 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChen Ma
An Empty Room is All We Want: Automatic Defurnishing of Indoor Panoramas
May 06, 2024
We propose a pipeline that leverages Stable Diffusion to improve inpainting results in the context of defurnishing -- the removal of furniture items from indoor panorama images. Specifically, we illustrate how increased context, domain-specific model fine-tuning, and improved image blending can produce high-fidelity inpaints that are geometrically plausible without needing to rely on room layout estimation. We demonstrate qualitative and quantitative improvements over other furniture removal techniques.
A Survey on the Memory Mechanism of Large Language Model based Agents
Apr 21, 2024Large language model (LLM) based agents have recently attracted much attention from the research and industry communities. Compared with original LLMs, LLM-based agents are featured in their self-evolving capability, which is the basis for solving real-world problems that need long-term and complex agent-environment interactions. The key component to support agent-environment interactions is the memory of the agents. While previous studies have proposed many promising memory mechanisms, they are scattered in different papers, and there lacks a systematical review to summarize and compare these works from a holistic perspective, failing to abstract common and effective designing patterns for inspiring future studies. To bridge this gap, in this paper, we propose a comprehensive survey on the memory mechanism of LLM-based agents. In specific, we first discuss ''what is'' and ''why do we need'' the memory in LLM-based agents. Then, we systematically review previous studies on how to design and evaluate the memory module. In addition, we also present many agent applications, where the memory module plays an important role. At last, we analyze the limitations of existing work and show important future directions. To keep up with the latest advances in this field, we create a repository at \url{https://github.com/nuster1128/LLM_Agent_Memory_Survey}.
Treatment-Aware Hyperbolic Representation Learning for Causal Effect Estimation with Social Networks
Jan 12, 2024Estimating the individual treatment effect (ITE) from observational data is a crucial research topic that holds significant value across multiple domains. How to identify hidden confounders poses a key challenge in ITE estimation. Recent studies have incorporated the structural information of social networks to tackle this challenge, achieving notable advancements. However, these methods utilize graph neural networks to learn the representation of hidden confounders in Euclidean space, disregarding two critical issues: (1) the social networks often exhibit a scalefree structure, while Euclidean embeddings suffer from high distortion when used to embed such graphs, and (2) each ego-centric network within a social network manifests a treatment-related characteristic, implying significant patterns of hidden confounders. To address these issues, we propose a novel method called Treatment-Aware Hyperbolic Representation Learning (TAHyper). Firstly, TAHyper employs the hyperbolic space to encode the social networks, thereby effectively reducing the distortion of confounder representation caused by Euclidean embeddings. Secondly, we design a treatment-aware relationship identification module that enhances the representation of hidden confounders by identifying whether an individual and her neighbors receive the same treatment. Extensive experiments on two benchmark datasets are conducted to demonstrate the superiority of our method.
Less or More From Teacher: Exploiting Trilateral Geometry For Knowledge Distillation
Jan 01, 2024Knowledge distillation aims to train a compact student network using soft supervision from a larger teacher network and hard supervision from ground truths. However, determining an optimal knowledge fusion ratio that balances these supervisory signals remains challenging. Prior methods generally resort to a constant or heuristic-based fusion ratio, which often falls short of a proper balance. In this study, we introduce a novel adaptive method for learning a sample-wise knowledge fusion ratio, exploiting both the correctness of teacher and student, as well as how well the student mimics the teacher on each sample. Our method naturally leads to the intra-sample trilateral geometric relations among the student prediction ($S$), teacher prediction ($T$), and ground truth ($G$). To counterbalance the impact of outliers, we further extend to the inter-sample relations, incorporating the teacher's global average prediction $\bar{T}$ for samples within the same class. A simple neural network then learns the implicit mapping from the intra- and inter-sample relations to an adaptive, sample-wise knowledge fusion ratio in a bilevel-optimization manner. Our approach provides a simple, practical, and adaptable solution for knowledge distillation that can be employed across various architectures and model sizes. Extensive experiments demonstrate consistent improvements over other loss re-weighting methods on image classification, attack detection, and click-through rate prediction.
SlowTrack: Increasing the Latency of Camera-based Perception in Autonomous Driving Using Adversarial Examples
Dec 26, 2023In Autonomous Driving (AD), real-time perception is a critical component responsible for detecting surrounding objects to ensure safe driving. While researchers have extensively explored the integrity of AD perception due to its safety and security implications, the aspect of availability (real-time performance) or latency has received limited attention. Existing works on latency-based attack have focused mainly on object detection, i.e., a component in camera-based AD perception, overlooking the entire camera-based AD perception, which hinders them to achieve effective system-level effects, such as vehicle crashes. In this paper, we propose SlowTrack, a novel framework for generating adversarial attacks to increase the execution time of camera-based AD perception. We propose a novel two-stage attack strategy along with the three new loss function designs. Our evaluation is conducted on four popular camera-based AD perception pipelines, and the results demonstrate that SlowTrack significantly outperforms existing latency-based attacks while maintaining comparable imperceptibility levels. Furthermore, we perform the evaluation on Baidu Apollo, an industry-grade full-stack AD system, and LGSVL, a production-grade AD simulator, with two scenarios to compare the system-level effects of SlowTrack and existing attacks. Our evaluation results show that the system-level effects can be significantly improved, i.e., the vehicle crash rate of SlowTrack is around 95% on average while existing works only have around 30%.
Large Language Models as Topological Structure Enhancers for Text-Attributed Graphs
Nov 24, 2023The latest advancements in large language models (LLMs) have revolutionized the field of natural language processing (NLP). Inspired by the success of LLMs in NLP tasks, some recent work has begun investigating the potential of applying LLMs in graph learning tasks. However, most of the existing work focuses on utilizing LLMs as powerful node feature augmenters, leaving employing LLMs to enhance graph topological structures an understudied problem. In this work, we explore how to leverage the information retrieval and text generation capabilities of LLMs to refine/enhance the topological structure of text-attributed graphs (TAGs) under the node classification setting. First, we propose using LLMs to help remove unreliable edges and add reliable ones in the TAG. Specifically, we first let the LLM output the semantic similarity between node attributes through delicate prompt designs, and then perform edge deletion and edge addition based on the similarity. Second, we propose using pseudo-labels generated by the LLM to improve graph topology, that is, we introduce the pseudo-label propagation as a regularization to guide the graph neural network (GNN) in learning proper edge weights. Finally, we incorporate the two aforementioned LLM-based methods for graph topological refinement into the process of GNN training, and perform extensive experiments on four real-world datasets. The experimental results demonstrate the effectiveness of LLM-based graph topology refinement (achieving a 0.15%--2.47% performance gain on public benchmarks).
Towards Hybrid-grained Feature Interaction Selection for Deep Sparse Network
Oct 30, 2023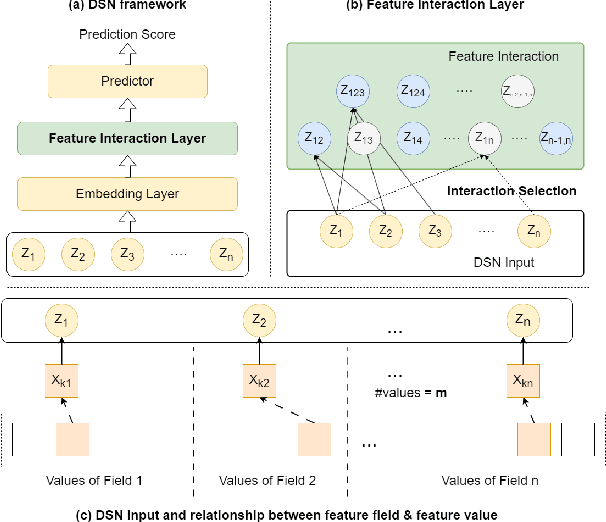
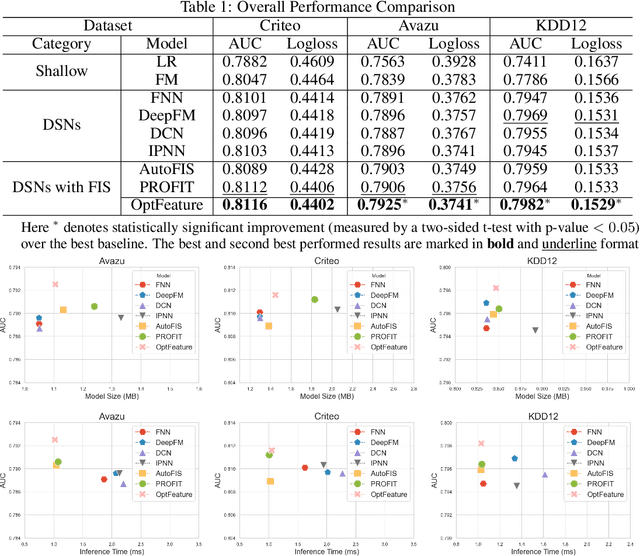
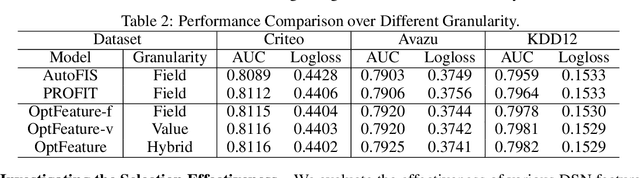

Deep sparse networks are widely investigated as a neural network architecture for prediction tasks with high-dimensional sparse features, with which feature interaction selection is a critical component. While previous methods primarily focus on how to search feature interaction in a coarse-grained space, less attention has been given to a finer granularity. In this work, we introduce a hybrid-grained feature interaction selection approach that targets both feature field and feature value for deep sparse networks. To explore such expansive space, we propose a decomposed space which is calculated on the fly. We then develop a selection algorithm called OptFeature, which efficiently selects the feature interaction from both the feature field and the feature value simultaneously. Results from experiments on three large real-world benchmark datasets demonstrate that OptFeature performs well in terms of accuracy and efficiency. Additional studies support the feasibility of our method.
Offline Imitation Learning with Variational Counterfactual Reasoning
Oct 17, 2023



In offline Imitation Learning (IL), an agent aims to learn an optimal expert behavior policy without additional online environment interactions. However, in many real-world scenarios, such as robotics manipulation, the offline dataset is collected from suboptimal behaviors without rewards. Due to the scarce expert data, the agents usually suffer from simply memorizing poor trajectories and are vulnerable to the variations in the environments, lacking the capability of generalizing to new environments. To effectively remove spurious features that would otherwise bias the agent and hinder generalization, we propose a framework named \underline{O}ffline \underline{I}mitation \underline{L}earning with \underline{C}ounterfactual data \underline{A}ugmentation (OILCA). In particular, we leverage the identifiable variational autoencoder to generate \textit{counterfactual} samples. We theoretically analyze the counterfactual identification and the improvement of generalization. Moreover, we conduct extensive experiments to demonstrate that our approach significantly outperforms various baselines on both \textsc{DeepMind Control Suite} benchmark for in-distribution robustness and \textsc{CausalWorld} benchmark for out-of-distribution generalization.
Robustness-enhanced Uplift Modeling with Adversarial Feature Desensitization
Oct 10, 2023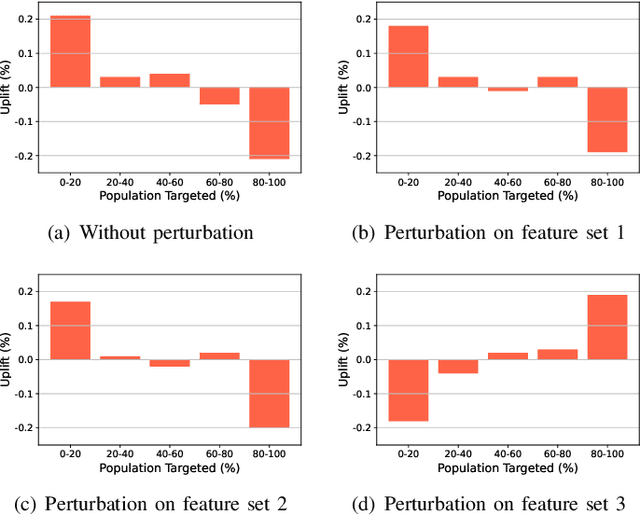
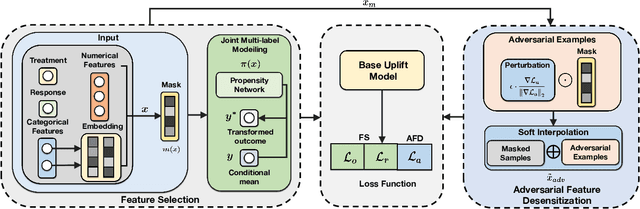


Uplift modeling has shown very promising results in online marketing. However, most existing works are prone to the robustness challenge in some practical applications. In this paper, we first present a possible explanation for the above phenomenon. We verify that there is a feature sensitivity problem in online marketing using different real-world datasets, where the perturbation of some key features will seriously affect the performance of the uplift model and even cause the opposite trend. To solve the above problem, we propose a novel robustness-enhanced uplift modeling framework with adversarial feature desensitization (RUAD). Specifically, our RUAD can more effectively alleviate the feature sensitivity of the uplift model through two customized modules, including a feature selection module with joint multi-label modeling to identify a key subset from the input features and an adversarial feature desensitization module using adversarial training and soft interpolation operations to enhance the robustness of the model against this selected subset of features. Finally, we conduct extensive experiments on a public dataset and a real product dataset to verify the effectiveness of our RUAD in online marketing. In addition, we also demonstrate the robustness of our RUAD to the feature sensitivity, as well as the compatibility with different uplift models.
A Survey on Large Language Model based Autonomous Agents
Sep 07, 2023
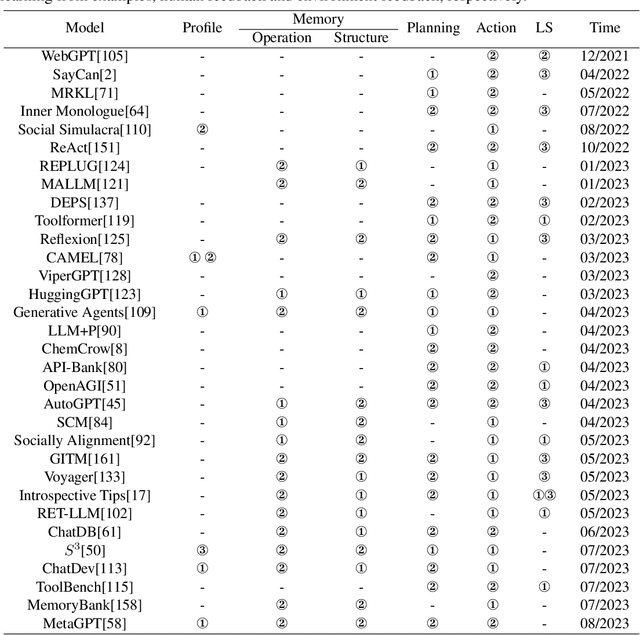
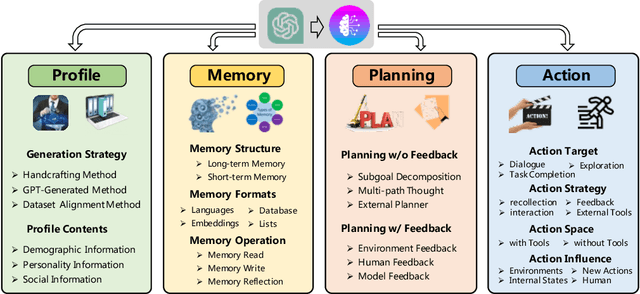
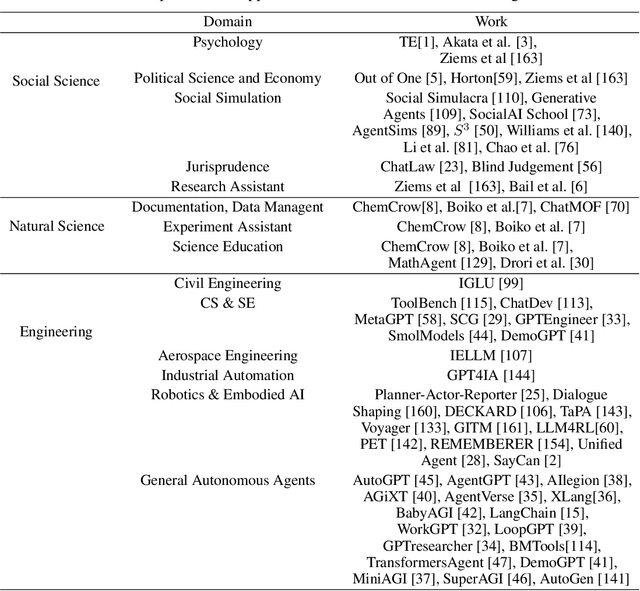
Autonomous agents have long been a prominent research focus in both academic and industry communities. Previous research in this field often focuses on training agents with limited knowledge within isolated environments, which diverges significantly from human learning processes, and thus makes the agents hard to achieve human-like decisions. Recently, through the acquisition of vast amounts of web knowledge, large language models (LLMs) have demonstrated remarkable potential in achieving human-level intelligence. This has sparked an upsurge in studies investigating LLM-based autonomous agents. In this paper, we present a comprehensive survey of these studies, delivering a systematic review of the field of LLM-based autonomous agents from a holistic perspective. More specifically, we first discuss the construction of LLM-based autonomous agents, for which we propose a unified framework that encompasses a majority of the previous work. Then, we present a comprehensive overview of the diverse applications of LLM-based autonomous agents in the fields of social science, natural science, and engineering. Finally, we delve into the evaluation strategies commonly used for LLM-based autonomous agents. Based on the previous studies, we also present several challenges and future directions in this field. To keep track of this field and continuously update our survey, we maintain a repository of relevant references at https://github.com/Paitesanshi/LLM-Agent-Survey.