 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKun Fang
Revisiting Random Weight Perturbation for Efficiently Improving Generalization
Mar 30, 2024
Improving the generalization ability of modern deep neural networks (DNNs) is a fundamental challenge in machine learning. Two branches of methods have been proposed to seek flat minima and improve generalization: one led by sharpness-aware minimization (SAM) minimizes the worst-case neighborhood loss through adversarial weight perturbation (AWP), and the other minimizes the expected Bayes objective with random weight perturbation (RWP). While RWP offers advantages in computation and is closely linked to AWP on a mathematical basis, its empirical performance has consistently lagged behind that of AWP. In this paper, we revisit the use of RWP for improving generalization and propose improvements from two perspectives: i) the trade-off between generalization and convergence and ii) the random perturbation generation. Through extensive experimental evaluations, we demonstrate that our enhanced RWP methods achieve greater efficiency in enhancing generalization, particularly in large-scale problems, while also offering comparable or even superior performance to SAM. The code is released at https://github.com/nblt/mARWP.
Small Models, Big Insights: Leveraging Slim Proxy Models To Decide When and What to Retrieve for LLMs
Feb 22, 2024The integration of large language models (LLMs) and search engines represents a significant evolution in knowledge acquisition methodologies. However, determining the knowledge that an LLM already possesses and the knowledge that requires the help of a search engine remains an unresolved issue. Most existing methods solve this problem through the results of preliminary answers or reasoning done by the LLM itself, but this incurs excessively high computational costs. This paper introduces a novel collaborative approach, namely SlimPLM, that detects missing knowledge in LLMs with a slim proxy model, to enhance the LLM's knowledge acquisition process. We employ a proxy model which has far fewer parameters, and take its answers as heuristic answers. Heuristic answers are then utilized to predict the knowledge required to answer the user question, as well as the known and unknown knowledge within the LLM. We only conduct retrieval for the missing knowledge in questions that the LLM does not know. Extensive experimental results on five datasets with two LLMs demonstrate a notable improvement in the end-to-end performance of LLMs in question-answering tasks, achieving or surpassing current state-of-the-art models with lower LLM inference costs.
Kernel PCA for Out-of-Distribution Detection
Feb 05, 2024Out-of-Distribution (OoD) detection is vital for the reliability of Deep Neural Networks (DNNs). Existing works have shown the insufficiency of Principal Component Analysis (PCA) straightforwardly applied on the features of DNNs in detecting OoD data from In-Distribution (InD) data. The failure of PCA suggests that the network features residing in OoD and InD are not well separated by simply proceeding in a linear subspace, which instead can be resolved through proper nonlinear mappings. In this work, we leverage the framework of Kernel PCA (KPCA) for OoD detection, seeking subspaces where OoD and InD features are allocated with significantly different patterns. We devise two feature mappings that induce non-linear kernels in KPCA to advocate the separability between InD and OoD data in the subspace spanned by the principal components. Given any test sample, the reconstruction error in such subspace is then used to efficiently obtain the detection result with $\mathcal{O}(1)$ time complexity in inference. Extensive empirical results on multiple OoD data sets and network structures verify the superiority of our KPCA-based detector in efficiency and efficacy with state-of-the-art OoD detection performances.
Revisiting Deep Ensemble for Out-of-Distribution Detection: A Loss Landscape Perspective
Oct 22, 2023Existing Out-of-Distribution (OoD) detection methods address to detect OoD samples from In-Distribution data (InD) mainly by exploring differences in features, logits and gradients in Deep Neural Networks (DNNs). We in this work propose a new perspective upon loss landscape and mode ensemble to investigate OoD detection. In the optimization of DNNs, there exist many local optima in the parameter space, or namely modes. Interestingly, we observe that these independent modes, which all reach low-loss regions with InD data (training and test data), yet yield significantly different loss landscapes with OoD data. Such an observation provides a novel view to investigate the OoD detection from the loss landscape and further suggests significantly fluctuating OoD detection performance across these modes. For instance, FPR values of the RankFeat method can range from 46.58% to 84.70% among 5 modes, showing uncertain detection performance evaluations across independent modes. Motivated by such diversities on OoD loss landscape across modes, we revisit the deep ensemble method for OoD detection through mode ensemble, leading to improved performance and benefiting the OoD detector with reduced variances. Extensive experiments covering varied OoD detectors and network structures illustrate high variances across modes and also validate the superiority of mode ensemble in boosting OoD detection. We hope this work could attract attention in the view of independent modes in the OoD loss landscape and more reliable evaluations on OoD detectors.
Baichuan 2: Open Large-scale Language Models
Sep 20, 2023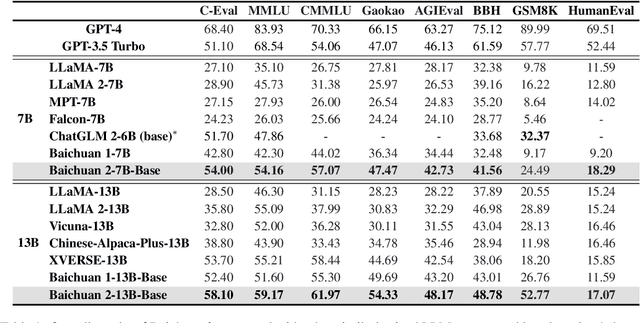
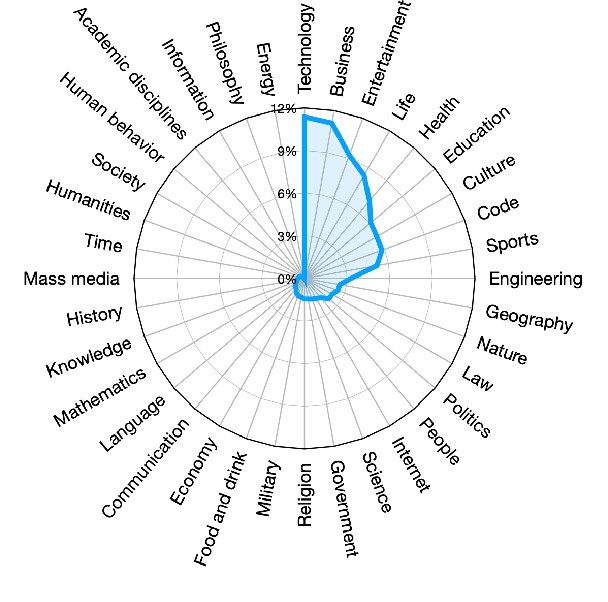
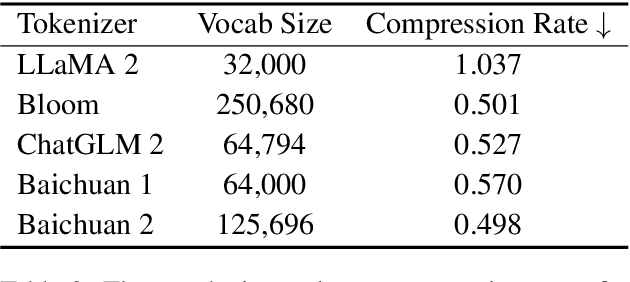
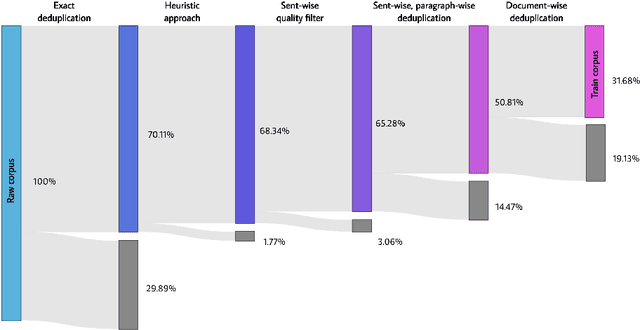
Large language models (LLMs) have demonstrated remarkable performance on a variety of natural language tasks based on just a few examples of natural language instructions, reducing the need for extensive feature engineering. However, most powerful LLMs are closed-source or limited in their capability for languages other than English. In this technical report, we present Baichuan 2, a series of large-scale multilingual language models containing 7 billion and 13 billion parameters, trained from scratch, on 2.6 trillion tokens. Baichuan 2 matches or outperforms other open-source models of similar size on public benchmarks like MMLU, CMMLU, GSM8K, and HumanEval. Furthermore, Baichuan 2 excels in vertical domains such as medicine and law. We will release all pre-training model checkpoints to benefit the research community in better understanding the training dynamics of Baichuan 2.
Efficient Generalization Improvement Guided by Random Weight Perturbation
Nov 21, 2022



To fully uncover the great potential of deep neural networks (DNNs), various learning algorithms have been developed to improve the model's generalization ability. Recently, sharpness-aware minimization (SAM) establishes a generic scheme for generalization improvements by minimizing the sharpness measure within a small neighborhood and achieves state-of-the-art performance. However, SAM requires two consecutive gradient evaluations for solving the min-max problem and inevitably doubles the training time. In this paper, we resort to filter-wise random weight perturbations (RWP) to decouple the nested gradients in SAM. Different from the small adversarial perturbations in SAM, RWP is softer and allows a much larger magnitude of perturbations. Specifically, we jointly optimize the loss function with random perturbations and the original loss function: the former guides the network towards a wider flat region while the latter helps recover the necessary local information. These two loss terms are complementary to each other and mutually independent. Hence, the corresponding gradients can be efficiently computed in parallel, enabling nearly the same training speed as regular training. As a result, we achieve very competitive performance on CIFAR and remarkably better performance on ImageNet (e.g. $\mathbf{ +1.1\%}$) compared with SAM, but always require half of the training time. The code is released at https://github.com/nblt/RWP.
On Multi-head Ensemble of Smoothed Classifiers for Certified Robustness
Nov 20, 2022



Randomized Smoothing (RS) is a promising technique for certified robustness, and recently in RS the ensemble of multiple deep neural networks (DNNs) has shown state-of-the-art performances. However, such an ensemble brings heavy computation burdens in both training and certification, and yet under-exploits individual DNNs and their mutual effects, as the communication between these classifiers is commonly ignored in optimization. In this work, starting from a single DNN, we augment the network with multiple heads, each of which pertains a classifier for the ensemble. A novel training strategy, namely Self-PAced Circular-TEaching (SPACTE), is proposed accordingly. SPACTE enables a circular communication flow among those augmented heads, i.e., each head teaches its neighbor with the self-paced learning using smoothed losses, which are specifically designed in relation to certified robustness. The deployed multi-head structure and the circular-teaching scheme of SPACTE jointly contribute to diversify and enhance the classifiers in augmented heads for ensemble, leading to even stronger certified robustness than ensembling multiple DNNs (effectiveness) at the cost of much less computational expenses (efficiency), verified by extensive experiments and discussions.
Online LiDAR-Camera Extrinsic Parameters Self-checking
Oct 19, 2022



With the development of neural networks and the increasing popularity of automatic driving, the calibration of the LiDAR and the camera has attracted more and more attention. This calibration task is multi-modal, where the rich color and texture information captured by the camera and the accurate three-dimensional spatial information from the LiDAR is incredibly significant for downstream tasks. Current research interests mainly focus on obtaining accurate calibration results through information fusion. However, they seldom analyze whether the calibrated results are correct or not, which could be of significant importance in real-world applications. For example, in large-scale production, the LiDARs and the cameras of each smart car have to get well-calibrated as the car leaves the production line, while in the rest of the car life period, the poses of the LiDARs and cameras should also get continually supervised to ensure the security. To this end, this paper proposes a self-checking algorithm to judge whether the extrinsic parameters are well-calibrated by introducing a binary classification network based on the fused information from the camera and the LiDAR. Moreover, since there is no such dataset for the task in this work, we further generate a new dataset branch from the KITTI dataset tailored for the task. Our experiments on the proposed dataset branch demonstrate the performance of our method. To the best of our knowledge, this is the first work to address the significance of continually checking the calibrated extrinsic parameters for autonomous driving. The code is open-sourced on the Github website at https://github.com/OpenCalib/LiDAR2camera_self-check.
Unifying Gradients to Improve Real-world Robustness for Deep Networks
Aug 12, 2022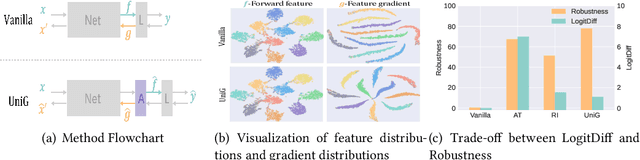
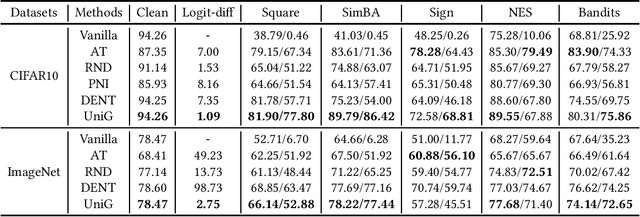
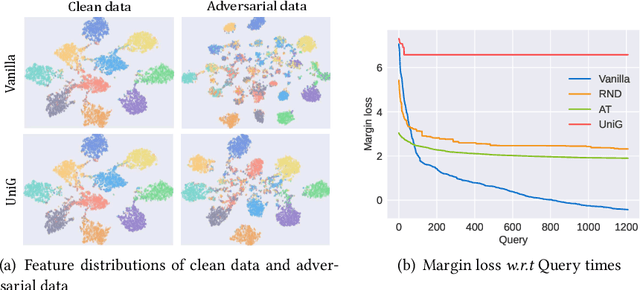

The wide application of deep neural networks (DNNs) demands an increasing amount of attention to their real-world robustness, i.e., whether a DNN resists black-box adversarial attacks, among them score-based query attacks (SQAs) are the most threatening ones because of their practicalities and effectiveness: the attackers only need dozens of queries on model outputs to seriously hurt a victim network. Defending against SQAs requires a slight but artful variation of outputs due to the service purpose for users, who share the same output information with attackers. In this paper, we propose a real-world defense, called Unifying Gradients (UniG), to unify gradients of different data so that attackers could only probe a much weaker attack direction that is similar for different samples. Since such universal attack perturbations have been validated as less aggressive than the input-specific perturbations, UniG protects real-world DNNs by indicating attackers a twisted and less informative attack direction. To enhance UniG's practical significance in real-world applications, we implement it as a Hadamard product module that is computationally-efficient and readily plugged into any model. According to extensive experiments on 5 SQAs and 4 defense baselines, UniG significantly improves real-world robustness without hurting clean accuracy on CIFAR10 and ImageNet. For instance, UniG maintains a CIFAR-10 model of 77.80% accuracy under 2500-query Square attack while the state-of-the-art adversarially-trained model only has 67.34% on CIFAR10. Simultaneously, UniG greatly surpasses all compared baselines in clean accuracy and the modification degree of outputs. The code would be released.
CROON: Automatic Multi-LiDAR Calibration and Refinement Method in Road Scene
Mar 07, 2022



Sensor-based environmental perception is a crucial part of the autonomous driving system. In order to get an excellent perception of the surrounding environment, an intelligent system would configure multiple LiDARs (3D Light Detection and Ranging) to cover the distant and near space of the car. The precision of perception relies on the quality of sensor calibration. This research aims at developing an accurate, automatic, and robust calibration strategy for multiple LiDAR systems in the general road scene. We thus propose CROON (automatiC multi-LiDAR CalibratiOn and Refinement method in rOad sceNe), a two-stage method including rough and refinement calibration. The first stage can calibrate the sensor from an arbitrary initial pose, and the second stage is able to precisely calibrate the sensor iteratively. Specifically, CROON utilize the nature characteristics of road scene so that it is independent and easy to apply in large-scale conditions. Experimental results on real-world and simulated data sets demonstrate the reliability and accuracy of our method. All the related data sets and codes are open-sourced on the Github website https://github.com/OpenCalib/LiDAR2LiDAR.