 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDifei Gao
Delocate: Detection and Localization for Deepfake Videos with Randomly-Located Tampered Traces
Jan 24, 2024
Deepfake videos are becoming increasingly realistic, showing subtle tampering traces on facial areasthat vary between frames. Consequently, many existing Deepfake detection methods struggle to detect unknown domain Deepfake videos while accurately locating the tampered region. To address thislimitation, we propose Delocate, a novel Deepfake detection model that can both recognize andlocalize unknown domain Deepfake videos. Ourmethod consists of two stages named recoveringand localization. In the recovering stage, the modelrandomly masks regions of interest (ROIs) and reconstructs real faces without tampering traces, resulting in a relatively good recovery effect for realfaces and a poor recovery effect for fake faces. Inthe localization stage, the output of the recoveryphase and the forgery ground truth mask serve assupervision to guide the forgery localization process. This process strategically emphasizes the recovery phase of fake faces with poor recovery, facilitating the localization of tampered regions. Ourextensive experiments on four widely used benchmark datasets demonstrate that Delocate not onlyexcels in localizing tampered areas but also enhances cross-domain detection performance.
ASSISTGUI: Task-Oriented Desktop Graphical User Interface Automation
Jan 01, 2024Graphical User Interface (GUI) automation holds significant promise for assisting users with complex tasks, thereby boosting human productivity. Existing works leveraging Large Language Model (LLM) or LLM-based AI agents have shown capabilities in automating tasks on Android and Web platforms. However, these tasks are primarily aimed at simple device usage and entertainment operations. This paper presents a novel benchmark, AssistGUI, to evaluate whether models are capable of manipulating the mouse and keyboard on the Windows platform in response to user-requested tasks. We carefully collected a set of 100 tasks from nine widely-used software applications, such as, After Effects and MS Word, each accompanied by the necessary project files for better evaluation. Moreover, we propose an advanced Actor-Critic Embodied Agent framework, which incorporates a sophisticated GUI parser driven by an LLM-agent and an enhanced reasoning mechanism adept at handling lengthy procedural tasks. Our experimental results reveal that our GUI Parser and Reasoning mechanism outshine existing methods in performance. Nevertheless, the potential remains substantial, with the best model attaining only a 46% success rate on our benchmark. We conclude with a thorough analysis of the current methods' limitations, setting the stage for future breakthroughs in this domain.
ViT-Lens-2: Gateway to Omni-modal Intelligence
Nov 27, 2023Aiming to advance AI agents, large foundation models significantly improve reasoning and instruction execution, yet the current focus on vision and language neglects the potential of perceiving diverse modalities in open-world environments. However, the success of data-driven vision and language models is costly or even infeasible to be reproduced for rare modalities. In this paper, we present ViT-Lens-2 that facilitates efficient omni-modal representation learning by perceiving novel modalities with a pretrained ViT and aligning them to a pre-defined space. Specifically, the modality-specific lens is tuned to project any-modal signals to an intermediate embedding space, which are then processed by a strong ViT with pre-trained visual knowledge. The encoded representations are optimized toward aligning with the modal-independent space, pre-defined by off-the-shelf foundation models. ViT-Lens-2 provides a unified solution for representation learning of increasing modalities with two appealing advantages: (i) Unlocking the great potential of pretrained ViTs to novel modalities effectively with efficient data regime; (ii) Enabling emergent downstream capabilities through modality alignment and shared ViT parameters. We tailor ViT-Lens-2 to learn representations for 3D point cloud, depth, audio, tactile and EEG, and set new state-of-the-art results across various understanding tasks, such as zero-shot classification. By seamlessly integrating ViT-Lens-2 into Multimodal Foundation Models, we enable Any-modality to Text and Image Generation in a zero-shot manner. Code and models are available at https://github.com/TencentARC/ViT-Lens.
CVPR 2023 Text Guided Video Editing Competition
Oct 24, 2023Humans watch more than a billion hours of video per day. Most of this video was edited manually, which is a tedious process. However, AI-enabled video-generation and video-editing is on the rise. Building on text-to-image models like Stable Diffusion and Imagen, generative AI has improved dramatically on video tasks. But it's hard to evaluate progress in these video tasks because there is no standard benchmark. So, we propose a new dataset for text-guided video editing (TGVE), and we run a competition at CVPR to evaluate models on our TGVE dataset. In this paper we present a retrospective on the competition and describe the winning method. The competition dataset is available at https://sites.google.com/view/loveucvpr23/track4.
Show-1: Marrying Pixel and Latent Diffusion Models for Text-to-Video Generation
Sep 27, 2023



Significant advancements have been achieved in the realm of large-scale pre-trained text-to-video Diffusion Models (VDMs). However, previous methods either rely solely on pixel-based VDMs, which come with high computational costs, or on latent-based VDMs, which often struggle with precise text-video alignment. In this paper, we are the first to propose a hybrid model, dubbed as Show-1, which marries pixel-based and latent-based VDMs for text-to-video generation. Our model first uses pixel-based VDMs to produce a low-resolution video of strong text-video correlation. After that, we propose a novel expert translation method that employs the latent-based VDMs to further upsample the low-resolution video to high resolution. Compared to latent VDMs, Show-1 can produce high-quality videos of precise text-video alignment; Compared to pixel VDMs, Show-1 is much more efficient (GPU memory usage during inference is 15G vs 72G). We also validate our model on standard video generation benchmarks. Our code and model weights are publicly available at \url{https://github.com/showlab/Show-1}.
Recap: Detecting Deepfake Video with Unpredictable Tampered Traces via Recovering Faces and Mapping Recovered Faces
Aug 19, 2023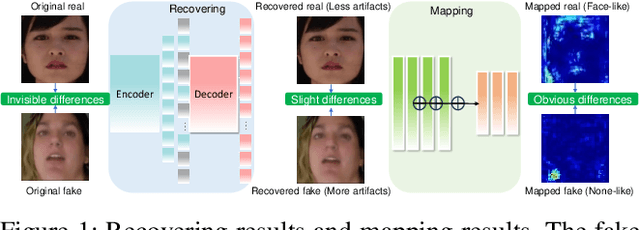
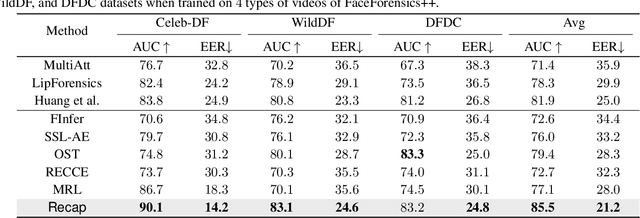
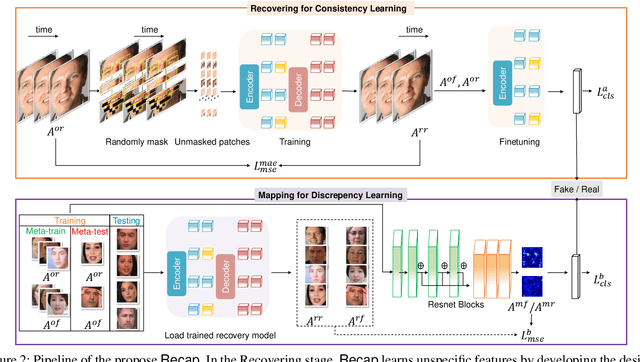
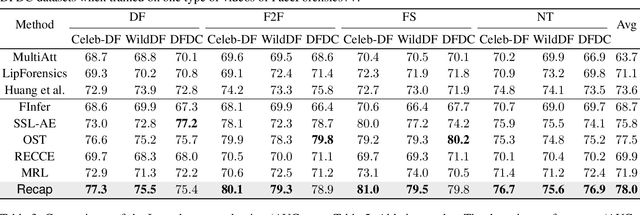
The exploitation of Deepfake techniques for malicious intentions has driven significant research interest in Deepfake detection. Deepfake manipulations frequently introduce random tampered traces, leading to unpredictable outcomes in different facial regions. However, existing detection methods heavily rely on specific forgery indicators, and as the forgery mode improves, these traces become increasingly randomized, resulting in a decline in the detection performance of methods reliant on specific forgery traces. To address the limitation, we propose Recap, a novel Deepfake detection model that exposes unspecific facial part inconsistencies by recovering faces and enlarges the differences between real and fake by mapping recovered faces. In the recovering stage, the model focuses on randomly masking regions of interest (ROIs) and reconstructing real faces without unpredictable tampered traces, resulting in a relatively good recovery effect for real faces while a poor recovery effect for fake faces. In the mapping stage, the output of the recovery phase serves as supervision to guide the facial mapping process. This mapping process strategically emphasizes the mapping of fake faces with poor recovery, leading to a further deterioration in their representation, while enhancing and refining the mapping of real faces with good representation. As a result, this approach significantly amplifies the discrepancies between real and fake videos. Our extensive experiments on standard benchmarks demonstrate that Recap is effective in multiple scenarios.
UniVTG: Towards Unified Video-Language Temporal Grounding
Aug 18, 2023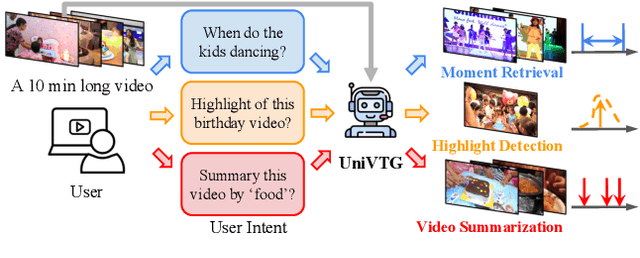
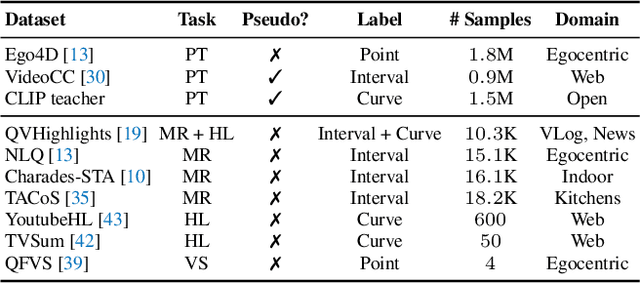
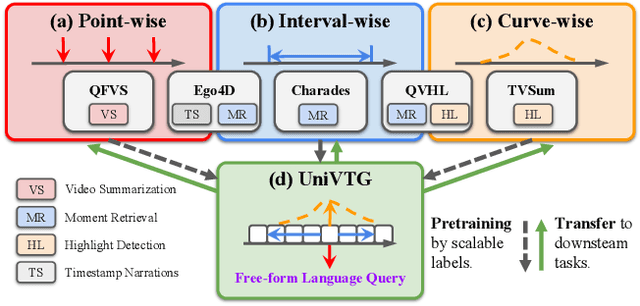
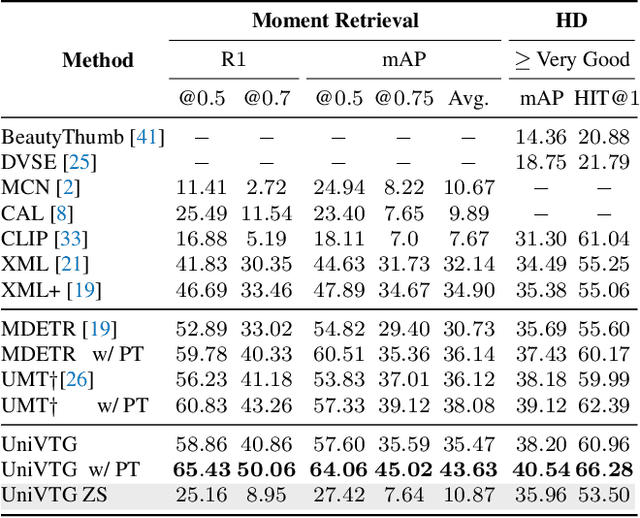
Video Temporal Grounding (VTG), which aims to ground target clips from videos (such as consecutive intervals or disjoint shots) according to custom language queries (e.g., sentences or words), is key for video browsing on social media. Most methods in this direction develop taskspecific models that are trained with type-specific labels, such as moment retrieval (time interval) and highlight detection (worthiness curve), which limits their abilities to generalize to various VTG tasks and labels. In this paper, we propose to Unify the diverse VTG labels and tasks, dubbed UniVTG, along three directions: Firstly, we revisit a wide range of VTG labels and tasks and define a unified formulation. Based on this, we develop data annotation schemes to create scalable pseudo supervision. Secondly, we develop an effective and flexible grounding model capable of addressing each task and making full use of each label. Lastly, thanks to the unified framework, we are able to unlock temporal grounding pretraining from large-scale diverse labels and develop stronger grounding abilities e.g., zero-shot grounding. Extensive experiments on three tasks (moment retrieval, highlight detection and video summarization) across seven datasets (QVHighlights, Charades-STA, TACoS, Ego4D, YouTube Highlights, TVSum, and QFVS) demonstrate the effectiveness and flexibility of our proposed framework. The codes are available at https://github.com/showlab/UniVTG.
AssistGPT: A General Multi-modal Assistant that can Plan, Execute, Inspect, and Learn
Jun 28, 2023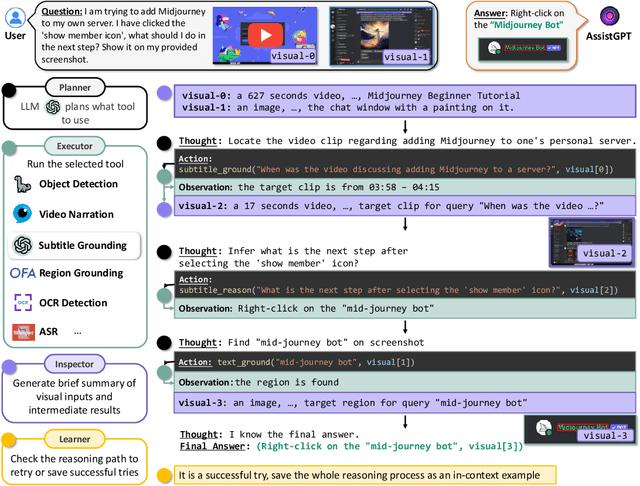


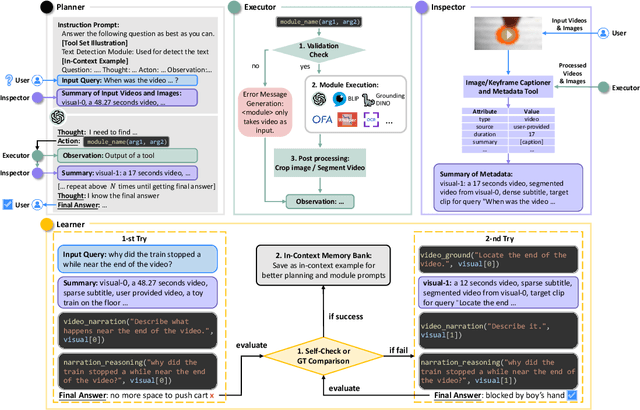
Recent research on Large Language Models (LLMs) has led to remarkable advancements in general NLP AI assistants. Some studies have further explored the use of LLMs for planning and invoking models or APIs to address more general multi-modal user queries. Despite this progress, complex visual-based tasks still remain challenging due to the diverse nature of visual tasks. This diversity is reflected in two aspects: 1) Reasoning paths. For many real-life applications, it is hard to accurately decompose a query simply by examining the query itself. Planning based on the specific visual content and the results of each step is usually required. 2) Flexible inputs and intermediate results. Input forms could be flexible for in-the-wild cases, and involves not only a single image or video but a mixture of videos and images, e.g., a user-view image with some reference videos. Besides, a complex reasoning process will also generate diverse multimodal intermediate results, e.g., video narrations, segmented video clips, etc. To address such general cases, we propose a multi-modal AI assistant, AssistGPT, with an interleaved code and language reasoning approach called Plan, Execute, Inspect, and Learn (PEIL) to integrate LLMs with various tools. Specifically, the Planner is capable of using natural language to plan which tool in Executor should do next based on the current reasoning progress. Inspector is an efficient memory manager to assist the Planner to feed proper visual information into a specific tool. Finally, since the entire reasoning process is complex and flexible, a Learner is designed to enable the model to autonomously explore and discover the optimal solution. We conducted experiments on A-OKVQA and NExT-QA benchmarks, achieving state-of-the-art results. Moreover, showcases demonstrate the ability of our system to handle questions far more complex than those found in the benchmarks.
GroundNLQ @ Ego4D Natural Language Queries Challenge 2023
Jun 27, 2023



In this report, we present our champion solution for Ego4D Natural Language Queries (NLQ) Challenge in CVPR 2023. Essentially, to accurately ground in a video, an effective egocentric feature extractor and a powerful grounding model are required. Motivated by this, we leverage a two-stage pre-training strategy to train egocentric feature extractors and the grounding model on video narrations, and further fine-tune the model on annotated data. In addition, we introduce a novel grounding model GroundNLQ, which employs a multi-modal multi-scale grounding module for effective video and text fusion and various temporal intervals, especially for long videos. On the blind test set, GroundNLQ achieves 25.67 and 18.18 for R1@IoU=0.3 and R1@IoU=0.5, respectively, and surpasses all other teams by a noticeable margin. Our code will be released at\url{https://github.com/houzhijian/GroundNLQ}.
Affordance Grounding from Demonstration Video to Target Image
Mar 26, 2023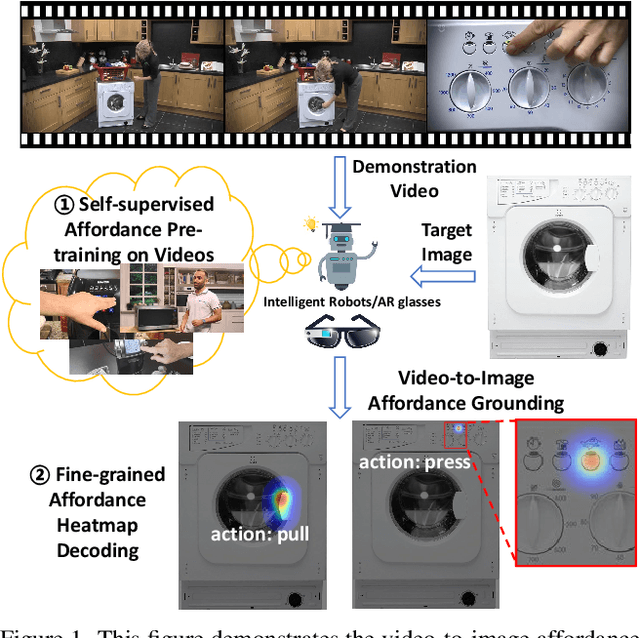
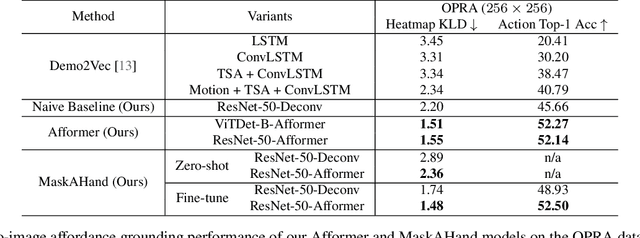
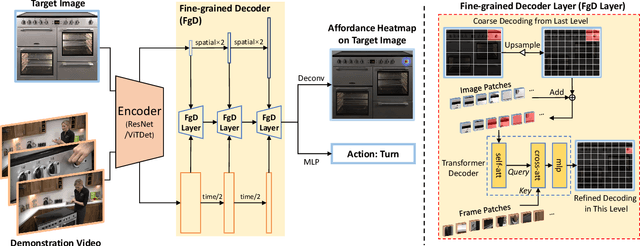
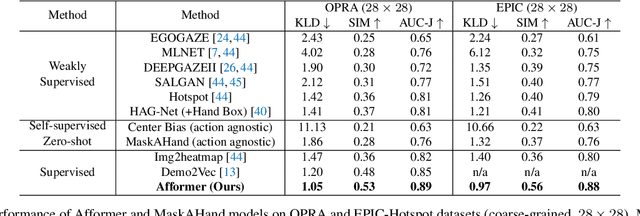
Humans excel at learning from expert demonstrations and solving their own problems. To equip intelligent robots and assistants, such as AR glasses, with this ability, it is essential to ground human hand interactions (i.e., affordances) from demonstration videos and apply them to a target image like a user's AR glass view. The video-to-image affordance grounding task is challenging due to (1) the need to predict fine-grained affordances, and (2) the limited training data, which inadequately covers video-image discrepancies and negatively impacts grounding. To tackle them, we propose Affordance Transformer (Afformer), which has a fine-grained transformer-based decoder that gradually refines affordance grounding. Moreover, we introduce Mask Affordance Hand (MaskAHand), a self-supervised pre-training technique for synthesizing video-image data and simulating context changes, enhancing affordance grounding across video-image discrepancies. Afformer with MaskAHand pre-training achieves state-of-the-art performance on multiple benchmarks, including a substantial 37% improvement on the OPRA dataset. Code is made available at https://github.com/showlab/afformer.