 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXin Liao
Compressed Deepfake Video Detection Based on 3D Spatiotemporal Trajectories
Apr 28, 2024
The misuse of deepfake technology by malicious actors poses a potential threat to nations, societies, and individuals. However, existing methods for detecting deepfakes primarily focus on uncompressed videos, such as noise characteristics, local textures, or frequency statistics. When applied to compressed videos, these methods experience a decrease in detection performance and are less suitable for real-world scenarios. In this paper, we propose a deepfake video detection method based on 3D spatiotemporal trajectories. Specifically, we utilize a robust 3D model to construct spatiotemporal motion features, integrating feature details from both 2D and 3D frames to mitigate the influence of large head rotation angles or insufficient lighting within frames. Furthermore, we separate facial expressions from head movements and design a sequential analysis method based on phase space motion trajectories to explore the feature differences between genuine and fake faces in deepfake videos. We conduct extensive experiments to validate the performance of our proposed method on several compressed deepfake benchmarks. The robustness of the well-designed features is verified by calculating the consistent distribution of facial landmarks before and after video compression.Our method yields satisfactory results and showcases its potential for practical applications.
SafePaint: Anti-forensic Image Inpainting with Domain Adaptation
Apr 28, 2024Existing image inpainting methods have achieved remarkable accomplishments in generating visually appealing results, often accompanied by a trend toward creating more intricate structural textures. However, while these models excel at creating more realistic image content, they often leave noticeable traces of tampering, posing a significant threat to security. In this work, we take the anti-forensic capabilities into consideration, firstly proposing an end-to-end training framework for anti-forensic image inpainting named SafePaint. Specifically, we innovatively formulated image inpainting as two major tasks: semantically plausible content completion and region-wise optimization. The former is similar to current inpainting methods that aim to restore the missing regions of corrupted images. The latter, through domain adaptation, endeavors to reconcile the discrepancies between the inpainted region and the unaltered area to achieve anti-forensic goals. Through comprehensive theoretical analysis, we validate the effectiveness of domain adaptation for anti-forensic performance. Furthermore, we meticulously crafted a region-wise separated attention (RWSA) module, which not only aligns with our objective of anti-forensics but also enhances the performance of the model. Extensive qualitative and quantitative evaluations show our approach achieves comparable results to existing image inpainting methods while offering anti-forensic capabilities not available in other methods.
Are Watermarks Bugs for Deepfake Detectors? Rethinking Proactive Forensics
Apr 27, 2024AI-generated content has accelerated the topic of media synthesis, particularly Deepfake, which can manipulate our portraits for positive or malicious purposes. Before releasing these threatening face images, one promising forensics solution is the injection of robust watermarks to track their own provenance. However, we argue that current watermarking models, originally devised for genuine images, may harm the deployed Deepfake detectors when directly applied to forged images, since the watermarks are prone to overlap with the forgery signals used for detection. To bridge this gap, we thus propose AdvMark, on behalf of proactive forensics, to exploit the adversarial vulnerability of passive detectors for good. Specifically, AdvMark serves as a plug-and-play procedure for fine-tuning any robust watermarking into adversarial watermarking, to enhance the forensic detectability of watermarked images; meanwhile, the watermarks can still be extracted for provenance tracking. Extensive experiments demonstrate the effectiveness of the proposed AdvMark, leveraging robust watermarking to fool Deepfake detectors, which can help improve the accuracy of downstream Deepfake detection without tuning the in-the-wild detectors. We believe this work will shed some light on the harmless proactive forensics against Deepfake.
VLM-CPL: Consensus Pseudo Labels from Vision-Language Models for Human Annotation-Free Pathological Image Classification
Mar 23, 2024Despite that deep learning methods have achieved remarkable performance in pathology image classification, they heavily rely on labeled data, demanding extensive human annotation efforts. In this study, we present a novel human annotation-free method for pathology image classification by leveraging pre-trained Vision-Language Models (VLMs). Without human annotation, pseudo labels of the training set are obtained by utilizing the zero-shot inference capabilities of VLM, which may contain a lot of noise due to the domain shift between the pre-training data and the target dataset. To address this issue, we introduce VLM-CPL, a novel approach based on consensus pseudo labels that integrates two noisy label filtering techniques with a semi-supervised learning strategy. Specifically, we first obtain prompt-based pseudo labels with uncertainty estimation by zero-shot inference with the VLM using multiple augmented views of an input. Then, by leveraging the feature representation ability of VLM, we obtain feature-based pseudo labels via sample clustering in the feature space. Prompt-feature consensus is introduced to select reliable samples based on the consensus between the two types of pseudo labels. By rejecting low-quality pseudo labels, we further propose High-confidence Cross Supervision (HCS) to learn from samples with reliable pseudo labels and the remaining unlabeled samples. Experimental results showed that our method obtained an accuracy of 87.1% and 95.1% on the HPH and LC25K datasets, respectively, and it largely outperformed existing zero-shot classification and noisy label learning methods. The code is available at https://github.com/lanfz2000/VLM-CPL.
Delocate: Detection and Localization for Deepfake Videos with Randomly-Located Tampered Traces
Jan 24, 2024Deepfake videos are becoming increasingly realistic, showing subtle tampering traces on facial areasthat vary between frames. Consequently, many existing Deepfake detection methods struggle to detect unknown domain Deepfake videos while accurately locating the tampered region. To address thislimitation, we propose Delocate, a novel Deepfake detection model that can both recognize andlocalize unknown domain Deepfake videos. Ourmethod consists of two stages named recoveringand localization. In the recovering stage, the modelrandomly masks regions of interest (ROIs) and reconstructs real faces without tampering traces, resulting in a relatively good recovery effect for realfaces and a poor recovery effect for fake faces. Inthe localization stage, the output of the recoveryphase and the forgery ground truth mask serve assupervision to guide the forgery localization process. This process strategically emphasizes the recovery phase of fake faces with poor recovery, facilitating the localization of tampered regions. Ourextensive experiments on four widely used benchmark datasets demonstrate that Delocate not onlyexcels in localizing tampered areas but also enhances cross-domain detection performance.
Recap: Detecting Deepfake Video with Unpredictable Tampered Traces via Recovering Faces and Mapping Recovered Faces
Aug 19, 2023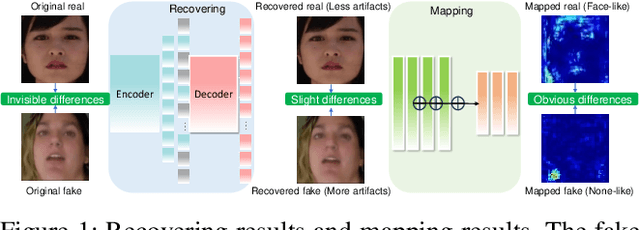
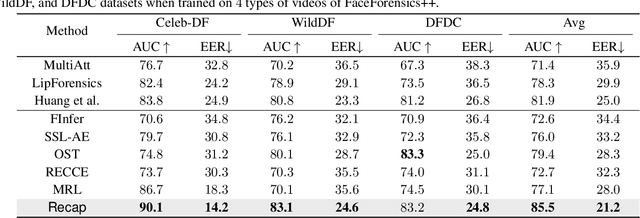
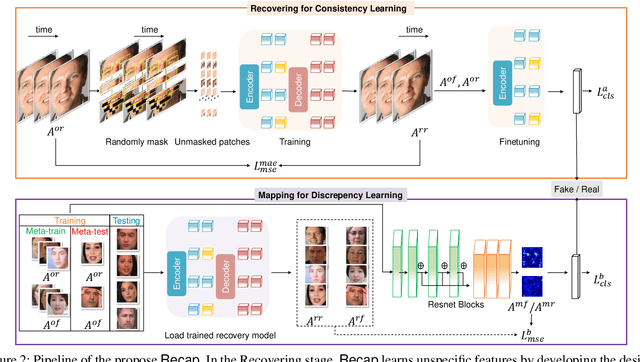
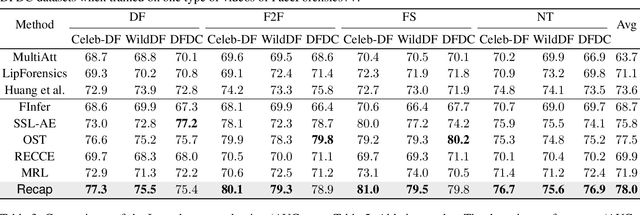
The exploitation of Deepfake techniques for malicious intentions has driven significant research interest in Deepfake detection. Deepfake manipulations frequently introduce random tampered traces, leading to unpredictable outcomes in different facial regions. However, existing detection methods heavily rely on specific forgery indicators, and as the forgery mode improves, these traces become increasingly randomized, resulting in a decline in the detection performance of methods reliant on specific forgery traces. To address the limitation, we propose Recap, a novel Deepfake detection model that exposes unspecific facial part inconsistencies by recovering faces and enlarges the differences between real and fake by mapping recovered faces. In the recovering stage, the model focuses on randomly masking regions of interest (ROIs) and reconstructing real faces without unpredictable tampered traces, resulting in a relatively good recovery effect for real faces while a poor recovery effect for fake faces. In the mapping stage, the output of the recovery phase serves as supervision to guide the facial mapping process. This mapping process strategically emphasizes the mapping of fake faces with poor recovery, leading to a further deterioration in their representation, while enhancing and refining the mapping of real faces with good representation. As a result, this approach significantly amplifies the discrepancies between real and fake videos. Our extensive experiments on standard benchmarks demonstrate that Recap is effective in multiple scenarios.
CTP-Net: Character Texture Perception Network for Document Image Forgery Localization
Aug 15, 2023
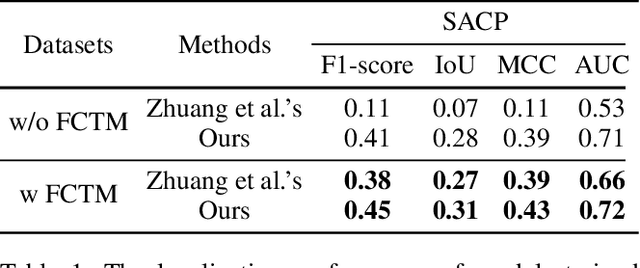


Due to the progression of information technology in recent years, document images have been widely disseminated on social networks. With the help of powerful image editing tools, document images are easily forged without leaving visible manipulation traces, which leads to severe issues if significant information is falsified for malicious use. Therefore, the research of document image forensics is worth further exploring. In this paper, we propose a Character Texture Perception Network (CTP-Net) to localize the forged regions in document images. Specifically, considering the characters with semantics in a document image are highly vulnerable, capturing the forgery traces is the key to localize the forged regions. We design a Character Texture Stream (CTS) based on optical character recognition to capture features of text areas that are essential components of a document image. Meanwhile, texture features of the whole document image are exploited by an Image Texture Stream (ITS). Combining the features extracted from the CTS and the ITS, the CTP-Net can reveal more subtle forgery traces from document images. Moreover, to overcome the challenge caused by the lack of fake document images, we design a data generation strategy that is utilized to construct a Fake Chinese Trademark dataset (FCTM). Experimental results on different datasets demonstrate that the proposed CTP-Net is able to localize multi-scale forged areas in document images, and outperform the state-of-the-art forgery localization methods, even though post-processing operations are applied.
Semi-supervised Pathological Image Segmentation via Cross Distillation of Multiple Attentions
May 30, 2023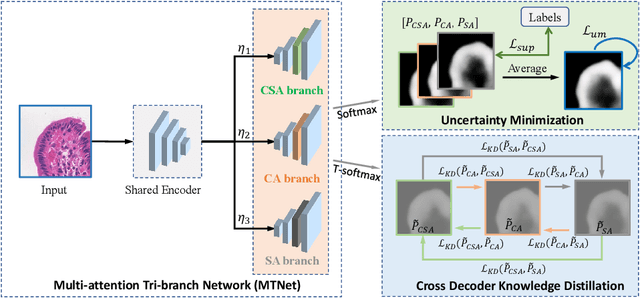
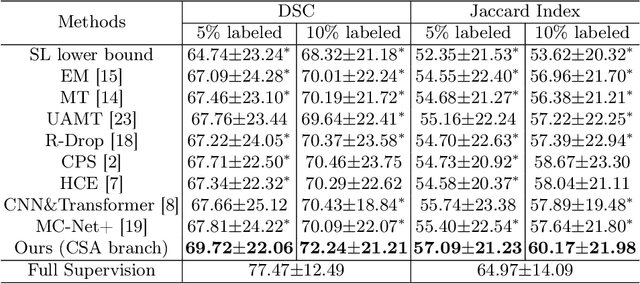
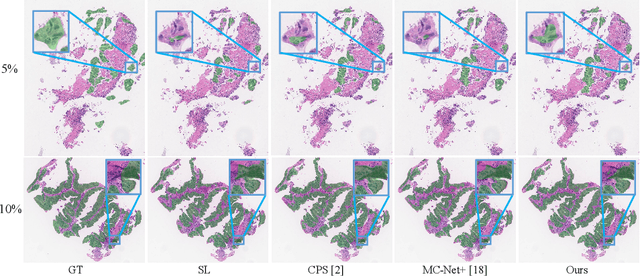

Segmentation of pathological images is a crucial step for accurate cancer diagnosis. However, acquiring dense annotations of such images for training is labor-intensive and time-consuming. To address this issue, Semi-Supervised Learning (SSL) has the potential for reducing the annotation cost, but it is challenged by a large number of unlabeled training images. In this paper, we propose a novel SSL method based on Cross Distillation of Multiple Attentions (CDMA) to effectively leverage unlabeled images. Firstly, we propose a Multi-attention Tri-branch Network (MTNet) that consists of an encoder and a three-branch decoder, with each branch using a different attention mechanism that calibrates features in different aspects to generate diverse outputs. Secondly, we introduce Cross Decoder Knowledge Distillation (CDKD) between the three decoder branches, allowing them to learn from each other's soft labels to mitigate the negative impact of incorrect pseudo labels in training. Additionally, uncertainty minimization is applied to the average prediction of the three branches, which further regularizes predictions on unlabeled images and encourages inter-branch consistency. Our proposed CDMA was compared with eight state-of-the-art SSL methods on the public DigestPath dataset, and the experimental results showed that our method outperforms the other approaches under different annotation ratios. The code is available at \href{https://github.com/HiLab-git/CDMA}{https://github.com/HiLab-git/CDMA.}
Exploiting Fine-Grained DCT Representations for Hiding Image-Level Messages within JPEG Images
May 11, 2023

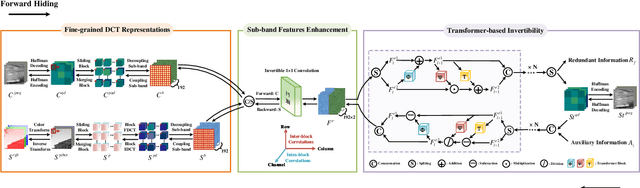
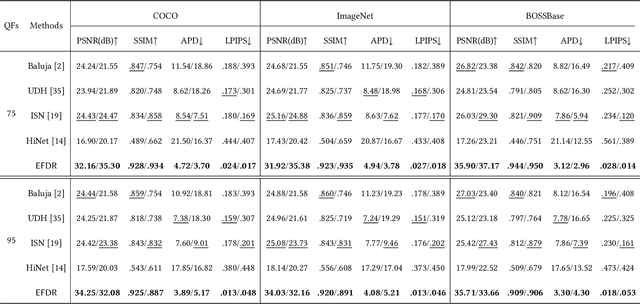
Unlike hiding bit-level messages, hiding image-level messages is more challenging, which requires large capacity, high imperceptibility, and high security. Although recent advances in hiding image-level messages have been remarkable, existing schemes are limited to lossless spatial images as covers and cannot be directly applied to JPEG images, the ubiquitous lossy format images in daily life. The difficulties of migration are caused by the lack of targeted design and the loss of details due to lossy decompression and re-compression. Considering that taking DCT densely on $8\times8$ image patches is the core of the JPEG compression standard, we design a novel model called \textsf{EFDR}, which can comprehensively \underline{E}xploit \underline{F}ine-grained \underline{D}CT \underline{R}epresentations and embed the secret image into quantized DCT coefficients to avoid the lossy process. Specifically, we transform the JPEG cover image and hidden secret image into fine-grained DCT representations that compact the frequency and are associated with the inter-block and intra-block correlations. Subsequently, the fine-grained DCT representations are further enhanced by a sub-band features enhancement module. Afterward, a transformer-based invertibility module is designed to fuse enhanced sub-band features. Such a design enables a fine-grained self-attention on each sub-band and captures long-range dependencies while maintaining excellent reversibility for hiding and recovery. To our best knowledge, this is the first attempt to embed a color image of equal size in a color JPEG image. Extensive experiments demonstrate the effectiveness of our \textsf{EFDR} with superior performance.
SepMark: Deep Separable Watermarking for Unified Source Tracing and Deepfake Detection
May 10, 2023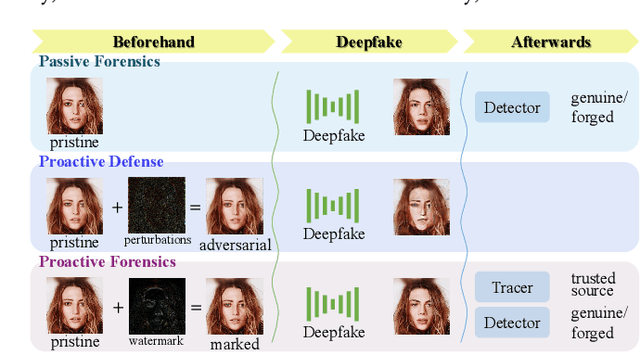
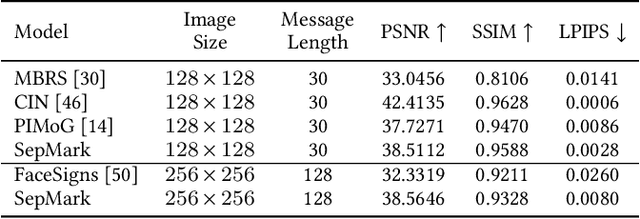

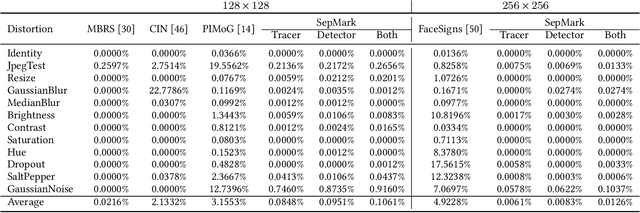
Malicious Deepfakes have led to a sharp conflict over distinguishing between genuine and forged faces. Although many countermeasures have been developed to detect Deepfakes ex-post, undoubtedly, passive forensics has not considered any preventive measures for the pristine face before foreseeable manipulations. To complete this forensics ecosystem, we thus put forward the proactive solution dubbed SepMark, which provides a unified framework for source tracing and Deepfake detection. SepMark originates from encoder-decoder-based deep watermarking but with two separable decoders. For the first time the deep separable watermarking, SepMark brings a new paradigm to the established study of deep watermarking, where a single encoder embeds one watermark elegantly, while two decoders can extract the watermark separately at different levels of robustness. The robust decoder termed Tracer that resists various distortions may have an overly high level of robustness, allowing the watermark to survive both before and after Deepfake. The semi-robust one termed Detector is selectively sensitive to malicious distortions, making the watermark disappear after Deepfake. Only SepMark comprising of Tracer and Detector can reliably trace the trusted source of the marked face and detect whether it has been altered since being marked; neither of the two alone can achieve this. Extensive experiments demonstrate the effectiveness of the proposed SepMark on typical Deepfakes, including face swapping, expression reenactment, and attribute editing.