 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHaoze Sun
Low-Res Leads the Way: Improving Generalization for Super-Resolution by Self-Supervised Learning
Mar 05, 2024
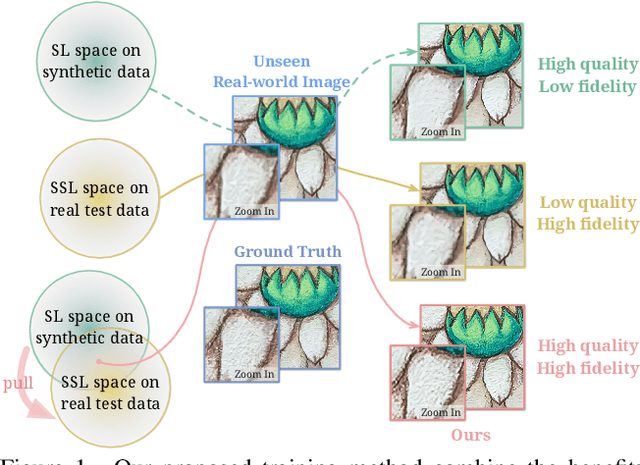
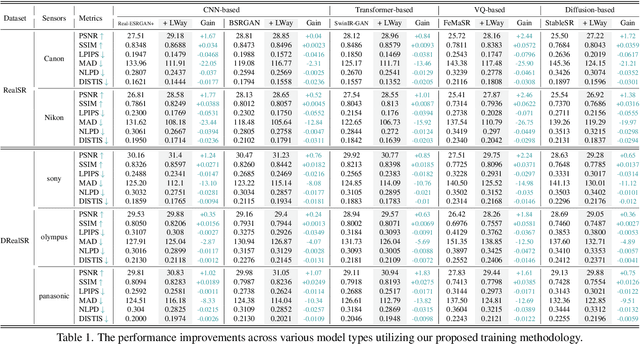
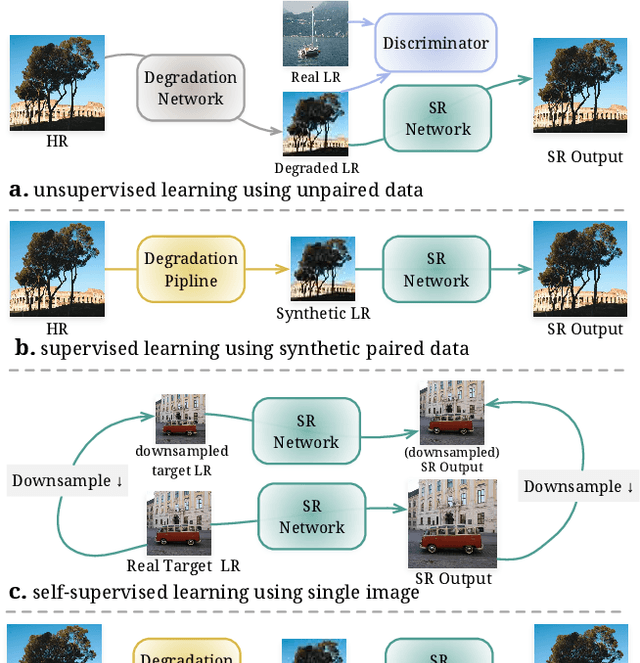

For image super-resolution (SR), bridging the gap between the performance on synthetic datasets and real-world degradation scenarios remains a challenge. This work introduces a novel "Low-Res Leads the Way" (LWay) training framework, merging Supervised Pre-training with Self-supervised Learning to enhance the adaptability of SR models to real-world images. Our approach utilizes a low-resolution (LR) reconstruction network to extract degradation embeddings from LR images, merging them with super-resolved outputs for LR reconstruction. Leveraging unseen LR images for self-supervised learning guides the model to adapt its modeling space to the target domain, facilitating fine-tuning of SR models without requiring paired high-resolution (HR) images. The integration of Discrete Wavelet Transform (DWT) further refines the focus on high-frequency details. Extensive evaluations show that our method significantly improves the generalization and detail restoration capabilities of SR models on unseen real-world datasets, outperforming existing methods. Our training regime is universally compatible, requiring no network architecture modifications, making it a practical solution for real-world SR applications.
CoSeR: Bridging Image and Language for Cognitive Super-Resolution
Dec 02, 2023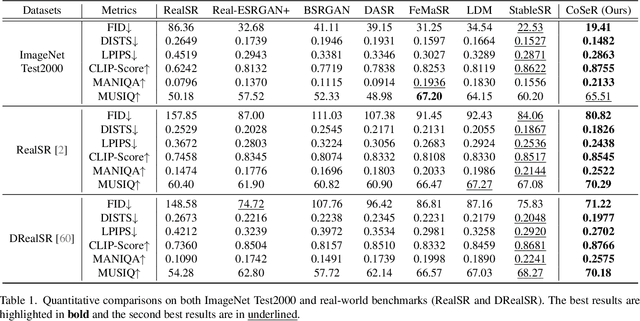
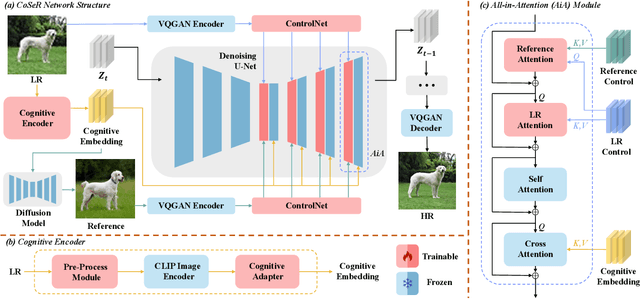

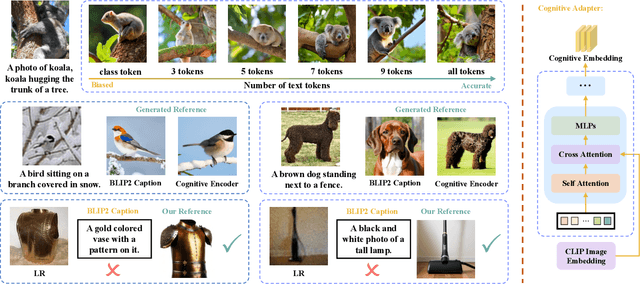
Existing super-resolution (SR) models primarily focus on restoring local texture details, often neglecting the global semantic information within the scene. This oversight can lead to the omission of crucial semantic details or the introduction of inaccurate textures during the recovery process. In our work, we introduce the Cognitive Super-Resolution (CoSeR) framework, empowering SR models with the capacity to comprehend low-resolution images. We achieve this by marrying image appearance and language understanding to generate a cognitive embedding, which not only activates prior information from large text-to-image diffusion models but also facilitates the generation of high-quality reference images to optimize the SR process. To further improve image fidelity, we propose a novel condition injection scheme called "All-in-Attention", consolidating all conditional information into a single module. Consequently, our method successfully restores semantically correct and photorealistic details, demonstrating state-of-the-art performance across multiple benchmarks. Code: https://github.com/VINHYU/CoSeR
Baichuan 2: Open Large-scale Language Models
Sep 20, 2023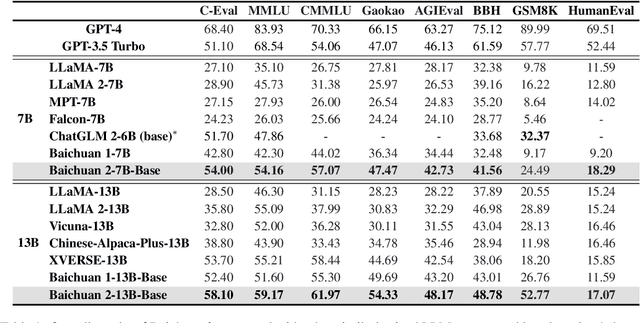
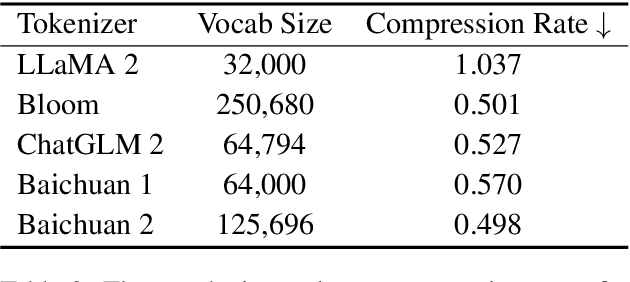
Large language models (LLMs) have demonstrated remarkable performance on a variety of natural language tasks based on just a few examples of natural language instructions, reducing the need for extensive feature engineering. However, most powerful LLMs are closed-source or limited in their capability for languages other than English. In this technical report, we present Baichuan 2, a series of large-scale multilingual language models containing 7 billion and 13 billion parameters, trained from scratch, on 2.6 trillion tokens. Baichuan 2 matches or outperforms other open-source models of similar size on public benchmarks like MMLU, CMMLU, GSM8K, and HumanEval. Furthermore, Baichuan 2 excels in vertical domains such as medicine and law. We will release all pre-training model checkpoints to benefit the research community in better understanding the training dynamics of Baichuan 2.
Accelerating Diffusion Models for Inverse Problems through Shortcut Sampling
May 26, 2023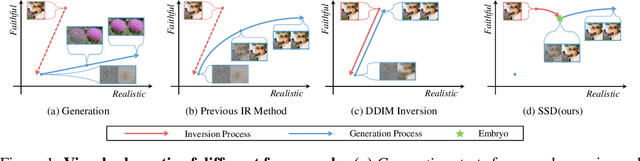
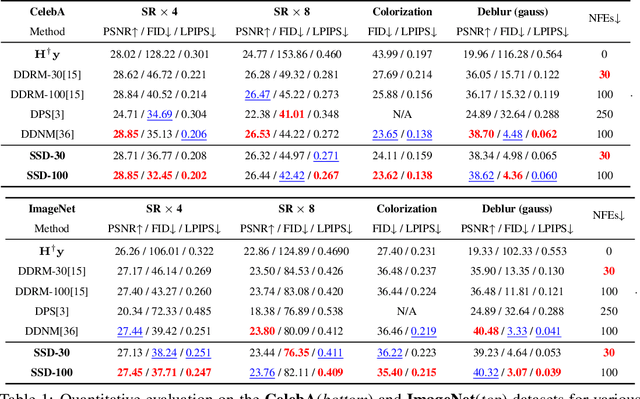
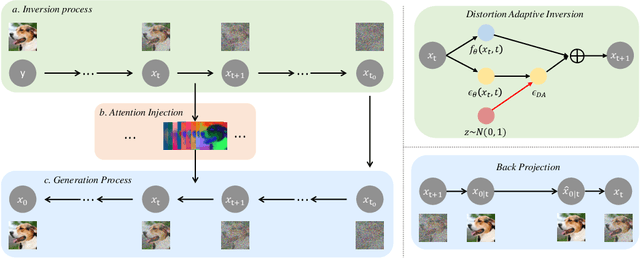

Recently, diffusion models have demonstrated a remarkable ability to solve inverse problems in an unsupervised manner. Existing methods mainly focus on modifying the posterior sampling process while neglecting the potential of the forward process. In this work, we propose Shortcut Sampling for Diffusion (SSD), a novel pipeline for solving inverse problems. Instead of initiating from random noise, the key concept of SSD is to find the "Embryo", a transitional state that bridges the measurement image y and the restored image x. By utilizing the "shortcut" path of "input-Embryo-output", SSD can achieve precise and fast restoration. To obtain the Embryo in the forward process, We propose Distortion Adaptive Inversion (DA Inversion). Moreover, we apply back projection and attention injection as additional consistency constraints during the generation process. Experimentally, we demonstrate the effectiveness of SSD on several representative tasks, including super-resolution, deblurring, and colorization. Compared to state-of-the-art zero-shot methods, our method achieves competitive results with only 30 NFEs. Moreover, SSD with 100 NFEs can outperform state-of-the-art zero-shot methods in certain tasks.
Sogou Machine Reading Comprehension Toolkit
Apr 01, 2019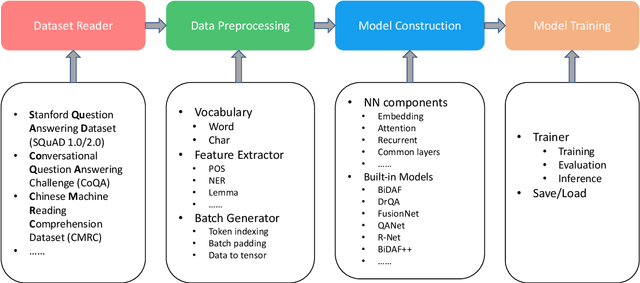
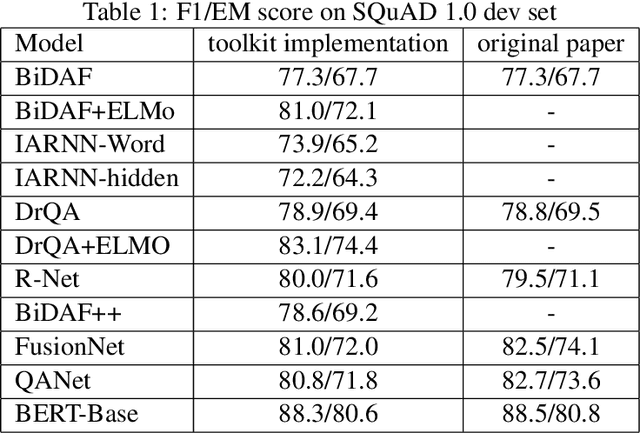
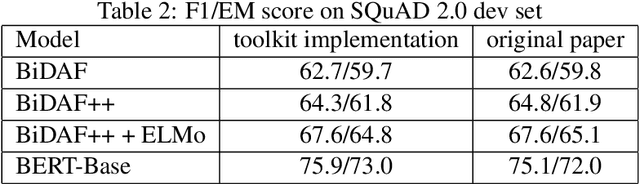
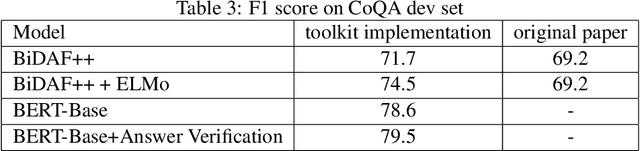
Machine reading comprehension have been intensively studied in recent years, and neural network-based models have shown dominant performances. In this paper, we present a Sogou Machine Reading Comprehension (SMRC) toolkit that can be used to provide the fast and efficient development of modern machine comprehension models, including both published models and original prototypes. To achieve this goal, the toolkit provides dataset readers, a flexible preprocessing pipeline, necessary neural network components, and built-in models, which make the whole process of data preparation, model construction, and training easier.
Variational Autoencoders for Semi-supervised Text Classification
Nov 24, 2016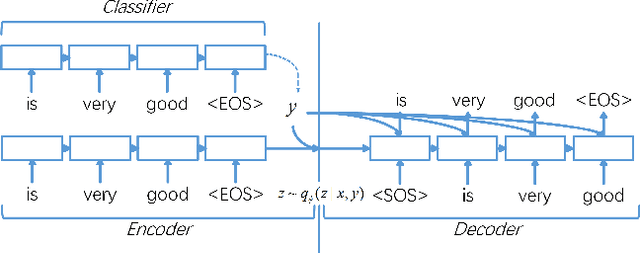
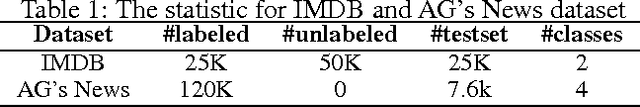
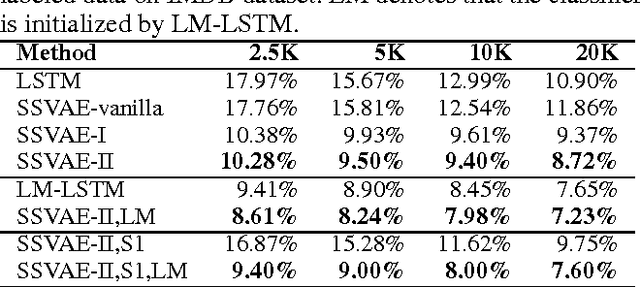
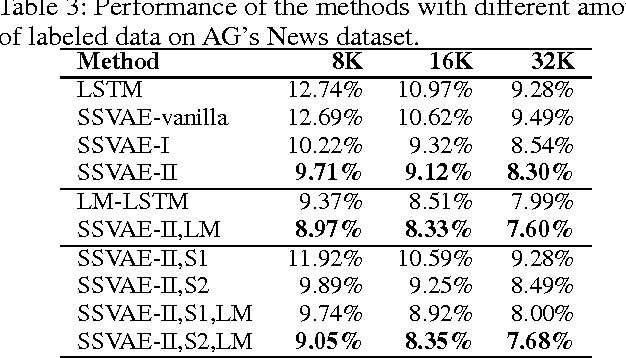
Although semi-supervised variational autoencoder (SemiVAE) works in image classification task, it fails in text classification task if using vanilla LSTM as its decoder. From a perspective of reinforcement learning, it is verified that the decoder's capability to distinguish between different categorical labels is essential. Therefore, Semi-supervised Sequential Variational Autoencoder (SSVAE) is proposed, which increases the capability by feeding label into its decoder RNN at each time-step. Two specific decoder structures are investigated and both of them are verified to be effective. Besides, in order to reduce the computational complexity in training, a novel optimization method is proposed, which estimates the gradient of the unlabeled objective function by sampling, along with two variance reduction techniques. Experimental results on Large Movie Review Dataset (IMDB) and AG's News corpus show that the proposed approach significantly improves the classification accuracy compared with pure-supervised classifiers, and achieves competitive performance against previous advanced methods. State-of-the-art results can be obtained by integrating other pretraining-based methods.