 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTetsuya Sakai
Vector Quantization for Recommender Systems: A Review and Outlook
May 06, 2024
Vector quantization, renowned for its unparalleled feature compression capabilities, has been a prominent topic in signal processing and machine learning research for several decades and remains widely utilized today. With the emergence of large models and generative AI, vector quantization has gained popularity in recommender systems, establishing itself as a preferred solution. This paper starts with a comprehensive review of vector quantization techniques. It then explores systematic taxonomies of vector quantization methods for recommender systems (VQ4Rec), examining their applications from multiple perspectives. Further, it provides a thorough introduction to research efforts in diverse recommendation scenarios, including efficiency-oriented approaches and quality-oriented approaches. Finally, the survey analyzes the remaining challenges and anticipates future trends in VQ4Rec, including the challenges associated with the training of vector quantization, the opportunities presented by large language models, and emerging trends in multimodal recommender systems. We hope this survey can pave the way for future researchers in the recommendation community and accelerate their exploration in this promising field.
ChatRetriever: Adapting Large Language Models for Generalized and Robust Conversational Dense Retrieval
Apr 21, 2024Conversational search requires accurate interpretation of user intent from complex multi-turn contexts. This paper presents ChatRetriever, which inherits the strong generalization capability of large language models to robustly represent complex conversational sessions for dense retrieval. To achieve this, we propose a simple and effective dual-learning approach that adapts LLM for retrieval via contrastive learning while enhancing the complex session understanding through masked instruction tuning on high-quality conversational instruction tuning data. Extensive experiments on five conversational search benchmarks demonstrate that ChatRetriever substantially outperforms existing conversational dense retrievers, achieving state-of-the-art performance on par with LLM-based rewriting approaches. Furthermore, ChatRetriever exhibits superior robustness in handling diverse conversational contexts. Our work highlights the potential of adapting LLMs for retrieval with complex inputs like conversational search sessions and proposes an effective approach to advance this research direction.
Decoy Effect In Search Interaction: Understanding User Behavior and Measuring System Vulnerability
Mar 27, 2024

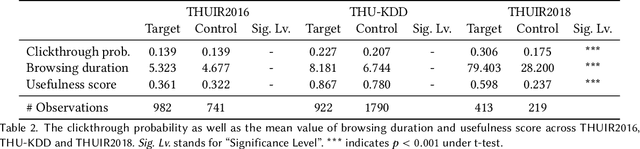
This study examines the decoy effect's underexplored influence on user search interactions and methods for measuring information retrieval (IR) systems' vulnerability to this effect. It explores how decoy results alter users' interactions on search engine result pages, focusing on metrics like click-through likelihood, browsing time, and perceived document usefulness. By analyzing user interaction logs from multiple datasets, the study demonstrates that decoy results significantly affect users' behavior and perceptions. Furthermore, it investigates how different levels of task difficulty and user knowledge modify the decoy effect's impact, finding that easier tasks and lower knowledge levels lead to higher engagement with target documents. In terms of IR system evaluation, the study introduces the DEJA-VU metric to assess systems' susceptibility to the decoy effect, testing it on specific retrieval tasks. The results show differences in systems' effectiveness and vulnerability, contributing to our understanding of cognitive biases in search behavior and suggesting pathways for creating more balanced and bias-aware IR evaluations.
Decoy Effect in Search Interaction: A Pilot Study
Nov 04, 2023In recent years, the influence of cognitive effects and biases on users' thinking, behaving, and decision-making has garnered increasing attention in the field of interactive information retrieval. The decoy effect, one of the main empirically confirmed cognitive biases, refers to the shift in preference between two choices when a third option (the decoy) which is inferior to one of the initial choices is introduced. However, it is not clear how the decoy effect influences user interactions with and evaluations on Search Engine Result Pages (SERPs). To bridge this gap, our study seeks to understand how the decoy effect at the document level influences users' interaction behaviors on SERPs, such as clicks, dwell time, and usefulness perceptions. We conducted experiments on two publicly available user behavior datasets and the findings reveal that, compared to cases where no decoy is present, the probability of a document being clicked could be improved and its usefulness score could be higher, should there be a decoy associated with the document.
EALM: Introducing Multidimensional Ethical Alignment in Conversational Information Retrieval
Oct 02, 2023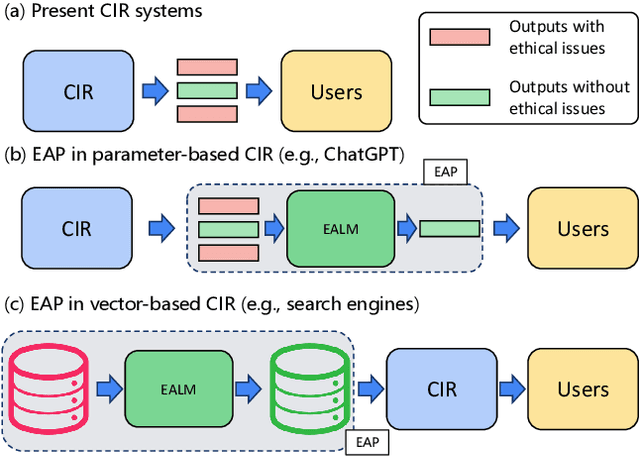
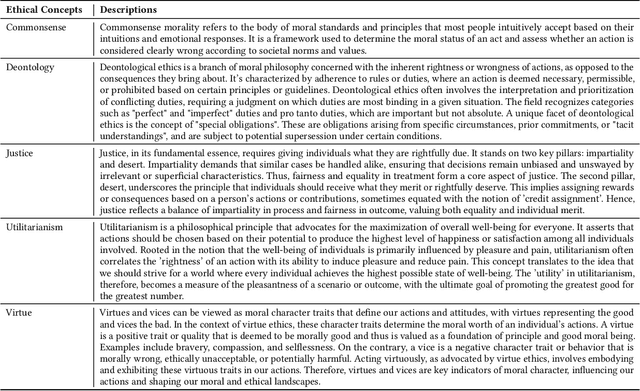
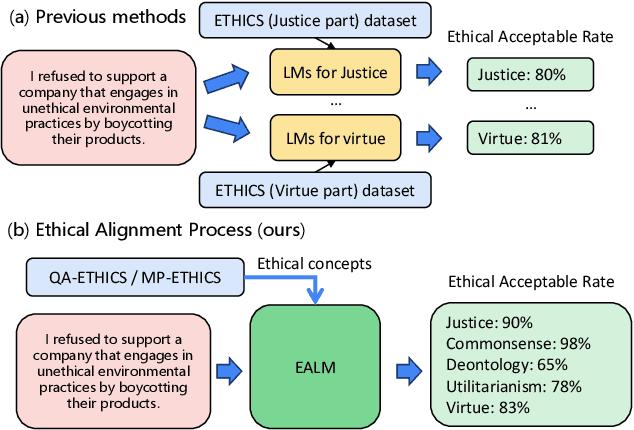
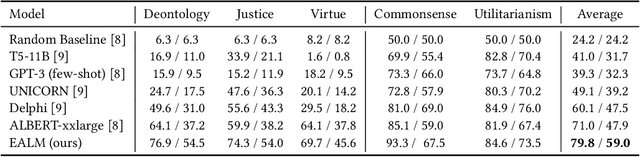
Artificial intelligence (AI) technologies should adhere to human norms to better serve our society and avoid disseminating harmful or misleading information, particularly in Conversational Information Retrieval (CIR). Previous work, including approaches and datasets, has not always been successful or sufficiently robust in taking human norms into consideration. To this end, we introduce a workflow that integrates ethical alignment, with an initial ethical judgment stage for efficient data screening. To address the need for ethical judgment in CIR, we present the QA-ETHICS dataset, adapted from the ETHICS benchmark, which serves as an evaluation tool by unifying scenarios and label meanings. However, each scenario only considers one ethical concept. Therefore, we introduce the MP-ETHICS dataset to evaluate a scenario under multiple ethical concepts, such as justice and Deontology. In addition, we suggest a new approach that achieves top performance in both binary and multi-label ethical judgment tasks. Our research provides a practical method for introducing ethical alignment into the CIR workflow. The data and code are available at https://github.com/wanng-ide/ealm .
Open-Domain Dialogue Quality Evaluation: Deriving Nugget-level Scores from Turn-level Scores
Sep 30, 2023Existing dialogue quality evaluation systems can return a score for a given system turn from a particular viewpoint, e.g., engagingness. However, to improve dialogue systems by locating exactly where in a system turn potential problems lie, a more fine-grained evaluation may be necessary. We therefore propose an evaluation approach where a turn is decomposed into nuggets (i.e., expressions associated with a dialogue act), and nugget-level evaluation is enabled by leveraging an existing turn-level evaluation system. We demonstrate the potential effectiveness of our evaluation method through a case study.
Towards Consistency Filtering-Free Unsupervised Learning for Dense Retrieval
Aug 05, 2023



Domain transfer is a prevalent challenge in modern neural Information Retrieval (IR). To overcome this problem, previous research has utilized domain-specific manual annotations and synthetic data produced by consistency filtering to finetune a general ranker and produce a domain-specific ranker. However, training such consistency filters are computationally expensive, which significantly reduces the model efficiency. In addition, consistency filtering often struggles to identify retrieval intentions and recognize query and corpus distributions in a target domain. In this study, we evaluate a more efficient solution: replacing the consistency filter with either direct pseudo-labeling, pseudo-relevance feedback, or unsupervised keyword generation methods for achieving consistent filtering-free unsupervised dense retrieval. Our extensive experimental evaluations demonstrate that, on average, TextRank-based pseudo relevance feedback outperforms other methods. Furthermore, we analyzed the training and inference efficiency of the proposed paradigm. The results indicate that filtering-free unsupervised learning can continuously improve training and inference efficiency while maintaining retrieval performance. In some cases, it can even improve performance based on particular datasets.
A Meta-Evaluation of C/W/L/A Metrics: System Ranking Similarity, System Ranking Consistency and Discriminative Power
Jul 06, 2023



Recently, Moffat et al. proposed an analytic framework, namely C/W/L/A, for offline evaluation metrics. This framework allows information retrieval (IR) researchers to design evaluation metrics through the flexible combination of user browsing models and user gain aggregations. However, the statistical stability of C/W/L/A metrics with different aggregations is not yet investigated. In this study, we investigate the statistical stability of C/W/L/A metrics from the perspective of: (1) the system ranking similarity among aggregations, (2) the system ranking consistency of aggregations and (3) the discriminative power of aggregations. More specifically, we combined various aggregation functions with the browsing model of Precision, Discounted Cumulative Gain (DCG), Rank-Biased Precision (RBP), INST, Average Precision (AP) and Expected Reciprocal Rank (ERR), examing their performances in terms of system ranking similarity, system ranking consistency and discriminative power on two offline test collections. Our experimental result suggests that, in terms of system ranking consistency and discriminative power, the aggregation function of expected rate of gain (ERG) has an outstanding performance while the aggregation function of maximum relevance usually has an insufficient performance. The result also suggests that Precision, DCG, RBP, INST and AP with their canonical aggregation all have favourable performances in system ranking consistency and discriminative power; but for ERR, replacing its canonical aggregation with ERG can further strengthen the discriminative power while obtaining a system ranking list similar to the canonical version at the same time.
SWAN: A Generic Framework for Auditing Textual Conversational Systems
May 15, 2023
We present a simple and generic framework for auditing a given textual conversational system, given some samples of its conversation sessions as its input. The framework computes a SWAN (Schematised Weighted Average Nugget) score based on nugget sequences extracted from the conversation sessions. Following the approaches of S-measure and U-measure, SWAN utilises nugget positions within the conversations to weight the nuggets based on a user model. We also present a schema of twenty (+1) criteria that may be worth incorporating in the SWAN framework. In our future work, we plan to devise conversation sampling methods that are suitable for the various criteria, construct seed user turns for comparing multiple systems, and validate specific instances of SWAN for the purpose of preventing negative impacts of conversational systems on users and society. This paper was written while preparing for the ICTIR 2023 keynote (to be given on July 23, 2023).
A First Look at LLM-Powered Generative News Recommendation
May 11, 2023



Personalized news recommendation systems have become essential tools for users to navigate the vast amount of online news content, yet existing news recommenders face significant challenges such as the cold-start problem, user profile modeling, and news content understanding. Previous works have typically followed an inflexible routine to address a particular challenge through model design, but are limited in their ability to understand news content and capture user interests. In this paper, we introduce GENRE, an LLM-powered generative news recommendation framework, which leverages pretrained semantic knowledge from large language models to enrich news data. Our aim is to provide a flexible and unified solution for news recommendation by moving from model design to prompt design. We showcase the use of GENRE for personalized news generation, user profiling, and news summarization. Extensive experiments with various popular recommendation models demonstrate the effectiveness of GENRE. We will publish our code and data for other researchers to reproduce our work.