 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZiyan Wang
Re2LLM: Reflective Reinforcement Large Language Model for Session-based Recommendation
Mar 27, 2024
Large Language Models (LLMs) are emerging as promising approaches to enhance session-based recommendation (SBR), where both prompt-based and fine-tuning-based methods have been widely investigated to align LLMs with SBR. However, the former methods struggle with optimal prompts to elicit the correct reasoning of LLMs due to the lack of task-specific feedback, leading to unsatisfactory recommendations. Although the latter methods attempt to fine-tune LLMs with domain-specific knowledge, they face limitations such as high computational costs and reliance on open-source backbones. To address such issues, we propose a Reflective Reinforcement Large Language Model (Re2LLM) for SBR, guiding LLMs to focus on specialized knowledge essential for more accurate recommendations effectively and efficiently. In particular, we first design the Reflective Exploration Module to effectively extract knowledge that is readily understandable and digestible by LLMs. To be specific, we direct LLMs to examine recommendation errors through self-reflection and construct a knowledge base (KB) comprising hints capable of rectifying these errors. To efficiently elicit the correct reasoning of LLMs, we further devise the Reinforcement Utilization Module to train a lightweight retrieval agent. It learns to select hints from the constructed KB based on the task-specific feedback, where the hints can serve as guidance to help correct LLMs reasoning for better recommendations. Extensive experiments on multiple real-world datasets demonstrate that our method consistently outperforms state-of-the-art methods.
ANIM: Accurate Neural Implicit Model for Human Reconstruction from a single RGB-D image
Mar 18, 2024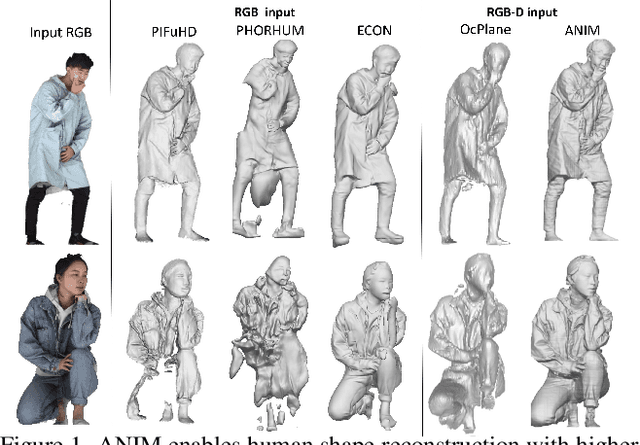
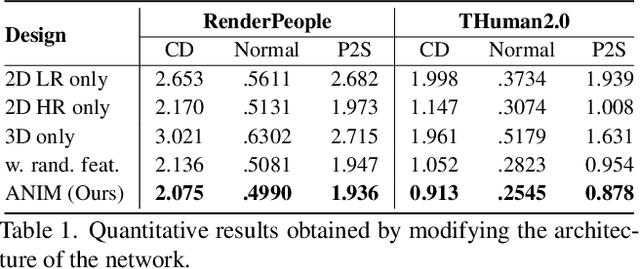
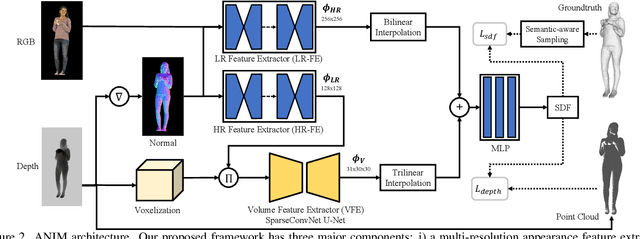
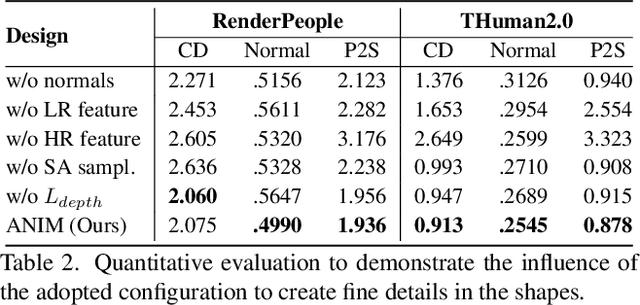
Recent progress in human shape learning, shows that neural implicit models are effective in generating 3D human surfaces from limited number of views, and even from a single RGB image. However, existing monocular approaches still struggle to recover fine geometric details such as face, hands or cloth wrinkles. They are also easily prone to depth ambiguities that result in distorted geometries along the camera optical axis. In this paper, we explore the benefits of incorporating depth observations in the reconstruction process by introducing ANIM, a novel method that reconstructs arbitrary 3D human shapes from single-view RGB-D images with an unprecedented level of accuracy. Our model learns geometric details from both multi-resolution pixel-aligned and voxel-aligned features to leverage depth information and enable spatial relationships, mitigating depth ambiguities. We further enhance the quality of the reconstructed shape by introducing a depth-supervision strategy, which improves the accuracy of the signed distance field estimation of points that lie on the reconstructed surface. Experiments demonstrate that ANIM outperforms state-of-the-art works that use RGB, surface normals, point cloud or RGB-D data as input. In addition, we introduce ANIM-Real, a new multi-modal dataset comprising high-quality scans paired with consumer-grade RGB-D camera, and our protocol to fine-tune ANIM, enabling high-quality reconstruction from real-world human capture.
Large Language Model with Graph Convolution for Recommendation
Feb 14, 2024In recent years, efforts have been made to use text information for better user profiling and item characterization in recommendations. However, text information can sometimes be of low quality, hindering its effectiveness for real-world applications. With knowledge and reasoning capabilities capsuled in Large Language Models (LLMs), utilizing LLMs emerges as a promising way for description improvement. However, existing ways of prompting LLMs with raw texts ignore structured knowledge of user-item interactions, which may lead to hallucination problems like inconsistent description generation. To this end, we propose a Graph-aware Convolutional LLM method to elicit LLMs to capture high-order relations in the user-item graph. To adapt text-based LLMs with structured graphs, We use the LLM as an aggregator in graph processing, allowing it to understand graph-based information step by step. Specifically, the LLM is required for description enhancement by exploring multi-hop neighbors layer by layer, thereby propagating information progressively in the graph. To enable LLMs to capture large-scale graph information, we break down the description task into smaller parts, which drastically reduces the context length of the token input with each step. Extensive experiments on three real-world datasets show that our method consistently outperforms state-of-the-art methods.
Natural Language Reinforcement Learning
Feb 14, 2024Reinforcement Learning (RL) has shown remarkable abilities in learning policies for decision-making tasks. However, RL is often hindered by issues such as low sample efficiency, lack of interpretability, and sparse supervision signals. To tackle these limitations, we take inspiration from the human learning process and introduce Natural Language Reinforcement Learning (NLRL), which innovatively combines RL principles with natural language representation. Specifically, NLRL redefines RL concepts like task objectives, policy, value function, Bellman equation, and policy iteration in natural language space. We present how NLRL can be practically implemented with the latest advancements in large language models (LLMs) like GPT-4. Initial experiments over tabular MDPs demonstrate the effectiveness, efficiency, and also interpretability of the NLRL framework.
Safe Reinforcement Learning with Free-form Natural Language Constraints and Pre-Trained Language Models
Jan 15, 2024Safe reinforcement learning (RL) agents accomplish given tasks while adhering to specific constraints. Employing constraints expressed via easily-understandable human language offers considerable potential for real-world applications due to its accessibility and non-reliance on domain expertise. Previous safe RL methods with natural language constraints typically adopt a recurrent neural network, which leads to limited capabilities when dealing with various forms of human language input. Furthermore, these methods often require a ground-truth cost function, necessitating domain expertise for the conversion of language constraints into a well-defined cost function that determines constraint violation. To address these issues, we proposes to use pre-trained language models (LM) to facilitate RL agents' comprehension of natural language constraints and allow them to infer costs for safe policy learning. Through the use of pre-trained LMs and the elimination of the need for a ground-truth cost, our method enhances safe policy learning under a diverse set of human-derived free-form natural language constraints. Experiments on grid-world navigation and robot control show that the proposed method can achieve strong performance while adhering to given constraints. The usage of pre-trained LMs allows our method to comprehend complicated constraints and learn safe policies without the need for ground-truth cost at any stage of training or evaluation. Extensive ablation studies are conducted to demonstrate the efficacy of each part of our method.
A Local Appearance Model for Volumetric Capture of Diverse Hairstyle
Dec 14, 2023Hair plays a significant role in personal identity and appearance, making it an essential component of high-quality, photorealistic avatars. Existing approaches either focus on modeling the facial region only or rely on personalized models, limiting their generalizability and scalability. In this paper, we present a novel method for creating high-fidelity avatars with diverse hairstyles. Our method leverages the local similarity across different hairstyles and learns a universal hair appearance prior from multi-view captures of hundreds of people. This prior model takes 3D-aligned features as input and generates dense radiance fields conditioned on a sparse point cloud with color. As our model splits different hairstyles into local primitives and builds prior at that level, it is capable of handling various hair topologies. Through experiments, we demonstrate that our model captures a diverse range of hairstyles and generalizes well to challenging new hairstyles. Empirical results show that our method improves the state-of-the-art approaches in capturing and generating photorealistic, personalized avatars with complete hair.
MACCA: Offline Multi-agent Reinforcement Learning with Causal Credit Assignment
Dec 06, 2023Offline Multi-agent Reinforcement Learning (MARL) is valuable in scenarios where online interaction is impractical or risky. While independent learning in MARL offers flexibility and scalability, accurately assigning credit to individual agents in offline settings poses challenges due to partial observability and emergent behavior. Directly transferring the online credit assignment method to offline settings results in suboptimal outcomes due to the absence of real-time feedback and intricate agent interactions. Our approach, MACCA, characterizing the generative process as a Dynamic Bayesian Network, captures relationships between environmental variables, states, actions, and rewards. Estimating this model on offline data, MACCA can learn each agent's contribution by analyzing the causal relationship of their individual rewards, ensuring accurate and interpretable credit assignment. Additionally, the modularity of our approach allows it to seamlessly integrate with various offline MARL methods. Theoretically, we proved that under the setting of the offline dataset, the underlying causal structure and the function for generating the individual rewards of agents are identifiable, which laid the foundation for the correctness of our modeling. Experimentally, we tested MACCA in two environments, including discrete and continuous action settings. The results show that MACCA outperforms SOTA methods and improves performance upon their backbones.
A Comprehensive Survey for Evaluation Methodologies of AI-Generated Music
Aug 26, 2023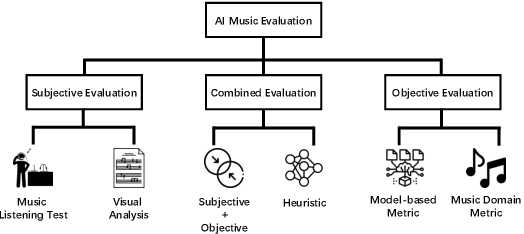
In recent years, AI-generated music has made significant progress, with several models performing well in multimodal and complex musical genres and scenes. While objective metrics can be used to evaluate generative music, they often lack interpretability for musical evaluation. Therefore, researchers often resort to subjective user studies to assess the quality of the generated works, which can be resource-intensive and less reproducible than objective metrics. This study aims to comprehensively evaluate the subjective, objective, and combined methodologies for assessing AI-generated music, highlighting the advantages and disadvantages of each approach. Ultimately, this study provides a valuable reference for unifying generative AI in the field of music evaluation.
ChessGPT: Bridging Policy Learning and Language Modeling
Jun 15, 2023When solving decision-making tasks, humans typically depend on information from two key sources: (1) Historical policy data, which provides interaction replay from the environment, and (2) Analytical insights in natural language form, exposing the invaluable thought process or strategic considerations. Despite this, the majority of preceding research focuses on only one source: they either use historical replay exclusively to directly learn policy or value functions, or engaged in language model training utilizing mere language corpus. In this paper, we argue that a powerful autonomous agent should cover both sources. Thus, we propose ChessGPT, a GPT model bridging policy learning and language modeling by integrating data from these two sources in Chess games. Specifically, we build a large-scale game and language dataset related to chess. Leveraging the dataset, we showcase two model examples ChessCLIP and ChessGPT, integrating policy learning and language modeling. Finally, we propose a full evaluation framework for evaluating language model's chess ability. Experimental results validate our model and dataset's effectiveness. We open source our code, model, and dataset at https://github.com/waterhorse1/ChessGPT.
Variational Imbalanced Regression
Jun 11, 2023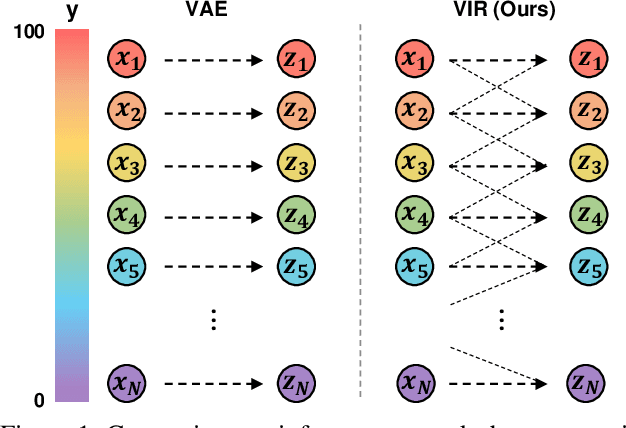
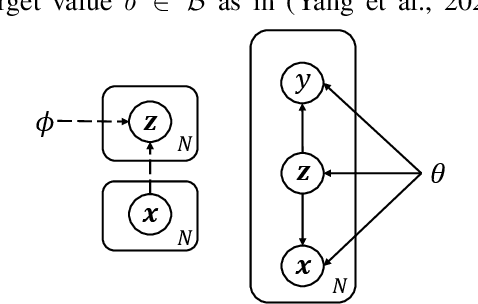
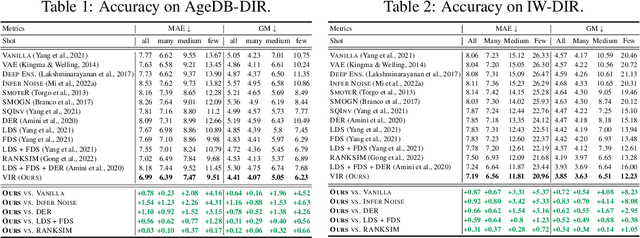
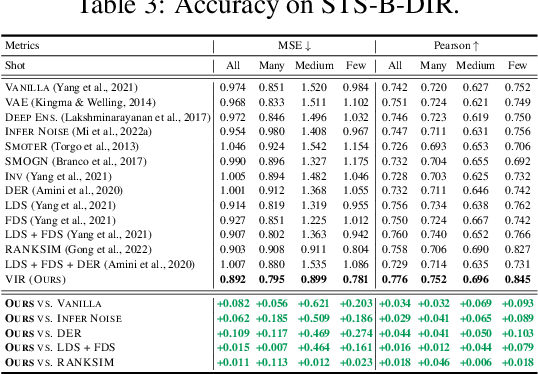
Existing regression models tend to fall short in both accuracy and uncertainty estimation when the label distribution is imbalanced. In this paper, we propose a probabilistic deep learning model, dubbed variational imbalanced regression (VIR), which not only performs well in imbalanced regression but naturally produces reasonable uncertainty estimation as a byproduct. Different from typical variational autoencoders assuming I.I.D. representations (a data point's representation is not directly affected by other data points), our VIR borrows data with similar regression labels to compute the latent representation's variational distribution; furthermore, different from deterministic regression models producing point estimates, VIR predicts the entire normal-inverse-gamma distributions and modulates the associated conjugate distributions to impose probabilistic reweighting on the imbalanced data, thereby providing better uncertainty estimation. Experiments in several real-world datasets show that our VIR can outperform state-of-the-art imbalanced regression models in terms of both accuracy and uncertainty estimation.