 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFengran Mo
Language Modeling Using Tensor Trains
May 07, 2024
We propose a novel tensor network language model based on the simplest tensor network (i.e., tensor trains), called `Tensor Train Language Model' (TTLM). TTLM represents sentences in an exponential space constructed by the tensor product of words, but computing the probabilities of sentences in a low-dimensional fashion. We demonstrate that the architectures of Second-order RNNs, Recurrent Arithmetic Circuits (RACs), and Multiplicative Integration RNNs are, essentially, special cases of TTLM. Experimental evaluations on real language modeling tasks show that the proposed variants of TTLM (i.e., TTLM-Large and TTLM-Tiny) outperform the vanilla Recurrent Neural Networks (RNNs) with low-scale of hidden units. (The code is available at https://github.com/shuishen112/tensortrainlm.)
A User-Centric Benchmark for Evaluating Large Language Models
Apr 23, 2024Large Language Models (LLMs) are essential tools to collaborate with users on different tasks. Evaluating their performance to serve users' needs in real-world scenarios is important. While many benchmarks have been created, they mainly focus on specific predefined model abilities. Few have covered the intended utilization of LLMs by real users. To address this oversight, we propose benchmarking LLMs from a user perspective in both dataset construction and evaluation designs. We first collect 1846 real-world use cases with 15 LLMs from a user study with 712 participants from 23 countries. These self-reported cases form the User Reported Scenarios(URS) dataset with a categorization of 7 user intents. Secondly, on this authentic multi-cultural dataset, we benchmark 10 LLM services on their efficacy in satisfying user needs. Thirdly, we show that our benchmark scores align well with user-reported experience in LLM interactions across diverse intents, both of which emphasize the overlook of subjective scenarios. In conclusion, our study proposes to benchmark LLMs from a user-centric perspective, aiming to facilitate evaluations that better reflect real user needs. The benchmark dataset and code are available at https://github.com/Alice1998/URS.
ChatRetriever: Adapting Large Language Models for Generalized and Robust Conversational Dense Retrieval
Apr 21, 2024Conversational search requires accurate interpretation of user intent from complex multi-turn contexts. This paper presents ChatRetriever, which inherits the strong generalization capability of large language models to robustly represent complex conversational sessions for dense retrieval. To achieve this, we propose a simple and effective dual-learning approach that adapts LLM for retrieval via contrastive learning while enhancing the complex session understanding through masked instruction tuning on high-quality conversational instruction tuning data. Extensive experiments on five conversational search benchmarks demonstrate that ChatRetriever substantially outperforms existing conversational dense retrievers, achieving state-of-the-art performance on par with LLM-based rewriting approaches. Furthermore, ChatRetriever exhibits superior robustness in handling diverse conversational contexts. Our work highlights the potential of adapting LLMs for retrieval with complex inputs like conversational search sessions and proposes an effective approach to advance this research direction.
ConvSDG: Session Data Generation for Conversational Search
Mar 17, 2024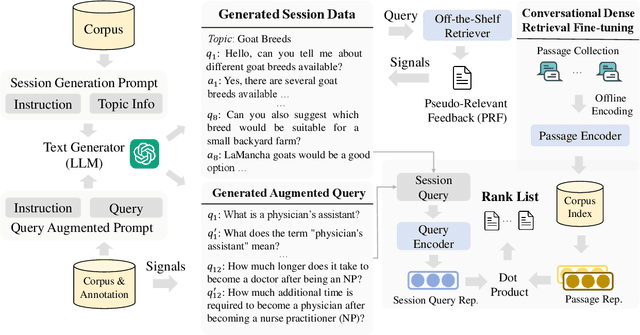


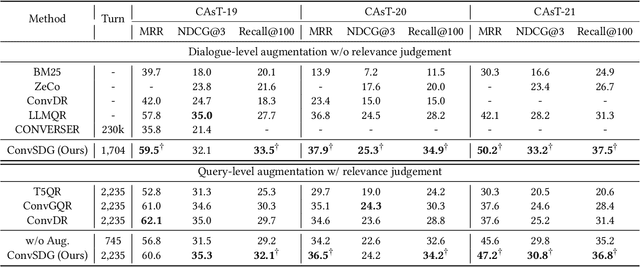
Conversational search provides a more convenient interface for users to search by allowing multi-turn interaction with the search engine. However, the effectiveness of the conversational dense retrieval methods is limited by the scarcity of training data required for their fine-tuning. Thus, generating more training conversational sessions with relevant labels could potentially improve search performance. Based on the promising capabilities of large language models (LLMs) on text generation, we propose ConvSDG, a simple yet effective framework to explore the feasibility of boosting conversational search by using LLM for session data generation. Within this framework, we design dialogue/session-level and query-level data generation with unsupervised and semi-supervised learning, according to the availability of relevance judgments. The generated data are used to fine-tune the conversational dense retriever. Extensive experiments on four widely used datasets demonstrate the effectiveness and broad applicability of our ConvSDG framework compared with several strong baselines.
History-Aware Conversational Dense Retrieval
Jan 30, 2024Conversational search facilitates complex information retrieval by enabling multi-turn interactions between users and the system. Supporting such interactions requires a comprehensive understanding of the conversational inputs to formulate a good search query based on historical information. In particular, the search query should include the relevant information from the previous conversation turns. However, current approaches for conversational dense retrieval primarily rely on fine-tuning a pre-trained ad-hoc retriever using the whole conversational search session, which can be lengthy and noisy. Moreover, existing approaches are limited by the amount of manual supervision signals in the existing datasets. To address the aforementioned issues, we propose a History-Aware Conversational Dense Retrieval (HAConvDR) system, which incorporates two ideas: context-denoised query reformulation and automatic mining of supervision signals based on the actual impact of historical turns. Experiments on two public conversational search datasets demonstrate the improved history modeling capability of HAConvDR, in particular for long conversations with topic shifts.
Collaboration and Transition: Distilling Item Transitions into Multi-Query Self-Attention for Sequential Recommendation
Nov 02, 2023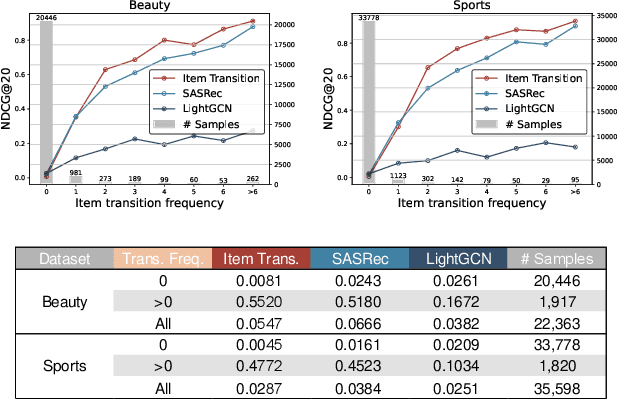
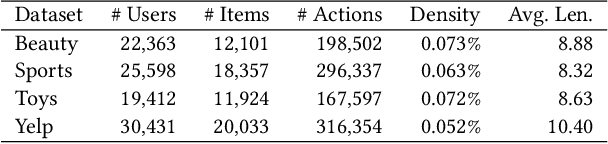

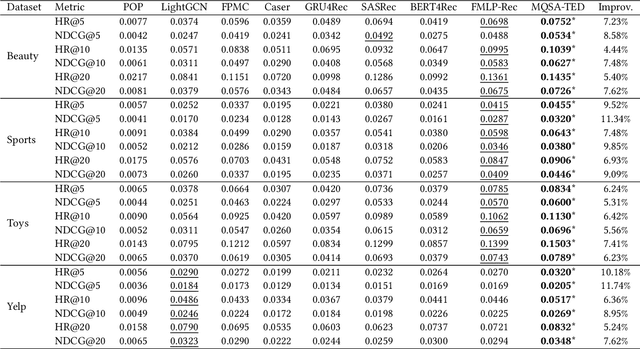
Modern recommender systems employ various sequential modules such as self-attention to learn dynamic user interests. However, these methods are less effective in capturing collaborative and transitional signals within user interaction sequences. First, the self-attention architecture uses the embedding of a single item as the attention query, which is inherently challenging to capture collaborative signals. Second, these methods typically follow an auto-regressive framework, which is unable to learn global item transition patterns. To overcome these limitations, we propose a new method called Multi-Query Self-Attention with Transition-Aware Embedding Distillation (MQSA-TED). First, we propose an $L$-query self-attention module that employs flexible window sizes for attention queries to capture collaborative signals. In addition, we introduce a multi-query self-attention method that balances the bias-variance trade-off in modeling user preferences by combining long and short-query self-attentions. Second, we develop a transition-aware embedding distillation module that distills global item-to-item transition patterns into item embeddings, which enables the model to memorize and leverage transitional signals and serves as a calibrator for collaborative signals. Experimental results on four real-world datasets show the superiority of our proposed method over state-of-the-art sequential recommendation methods.
MoqaGPT : Zero-Shot Multi-modal Open-domain Question Answering with Large Language Model
Oct 20, 2023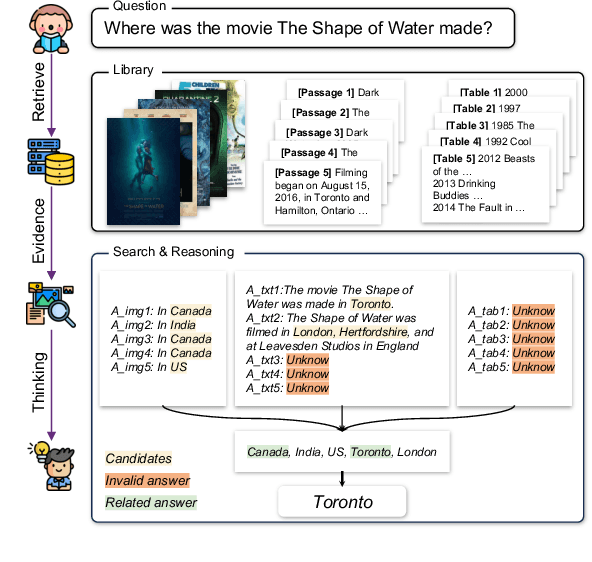

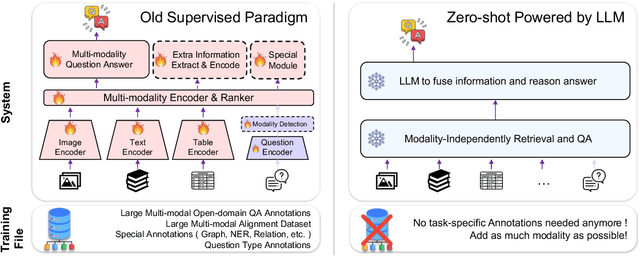
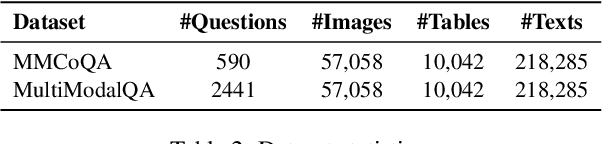
Multi-modal open-domain question answering typically requires evidence retrieval from databases across diverse modalities, such as images, tables, passages, etc. Even Large Language Models (LLMs) like GPT-4 fall short in this task. To enable LLMs to tackle the task in a zero-shot manner, we introduce MoqaGPT, a straightforward and flexible framework. Using a divide-and-conquer strategy that bypasses intricate multi-modality ranking, our framework can accommodate new modalities and seamlessly transition to new models for the task. Built upon LLMs, MoqaGPT retrieves and extracts answers from each modality separately, then fuses this multi-modal information using LLMs to produce a final answer. Our methodology boosts performance on the MMCoQA dataset, improving F1 by +37.91 points and EM by +34.07 points over the supervised baseline. On the MultiModalQA dataset, MoqaGPT surpasses the zero-shot baseline, improving F1 by 9.5 points and EM by 10.1 points, and significantly closes the gap with supervised methods. Our codebase is available at https://github.com/lezhang7/MOQAGPT.
Learning to Relate to Previous Turns in Conversational Search
Jun 05, 2023
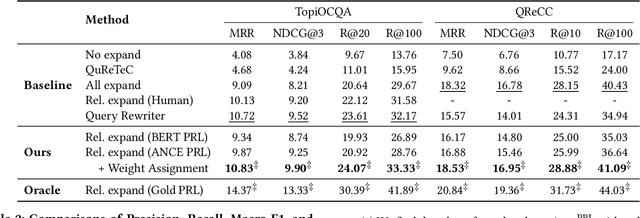


Conversational search allows a user to interact with a search system in multiple turns. A query is strongly dependent on the conversation context. An effective way to improve retrieval effectiveness is to expand the current query with historical queries. However, not all the previous queries are related to, and useful for expanding the current query. In this paper, we propose a new method to select relevant historical queries that are useful for the current query. To cope with the lack of labeled training data, we use a pseudo-labeling approach to annotate useful historical queries based on their impact on the retrieval results. The pseudo-labeled data are used to train a selection model. We further propose a multi-task learning framework to jointly train the selector and the retriever during fine-tuning, allowing us to mitigate the possible inconsistency between the pseudo labels and the changed retriever. Extensive experiments on four conversational search datasets demonstrate the effectiveness and broad applicability of our method compared with several strong baselines.
ConvGQR: Generative Query Reformulation for Conversational Search
May 26, 2023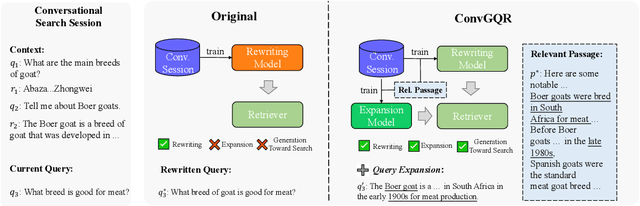
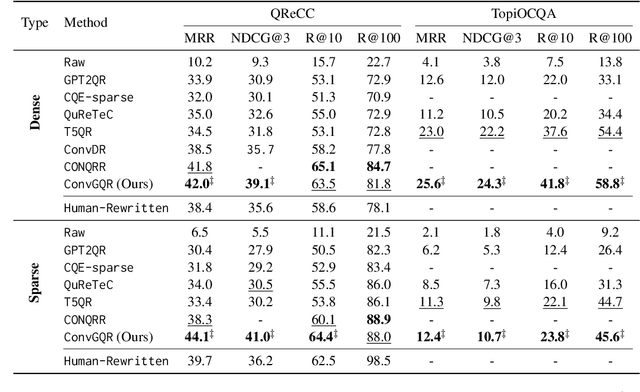


In conversational search, the user's real search intent for the current turn is dependent on the previous conversation history. It is challenging to determine a good search query from the whole conversation context. To avoid the expensive re-training of the query encoder, most existing methods try to learn a rewriting model to de-contextualize the current query by mimicking the manual query rewriting. However, manually rewritten queries are not always the best search queries. Training a rewriting model on them would limit the model's ability to produce good search queries. Another useful hint is the potential answer to the question. In this paper, we propose ConvGQR, a new framework to reformulate conversational queries based on generative pre-trained language models (PLMs), one for query rewriting and another for generating potential answers. By combining both, ConvGQR can produce better search queries. In addition, to relate query reformulation to retrieval performance, we propose a knowledge infusion mechanism to optimize both query reformulation and retrieval. Extensive experiments on four conversational search datasets demonstrate the effectiveness of ConvGQR.
Large Language Models Know Your Contextual Search Intent: A Prompting Framework for Conversational Search
Mar 12, 2023



In this paper, we present a prompting framework called LLMCS that leverages large language models, such as code-davinci-002 of GPT-3, to perform few-shot conversational query rewriting for conversational search. We explore three prompting methods to generate multiple query rewrites and hypothetical responses, and propose aggregating them into an integrated representation that can robustly represent the user's real contextual search intent. Experimental results on two conversational search datasets, including CAst-19 and CAsT-20, show that our approach achieves significant improvements in search effectiveness over existing baselines and manual rewrites. Notably, LLMCS can significantly outperform the state-of-the-art baselines by up to +5.9\% and +32.9\% w.r.t. NDCG@3 on CAsT-19 and CAsT-20, highlighting the vast potential of large language models for conversational search. Our code will be released at https://github.com/kyriemao/LLMCS.