 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYuan Fang
Collaborative-Enhanced Prediction of Spending on Newly Downloaded Mobile Games under Consumption Uncertainty
Apr 12, 2024
With the surge in mobile gaming, accurately predicting user spending on newly downloaded games has become paramount for maximizing revenue. However, the inherently unpredictable nature of user behavior poses significant challenges in this endeavor. To address this, we propose a robust model training and evaluation framework aimed at standardizing spending data to mitigate label variance and extremes, ensuring stability in the modeling process. Within this framework, we introduce a collaborative-enhanced model designed to predict user game spending without relying on user IDs, thus ensuring user privacy and enabling seamless online training. Our model adopts a unique approach by separately representing user preferences and game features before merging them as input to the spending prediction module. Through rigorous experimentation, our approach demonstrates notable improvements over production models, achieving a remarkable \textbf{17.11}\% enhancement on offline data and an impressive \textbf{50.65}\% boost in an online A/B test. In summary, our contributions underscore the importance of stable model training frameworks and the efficacy of collaborative-enhanced models in predicting user spending behavior in mobile gaming.
Samba: Semantic Segmentation of Remotely Sensed Images with State Space Model
Apr 11, 2024High-resolution remotely sensed images pose a challenge for commonly used semantic segmentation methods such as Convolutional Neural Network (CNN) and Vision Transformer (ViT). CNN-based methods struggle with handling such high-resolution images due to their limited receptive field, while ViT faces challenges in handling long sequences. Inspired by Mamba, which adopts a State Space Model (SSM) to efficiently capture global semantic information, we propose a semantic segmentation framework for high-resolution remotely sensed images, named Samba. Samba utilizes an encoder-decoder architecture, with Samba blocks serving as the encoder for efficient multi-level semantic information extraction, and UperNet functioning as the decoder. We evaluate Samba on the LoveDA, ISPRS Vaihingen, and ISPRS Potsdam datasets, comparing its performance against top-performing CNN and ViT methods. The results reveal that Samba achieved unparalleled performance on commonly used remote sensing datasets for semantic segmentation. Our proposed Samba demonstrates for the first time the effectiveness of SSM in semantic segmentation of remotely sensed images, setting a new benchmark in performance for Mamba-based techniques in this specific application. The source code and baseline implementations are available at https://github.com/zhuqinfeng1999/Samba.
Diffusion-based Negative Sampling on Graphs for Link Prediction
Mar 25, 2024



Link prediction is a fundamental task for graph analysis with important applications on the Web, such as social network analysis and recommendation systems, etc. Modern graph link prediction methods often employ a contrastive approach to learn robust node representations, where negative sampling is pivotal. Typical negative sampling methods aim to retrieve hard examples based on either predefined heuristics or automatic adversarial approaches, which might be inflexible or difficult to control. Furthermore, in the context of link prediction, most previous methods sample negative nodes from existing substructures of the graph, missing out on potentially more optimal samples in the latent space. To address these issues, we investigate a novel strategy of multi-level negative sampling that enables negative node generation with flexible and controllable ``hardness'' levels from the latent space. Our method, called Conditional Diffusion-based Multi-level Negative Sampling (DMNS), leverages the Markov chain property of diffusion models to generate negative nodes in multiple levels of variable hardness and reconcile them for effective graph link prediction. We further demonstrate that DMNS follows the sub-linear positivity principle for robust negative sampling. Extensive experiments on several benchmark datasets demonstrate the effectiveness of DMNS.
Energy-Efficient Hybrid Beamforming with Dynamic On-off Control for Integrated Sensing, Communications, and Powering
Mar 25, 2024This paper investigates the energy-efficient hybrid beamforming design for a multi-functional integrated sensing, communications, and powering (ISCAP) system. In this system, a base station (BS) with a hybrid analog-digital (HAD) architecture sends unified wireless signals to communicate with multiple information receivers (IRs), sense multiple point targets, and wirelessly charge multiple energy receivers (ERs) at the same time. To facilitate the energy-efficient design, we present a novel HAD architecture for the BS transmitter, which allows dynamic on-off control of its radio frequency (RF) chains and analog phase shifters (PSs) through a switch network. We also consider a practical and comprehensive power consumption model for the BS, by taking into account the power-dependent non-linear power amplifier (PA) efficiency, and the on-off non-transmission power consumption model of RF chains and PSs. We jointly design the hybrid beamforming and dynamic on-off control at the BS, aiming to minimize its total power consumption, while guaranteeing the performance requirements on communication rates, sensing Cram\'er-Rao bound (CRB), and harvested power levels. The formulation also takes into consideration the per-antenna transmit power constraint and the constant modulus constraints for the analog beamformer at the BS. The resulting optimization problem for ISCAP is highly non-convex. Please refer to the paper for a complete abstract.
Deep unfolding Network for Hyperspectral Image Super-Resolution with Automatic Exposure Correction
Mar 14, 2024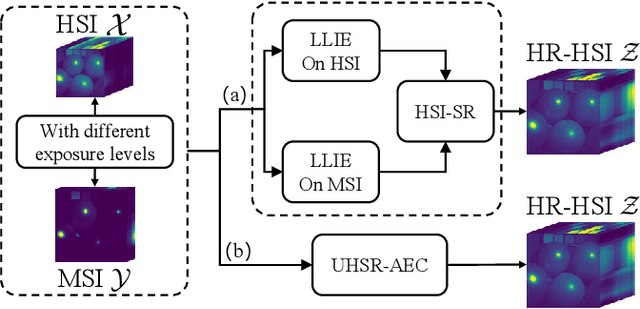
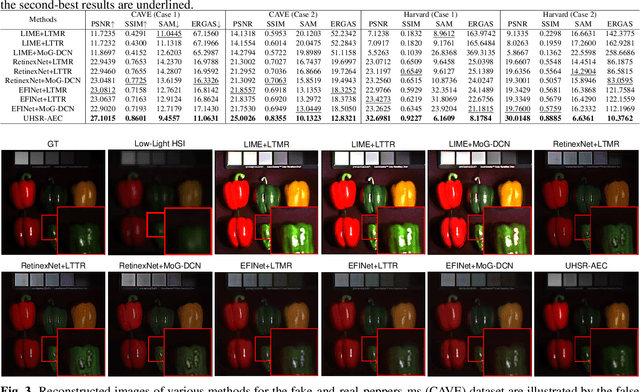
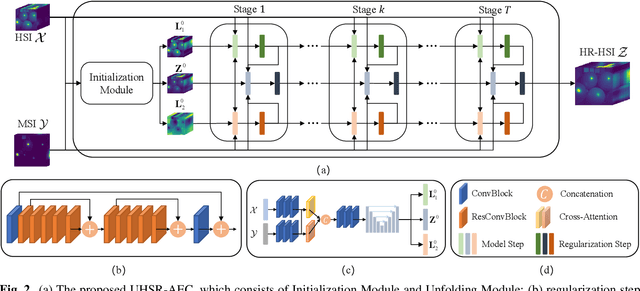
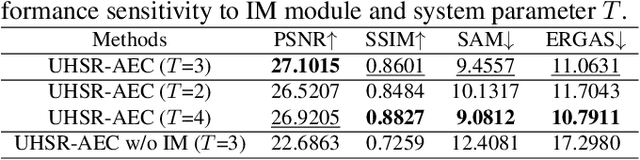
In recent years, the fusion of high spatial resolution multispectral image (HR-MSI) and low spatial resolution hyperspectral image (LR-HSI) has been recognized as an effective method for HSI super-resolution (HSI-SR). However, both HSI and MSI may be acquired under extreme conditions such as night or poorly illuminating scenarios, which may cause different exposure levels, thereby seriously downgrading the yielded HSISR. In contrast to most existing methods based on respective low-light enhancements (LLIE) of MSI and HSI followed by their fusion, a deep Unfolding HSI Super-Resolution with Automatic Exposure Correction (UHSR-AEC) is proposed, that can effectively generate a high-quality fused HSI-SR (in texture and features) even under very imbalanced exposures, thanks to the correlation between LLIE and HSI-SR taken into account. Extensive experiments are provided to demonstrate the state-of-the-art overall performance of the proposed UHSR-AEC, including comparison with some benchmark peer methods.
SIBO: A Simple Booster for Parameter-Efficient Fine-Tuning
Feb 19, 2024Fine-tuning all parameters of large language models (LLMs) necessitates substantial computational power and extended time. Latest advancements in parameter-efficient fine-tuning (PEFT) techniques, such as Adapter tuning and LoRA, allow for adjustments to only a minor fraction of the parameters of these LLMs. Concurrently, it has been noted that the issue of over-smoothing diminishes the effectiveness of these Transformer-based LLMs, resulting in suboptimal performances in downstream tasks. In this paper, we present SIBO, which is a SImple BOoster to enhance PEFT, by injecting an initial residual. SIBO is straight-forward and readily extensible to a range of state-of-the-art PEFT techniques to alleviate over-smoothing and enhance performance. Extensive experiments on 22 benchmark datasets demonstrate that SIBO significantly enhances the performance of various strong baselines, achieving up to 15.7% and 23.5% improvement over existing PEFT methods on the arithmetic and commonsense reasoning tasks, respectively.
Few-Shot Learning on Graphs: from Meta-learning to Pre-training and Prompting
Feb 02, 2024Graph representation learning, a critical step in graph-centric tasks, has seen significant advancements. Earlier techniques often operate in an end-to-end setting, where performance heavily relies on the availability of ample labeled data. This constraint has spurred the emergence of few-shot learning on graphs, where only a few task-specific labels are available for each task. Given the extensive literature in this field, this survey endeavors to synthesize recent developments, provide comparative insights, and identify future directions. We systematically categorize existing studies into three major families: meta-learning approaches, pre-training approaches, and hybrid approaches, with a finer-grained classification in each family to aid readers in their method selection process. Within each category, we analyze the relationships among these methods and compare their strengths and limitations. Finally, we outline prospective future directions for few-shot learning on graphs to catalyze continued innovation in this field.
HGPROMPT: Bridging Homogeneous and Heterogeneous Graphs for Few-shot Prompt Learning
Dec 04, 2023Graph neural networks (GNNs) and heterogeneous graph neural networks (HGNNs) are prominent techniques for homogeneous and heterogeneous graph representation learning, yet their performance in an end-to-end supervised framework greatly depends on the availability of task-specific supervision. To reduce the labeling cost, pre-training on self-supervised pretext tasks has become a popular paradigm,but there is often a gap between the pre-trained model and downstream tasks, stemming from the divergence in their objectives. To bridge the gap, prompt learning has risen as a promising direction especially in few-shot settings, without the need to fully fine-tune the pre-trained model. While there has been some early exploration of prompt-based learning on graphs, they primarily deal with homogeneous graphs, ignoring the heterogeneous graphs that are prevalent in downstream applications. In this paper, we propose HGPROMPT, a novel pre-training and prompting framework to unify not only pre-training and downstream tasks but also homogeneous and heterogeneous graphs via a dual-template design. Moreover, we propose dual-prompt in HGPROMPT to assist a downstream task in locating the most relevant prior to bridge the gaps caused by not only feature variations but also heterogeneity differences across tasks. Finally, we thoroughly evaluate and analyze HGPROMPT through extensive experiments on three public datasets.
MultiGPrompt for Multi-Task Pre-Training and Prompting on Graphs
Nov 28, 2023Graphs can inherently model interconnected objects on the Web, thereby facilitating a series of Web applications, such as web analyzing and content recommendation. Recently, Graph Neural Networks (GNNs) have emerged as a mainstream technique for graph representation learning. However, their efficacy within an end-to-end supervised framework is significantly tied to the availabilityof task-specific labels. To mitigate labeling costs and enhance robustness in few-shot settings, pre-training on self-supervised tasks has emerged as a promising method, while prompting has been proposed to further narrow the objective gap between pretext and downstream tasks. Although there has been some initial exploration of prompt-based learning on graphs, they primarily leverage a single pretext task, resulting in a limited subset of general knowledge that could be learned from the pre-training data. Hence, in this paper, we propose MultiGPrompt, a novel multi-task pre-training and prompting framework to exploit multiple pretext tasks for more comprehensive pre-trained knowledge. First, in pre-training, we design a set of pretext tokens to synergize multiple pretext tasks. Second, we propose a dual-prompt mechanism consisting of composed and open prompts to leverage task-specific and global pre-training knowledge, to guide downstream tasks in few-shot settings. Finally, we conduct extensive experiments on six public datasets to evaluate and analyze MultiGPrompt.
Generalized Graph Prompt: Toward a Unification of Pre-Training and Downstream Tasks on Graphs
Nov 26, 2023Graph neural networks have emerged as a powerful tool for graph representation learning, but their performance heavily relies on abundant task-specific supervision. To reduce labeling requirement, the "pre-train, prompt" paradigms have become increasingly common. However, existing study of prompting on graphs is limited, lacking a universal treatment to appeal to different downstream tasks. In this paper, we propose GraphPrompt, a novel pre-training and prompting framework on graphs. GraphPrompt not only unifies pre-training and downstream tasks into a common task template but also employs a learnable prompt to assist a downstream task in locating the most relevant knowledge from the pre-trained model in a task-specific manner. To further enhance GraphPrompt in these two stages, we extend it into GraphPrompt+ with two major enhancements. First, we generalize several popular graph pre-training tasks beyond simple link prediction to broaden the compatibility with our task template. Second, we propose a more generalized prompt design that incorporates a series of prompt vectors within every layer of the pre-trained graph encoder, in order to capitalize on the hierarchical information across different layers beyond just the readout layer. Finally, we conduct extensive experiments on five public datasets to evaluate and analyze GraphPrompt and GraphPrompt+.