 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJianxiao Zou
Unsupervised Anomaly Detection via Masked Diffusion Posterior Sampling
Apr 27, 2024
Reconstruction-based methods have been commonly used for unsupervised anomaly detection, in which a normal image is reconstructed and compared with the given test image to detect and locate anomalies. Recently, diffusion models have shown promising applications for anomaly detection due to their powerful generative ability. However, these models lack strict mathematical support for normal image reconstruction and unexpectedly suffer from low reconstruction quality. To address these issues, this paper proposes a novel and highly-interpretable method named Masked Diffusion Posterior Sampling (MDPS). In MDPS, the problem of normal image reconstruction is mathematically modeled as multiple diffusion posterior sampling for normal images based on the devised masked noisy observation model and the diffusion-based normal image prior under Bayesian framework. Using a metric designed from pixel-level and perceptual-level perspectives, MDPS can effectively compute the difference map between each normal posterior sample and the given test image. Anomaly scores are obtained by averaging all difference maps for multiple posterior samples. Exhaustive experiments on MVTec and BTAD datasets demonstrate that MDPS can achieve state-of-the-art performance in normal image reconstruction quality as well as anomaly detection and localization.
Variational Probabilistic Fusion Network for RGB-T Semantic Segmentation
Jul 17, 2023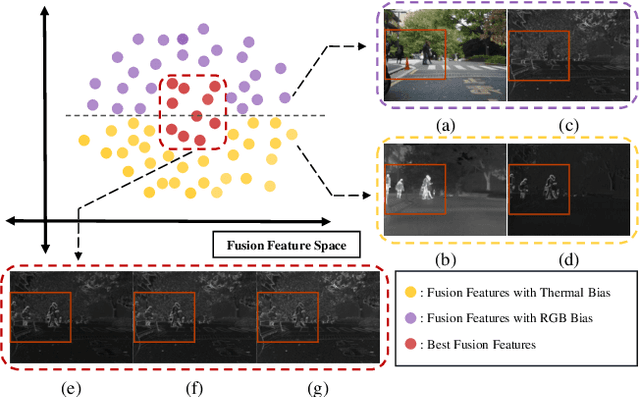
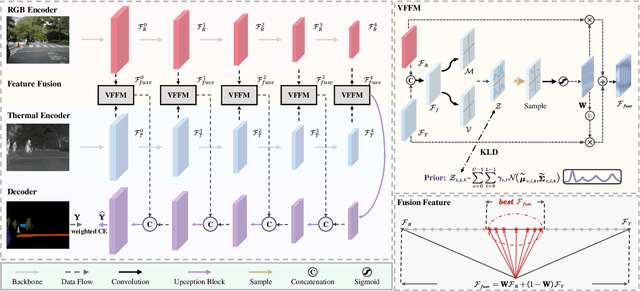

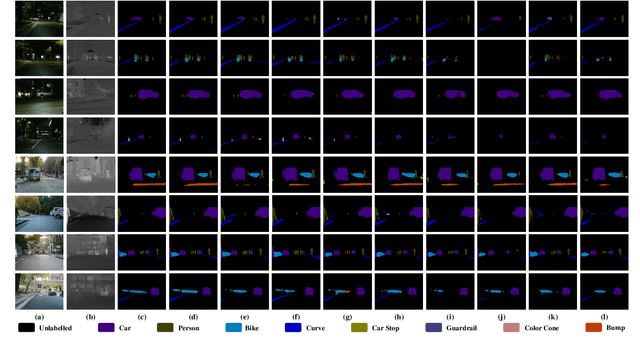
RGB-T semantic segmentation has been widely adopted to handle hard scenes with poor lighting conditions by fusing different modality features of RGB and thermal images. Existing methods try to find an optimal fusion feature for segmentation, resulting in sensitivity to modality noise, class-imbalance, and modality bias. To overcome the problems, this paper proposes a novel Variational Probabilistic Fusion Network (VPFNet), which regards fusion features as random variables and obtains robust segmentation by averaging segmentation results under multiple samples of fusion features. The random samples generation of fusion features in VPFNet is realized by a novel Variational Feature Fusion Module (VFFM) designed based on variation attention. To further avoid class-imbalance and modality bias, we employ the weighted cross-entropy loss and introduce prior information of illumination and category to control the proposed VFFM. Experimental results on MFNet and PST900 datasets demonstrate that the proposed VPFNet can achieve state-of-the-art segmentation performance.
Rethinking the competition between detection and ReID in Multi-Object Tracking
Oct 23, 2020

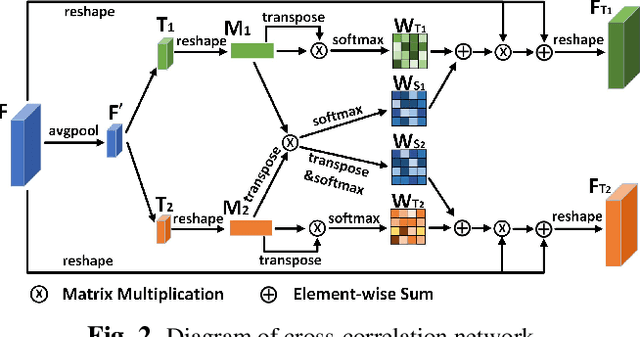

Due to balanced accuracy and speed, joint learning detection and ReID-based one-shot models have drawn great attention in multi-object tracking(MOT). However, the differences between the above two tasks in the one-shot tracking paradigm are unconsciously overlooked, leading to inferior performance than the two-stage methods. In this paper, we dissect the reasoning process of the aforementioned two tasks. Our analysis reveals that the competition of them inevitably hurts the learning of task-dependent representations, which further impedes the tracking performance. To remedy this issue, we propose a novel cross-correlation network that can effectively impel the separate branches to learn task-dependent representations. Furthermore, we introduce a scale-aware attention network that learns discriminative embeddings to improve the ReID capability. We integrate the delicately designed networks into a one-shot online MOT system, dubbed CSTrack. Without bells and whistles, our model achieves new state-of-the-art performances on MOT16 and MOT17. We will release our code to facilitate further work.