 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHaolun Wu
Towards Group-aware Search Success
Apr 26, 2024
Traditional measures of search success often overlook the varying information needs of different demographic groups. To address this gap, we introduce a novel metric, named Group-aware Search Success (GA-SS). GA-SS redefines search success to ensure that all demographic groups achieve satisfaction from search outcomes. We introduce a comprehensive mathematical framework to calculate GA-SS, incorporating both static and stochastic ranking policies and integrating user browsing models for a more accurate assessment. In addition, we have proposed Group-aware Most Popular Completion (gMPC) ranking model to account for demographic variances in user intent, aligning more closely with the diverse needs of all user groups. We empirically validate our metric and approach with two real-world datasets: one focusing on query auto-completion and the other on movie recommendations, where the results highlight the impact of stochasticity and the complex interplay among various search success metrics. Our findings advocate for a more inclusive approach in measuring search success, as well as inspiring future investigations into the quality of service of search.
Structured Entity Extraction Using Large Language Models
Feb 06, 2024Recent advances in machine learning have significantly impacted the field of information extraction, with Large Language Models (LLMs) playing a pivotal role in extracting structured information from unstructured text. This paper explores the challenges and limitations of current methodologies in structured entity extraction and introduces a novel approach to address these issues. We contribute to the field by first introducing and formalizing the task of Structured Entity Extraction (SEE), followed by proposing Approximate Entity Set OverlaP (AESOP) Metric designed to appropriately assess model performance on this task. Later, we propose a new model that harnesses the power of LLMs for enhanced effectiveness and efficiency through decomposing the entire extraction task into multiple stages. Quantitative evaluation and human side-by-side evaluation confirm that our model outperforms baselines, offering promising directions for future advancements in structured entity extraction.
Less or More From Teacher: Exploiting Trilateral Geometry For Knowledge Distillation
Jan 01, 2024Knowledge distillation aims to train a compact student network using soft supervision from a larger teacher network and hard supervision from ground truths. However, determining an optimal knowledge fusion ratio that balances these supervisory signals remains challenging. Prior methods generally resort to a constant or heuristic-based fusion ratio, which often falls short of a proper balance. In this study, we introduce a novel adaptive method for learning a sample-wise knowledge fusion ratio, exploiting both the correctness of teacher and student, as well as how well the student mimics the teacher on each sample. Our method naturally leads to the intra-sample trilateral geometric relations among the student prediction ($S$), teacher prediction ($T$), and ground truth ($G$). To counterbalance the impact of outliers, we further extend to the inter-sample relations, incorporating the teacher's global average prediction $\bar{T}$ for samples within the same class. A simple neural network then learns the implicit mapping from the intra- and inter-sample relations to an adaptive, sample-wise knowledge fusion ratio in a bilevel-optimization manner. Our approach provides a simple, practical, and adaptable solution for knowledge distillation that can be employed across various architectures and model sizes. Extensive experiments demonstrate consistent improvements over other loss re-weighting methods on image classification, attack detection, and click-through rate prediction.
Density-based User Representation through Gaussian Process Regression for Multi-interest Personalized Retrieval
Nov 15, 2023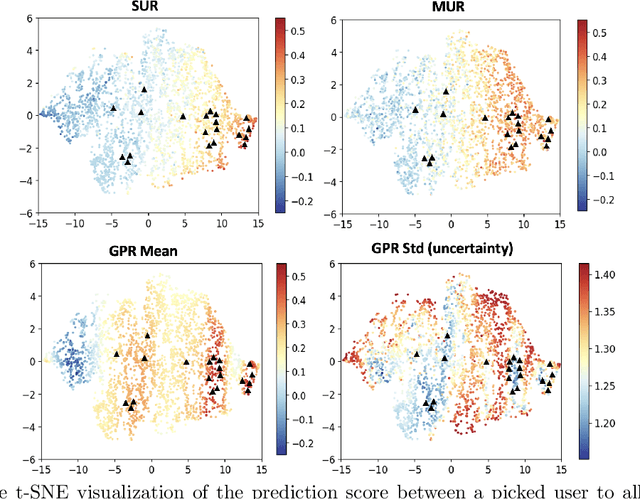

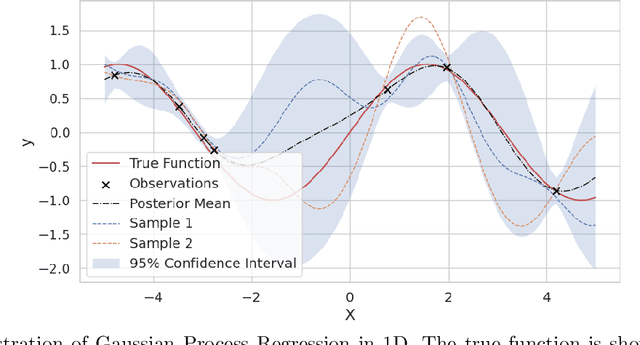
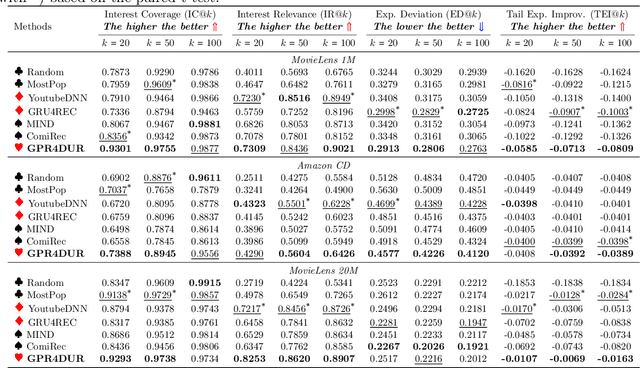
Accurate modeling of the diverse and dynamic interests of users remains a significant challenge in the design of personalized recommender systems. Existing user modeling methods, like single-point and multi-point representations, have limitations w.r.t. accuracy, diversity, computational cost, and adaptability. To overcome these deficiencies, we introduce density-based user representations (DURs), a novel model that leverages Gaussian process regression for effective multi-interest recommendation and retrieval. Our approach, GPR4DUR, exploits DURs to capture user interest variability without manual tuning, incorporates uncertainty-awareness, and scales well to large numbers of users. Experiments using real-world offline datasets confirm the adaptability and efficiency of GPR4DUR, while online experiments with simulated users demonstrate its ability to address the exploration-exploitation trade-off by effectively utilizing model uncertainty.
Teacher-Student Architecture for Knowledge Distillation: A Survey
Aug 08, 2023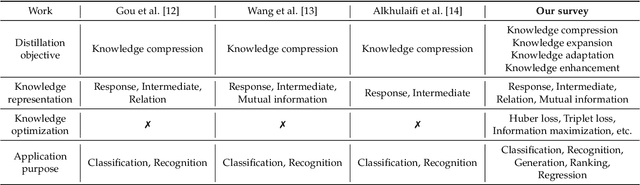
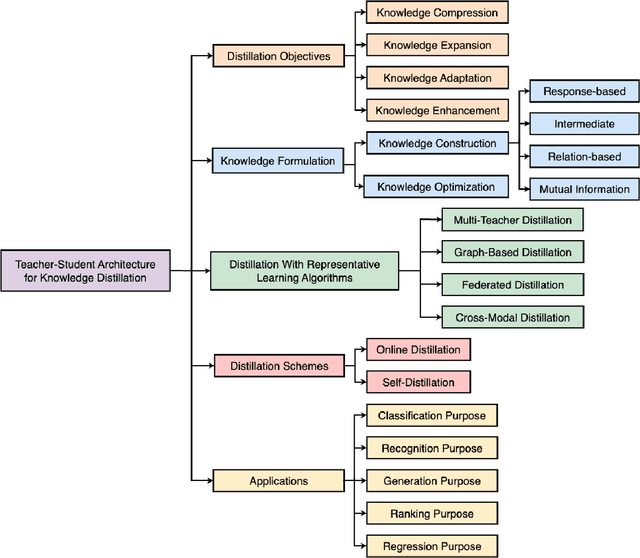

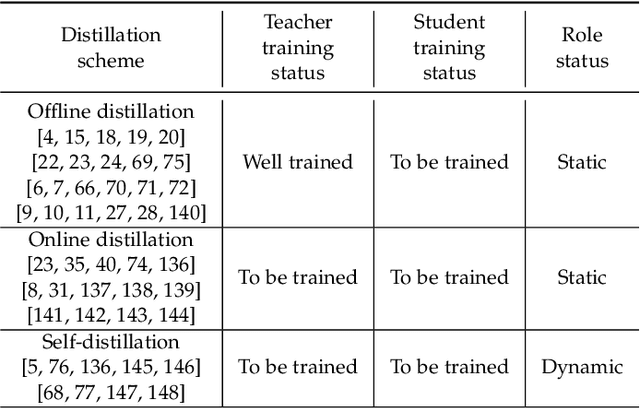
Although Deep neural networks (DNNs) have shown a strong capacity to solve large-scale problems in many areas, such DNNs are hard to be deployed in real-world systems due to their voluminous parameters. To tackle this issue, Teacher-Student architectures were proposed, where simple student networks with a few parameters can achieve comparable performance to deep teacher networks with many parameters. Recently, Teacher-Student architectures have been effectively and widely embraced on various knowledge distillation (KD) objectives, including knowledge compression, knowledge expansion, knowledge adaptation, and knowledge enhancement. With the help of Teacher-Student architectures, current studies are able to achieve multiple distillation objectives through lightweight and generalized student networks. Different from existing KD surveys that primarily focus on knowledge compression, this survey first explores Teacher-Student architectures across multiple distillation objectives. This survey presents an introduction to various knowledge representations and their corresponding optimization objectives. Additionally, we provide a systematic overview of Teacher-Student architectures with representative learning algorithms and effective distillation schemes. This survey also summarizes recent applications of Teacher-Student architectures across multiple purposes, including classification, recognition, generation, ranking, and regression. Lastly, potential research directions in KD are investigated, focusing on architecture design, knowledge quality, and theoretical studies of regression-based learning, respectively. Through this comprehensive survey, industry practitioners and the academic community can gain valuable insights and guidelines for effectively designing, learning, and applying Teacher-Student architectures on various distillation objectives.
Feature Representation Learning for Click-through Rate Prediction: A Review and New Perspectives
Feb 04, 2023



Representation learning has been a critical topic in machine learning. In Click-through Rate Prediction, most features are represented as embedding vectors and learned simultaneously with other parameters in the model. With the development of CTR models, feature representation learning has become a trending topic and has been extensively studied by both industrial and academic researchers in recent years. This survey aims at summarizing the feature representation learning in a broader picture and pave the way for future research. To achieve such a goal, we first present a taxonomy of current research methods on feature representation learning following two main issues: (i) which feature to represent and (ii) how to represent these features. Then we give a detailed description of each method regarding these two issues. Finally, the review concludes with a discussion on the future directions of this field.
A Survey of Diversification Techniques in Search and Recommendation
Jan 02, 2023

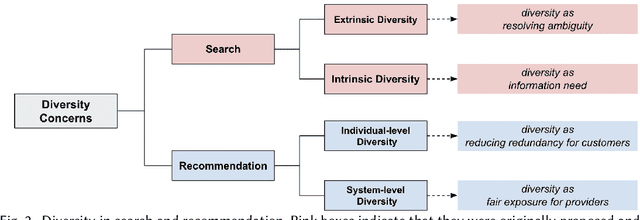
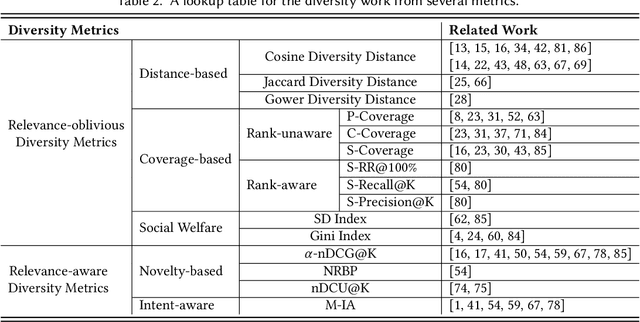
Diversifying search results is an important research topic in retrieval systems in order to satisfy both the various interests of customers and the equal market exposure of providers. There has been a growing attention on diversity-aware research during recent years, accompanied by a proliferation of literature on methods to promote diversity in search and recommendation. However, the diversity-aware studies in retrieval systems lack a systematic organization and are rather fragmented. In this survey, we are the first to propose a unified taxonomy for classifying the metrics and approaches of diversification in both search and recommendation, which are two of the most extensively researched fields of retrieval systems. We begin the survey with a brief discussion of why diversity is important in retrieval systems, followed by a summary of the various diversity concerns in search and recommendation, highlighting their relationship and differences. For the survey's main body, we present a unified taxonomy of diversification metrics and approaches in retrieval systems, from both the search and recommendation perspectives. In the later part of the survey, we discuss the openness research questions of diversity-aware research in search and recommendation in an effort to inspire future innovations and encourage the implementation of diversity in real-world systems.
Intent-aware Multi-source Contrastive Alignment for Tag-enhanced Recommendation
Nov 11, 2022



To offer accurate and diverse recommendation services, recent methods use auxiliary information to foster the learning process of user and item representations. Many SOTA methods fuse different sources of information (user, item, knowledge graph, tags, etc.) into a graph and use Graph Neural Networks to introduce the auxiliary information through the message passing paradigm. In this work, we seek an alternative framework that is light and effective through self-supervised learning across different sources of information, particularly for the commonly accessible item tag information. We use a self-supervision signal to pair users with the auxiliary information associated with the items they have interacted with before. To achieve the pairing, we create a proxy training task. For a given item, the model predicts the correct pairing between the representations obtained from the users that have interacted with this item and the assigned tags. This design provides an efficient solution, using the auxiliary information directly to enhance the quality of user and item embeddings. User behavior in recommendation systems is driven by the complex interactions of many factors behind the decision-making processes. To make the pairing process more fine-grained and avoid embedding collapse, we propose an intent-aware self-supervised pairing process where we split the user embeddings into multiple sub-embedding vectors. Each sub-embedding vector captures a specific user intent via self-supervised alignment with a particular cluster of tags. We integrate our designed framework with various recommendation models, demonstrating its flexibility and compatibility. Through comparison with numerous SOTA methods on seven real-world datasets, we show that our method can achieve better performance while requiring less training time. This indicates the potential of applying our approach on web-scale datasets.
Coarse-to-Fine Knowledge-Enhanced Multi-Interest Learning Framework for Multi-Behavior Recommendation
Aug 05, 2022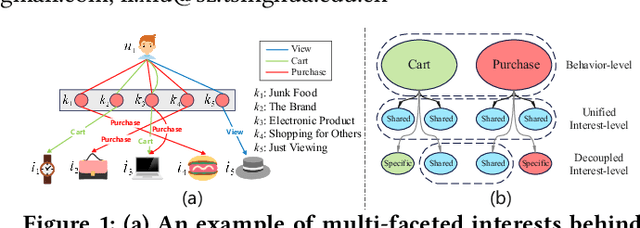
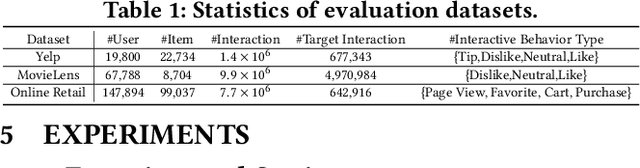

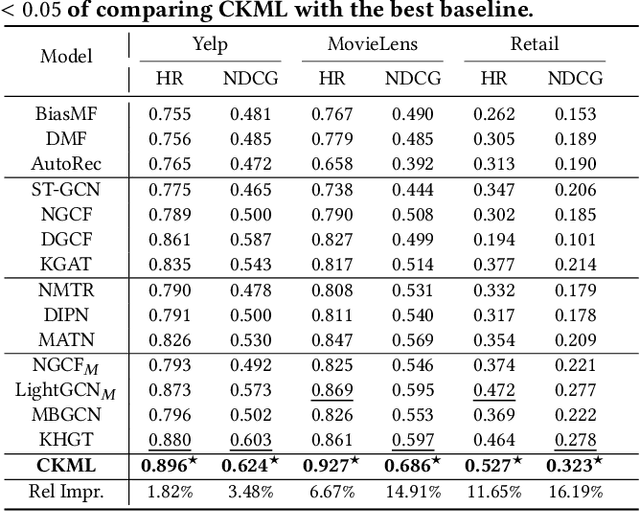
Multi-types of behaviors (e.g., clicking, adding to cart, purchasing, etc.) widely exist in most real-world recommendation scenarios, which are beneficial to learn users' multi-faceted preferences. As dependencies are explicitly exhibited by the multiple types of behaviors, effectively modeling complex behavior dependencies is crucial for multi-behavior prediction. The state-of-the-art multi-behavior models learn behavior dependencies indistinguishably with all historical interactions as input. However, different behaviors may reflect different aspects of user preference, which means that some irrelevant interactions may play as noises to the target behavior to be predicted. To address the aforementioned limitations, we introduce multi-interest learning to the multi-behavior recommendation. More specifically, we propose a novel Coarse-to-fine Knowledge-enhanced Multi-interest Learning (CKML) framework to learn shared and behavior-specific interests for different behaviors. CKML introduces two advanced modules, namely Coarse-grained Interest Extracting (CIE) and Fine-grained Behavioral Correlation (FBC), which work jointly to capture fine-grained behavioral dependencies. CIE uses knowledge-aware information to extract initial representations of each interest. FBC incorporates a dynamic routing scheme to further assign each behavior among interests. Additionally, we use the self-attention mechanism to correlate different behavioral information at the interest level. Empirical results on three real-world datasets verify the effectiveness and efficiency of our model in exploiting multi-behavior data. Further experiments demonstrate the effectiveness of each module and the robustness and superiority of the shared and specific modelling paradigm for multi-behavior data.
Adapting Triplet Importance of Implicit Feedback for Personalized Recommendation
Aug 05, 2022



Implicit feedback is frequently used for developing personalized recommendation services due to its ubiquity and accessibility in real-world systems. In order to effectively utilize such information, most research adopts the pairwise ranking method on constructed training triplets (user, positive item, negative item) and aims to distinguish between positive items and negative items for each user. However, most of these methods treat all the training triplets equally, which ignores the subtle difference between different positive or negative items. On the other hand, even though some other works make use of the auxiliary information (e.g., dwell time) of user behaviors to capture this subtle difference, such auxiliary information is hard to obtain. To mitigate the aforementioned problems, we propose a novel training framework named Triplet Importance Learning (TIL), which adaptively learns the importance score of training triplets. We devise two strategies for the importance score generation and formulate the whole procedure as a bilevel optimization, which does not require any rule-based design. We integrate the proposed training procedure with several Matrix Factorization (MF)- and Graph Neural Network (GNN)-based recommendation models, demonstrating the compatibility of our framework. Via a comparison using three real-world datasets with many state-of-the-art methods, we show that our proposed method outperforms the best existing models by 3-21\% in terms of Recall@k for the top-k recommendation.