 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXing Tang
DSGNN: A Dual-View Supergrid-Aware Graph Neural Network for Regional Air Quality Estimation
Apr 02, 2024
Air quality estimation can provide air quality for target regions without air quality stations, which is useful for the public. Existing air quality estimation methods divide the study area into disjointed grid regions, and apply 2D convolution to model the spatial dependencies of adjacent grid regions based on the first law of geography, failing to model the spatial dependencies of distant grid regions. To this end, we propose a Dual-view Supergrid-aware Graph Neural Network (DSGNN) for regional air quality estimation, which can model the spatial dependencies of distant grid regions from dual views (i.e., satellite-derived aerosol optical depth (AOD) and meteorology). Specifically, images are utilized to represent the regional data (i.e., AOD data and meteorology data). The dual-view supergrid learning module is introduced to generate supergrids in a parameterized way. Based on the dual-view supergrids, the dual-view implicit correlation encoding module is introduced to learn the correlations between pairwise supergrids. In addition, the dual-view message passing network is introduced to implement the information interaction on the supergrid graphs and images. Extensive experiments on two real-world datasets demonstrate that DSGNN achieves the state-of-the-art performances on the air quality estimation task, outperforming the best baseline by an average of 19.64% in MAE.
Touch the Core: Exploring Task Dependence Among Hybrid Targets for Recommendation
Mar 26, 2024

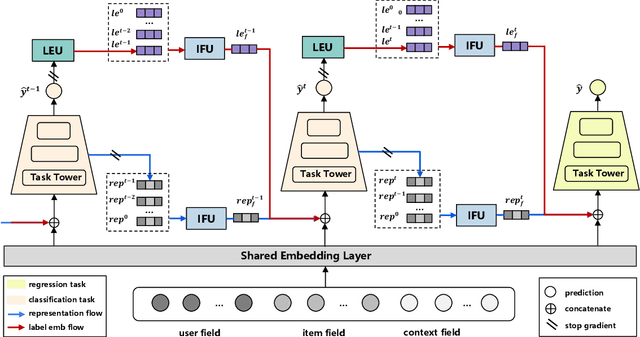

As user behaviors become complicated on business platforms, online recommendations focus more on how to touch the core conversions, which are highly related to the interests of platforms. These core conversions are usually continuous targets, such as \textit{watch time}, \textit{revenue}, and so on, whose predictions can be enhanced by previous discrete conversion actions. Therefore, multi-task learning (MTL) can be adopted as the paradigm to learn these hybrid targets. However, existing works mainly emphasize investigating the sequential dependence among discrete conversion actions, which neglects the complexity of dependence between discrete conversions and the final continuous conversion. Moreover, simultaneously optimizing hybrid tasks with stronger task dependence will suffer from volatile issues where the core regression task might have a larger influence on other tasks. In this paper, we study the MTL problem with hybrid targets for the first time and propose the model named Hybrid Targets Learning Network (HTLNet) to explore task dependence and enhance optimization. Specifically, we introduce label embedding for each task to explicitly transfer the label information among these tasks, which can effectively explore logical task dependence. We also further design the gradient adjustment regime between the final regression task and other classification tasks to enhance the optimization. Extensive experiments on two offline public datasets and one real-world industrial dataset are conducted to validate the effectiveness of HTLNet. Moreover, online A/B tests on the financial recommender system also show our model has superior improvement.
RecDCL: Dual Contrastive Learning for Recommendation
Jan 28, 2024Self-supervised recommendation (SSR) has achieved great success in mining the potential interacted behaviors for collaborative filtering in recent years. As a major branch, Contrastive Learning (CL) based SSR conquers data sparsity in Web platforms by contrasting the embedding between raw data and augmented data. However, existing CL-based SSR methods mostly focus on contrasting in a batch-wise way, failing to exploit potential regularity in the feature-wise dimension, leading to redundant solutions during the representation learning process of users (items) from Websites. Furthermore, the joint benefits of utilizing both Batch-wise CL (BCL) and Feature-wise CL (FCL) for recommendations remain underexplored. To address these issues, we investigate the relationship of objectives between BCL and FCL. Our study suggests a cooperative benefit of employing both methods, as evidenced from theoretical and experimental perspectives. Based on these insights, we propose a dual CL method for recommendation, referred to as RecDCL. RecDCL first eliminates redundant solutions on user-item positive pairs in a feature-wise manner. It then optimizes the uniform distributions within users and items using a polynomial kernel from an FCL perspective. Finally, it generates contrastive embedding on output vectors in a batch-wise objective. We conduct experiments on four widely-used benchmarks and an industrial dataset. The results consistently demonstrate that the proposed RecDCL outperforms the state-of-the-art GNNs-based and SSL-based models (with up to a 5.65\% improvement in terms of Recall@20), thereby confirming the effectiveness of the joint-wise objective. All source codes used in this paper are publicly available at \url{https://github.com/THUDM/RecDCL}}.
* Accepted to WWW 2024
Treatment-Aware Hyperbolic Representation Learning for Causal Effect Estimation with Social Networks
Jan 12, 2024Estimating the individual treatment effect (ITE) from observational data is a crucial research topic that holds significant value across multiple domains. How to identify hidden confounders poses a key challenge in ITE estimation. Recent studies have incorporated the structural information of social networks to tackle this challenge, achieving notable advancements. However, these methods utilize graph neural networks to learn the representation of hidden confounders in Euclidean space, disregarding two critical issues: (1) the social networks often exhibit a scalefree structure, while Euclidean embeddings suffer from high distortion when used to embed such graphs, and (2) each ego-centric network within a social network manifests a treatment-related characteristic, implying significant patterns of hidden confounders. To address these issues, we propose a novel method called Treatment-Aware Hyperbolic Representation Learning (TAHyper). Firstly, TAHyper employs the hyperbolic space to encode the social networks, thereby effectively reducing the distortion of confounder representation caused by Euclidean embeddings. Secondly, we design a treatment-aware relationship identification module that enhances the representation of hidden confounders by identifying whether an individual and her neighbors receive the same treatment. Extensive experiments on two benchmark datasets are conducted to demonstrate the superiority of our method.
Expected Transaction Value Optimization for Precise Marketing in FinTech Platforms
Jan 03, 2024FinTech platforms facilitated by digital payments are watching growth rapidly, which enable the distribution of mutual funds personalized to individual investors via mobile Apps. As the important intermediation of financial products investment, these platforms distribute thousands of mutual funds obtaining impressions under guaranteed delivery (GD) strategy required by fund companies. Driven by the profit from fund purchases of users, the platform aims to maximize each transaction amount of customers by promoting mutual funds to these investors who will be interested in. Different from the conversions in traditional advertising or e-commerce recommendations, the investment amount in each purchase varies greatly even for the same financial product, which provides a significant challenge for the promotion recommendation of mutual funds. In addition to predicting the click-through rate (CTR) or the conversion rate (CVR) as in traditional recommendations, it is essential for FinTech platforms to estimate the customers' purchase amount for each delivered fund and achieve an effective allocation of impressions based on the predicted results to optimize the total expected transaction value (ETV). In this paper, we propose an ETV optimized customer allocation framework (EOCA) that aims to maximize the total ETV of recommended funds, under the constraints of GD dealt with fund companies. To the best of our knowledge, it's the first attempt to solve the GD problem for financial product promotions based on customer purchase amount prediction. We conduct extensive experiments on large scale real-world datasets and online tests based on LiCaiTong, Tencent wealth management platform, to demonstrate the effectiveness of our proposed EOCA framework.
Towards Automated Negative Sampling in Implicit Recommendation
Nov 06, 2023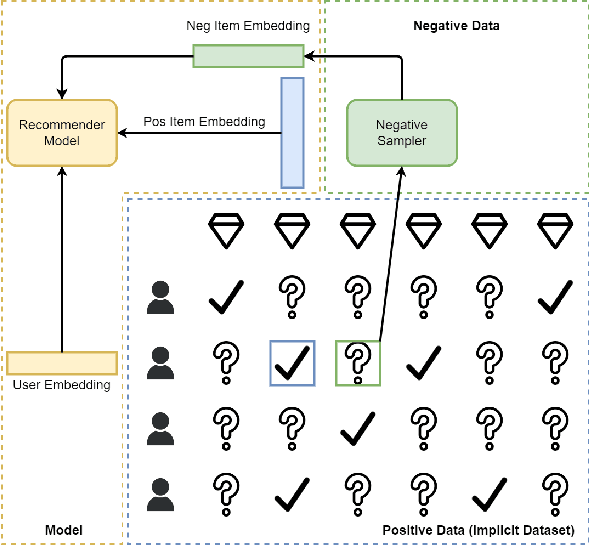

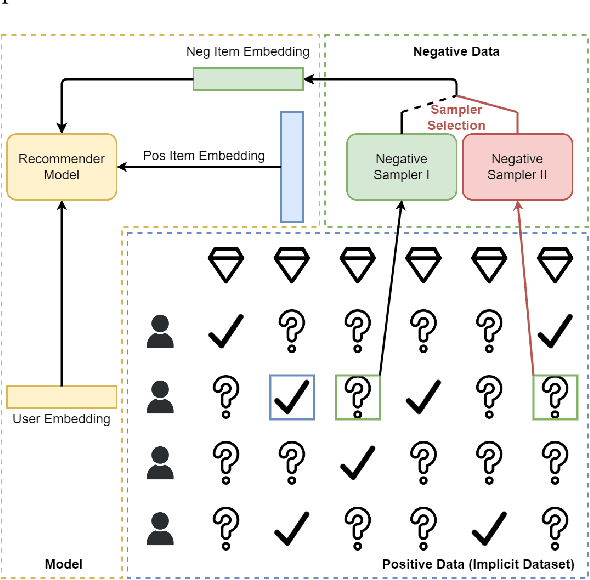

Negative sampling methods are vital in implicit recommendation models as they allow us to obtain negative instances from massive unlabeled data. Most existing approaches focus on sampling hard negative samples in various ways. These studies are orthogonal to the recommendation model and implicit datasets. However, such an idea contradicts the common belief in AutoML that the model and dataset should be matched. Empirical experiments suggest that the best-performing negative sampler depends on the implicit dataset and the specific recommendation model. Hence, we propose a hypothesis that the negative sampler should align with the capacity of the recommendation models as well as the statistics of the datasets to achieve optimal performance. A mismatch between these three would result in sub-optimal outcomes. An intuitive idea to address the mismatch problem is to exhaustively select the best-performing negative sampler given the model and dataset. However, such an approach is computationally expensive and time-consuming, leaving the problem unsolved. In this work, we propose the AutoSample framework that adaptively selects the best-performing negative sampler among candidates. Specifically, we propose a loss-to-instance approximation to transform the negative sampler search task into the learning task over a weighted sum, enabling end-to-end training of the model. We also designed an adaptive search algorithm to extensively and efficiently explore the search space. A specific initialization approach is also obtained to better utilize the obtained model parameters during the search stage, which is similar to curriculum learning and leads to better performance and less computation resource consumption. We evaluate the proposed framework on four benchmarks over three models. Extensive experiments demonstrate the effectiveness and efficiency of our proposed framework.
Towards Hybrid-grained Feature Interaction Selection for Deep Sparse Network
Oct 30, 2023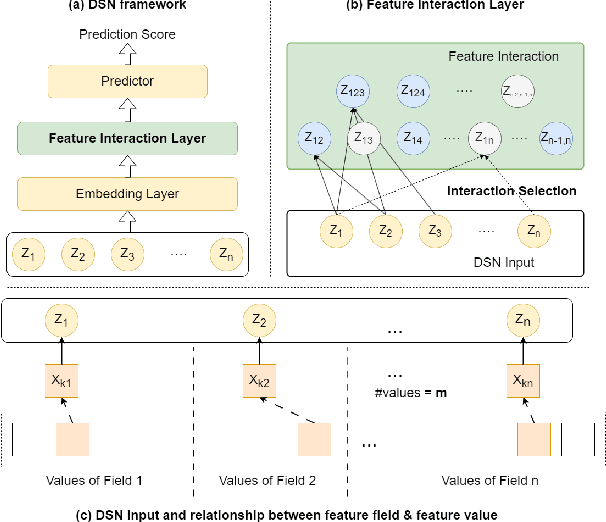
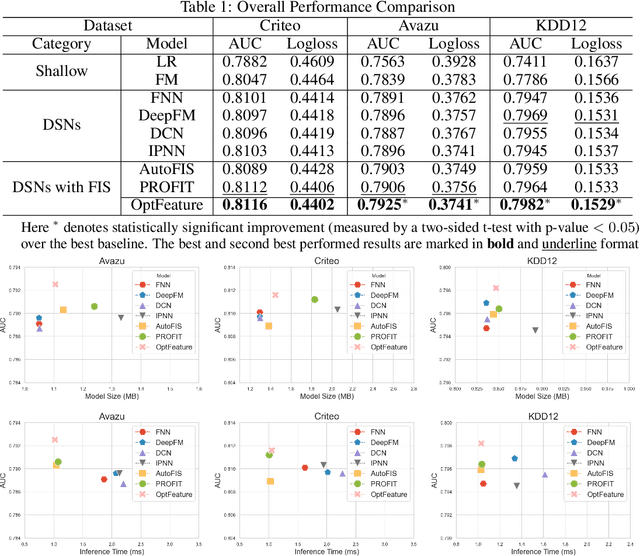
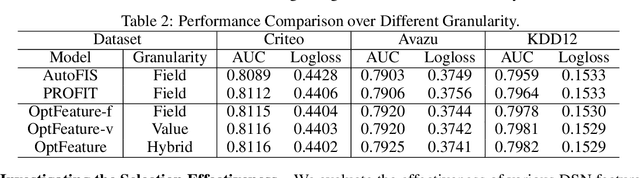

Deep sparse networks are widely investigated as a neural network architecture for prediction tasks with high-dimensional sparse features, with which feature interaction selection is a critical component. While previous methods primarily focus on how to search feature interaction in a coarse-grained space, less attention has been given to a finer granularity. In this work, we introduce a hybrid-grained feature interaction selection approach that targets both feature field and feature value for deep sparse networks. To explore such expansive space, we propose a decomposed space which is calculated on the fly. We then develop a selection algorithm called OptFeature, which efficiently selects the feature interaction from both the feature field and the feature value simultaneously. Results from experiments on three large real-world benchmark datasets demonstrate that OptFeature performs well in terms of accuracy and efficiency. Additional studies support the feasibility of our method.
Robust Long-Tailed Learning via Label-Aware Bounded CVaR
Aug 29, 2023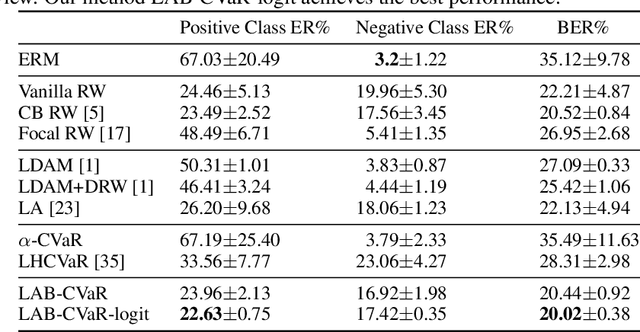
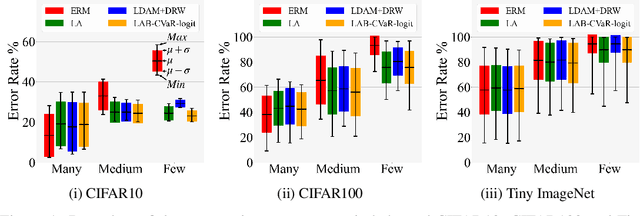
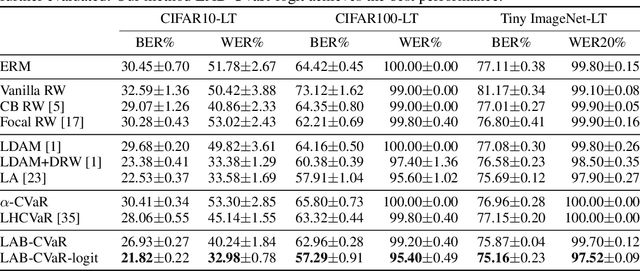
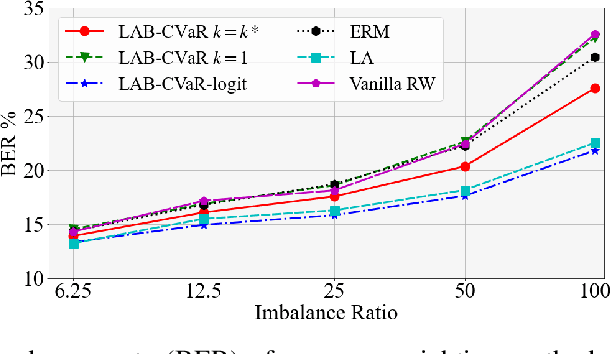
Data in the real-world classification problems are always imbalanced or long-tailed, wherein the majority classes have the most of the samples that dominate the model training. In such setting, the naive model tends to have poor performance on the minority classes. Previously, a variety of loss modifications have been proposed to address the long-tailed leaning problem, while these methods either treat the samples in the same class indiscriminatingly or lack a theoretical guarantee. In this paper, we propose two novel approaches based on CVaR (Conditional Value at Risk) to improve the performance of long-tailed learning with a solid theoretical ground. Specifically, we firstly introduce a Label-Aware Bounded CVaR (LAB-CVaR) loss to overcome the pessimistic result of the original CVaR, and further design the optimal weight bounds for LAB-CVaR theoretically. Based on LAB-CVaR, we additionally propose a LAB-CVaR with logit adjustment (LAB-CVaR-logit) loss to stabilize the optimization process, where we also offer the theoretical support. Extensive experiments on real-world datasets with long-tailed label distributions verify the superiority of our proposed methods.
OptMSM: Optimizing Multi-Scenario Modeling for Click-Through Rate Prediction
Jun 23, 2023A large-scale industrial recommendation platform typically consists of multiple associated scenarios, requiring a unified click-through rate (CTR) prediction model to serve them simultaneously. Existing approaches for multi-scenario CTR prediction generally consist of two main modules: i) a scenario-aware learning module that learns a set of multi-functional representations with scenario-shared and scenario-specific information from input features, and ii) a scenario-specific prediction module that serves each scenario based on these representations. However, most of these approaches primarily focus on improving the former module and neglect the latter module. This can result in challenges such as increased model parameter size, training difficulty, and performance bottlenecks for each scenario. To address these issues, we propose a novel framework called OptMSM (\textbf{Opt}imizing \textbf{M}ulti-\textbf{S}cenario \textbf{M}odeling). First, we introduce a simplified yet effective scenario-enhanced learning module to alleviate the aforementioned challenges. Specifically, we partition the input features into scenario-specific and scenario-shared features, which are mapped to specific information embedding encodings and a set of shared information embeddings, respectively. By imposing an orthogonality constraint on the shared information embeddings to facilitate the disentanglement of shared information corresponding to each scenario, we combine them with the specific information embeddings to obtain multi-functional representations. Second, we introduce a scenario-specific hypernetwork in the scenario-specific prediction module to capture interactions within each scenario more effectively, thereby alleviating the performance bottlenecks. Finally, we conduct extensive offline experiments and an online A/B test to demonstrate the effectiveness of OptMSM.
Explicit Feature Interaction-aware Uplift Network for Online Marketing
Jun 01, 2023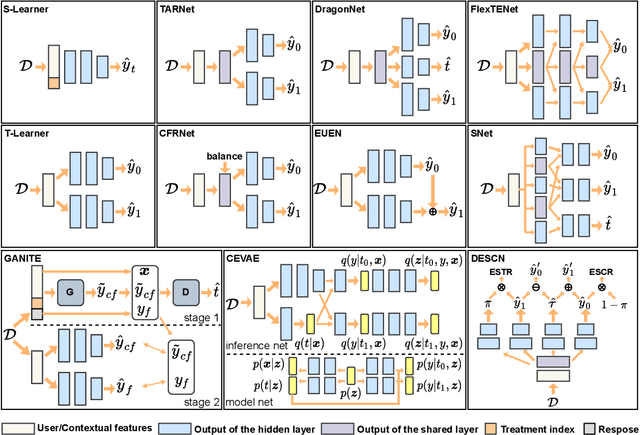



As a key component in online marketing, uplift modeling aims to accurately capture the degree to which different treatments motivate different users, such as coupons or discounts, also known as the estimation of individual treatment effect (ITE). In an actual business scenario, the options for treatment may be numerous and complex, and there may be correlations between different treatments. In addition, each marketing instance may also have rich user and contextual features. However, existing methods still fall short in both fully exploiting treatment information and mining features that are sensitive to a particular treatment. In this paper, we propose an explicit feature interaction-aware uplift network (EFIN) to address these two problems. Our EFIN includes four customized modules: 1) a feature encoding module encodes not only the user and contextual features, but also the treatment features; 2) a self-interaction module aims to accurately model the user's natural response with all but the treatment features; 3) a treatment-aware interaction module accurately models the degree to which a particular treatment motivates a user through interactions between the treatment features and other features, i.e., ITE; and 4) an intervention constraint module is used to balance the ITE distribution of users between the control and treatment groups so that the model would still achieve a accurate uplift ranking on data collected from a non-random intervention marketing scenario. We conduct extensive experiments on two public datasets and one product dataset to verify the effectiveness of our EFIN. In addition, our EFIN has been deployed in a credit card bill payment scenario of a large online financial platform with a significant improvement.