We then decompose each visual sentence into sub-patches as "visual words" and use the Inner Mamba to further explore the local information among words in the visual sentence with negligible computational costs. By aggregating the word and sentence features, the MiM-ISTD can effectively explore both global and local information. Experiments on NUAA-SIRST and IRSTD-1k show the superior accuracy and efficiency of our method. Specifically, MiM-ISTD is $10 \times$ faster than the SOTA method and reduces GPU memory usage by 73.4$\%$ when testing on $2048 \times 2048$ image, overcoming the computation and memory constraints on high-resolution infrared images. Source code is available at https://github.com/txchen-USTC/MiM-ISTD.
IBD: Alleviating Hallucinations in Large Vision-Language Models via Image-Biased Decoding
Feb 28, 2024Despite achieving rapid developments and with widespread applications, Large Vision-Language Models (LVLMs) confront a serious challenge of being prone to generating hallucinations. An over-reliance on linguistic priors has been identified as a key factor leading to these hallucinations. In this paper, we propose to alleviate this problem by introducing a novel image-biased decoding (IBD) technique. Our method derives the next-token probability distribution by contrasting predictions from a conventional LVLM with those of an image-biased LVLM, thereby amplifying the correct information highly correlated with image content while mitigating the hallucinatory errors caused by excessive dependence on text. We further conduct a comprehensive statistical analysis to validate the reliability of our method, and design an adaptive adjustment strategy to achieve robust and flexible handling under varying conditions. Experimental results across multiple evaluation metrics verify that our method, despite not requiring additional training data and only with a minimal increase in model parameters, can significantly reduce hallucinations in LVLMs and enhance the truthfulness of the generated response.
Bootstrapping Audio-Visual Segmentation by Strengthening Audio Cues
Feb 06, 2024How to effectively interact audio with vision has garnered considerable interest within the multi-modality research field. Recently, a novel audio-visual segmentation (AVS) task has been proposed, aiming to segment the sounding objects in video frames under the guidance of audio cues. However, most existing AVS methods are hindered by a modality imbalance where the visual features tend to dominate those of the audio modality, due to a unidirectional and insufficient integration of audio cues. This imbalance skews the feature representation towards the visual aspect, impeding the learning of joint audio-visual representations and potentially causing segmentation inaccuracies. To address this issue, we propose AVSAC. Our approach features a Bidirectional Audio-Visual Decoder (BAVD) with integrated bidirectional bridges, enhancing audio cues and fostering continuous interplay between audio and visual modalities. This bidirectional interaction narrows the modality imbalance, facilitating more effective learning of integrated audio-visual representations. Additionally, we present a strategy for audio-visual frame-wise synchrony as fine-grained guidance of BAVD. This strategy enhances the share of auditory components in visual features, contributing to a more balanced audio-visual representation learning. Extensive experiments show that our method attains new benchmarks in AVS performance.
INSIDE: LLMs' Internal States Retain the Power of Hallucination Detection
Feb 06, 2024Knowledge hallucination have raised widespread concerns for the security and reliability of deployed LLMs. Previous efforts in detecting hallucinations have been employed at logit-level uncertainty estimation or language-level self-consistency evaluation, where the semantic information is inevitably lost during the token-decoding procedure. Thus, we propose to explore the dense semantic information retained within LLMs' \textbf{IN}ternal \textbf{S}tates for halluc\textbf{I}nation \textbf{DE}tection (\textbf{INSIDE}). In particular, a simple yet effective \textbf{EigenScore} metric is proposed to better evaluate responses' self-consistency, which exploits the eigenvalues of responses' covariance matrix to measure the semantic consistency/diversity in the dense embedding space. Furthermore, from the perspective of self-consistent hallucination detection, a test time feature clipping approach is explored to truncate extreme activations in the internal states, which reduces overconfident generations and potentially benefits the detection of overconfident hallucinations. Extensive experiments and ablation studies are performed on several popular LLMs and question-answering (QA) benchmarks, showing the effectiveness of our proposal.
Optimal Parameter and Neuron Pruning for Out-of-Distribution Detection
Feb 04, 2024For a machine learning model deployed in real world scenarios, the ability of detecting out-of-distribution (OOD) samples is indispensable and challenging. Most existing OOD detection methods focused on exploring advanced training skills or training-free tricks to prevent the model from yielding overconfident confidence score for unknown samples. The training-based methods require expensive training cost and rely on OOD samples which are not always available, while most training-free methods can not efficiently utilize the prior information from the training data. In this work, we propose an \textbf{O}ptimal \textbf{P}arameter and \textbf{N}euron \textbf{P}runing (\textbf{OPNP}) approach, which aims to identify and remove those parameters and neurons that lead to over-fitting. The main method is divided into two steps. In the first step, we evaluate the sensitivity of the model parameters and neurons by averaging gradients over all training samples. In the second step, the parameters and neurons with exceptionally large or close to zero sensitivities are removed for prediction. Our proposal is training-free, compatible with other post-hoc methods, and exploring the information from all training data. Extensive experiments are performed on multiple OOD detection tasks and model architectures, showing that our proposed OPNP consistently outperforms the existing methods by a large margin.
* Accepted by NeurIPS 2023. 19 pages
LLaFS: When Large-Language Models Meet Few-Shot Segmentation
Dec 05, 2023This paper proposes LLaFS, the first attempt to leverage large language models (LLMs) in few-shot segmentation. In contrast to the conventional few-shot segmentation methods that only rely on the limited and biased information from the annotated support images, LLaFS leverages the vast prior knowledge gained by LLM as an effective supplement and directly uses the LLM to segment images in a few-shot manner. To enable the text-based LLM to handle image-related tasks, we carefully design an input instruction that allows the LLM to produce segmentation results represented as polygons, and propose a region-attribute table to simulate the human visual mechanism and provide multi-modal guidance. We also synthesize pseudo samples and use curriculum learning for pretraining to augment data and achieve better optimization. LLaFS achieves state-of-the-art results on multiple datasets, showing the potential of using LLMs for few-shot computer vision tasks. Code will be available at https://github.com/lanyunzhu99/LLaFS.