 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZhicheng Dou
Extending Llama-3's Context Ten-Fold Overnight
Apr 30, 2024
We extend the context length of Llama-3-8B-Instruct from 8K to 80K via QLoRA fine-tuning. The entire training cycle is super efficient, which takes 8 hours on one 8xA800 (80G) GPU machine. The resulted model exhibits superior performances across a broad range of evaluation tasks, such as NIHS, topic retrieval, and long-context language understanding; meanwhile, it also well preserves the original capability over short contexts. The dramatic context extension is mainly attributed to merely 3.5K synthetic training samples generated by GPT-4 , which indicates the LLMs' inherent (yet largely underestimated) potential to extend its original context length. In fact, the context length could be extended far beyond 80K with more computation resources. Therefore, the team will publicly release the entire resources (including data, model, data generation pipeline, training code) so as to facilitate the future research from the community: \url{https://github.com/FlagOpen/FlagEmbedding}.
From Matching to Generation: A Survey on Generative Information Retrieval
Apr 23, 2024Information Retrieval (IR) systems are crucial tools for users to access information, widely applied in scenarios like search engines, question answering, and recommendation systems. Traditional IR methods, based on similarity matching to return ranked lists of documents, have been reliable means of information acquisition, dominating the IR field for years. With the advancement of pre-trained language models, generative information retrieval (GenIR) has emerged as a novel paradigm, gaining increasing attention in recent years. Currently, research in GenIR can be categorized into two aspects: generative document retrieval (GR) and reliable response generation. GR leverages the generative model's parameters for memorizing documents, enabling retrieval by directly generating relevant document identifiers without explicit indexing. Reliable response generation, on the other hand, employs language models to directly generate the information users seek, breaking the limitations of traditional IR in terms of document granularity and relevance matching, offering more flexibility, efficiency, and creativity, thus better meeting practical needs. This paper aims to systematically review the latest research progress in GenIR. We will summarize the advancements in GR regarding model training, document identifier, incremental learning, downstream tasks adaptation, multi-modal GR and generative recommendation, as well as progress in reliable response generation in aspects of internal knowledge memorization, external knowledge augmentation, generating response with citations and personal information assistant. We also review the evaluation, challenges and future prospects in GenIR systems. This review aims to offer a comprehensive reference for researchers in the GenIR field, encouraging further development in this area.
ChatRetriever: Adapting Large Language Models for Generalized and Robust Conversational Dense Retrieval
Apr 21, 2024Conversational search requires accurate interpretation of user intent from complex multi-turn contexts. This paper presents ChatRetriever, which inherits the strong generalization capability of large language models to robustly represent complex conversational sessions for dense retrieval. To achieve this, we propose a simple and effective dual-learning approach that adapts LLM for retrieval via contrastive learning while enhancing the complex session understanding through masked instruction tuning on high-quality conversational instruction tuning data. Extensive experiments on five conversational search benchmarks demonstrate that ChatRetriever substantially outperforms existing conversational dense retrievers, achieving state-of-the-art performance on par with LLM-based rewriting approaches. Furthermore, ChatRetriever exhibits superior robustness in handling diverse conversational contexts. Our work highlights the potential of adapting LLMs for retrieval with complex inputs like conversational search sessions and proposes an effective approach to advance this research direction.
An Analysis on Matching Mechanisms and Token Pruning for Late-interaction Models
Mar 20, 2024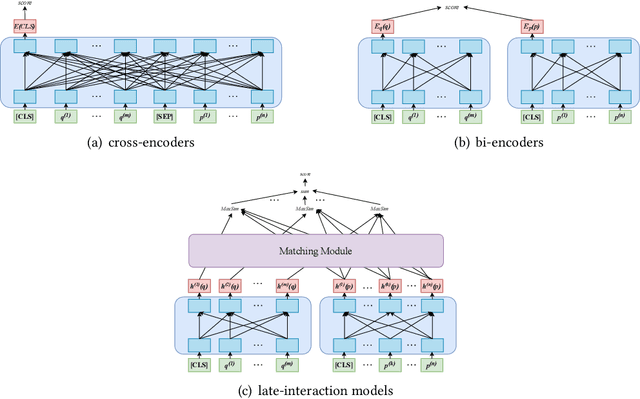

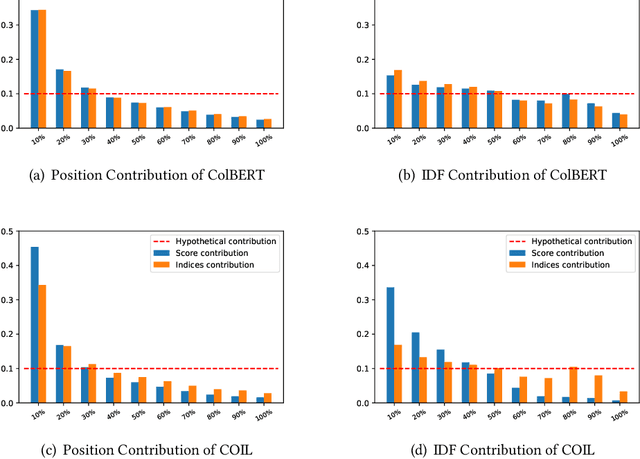
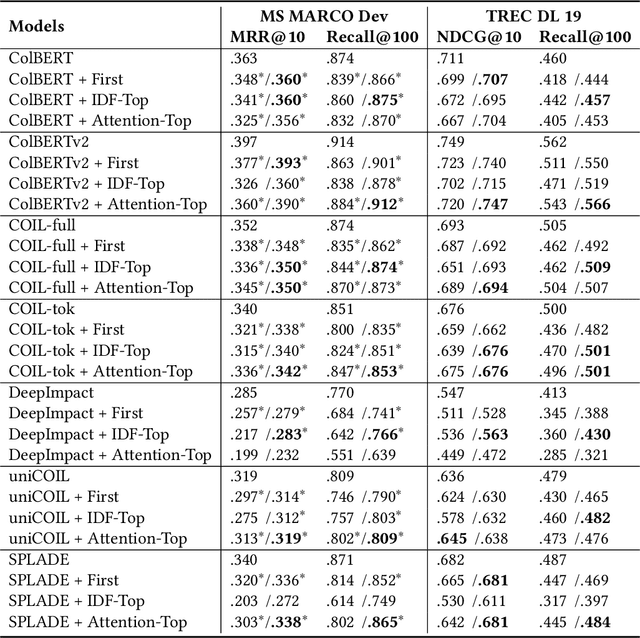
With the development of pre-trained language models, the dense retrieval models have become promising alternatives to the traditional retrieval models that rely on exact match and sparse bag-of-words representations. Different from most dense retrieval models using a bi-encoder to encode each query or document into a dense vector, the recently proposed late-interaction multi-vector models (i.e., ColBERT and COIL) achieve state-of-the-art retrieval effectiveness by using all token embeddings to represent documents and queries and modeling their relevance with a sum-of-max operation. However, these fine-grained representations may cause unacceptable storage overhead for practical search systems. In this study, we systematically analyze the matching mechanism of these late-interaction models and show that the sum-of-max operation heavily relies on the co-occurrence signals and some important words in the document. Based on these findings, we then propose several simple document pruning methods to reduce the storage overhead and compare the effectiveness of different pruning methods on different late-interaction models. We also leverage query pruning methods to further reduce the retrieval latency. We conduct extensive experiments on both in-domain and out-domain datasets and show that some of the used pruning methods can significantly improve the efficiency of these late-interaction models without substantially hurting their retrieval effectiveness.
UFO: a Unified and Flexible Framework for Evaluating Factuality of Large Language Models
Feb 22, 2024Large language models (LLMs) may generate text that lacks consistency with human knowledge, leading to factual inaccuracies or \textit{hallucination}. Existing research for evaluating the factuality of LLMs involves extracting fact claims using an LLM and verifying them against a predefined fact source. However, these evaluation metrics are task-specific, and not scalable, and the substitutability of fact sources in different tasks is under-explored. To address these challenges, we categorize four available fact sources: human-written evidence, reference documents, search engine results, and LLM knowledge, along with five text generation tasks containing six representative datasets. Then, we propose \texttt{UFO}, an LLM-based unified and flexible evaluation framework to verify facts against plug-and-play fact sources. We implement five evaluation scenarios based on this framework. Experimental results show that for most QA tasks, human-written evidence and reference documents are crucial, and they can substitute for each other in retrieval-augmented QA tasks. In news fact generation tasks, search engine results and LLM knowledge are essential. Our dataset and code are available at \url{https://github.com/WaldenRUC/UFO}.
Small Models, Big Insights: Leveraging Slim Proxy Models To Decide When and What to Retrieve for LLMs
Feb 22, 2024The integration of large language models (LLMs) and search engines represents a significant evolution in knowledge acquisition methodologies. However, determining the knowledge that an LLM already possesses and the knowledge that requires the help of a search engine remains an unresolved issue. Most existing methods solve this problem through the results of preliminary answers or reasoning done by the LLM itself, but this incurs excessively high computational costs. This paper introduces a novel collaborative approach, namely SlimPLM, that detects missing knowledge in LLMs with a slim proxy model, to enhance the LLM's knowledge acquisition process. We employ a proxy model which has far fewer parameters, and take its answers as heuristic answers. Heuristic answers are then utilized to predict the knowledge required to answer the user question, as well as the known and unknown knowledge within the LLM. We only conduct retrieval for the missing knowledge in questions that the LLM does not know. Extensive experimental results on five datasets with two LLMs demonstrate a notable improvement in the end-to-end performance of LLMs in question-answering tasks, achieving or surpassing current state-of-the-art models with lower LLM inference costs.
Interpreting Conversational Dense Retrieval by Rewriting-Enhanced Inversion of Session Embedding
Feb 20, 2024Conversational dense retrieval has shown to be effective in conversational search. However, a major limitation of conversational dense retrieval is their lack of interpretability, hindering intuitive understanding of model behaviors for targeted improvements. This paper presents CONVINV, a simple yet effective approach to shed light on interpretable conversational dense retrieval models. CONVINV transforms opaque conversational session embeddings into explicitly interpretable text while faithfully maintaining their original retrieval performance as much as possible. Such transformation is achieved by training a recently proposed Vec2Text model based on the ad-hoc query encoder, leveraging the fact that the session and query embeddings share the same space in existing conversational dense retrieval. To further enhance interpretability, we propose to incorporate external interpretable query rewrites into the transformation process. Extensive evaluations on three conversational search benchmarks demonstrate that CONVINV can yield more interpretable text and faithfully preserve original retrieval performance than baselines. Our work connects opaque session embeddings with transparent query rewriting, paving the way toward trustworthy conversational search.
BIDER: Bridging Knowledge Inconsistency for Efficient Retrieval-Augmented LLMs via Key Supporting Evidence
Feb 19, 2024Retrieval-augmented large language models (LLMs) have demonstrated efficacy in knowledge-intensive tasks such as open-domain QA, addressing inherent challenges in knowledge update and factual inadequacy. However, inconsistencies between retrieval knowledge and the necessary knowledge for LLMs, leading to a decline in LLM's answer quality. This paper introduces BIDER, an approach that refines retrieval documents into Key Supporting Evidence (KSE) through knowledge synthesis, supervised fine-tuning (SFT), and preference alignment. We train BIDER by learning from crafting KSE, while maximizing its output to align with LLM's information acquisition preferences through reinforcement learning. Evaluations across five datasets show BIDER boosts LLMs' answer quality by 7% while reducing input content length in retrieval documents by 80%, outperforming existing methods. The proposed KSE simulation effectively equips LLMs with essential information for accurate question answering.
Generalizing Conversational Dense Retrieval via LLM-Cognition Data Augmentation
Feb 19, 2024Conversational search utilizes muli-turn natural language contexts to retrieve relevant passages. Existing conversational dense retrieval models mostly view a conversation as a fixed sequence of questions and responses, overlooking the severe data sparsity problem -- that is, users can perform a conversation in various ways, and these alternate conversations are unrecorded. Consequently, they often struggle to generalize to diverse conversations in real-world scenarios. In this work, we propose a framework for generalizing Conversational dense retrieval via LLM-cognition data Augmentation (ConvAug). ConvAug first generates multi-level augmented conversations to capture the diverse nature of conversational contexts. Inspired by human cognition, we devise a cognition-aware process to mitigate the generation of false positives, false negatives, and hallucinations. Moreover, we develop a difficulty-adaptive sample filter that selects challenging samples for complex conversations, thereby giving the model a larger learning space. A contrastive learning objective is then employed to train a better conversational context encoder. Extensive experiments conducted on four public datasets, under both normal and zero-shot settings, demonstrate the effectiveness, generalizability, and applicability of ConvAug.
Metacognitive Retrieval-Augmented Large Language Models
Feb 18, 2024Retrieval-augmented generation have become central in natural language processing due to their efficacy in generating factual content. While traditional methods employ single-time retrieval, more recent approaches have shifted towards multi-time retrieval for multi-hop reasoning tasks. However, these strategies are bound by predefined reasoning steps, potentially leading to inaccuracies in response generation. This paper introduces MetaRAG, an approach that combines the retrieval-augmented generation process with metacognition. Drawing from cognitive psychology, metacognition allows an entity to self-reflect and critically evaluate its cognitive processes. By integrating this, MetaRAG enables the model to monitor, evaluate, and plan its response strategies, enhancing its introspective reasoning abilities. Through a three-step metacognitive regulation pipeline, the model can identify inadequacies in initial cognitive responses and fixes them. Empirical evaluations show that MetaRAG significantly outperforms existing methods.