 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePeiran Li
Pooling Image Datasets With Multiple Covariate Shift and Imbalance
Mar 14, 2024




Small sample sizes are common in many disciplines, which necessitates pooling roughly similar datasets across multiple institutions to study weak but relevant associations between images and disease outcomes. Such data often manifest shift/imbalance in covariates (i.e., secondary non-imaging data). Controlling for such nuisance variables is common within standard statistical analysis, but the ideas do not directly apply to overparameterized models. Consequently, recent work has shown how strategies from invariant representation learning provides a meaningful starting point, but the current repertoire of methods is limited to accounting for shifts/imbalances in just a couple of covariates at a time. In this paper, we show how viewing this problem from the perspective of Category theory provides a simple and effective solution that completely avoids elaborate multi-stage training pipelines that would otherwise be needed. We show the effectiveness of this approach via extensive experiments on real datasets. Further, we discuss how this style of formulation offers a unified perspective on at least 5+ distinct problem settings, from self-supervised learning to matching problems in 3D reconstruction.
ASSISTGUI: Task-Oriented Desktop Graphical User Interface Automation
Jan 01, 2024Graphical User Interface (GUI) automation holds significant promise for assisting users with complex tasks, thereby boosting human productivity. Existing works leveraging Large Language Model (LLM) or LLM-based AI agents have shown capabilities in automating tasks on Android and Web platforms. However, these tasks are primarily aimed at simple device usage and entertainment operations. This paper presents a novel benchmark, AssistGUI, to evaluate whether models are capable of manipulating the mouse and keyboard on the Windows platform in response to user-requested tasks. We carefully collected a set of 100 tasks from nine widely-used software applications, such as, After Effects and MS Word, each accompanied by the necessary project files for better evaluation. Moreover, we propose an advanced Actor-Critic Embodied Agent framework, which incorporates a sophisticated GUI parser driven by an LLM-agent and an enhanced reasoning mechanism adept at handling lengthy procedural tasks. Our experimental results reveal that our GUI Parser and Reasoning mechanism outshine existing methods in performance. Nevertheless, the potential remains substantial, with the best model attaining only a 46% success rate on our benchmark. We conclude with a thorough analysis of the current methods' limitations, setting the stage for future breakthroughs in this domain.
User-Guided Aspect Classification for Domain-Specific Texts
Apr 30, 2020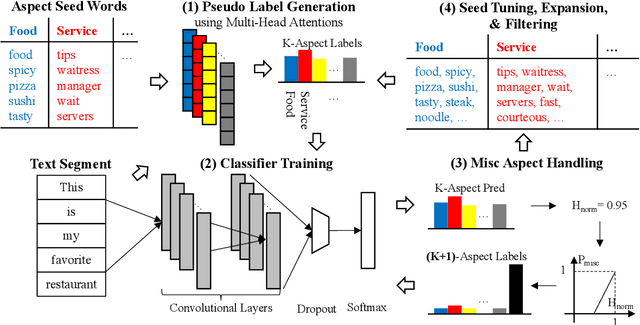
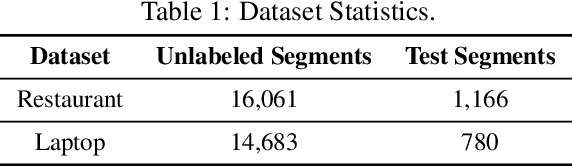

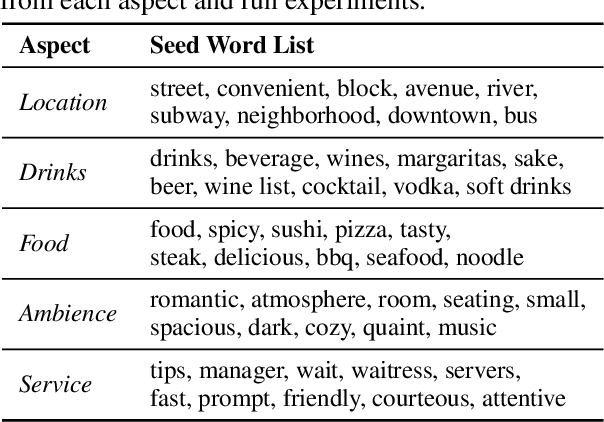
Aspect classification, identifying aspects of text segments, facilitates numerous applications, such as sentiment analysis and review summarization. To alleviate the human effort on annotating massive texts, in this paper, we study the problem of classifying aspects based on only a few user-provided seed words for pre-defined aspects. The major challenge lies in how to handle the noisy misc aspect, which is designed for texts without any pre-defined aspects. Even domain experts have difficulties to nominate seed words for the misc aspect, making existing seed-driven text classification methods not applicable. We propose a novel framework, ARYA, which enables mutual enhancements between pre-defined aspects and the misc aspect via iterative classifier training and seed updating. Specifically, it trains a classifier for pre-defined aspects and then leverages it to induce the supervision for the misc aspect. The prediction results of the misc aspect are later utilized to filter out noisy seed words for pre-defined aspects. Experiments in two domains demonstrate the superior performance of our proposed framework, as well as the necessity and importance of properly modeling the misc aspect.