 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLing Chen
Interest Clock: Time Perception in Real-Time Streaming Recommendation System
Apr 30, 2024
User preferences follow a dynamic pattern over a day, e.g., at 8 am, a user might prefer to read news, while at 8 pm, they might prefer to watch movies. Time modeling aims to enable recommendation systems to perceive time changes to capture users' dynamic preferences over time, which is an important and challenging problem in recommendation systems. Especially, streaming recommendation systems in the industry, with only available samples of the current moment, present greater challenges for time modeling. There is still a lack of effective time modeling methods for streaming recommendation systems. In this paper, we propose an effective and universal method Interest Clock to perceive time information in recommendation systems. Interest Clock first encodes users' time-aware preferences into a clock (hour-level personalized features) and then uses Gaussian distribution to smooth and aggregate them into the final interest clock embedding according to the current time for the final prediction. By arming base models with Interest Clock, we conduct online A/B tests, obtaining +0.509% and +0.758% improvements on user active days and app duration respectively. Besides, the extended offline experiments show improvements as well. Interest Clock has been deployed on Douyin Music App.
ICST-DNET: An Interpretable Causal Spatio-Temporal Diffusion Network for Traffic Speed Prediction
Apr 22, 2024Traffic speed prediction is significant for intelligent navigation and congestion alleviation. However, making accurate predictions is challenging due to three factors: 1) traffic diffusion, i.e., the spatial and temporal causality existing between the traffic conditions of multiple neighboring roads, 2) the poor interpretability of traffic data with complicated spatio-temporal correlations, and 3) the latent pattern of traffic speed fluctuations over time, such as morning and evening rush. Jointly considering these factors, in this paper, we present a novel architecture for traffic speed prediction, called Interpretable Causal Spatio-Temporal Diffusion Network (ICST-DNET). Specifically, ICST-DENT consists of three parts, namely the Spatio-Temporal Causality Learning (STCL), Causal Graph Generation (CGG), and Speed Fluctuation Pattern Recognition (SFPR) modules. First, to model the traffic diffusion within road networks, an STCL module is proposed to capture both the temporal causality on each individual road and the spatial causality in each road pair. The CGG module is then developed based on STCL to enhance the interpretability of the traffic diffusion procedure from the temporal and spatial perspectives. Specifically, a time causality matrix is generated to explain the temporal causality between each road's historical and future traffic conditions. For spatial causality, we utilize causal graphs to visualize the diffusion process in road pairs. Finally, to adapt to traffic speed fluctuations in different scenarios, we design a personalized SFPR module to select the historical timesteps with strong influences for learning the pattern of traffic speed fluctuations. Extensive experimental results prove that ICST-DNET can outperform all existing baselines, as evidenced by the higher prediction accuracy, ability to explain causality, and adaptability to different scenarios.
Graph Continual Learning with Debiased Lossless Memory Replay
Apr 17, 2024Real-life graph data often expands continually, rendering the learning of graph neural networks (GNNs) on static graph data impractical. Graph continual learning (GCL) tackles this problem by continually adapting GNNs to the expanded graph of the current task while maintaining the performance over the graph of previous tasks. Memory replay-based methods, which aim to replay data of previous tasks when learning new tasks, have been explored as one principled approach to mitigate the forgetting of the knowledge learned from the previous tasks. In this paper we extend this methodology with a novel framework, called Debiased Lossless Memory replay (DeLoMe). Unlike existing methods that sample nodes/edges of previous graphs to construct the memory, DeLoMe learns small lossless synthetic node representations as the memory. The learned memory can not only preserve the graph data privacy but also capture the holistic graph information, for which the sampling-based methods are not viable. Further, prior methods suffer from bias toward the current task due to the data imbalance between the classes in the memory data and the current data. A debiased GCL loss function is devised in DeLoMe to effectively alleviate this bias. Extensive experiments on four graph datasets show the effectiveness of DeLoMe under both class- and task-incremental learning settings.
DSGNN: A Dual-View Supergrid-Aware Graph Neural Network for Regional Air Quality Estimation
Apr 02, 2024Air quality estimation can provide air quality for target regions without air quality stations, which is useful for the public. Existing air quality estimation methods divide the study area into disjointed grid regions, and apply 2D convolution to model the spatial dependencies of adjacent grid regions based on the first law of geography, failing to model the spatial dependencies of distant grid regions. To this end, we propose a Dual-view Supergrid-aware Graph Neural Network (DSGNN) for regional air quality estimation, which can model the spatial dependencies of distant grid regions from dual views (i.e., satellite-derived aerosol optical depth (AOD) and meteorology). Specifically, images are utilized to represent the regional data (i.e., AOD data and meteorology data). The dual-view supergrid learning module is introduced to generate supergrids in a parameterized way. Based on the dual-view supergrids, the dual-view implicit correlation encoding module is introduced to learn the correlations between pairwise supergrids. In addition, the dual-view message passing network is introduced to implement the information interaction on the supergrid graphs and images. Extensive experiments on two real-world datasets demonstrate that DSGNN achieves the state-of-the-art performances on the air quality estimation task, outperforming the best baseline by an average of 19.64% in MAE.
D-PAD: Deep-Shallow Multi-Frequency Patterns Disentangling for Time Series Forecasting
Mar 26, 2024

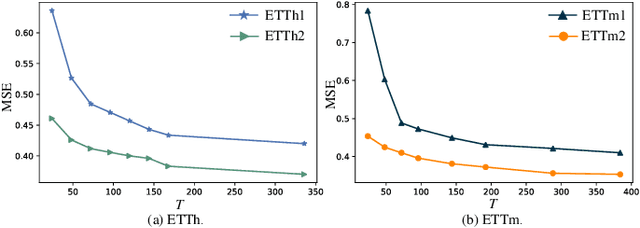
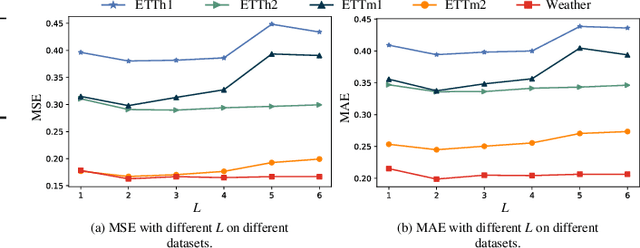
In time series forecasting, effectively disentangling intricate temporal patterns is crucial. While recent works endeavor to combine decomposition techniques with deep learning, multiple frequencies may still be mixed in the decomposed components, e.g., trend and seasonal. Furthermore, frequency domain analysis methods, e.g., Fourier and wavelet transforms, have limitations in resolution in the time domain and adaptability. In this paper, we propose D-PAD, a deep-shallow multi-frequency patterns disentangling neural network for time series forecasting. Specifically, a multi-component decomposing (MCD) block is introduced to decompose the series into components with different frequency ranges, corresponding to the "shallow" aspect. A decomposition-reconstruction-decomposition (D-R-D) module is proposed to progressively extract the information of frequencies mixed in the components, corresponding to the "deep" aspect. After that, an interaction and fusion (IF) module is used to further analyze the components. Extensive experiments on seven real-world datasets demonstrate that D-PAD achieves the state-of-the-art performance, outperforming the best baseline by an average of 9.48% and 7.15% in MSE and MAE, respectively.
Call Me When Necessary: LLMs can Efficiently and Faithfully Reason over Structured Environments
Mar 13, 2024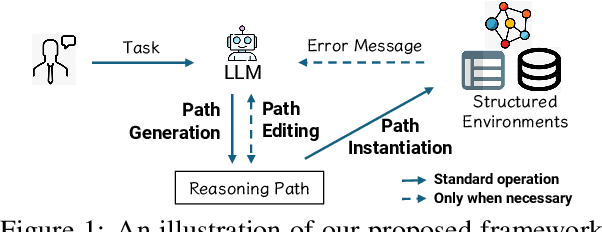
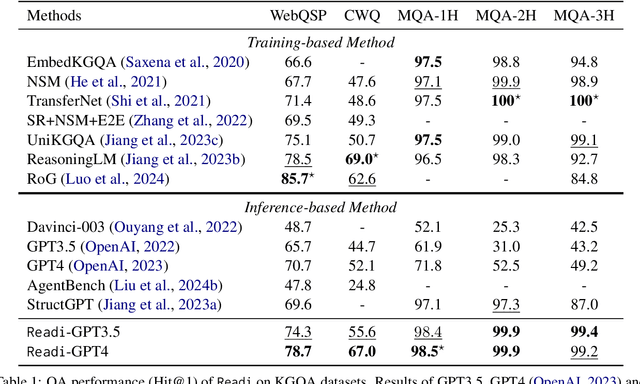
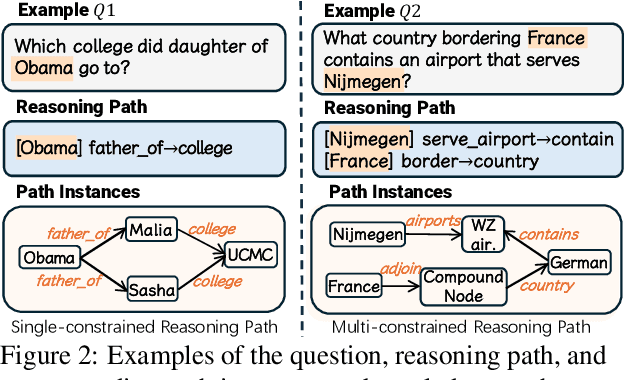
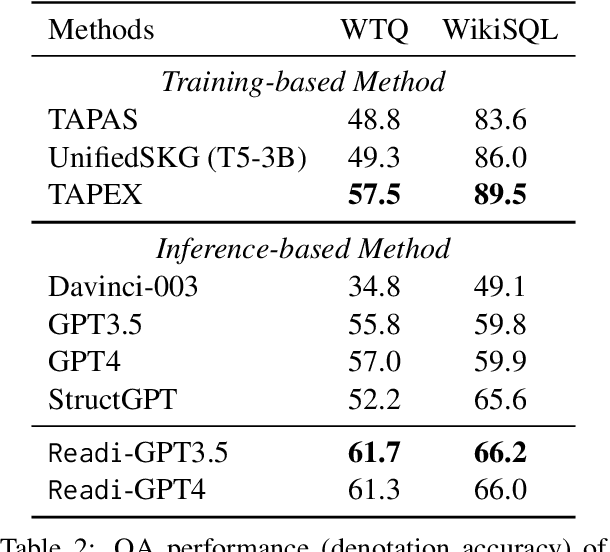
Large Language Models (LLMs) have shown potential in reasoning over structured environments, e.g., knowledge graph and table. Such tasks typically require multi-hop reasoning, i.e., match natural language utterance with instances in the environment. Previous methods leverage LLMs to incrementally build a reasoning path, where the LLMs either invoke tools or pick up schemas by step-by-step interacting with the environment. We propose Reasoning-Path-Editing (Readi), a novel framework where LLMs can efficiently and faithfully reason over structured environments. In Readi, LLMs initially generate a reasoning path given a query, and edit the path only when necessary. We instantiate the path on structured environments and provide feedback to edit the path if anything goes wrong. Experimental results on three KGQA datasets and two TableQA datasets show the effectiveness of Readi, significantly surpassing all LLM-based methods (by 9.1% on WebQSP, 12.4% on MQA-3H and 10.9% on WTQ), comparable with state-of-the-art fine-tuned methods (67% on CWQ and 74.7% on WebQSP) and substantially boosting the vanilla LLMs (by 14.9% on CWQ). Our code will be available upon publication.
Large Language Multimodal Models for 5-Year Chronic Disease Cohort Prediction Using EHR Data
Mar 02, 2024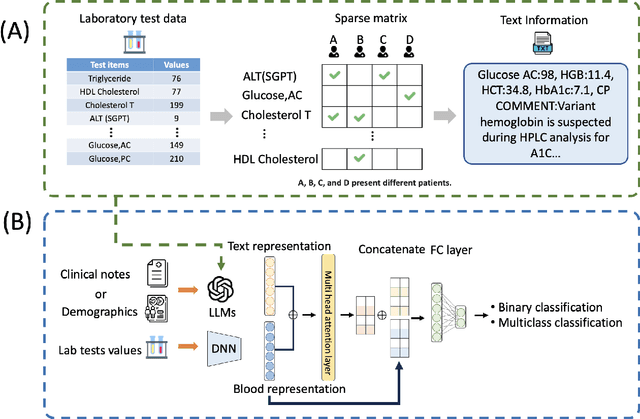
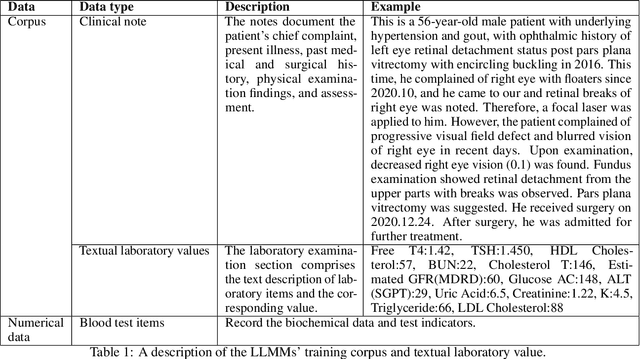

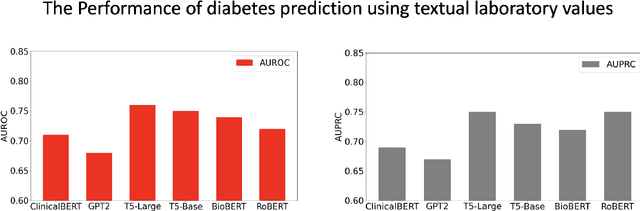
Chronic diseases such as diabetes are the leading causes of morbidity and mortality worldwide. Numerous research studies have been attempted with various deep learning models in diagnosis. However, most previous studies had certain limitations, including using publicly available datasets (e.g. MIMIC), and imbalanced data. In this study, we collected five-year electronic health records (EHRs) from the Taiwan hospital database, including 1,420,596 clinical notes, 387,392 laboratory test results, and more than 1,505 laboratory test items, focusing on research pre-training large language models. We proposed a novel Large Language Multimodal Models (LLMMs) framework incorporating multimodal data from clinical notes and laboratory test results for the prediction of chronic disease risk. Our method combined a text embedding encoder and multi-head attention layer to learn laboratory test values, utilizing a deep neural network (DNN) module to merge blood features with chronic disease semantics into a latent space. In our experiments, we observe that clinicalBERT and PubMed-BERT, when combined with attention fusion, can achieve an accuracy of 73% in multiclass chronic diseases and diabetes prediction. By transforming laboratory test values into textual descriptions and employing the Flan T-5 model, we achieved a 76% Area Under the ROC Curve (AUROC), demonstrating the effectiveness of leveraging numerical text data for training and inference in language models. This approach significantly improves the accuracy of early-stage diabetes prediction.
RetrievalQA: Assessing Adaptive Retrieval-Augmented Generation for Short-form Open-Domain Question Answering
Feb 26, 2024Adaptive retrieval-augmented generation (ARAG) aims to dynamically determine the necessity of retrieval for queries instead of retrieving indiscriminately to enhance the efficiency and relevance of the sourced information. However, previous works largely overlook the evaluation of ARAG approaches, leading to their effectiveness being understudied. This work presents a benchmark, RetrievalQA, comprising 1,271 short-form questions covering new world and long-tail knowledge. The knowledge necessary to answer the questions is absent from LLMs; therefore, external information must be retrieved to answer correctly. This makes RetrievalQA a suitable testbed to evaluate existing ARAG methods. We observe that calibration-based methods heavily rely on threshold tuning, while vanilla prompting is inadequate for guiding LLMs to make reliable retrieval decisions. Based on our findings, we propose Time-Aware Adaptive Retrieval (TA-ARE), a simple yet effective method that helps LLMs assess the necessity of retrieval without calibration or additional training. The dataset and code will be available at \url{https://github.com/hyintell/RetrievalQA}
Rethinking Human-like Translation Strategy: Integrating Drift-Diffusion Model with Large Language Models for Machine Translation
Feb 16, 2024
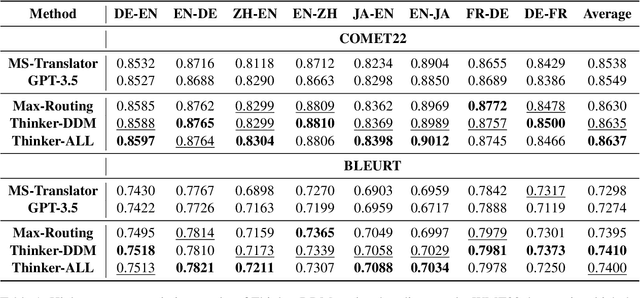
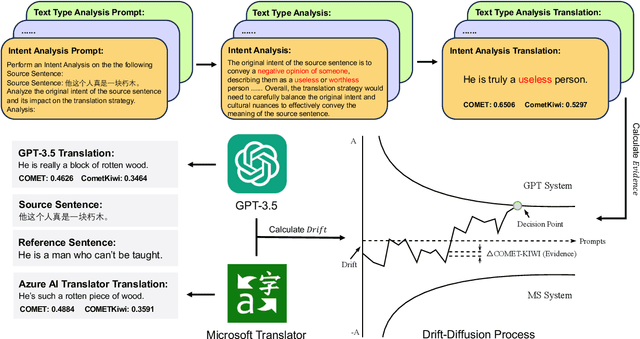
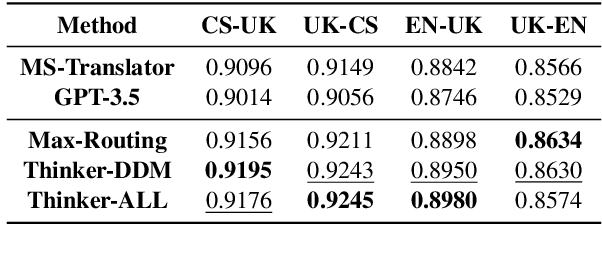
Large language models (LLMs) have demonstrated promising potential in various downstream tasks, including machine translation. However, prior work on LLM-based machine translation has mainly focused on better utilizing training data, demonstrations, or pre-defined and universal knowledge to improve performance, with a lack of consideration of decision-making like human translators. In this paper, we incorporate Thinker with the Drift-Diffusion Model (Thinker-DDM) to address this issue. We then redefine the Drift-Diffusion process to emulate human translators' dynamic decision-making under constrained resources. We conduct extensive experiments under the high-resource, low-resource, and commonsense translation settings using the WMT22 and CommonMT datasets, in which Thinker-DDM outperforms baselines in the first two scenarios. We also perform additional analysis and evaluation on commonsense translation to illustrate the high effectiveness and efficacy of the proposed method.
SA-MDKIF: A Scalable and Adaptable Medical Domain Knowledge Injection Framework for Large Language Models
Feb 01, 2024Recent advances in large language models (LLMs) have demonstrated exceptional performance in various natural language processing (NLP) tasks. However, their effective application in the medical domain is hampered by a lack of medical domain knowledge. In this study, we present SA-MDKIF, a scalable and adaptable framework that aims to inject medical knowledge into general-purpose LLMs through instruction tuning, thereby enabling adaptability for various downstream tasks. SA-MDKIF consists of two stages: skill training and skill adaptation. In the first stage, we define 12 basic medical skills and use AdaLoRA to train these skills based on uniformly formatted instructional datasets that we have constructed. In the next stage, we train the skill router using task-specific downstream data and use this router to integrate the acquired skills with LLMs during inference. Experimental results on 9 different medical tasks show that SA-MDKIF improves performance by 10-20% compared to the original LLMs. Notably, this improvement is particularly pronounced for unseen medical tasks, showing an improvement of up to 30%.