 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXu Cheng
CVPR 2023 Text Guided Video Editing Competition
Oct 24, 2023
Humans watch more than a billion hours of video per day. Most of this video was edited manually, which is a tedious process. However, AI-enabled video-generation and video-editing is on the rise. Building on text-to-image models like Stable Diffusion and Imagen, generative AI has improved dramatically on video tasks. But it's hard to evaluate progress in these video tasks because there is no standard benchmark. So, we propose a new dataset for text-guided video editing (TGVE), and we run a competition at CVPR to evaluate models on our TGVE dataset. In this paper we present a retrospective on the competition and describe the winning method. The competition dataset is available at https://sites.google.com/view/loveucvpr23/track4.
Modality Unifying Network for Visible-Infrared Person Re-Identification
Sep 12, 2023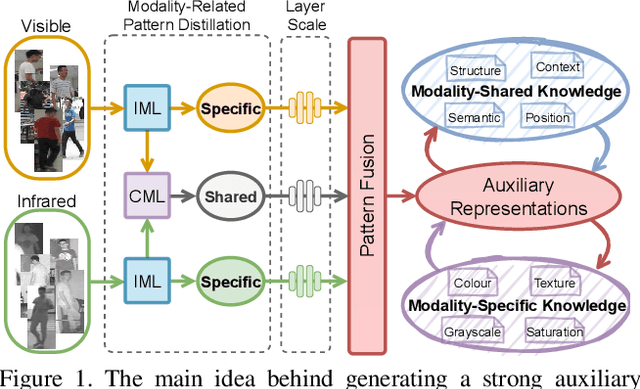
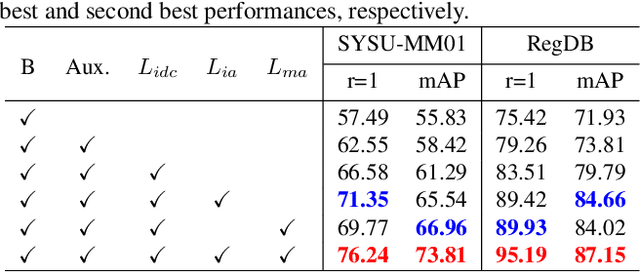
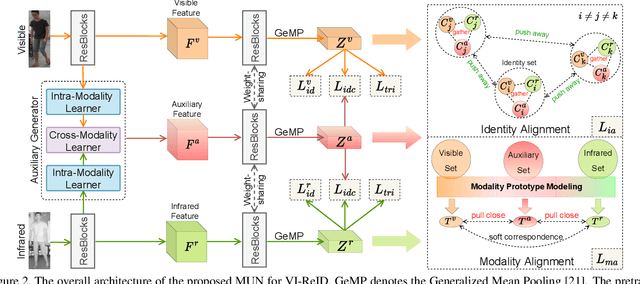

Visible-infrared person re-identification (VI-ReID) is a challenging task due to large cross-modality discrepancies and intra-class variations. Existing methods mainly focus on learning modality-shared representations by embedding different modalities into the same feature space. As a result, the learned feature emphasizes the common patterns across modalities while suppressing modality-specific and identity-aware information that is valuable for Re-ID. To address these issues, we propose a novel Modality Unifying Network (MUN) to explore a robust auxiliary modality for VI-ReID. First, the auxiliary modality is generated by combining the proposed cross-modality learner and intra-modality learner, which can dynamically model the modality-specific and modality-shared representations to alleviate both cross-modality and intra-modality variations. Second, by aligning identity centres across the three modalities, an identity alignment loss function is proposed to discover the discriminative feature representations. Third, a modality alignment loss is introduced to consistently reduce the distribution distance of visible and infrared images by modality prototype modeling. Extensive experiments on multiple public datasets demonstrate that the proposed method surpasses the current state-of-the-art methods by a significant margin.
MAE-GEBD:Winning the CVPR'2023 LOVEU-GEBD Challenge
Jun 27, 2023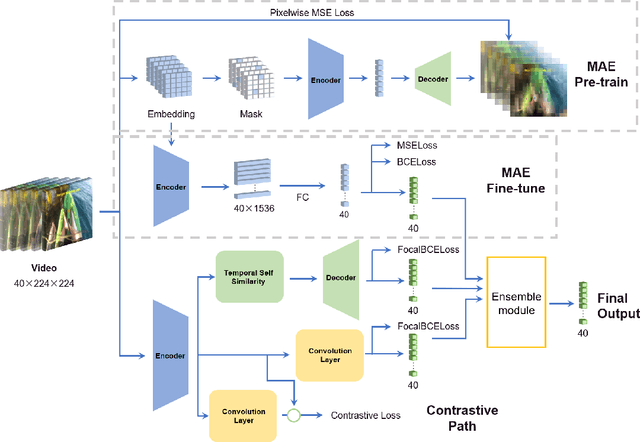
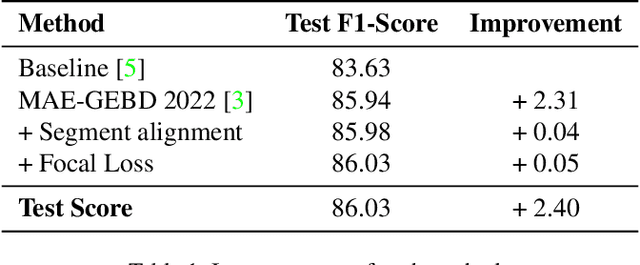
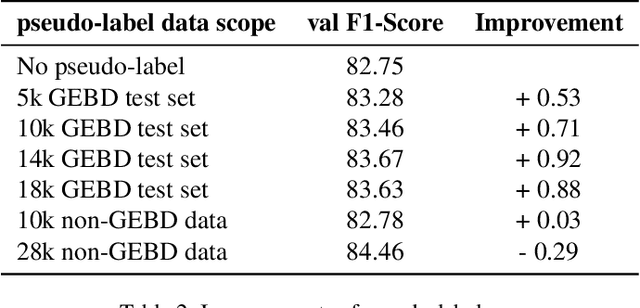
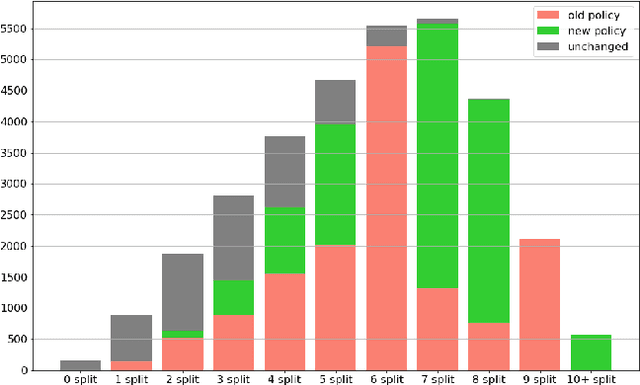
The Generic Event Boundary Detection (GEBD) task aims to build a model for segmenting videos into segments by detecting general event boundaries applicable to various classes. In this paper, based on last year's MAE-GEBD method, we have improved our model performance on the GEBD task by adjusting the data processing strategy and loss function. Based on last year's approach, we extended the application of pseudo-label to a larger dataset and made many experimental attempts. In addition, we applied focal loss to concentrate more on difficult samples and improved our model performance. Finally, we improved the segmentation alignment strategy used last year, and dynamically adjusted the segmentation alignment method according to the boundary density and duration of the video, so that our model can be more flexible and fully applicable in different situations. With our method, we achieve an F1 score of 86.03% on the Kinetics-GEBD test set, which is a 0.09% improvement in the F1 score compared to our 2022 Kinetics-GEBD method.
High-order Spatial Interactions Enhanced Lightweight Model for Optical Remote Sensing Image-based Small Ship Detection
Apr 07, 2023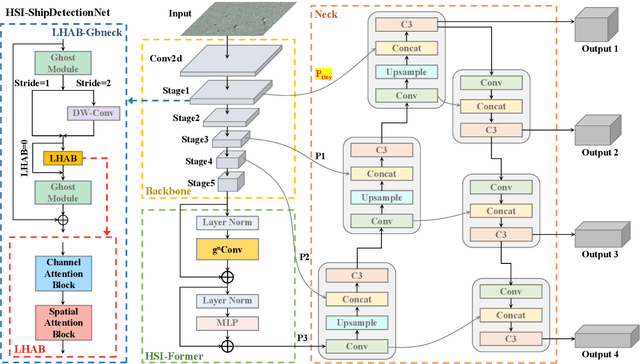
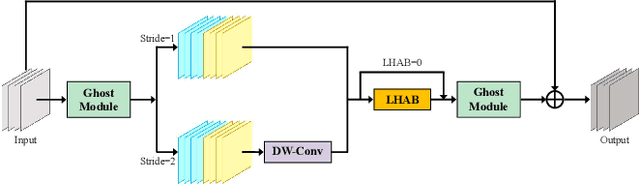
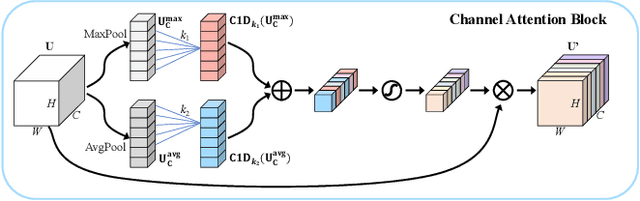
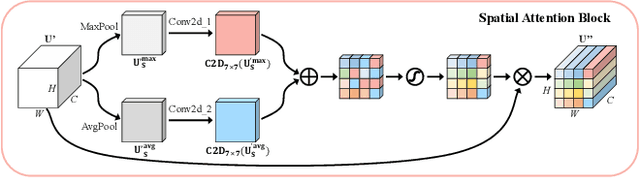
Accurate and reliable optical remote sensing image-based small-ship detection is crucial for maritime surveillance systems, but existing methods often struggle with balancing detection performance and computational complexity. In this paper, we propose a novel lightweight framework called \textit{HSI-ShipDetectionNet} that is based on high-order spatial interactions and is suitable for deployment on resource-limited platforms, such as satellites and unmanned aerial vehicles. HSI-ShipDetectionNet includes a prediction branch specifically for tiny ships and a lightweight hybrid attention block for reduced complexity. Additionally, the use of a high-order spatial interactions module improves advanced feature understanding and modeling ability. Our model is evaluated using the public Kaggle marine ship detection dataset and compared with multiple state-of-the-art models including small object detection models, lightweight detection models, and ship detection models. The results show that HSI-ShipDetectionNet outperforms the other models in terms of recall, and mean average precision (mAP) while being lightweight and suitable for deployment on resource-limited platforms.
Friend Recall in Online Games via Pre-training Edge Transformers
Feb 20, 2023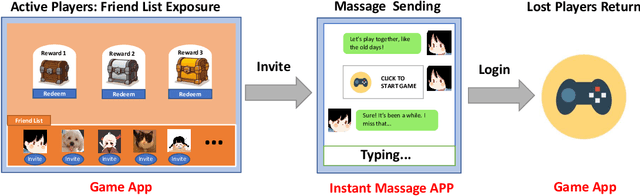
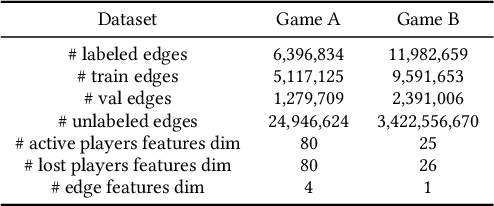

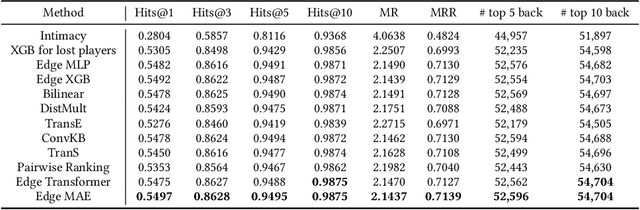
Friend recall is an important way to improve Daily Active Users (DAU) in Tencent games. Traditional friend recall methods focus on rules like friend intimacy or training a classifier for predicting lost players' return probability, but ignore feature information of (active) players and historical friend recall events. In this work, we treat friend recall as a link prediction problem and explore several link prediction methods which can use features of both active and lost players, as well as historical events. Furthermore, we propose a novel Edge Transformer model and pre-train the model via masked auto-encoders. Our method achieves state-of-the-art results in the offline experiments and online A/B Tests of three Tencent games.
Advancing 3D finger knuckle recognition via deep feature learning
Jan 07, 2023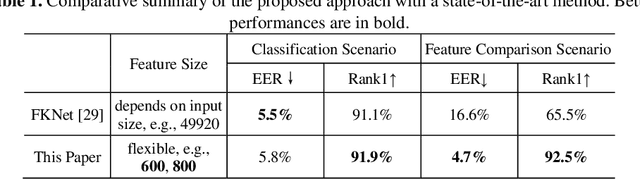
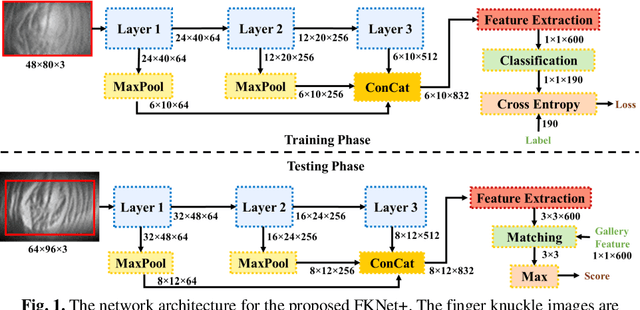
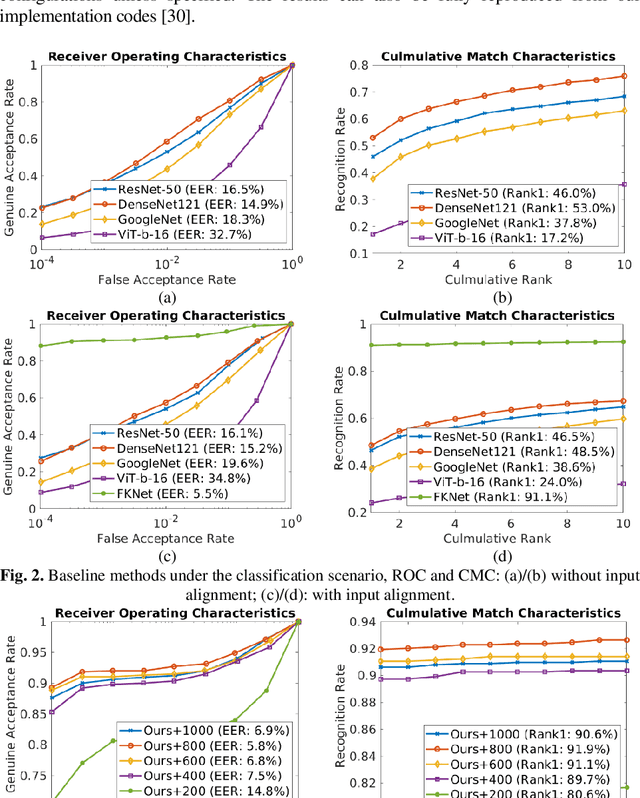
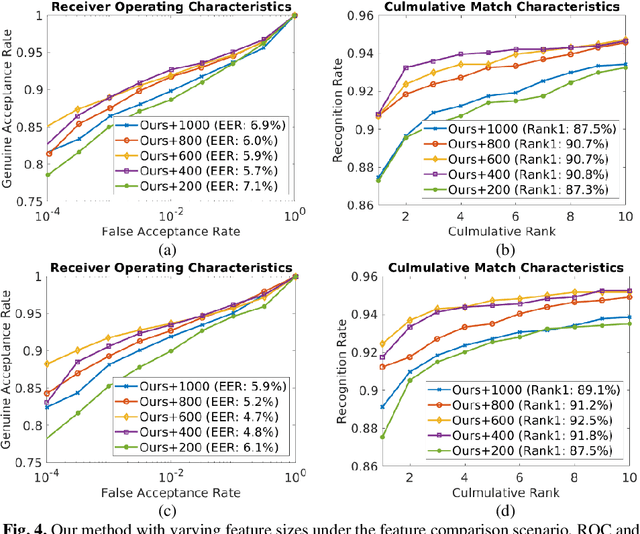
Contactless 3D finger knuckle patterns have emerged as an effective biometric identifier due to its discriminativeness, visibility from a distance, and convenience. Recent research has developed a deep feature collaboration network which simultaneously incorporates intermediate features from deep neural networks with multiple scales. However, this approach results in a large feature dimension, and the trained classification layer is required for comparing probe samples, which limits the introduction of new classes. This paper advances this approach by investigating the possibility of learning a discriminative feature vector with the least possible dimension for representing 3D finger knuckle images. Experimental results are presented using a publicly available 3D finger knuckle images database with comparisons to popular deep learning architectures and the state-of-the-art 3D finger knuckle recognition methods. The proposed approach offers outperforming results in classification and identification tasks under the more practical feature comparison scenario, i.e., using the extracted deep feature instead of the trained classification layer for comparing probe samples. More importantly, this approach can offer 99% reduction in the size of feature templates, which is highly attractive for deploying biometric systems in the real world. Experiments are also performed using other two public biometric databases with similar patterns to ascertain the effectiveness and generalizability of our proposed approach.
Improving Few-Shot Performance of Language Models via Nearest Neighbor Calibration
Dec 05, 2022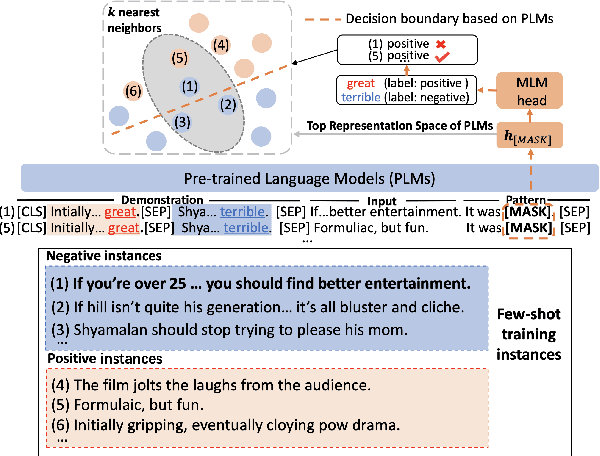
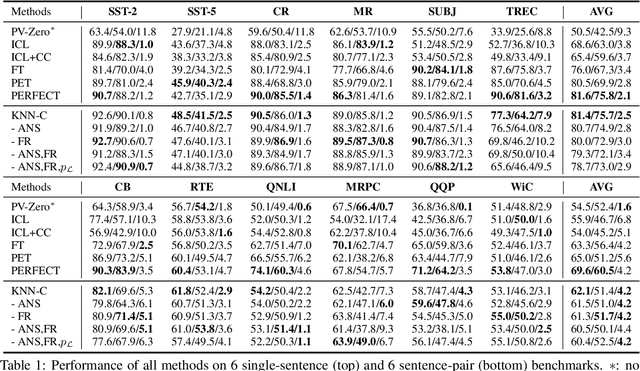
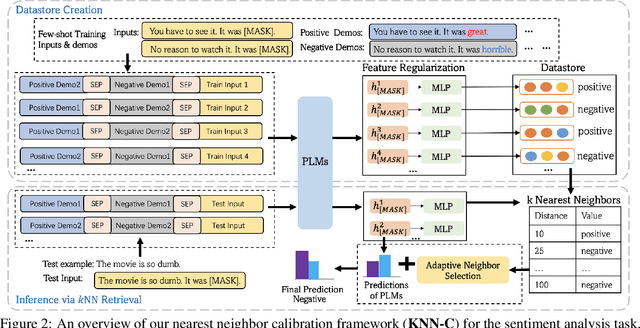
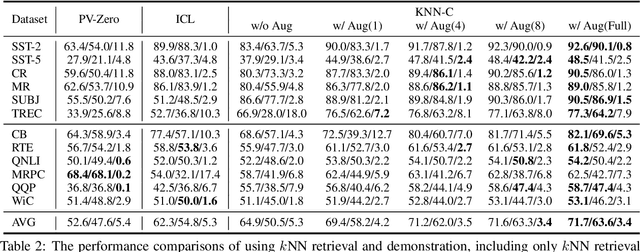
Pre-trained language models (PLMs) have exhibited remarkable few-shot learning capabilities when provided a few examples in a natural language prompt as demonstrations of test instances, i.e., in-context learning. However, the performance of in-context learning is susceptible to the choice of prompt format, training examples and the ordering of the training examples. In this paper, we propose a novel nearest-neighbor calibration framework for in-context learning to ease this issue. It is inspired by a phenomenon that the in-context learning paradigm produces incorrect labels when inferring training instances, which provides a useful supervised signal to calibrate predictions. Thus, our method directly augments the predictions with a $k$-nearest-neighbor ($k$NN) classifier over a datastore of cached few-shot instance representations obtained by PLMs and their corresponding labels. Then adaptive neighbor selection and feature regularization modules are introduced to make full use of a few support instances to reduce the $k$NN retrieval noise. Experiments on various few-shot text classification tasks demonstrate that our method significantly improves in-context learning, while even achieving comparable performance with state-of-the-art tuning-based approaches in some sentiment analysis tasks.
A Review of Federated Learning in Energy Systems
Aug 20, 2022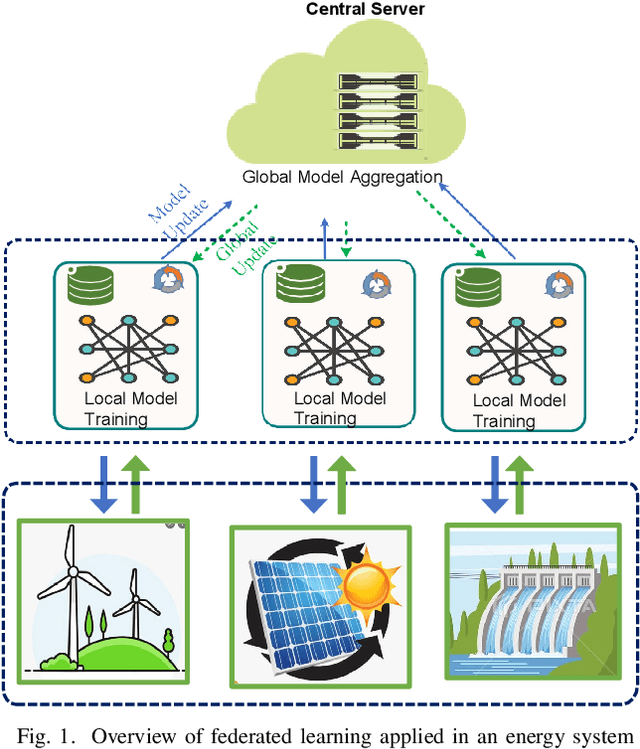
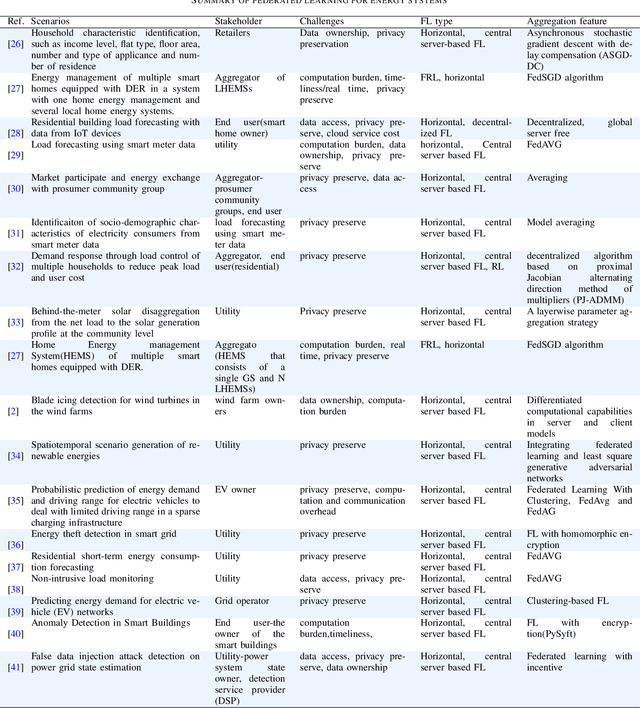
With increasing concerns for data privacy and ownership, recent years have witnessed a paradigm shift in machine learning (ML). An emerging paradigm, federated learning (FL), has gained great attention and has become a novel design for machine learning implementations. FL enables the ML model training at data silos under the coordination of a central server, eliminating communication overhead and without sharing raw data. In this paper, we conduct a review of the FL paradigm and, in particular, compare the types, the network structures, and the global model aggregation methods. Then, we conducted a comprehensive review of FL applications in the energy domain (refer to the smart grid in this paper). We provide a thematic classification of FL to address a variety of energy-related problems, including demand response, identification, prediction, and federated optimizations. We describe the taxonomy in detail and conclude with a discussion of various aspects, including challenges, opportunities, and limitations in its energy informatics applications, such as energy system modeling and design, privacy, and evolution.
Quantifying the Knowledge in a DNN to Explain Knowledge Distillation for Classification
Aug 18, 2022
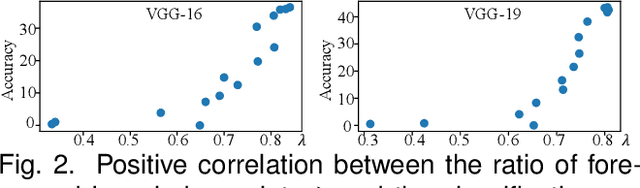
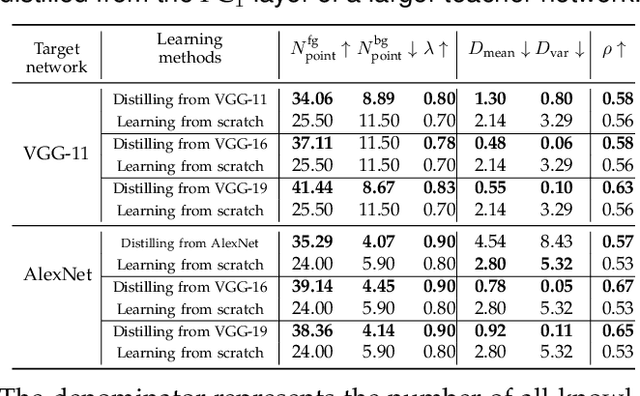
Compared to traditional learning from scratch, knowledge distillation sometimes makes the DNN achieve superior performance. This paper provides a new perspective to explain the success of knowledge distillation, i.e., quantifying knowledge points encoded in intermediate layers of a DNN for classification, based on the information theory. To this end, we consider the signal processing in a DNN as the layer-wise information discarding. A knowledge point is referred to as an input unit, whose information is much less discarded than other input units. Thus, we propose three hypotheses for knowledge distillation based on the quantification of knowledge points. 1. The DNN learning from knowledge distillation encodes more knowledge points than the DNN learning from scratch. 2. Knowledge distillation makes the DNN more likely to learn different knowledge points simultaneously. In comparison, the DNN learning from scratch tends to encode various knowledge points sequentially. 3. The DNN learning from knowledge distillation is often optimized more stably than the DNN learning from scratch. In order to verify the above hypotheses, we design three types of metrics with annotations of foreground objects to analyze feature representations of the DNN, \textit{i.e.} the quantity and the quality of knowledge points, the learning speed of different knowledge points, and the stability of optimization directions. In experiments, we diagnosed various DNNs for different classification tasks, i.e., image classification, 3D point cloud classification, binary sentiment classification, and question answering, which verified above hypotheses.
Proving Common Mechanisms Shared by Twelve Methods of Boosting Adversarial Transferability
Jul 24, 2022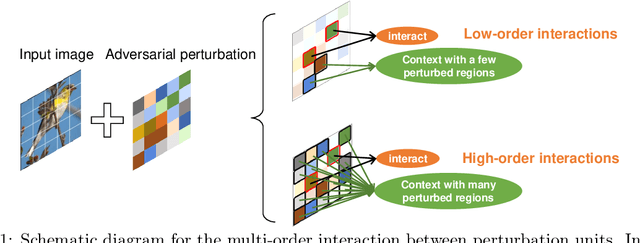
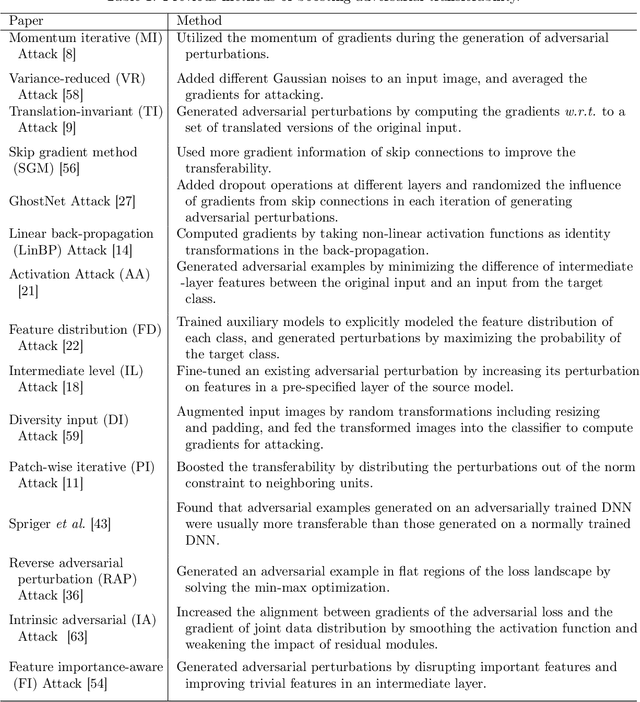

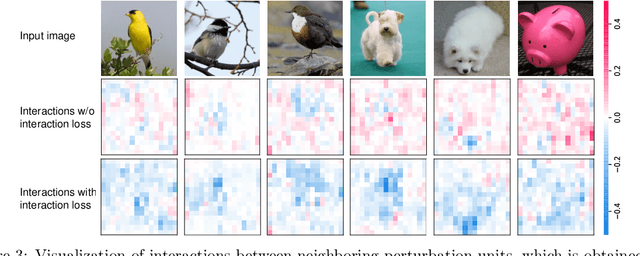
Although many methods have been proposed to enhance the transferability of adversarial perturbations, these methods are designed in a heuristic manner, and the essential mechanism for improving adversarial transferability is still unclear. This paper summarizes the common mechanism shared by twelve previous transferability-boosting methods in a unified view, i.e., these methods all reduce game-theoretic interactions between regional adversarial perturbations. To this end, we focus on the attacking utility of all interactions between regional adversarial perturbations, and we first discover and prove the negative correlation between the adversarial transferability and the attacking utility of interactions. Based on this discovery, we theoretically prove and empirically verify that twelve previous transferability-boosting methods all reduce interactions between regional adversarial perturbations. More crucially, we consider the reduction of interactions as the essential reason for the enhancement of adversarial transferability. Furthermore, we design the interaction loss to directly penalize interactions between regional adversarial perturbations during attacking. Experimental results show that the interaction loss significantly improves the transferability of adversarial perturbations.