 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWenqiao Zhang
LASER: Tuning-Free LLM-Driven Attention Control for Efficient Text-conditioned Image-to-Animation
Apr 23, 2024
Revolutionary advancements in text-to-image models have unlocked new dimensions for sophisticated content creation, e.g., text-conditioned image editing, allowing us to edit the diverse images that convey highly complex visual concepts according to the textual guidance. Despite being promising, existing methods focus on texture- or non-rigid-based visual manipulation, which struggles to produce the fine-grained animation of smooth text-conditioned image morphing without fine-tuning, i.e., due to their highly unstructured latent space. In this paper, we introduce a tuning-free LLM-driven attention control framework, encapsulated by the progressive process of LLM planning, prompt-Aware editing, StablE animation geneRation, abbreviated as LASER. LASER employs a large language model (LLM) to refine coarse descriptions into detailed prompts, guiding pre-trained text-to-image models for subsequent image generation. We manipulate the model's spatial features and self-attention mechanisms to maintain animation integrity and enable seamless morphing directly from text prompts, eliminating the need for additional fine-tuning or annotations. Our meticulous control over spatial features and self-attention ensures structural consistency in the images. This paper presents a novel framework integrating LLMs with text-to-image models to create high-quality animations from a single text input. We also propose a Text-conditioned Image-to-Animation Benchmark to validate the effectiveness and efficacy of LASER. Extensive experiments demonstrate that LASER produces impressive, consistent, and efficient results in animation generation, positioning it as a powerful tool for advanced digital content creation.
Fact :Teaching MLLMs with Faithful, Concise and Transferable Rationales
Apr 17, 2024The remarkable performance of Multimodal Large Language Models (MLLMs) has unequivocally demonstrated their proficient understanding capabilities in handling a wide array of visual tasks. Nevertheless, the opaque nature of their black-box reasoning processes persists as an enigma, rendering them uninterpretable and struggling with hallucination. Their ability to execute intricate compositional reasoning tasks is also constrained, culminating in a stagnation of learning progression for these models. In this work, we introduce Fact, a novel paradigm designed to generate multimodal rationales that are faithful, concise, and transferable for teaching MLLMs. This paradigm utilizes verifiable visual programming to generate executable code guaranteeing faithfulness and precision. Subsequently, through a series of operations including pruning, merging, and bridging, the rationale enhances its conciseness. Furthermore, we filter rationales that can be transferred to end-to-end paradigms from programming paradigms to guarantee transferability. Empirical evidence from experiments demonstrates the superiority of our method across models of varying parameter sizes, significantly enhancing their compositional reasoning and generalization ability. Our approach also reduces hallucinations owing to its high correlation between images and text.
HyperLLaVA: Dynamic Visual and Language Expert Tuning for Multimodal Large Language Models
Mar 20, 2024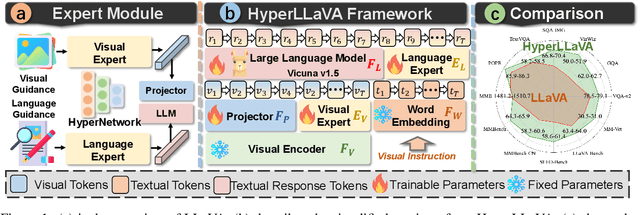
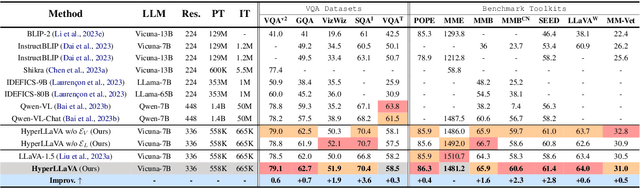
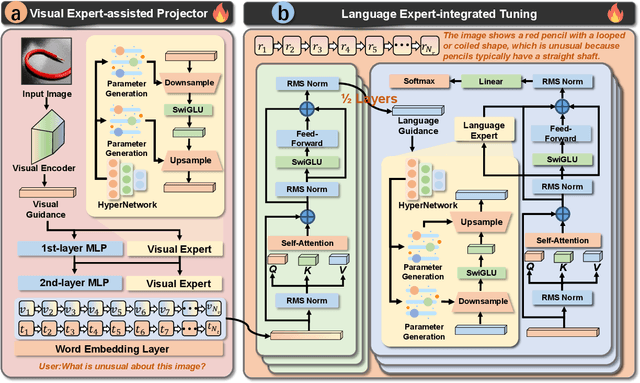
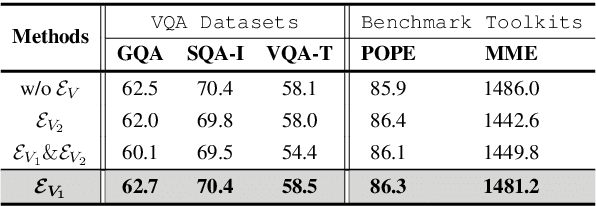
Recent advancements indicate that scaling up Multimodal Large Language Models (MLLMs) effectively enhances performance on downstream multimodal tasks. The prevailing MLLM paradigm, \emph{e.g.}, LLaVA, transforms visual features into text-like tokens using a \emph{static} vision-language mapper, thereby enabling \emph{static} LLMs to develop the capability to comprehend visual information through visual instruction tuning. Although promising, the \emph{static} tuning strategy~\footnote{The static tuning refers to the trained model with static parameters.} that shares the same parameters may constrain performance across different downstream multimodal tasks. In light of this, we introduce HyperLLaVA, which involves adaptive tuning of the projector and LLM parameters, in conjunction with a dynamic visual expert and language expert, respectively. These experts are derived from HyperNetworks, which generates adaptive parameter shifts through visual and language guidance, enabling dynamic projector and LLM modeling in two-stage training. Our experiments demonstrate that our solution significantly surpasses LLaVA on existing MLLM benchmarks, including MME, MMBench, SEED-Bench, and LLaVA-Bench. ~\footnote{Our project is available on the link https://github.com/DCDmllm/HyperLLaVA}.
METER: A Dynamic Concept Adaptation Framework for Online Anomaly Detection
Dec 28, 2023Real-time analytics and decision-making require online anomaly detection (OAD) to handle drifts in data streams efficiently and effectively. Unfortunately, existing approaches are often constrained by their limited detection capacity and slow adaptation to evolving data streams, inhibiting their efficacy and efficiency in handling concept drift, which is a major challenge in evolving data streams. In this paper, we introduce METER, a novel dynamic concept adaptation framework that introduces a new paradigm for OAD. METER addresses concept drift by first training a base detection model on historical data to capture recurring central concepts, and then learning to dynamically adapt to new concepts in data streams upon detecting concept drift. Particularly, METER employs a novel dynamic concept adaptation technique that leverages a hypernetwork to dynamically generate the parameter shift of the base detection model, providing a more effective and efficient solution than conventional retraining or fine-tuning approaches. Further, METER incorporates a lightweight drift detection controller, underpinned by evidential deep learning, to support robust and interpretable concept drift detection. We conduct an extensive experimental evaluation, and the results show that METER significantly outperforms existing OAD approaches in various application scenarios.
Music-PAW: Learning Music Representations via Hierarchical Part-whole Interaction and Contrast
Dec 11, 2023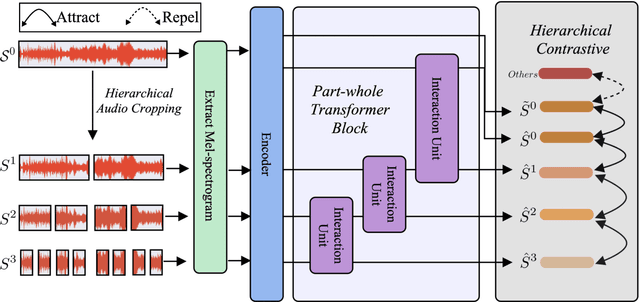
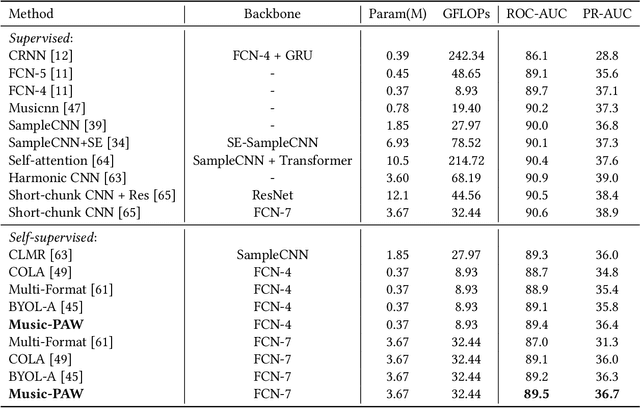
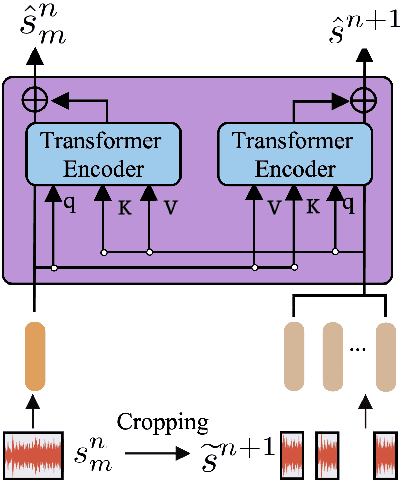
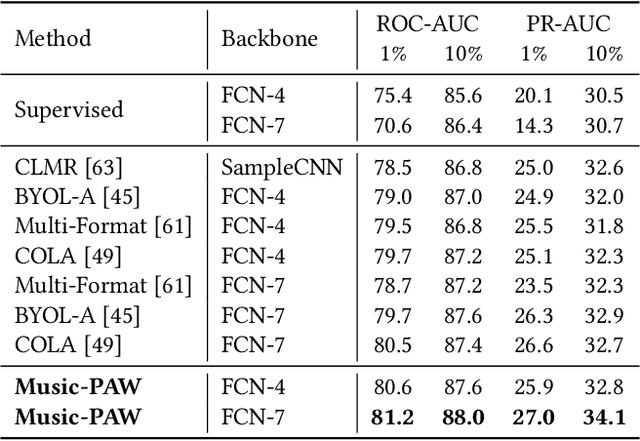
The excellent performance of recent self-supervised learning methods on various downstream tasks has attracted great attention from academia and industry. Some recent research efforts have been devoted to self-supervised music representation learning. Nevertheless, most of them learn to represent equally-sized music clips in the waveform or a spectrogram. Despite being effective in some tasks, learning music representations in such a manner largely neglect the inherent part-whole hierarchies of music. Due to the hierarchical nature of the auditory cortex [24], understanding the bottom-up structure of music, i.e., how different parts constitute the whole at different levels, is essential for music understanding and representation learning. This work pursues hierarchical music representation learning and introduces the Music-PAW framework, which enables feature interactions of cropped music clips with part-whole hierarchies. From a technical perspective, we propose a transformer-based part-whole interaction module to progressively reason the structural relationships between part-whole music clips at adjacent levels. Besides, to create a multi-hierarchy representation space, we devise a hierarchical contrastive learning objective to align part-whole music representations in adjacent hierarchies. The merits of audio representation learning from part-whole hierarchies have been validated on various downstream tasks, including music classification (single-label and multi-label), cover song identification and acoustic scene classification.
De-fine: Decomposing and Refining Visual Programs with Auto-Feedback
Nov 25, 2023Visual programming, a modular and generalizable paradigm, integrates different modules and Python operators to solve various vision-language tasks. Unlike end-to-end models that need task-specific data, it advances in performing visual processing and reasoning in an unsupervised manner. Current visual programming methods generate programs in a single pass for each task where the ability to evaluate and optimize based on feedback, unfortunately, is lacking, which consequentially limits their effectiveness for complex, multi-step problems. Drawing inspiration from benders decomposition, we introduce De-fine, a general framework that automatically decomposes complex tasks into simpler subtasks and refines programs through auto-feedback. This model-agnostic approach can improve logical reasoning performance by integrating the strengths of multiple models. Our experiments across various visual tasks show that De-fine creates more accurate and robust programs, setting new benchmarks in the field.
Revisiting the Domain Shift and Sample Uncertainty in Multi-source Active Domain Transfer
Nov 21, 2023Active Domain Adaptation (ADA) aims to maximally boost model adaptation in a new target domain by actively selecting a limited number of target data to annotate.This setting neglects the more practical scenario where training data are collected from multiple sources. This motivates us to target a new and challenging setting of knowledge transfer that extends ADA from a single source domain to multiple source domains, termed Multi-source Active Domain Adaptation (MADA). Not surprisingly, we find that most traditional ADA methods cannot work directly in such a setting, mainly due to the excessive domain gap introduced by all the source domains and thus their uncertainty-aware sample selection can easily become miscalibrated under the multi-domain shifts. Considering this, we propose a Dynamic integrated uncertainty valuation framework(Detective) that comprehensively consider the domain shift between multi-source domains and target domain to detect the informative target samples. Specifically, the leverages a dynamic Domain Adaptation(DA) model that learns how to adapt the model's parameters to fit the union of multi-source domains. This enables an approximate single-source domain modeling by the dynamic model. We then comprehensively measure both domain uncertainty and predictive uncertainty in the target domain to detect informative target samples using evidential deep learning, thereby mitigating uncertainty miscalibration. Furthermore, we introduce a contextual diversity-aware calculator to enhance the diversity of the selected samples. Experiments demonstrate that our solution outperforms existing methods by a considerable margin on three domain adaptation benchmarks.
Empowering Vision-Language Models to Follow Interleaved Vision-Language Instructions
Aug 10, 2023

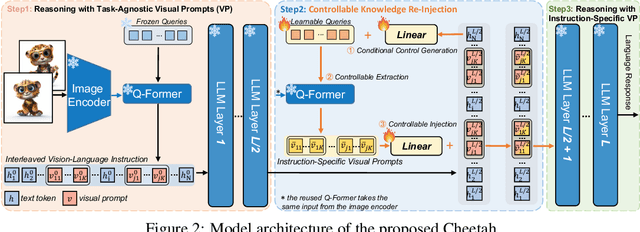
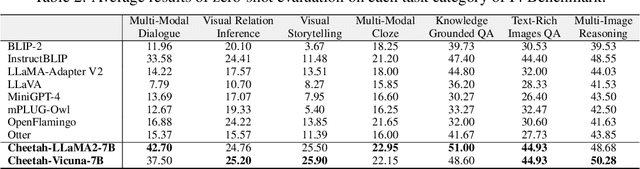
Multimodal Large Language Models (MLLMs) have recently sparked significant interest, which demonstrates emergent capabilities to serve as a general-purpose model for various vision-language tasks. However, existing methods mainly focus on limited types of instructions with a single image as visual context, which hinders the widespread availability of MLLMs. In this paper, we introduce the I4 benchmark to comprehensively evaluate the instruction following ability on complicated interleaved vision-language instructions, which involve intricate image-text sequential context, covering a diverse range of scenarios (e.g., visually-rich webpages/textbooks, lecture slides, embodied dialogue). Systematic evaluation on our I4 benchmark reveals a common defect of existing methods: the Visual Prompt Generator (VPG) trained on image-captioning alignment objective tends to attend to common foreground information for captioning but struggles to extract specific information required by particular tasks. To address this issue, we propose a generic and lightweight controllable knowledge re-injection module, which utilizes the sophisticated reasoning ability of LLMs to control the VPG to conditionally extract instruction-specific visual information and re-inject it into the LLM. Further, we introduce an annotation-free cross-attention guided counterfactual image training strategy to methodically learn the proposed module by collaborating a cascade of foundation models. Enhanced by the proposed module and training strategy, we present Cheetor, a Transformer-based MLLM that can effectively handle a wide variety of interleaved vision-language instructions and achieves state-of-the-art zero-shot performance across all tasks of I4, without high-quality multimodal instruction tuning data. Cheetor also exhibits competitive performance compared with state-of-the-art instruction tuned models on MME benchmark.
Denoising Multi-modal Sequential Recommenders with Contrastive Learning
May 03, 2023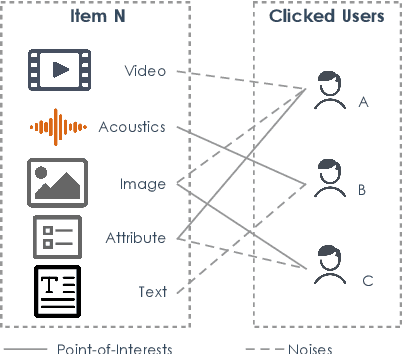

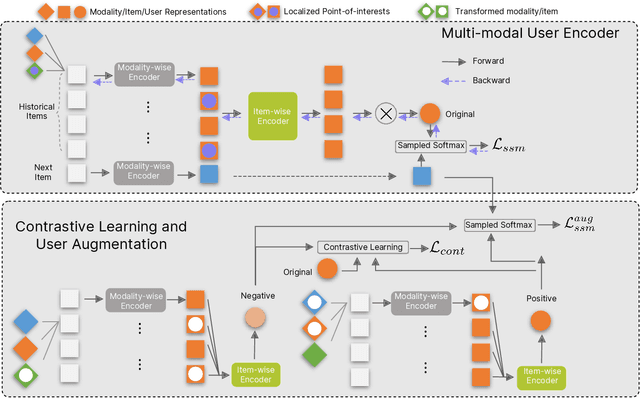
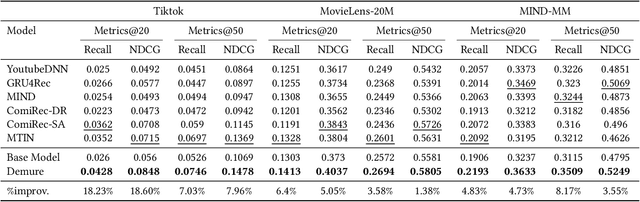
There is a rapidly-growing research interest in engaging users with multi-modal data for accurate user modeling on recommender systems. Existing multimedia recommenders have achieved substantial improvements by incorporating various modalities and devising delicate modules. However, when users decide to interact with items, most of them do not fully read the content of all modalities. We refer to modalities that directly cause users' behaviors as point-of-interests, which are important aspects to capture users' interests. In contrast, modalities that do not cause users' behaviors are potential noises and might mislead the learning of a recommendation model. Not surprisingly, little research in the literature has been devoted to denoising such potential noises due to the inaccessibility of users' explicit feedback on their point-of-interests. To bridge the gap, we propose a weakly-supervised framework based on contrastive learning for denoising multi-modal recommenders (dubbed Demure). In a weakly-supervised manner, Demure circumvents the requirement of users' explicit feedback and identifies the noises by analyzing the modalities of all interacted items from a given user.
Learning in Imperfect Environment: Multi-Label Classification with Long-Tailed Distribution and Partial Labels
Apr 20, 2023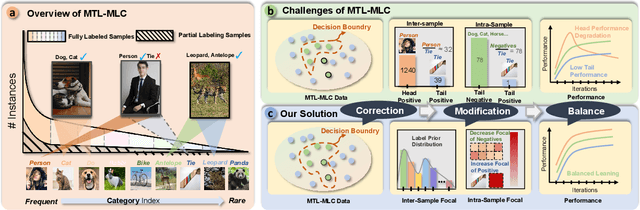
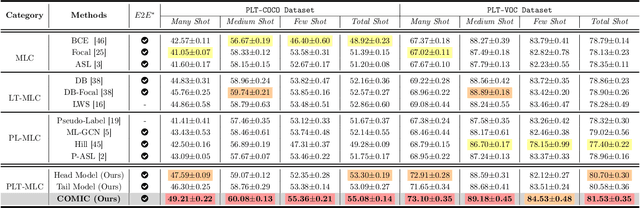
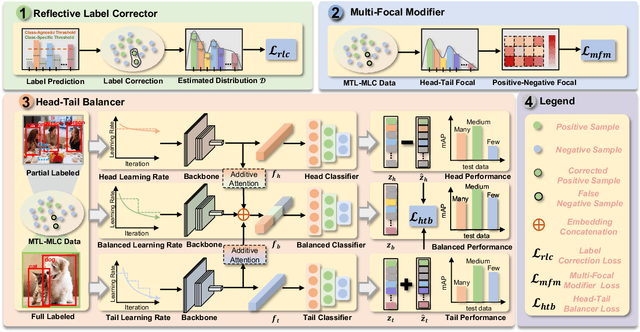
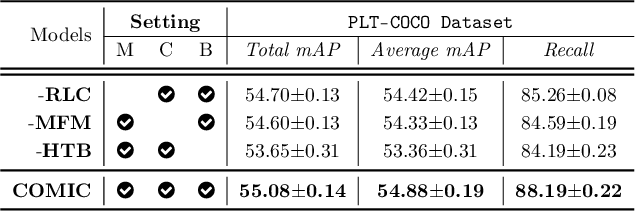
Conventional multi-label classification (MLC) methods assume that all samples are fully labeled and identically distributed. Unfortunately, this assumption is unrealistic in large-scale MLC data that has long-tailed (LT) distribution and partial labels (PL). To address the problem, we introduce a novel task, Partial labeling and Long-Tailed Multi-Label Classification (PLT-MLC), to jointly consider the above two imperfect learning environments. Not surprisingly, we find that most LT-MLC and PL-MLC approaches fail to solve the PLT-MLC, resulting in significant performance degradation on the two proposed PLT-MLC benchmarks. Therefore, we propose an end-to-end learning framework: \textbf{CO}rrection $\rightarrow$ \textbf{M}odificat\textbf{I}on $\rightarrow$ balan\textbf{C}e, abbreviated as \textbf{\method{}}. Our bootstrapping philosophy is to simultaneously correct the missing labels (Correction) with convinced prediction confidence over a class-aware threshold and to learn from these recall labels during training. We next propose a novel multi-focal modifier loss that simultaneously addresses head-tail imbalance and positive-negative imbalance to adaptively modify the attention to different samples (Modification) under the LT class distribution. In addition, we develop a balanced training strategy by distilling the model's learning effect from head and tail samples, and thus design a balanced classifier (Balance) conditioned on the head and tail learning effect to maintain stable performance for all samples. Our experimental study shows that the proposed \method{} significantly outperforms general MLC, LT-MLC and PL-MLC methods in terms of effectiveness and robustness on our newly created PLT-MLC datasets.