 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeipeng Chen
Clover: Regressive Lightweight Speculative Decoding with Sequential Knowledge
May 01, 2024
Large language models (LLMs) suffer from low efficiency as the mismatch between the requirement of auto-regressive decoding and the design of most contemporary GPUs. Specifically, billions to trillions of parameters must be loaded to the GPU cache through its limited memory bandwidth for computation, but only a small batch of tokens is actually computed. Consequently, the GPU spends most of its time on memory transfer instead of computation. Recently, parallel decoding, a type of speculative decoding algorithms, is becoming more popular and has demonstrated impressive efficiency improvement in generation. It introduces extra decoding heads to large models, enabling them to predict multiple subsequent tokens simultaneously and verify these candidate continuations in a single decoding step. However, this approach deviates from the training objective of next token prediction used during pre-training, resulting in a low hit rate for candidate tokens. In this paper, we propose a new speculative decoding algorithm, Clover, which integrates sequential knowledge into the parallel decoding process. This enhancement improves the hit rate of speculators and thus boosts the overall efficiency. Clover transmits the sequential knowledge from pre-speculated tokens via the Regressive Connection, then employs an Attention Decoder to integrate these speculated tokens. Additionally, Clover incorporates an Augmenting Block that modifies the hidden states to better align with the purpose of speculative generation rather than next token prediction. The experiment results demonstrate that Clover outperforms the baseline by up to 91% on Baichuan-Small and 146% on Baichuan-Large, respectively, and exceeds the performance of the previously top-performing method, Medusa, by up to 37% on Baichuan-Small and 57% on Baichuan-Large, respectively.
Checkpoint Merging via Bayesian Optimization in LLM Pretraining
Mar 28, 2024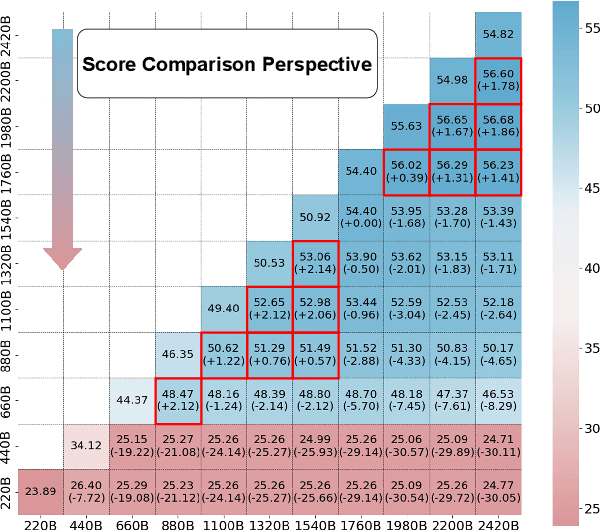
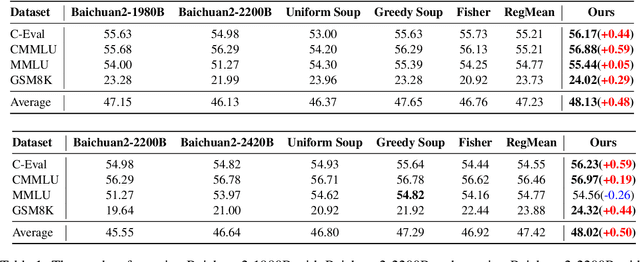
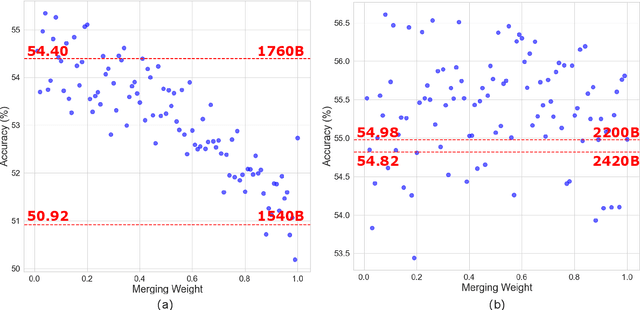
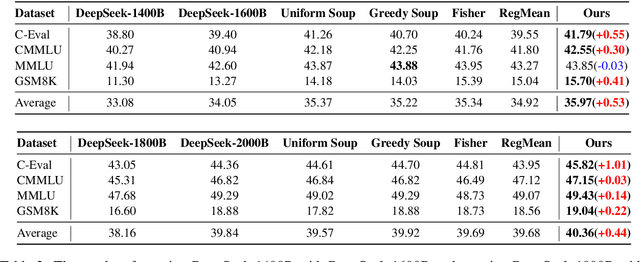
The rapid proliferation of large language models (LLMs) such as GPT-4 and Gemini underscores the intense demand for resources during their training processes, posing significant challenges due to substantial computational and environmental costs. To alleviate this issue, we propose checkpoint merging in pretraining LLM. This method utilizes LLM checkpoints with shared training trajectories, and is rooted in an extensive search space exploration for the best merging weight via Bayesian optimization. Through various experiments, we demonstrate that: (1) Our proposed methodology exhibits the capacity to augment pretraining, presenting an opportunity akin to obtaining substantial benefits at minimal cost; (2) Our proposed methodology, despite requiring a given held-out dataset, still demonstrates robust generalization capabilities across diverse domains, a pivotal aspect in pretraining.
ShortGPT: Layers in Large Language Models are More Redundant Than You Expect
Mar 07, 2024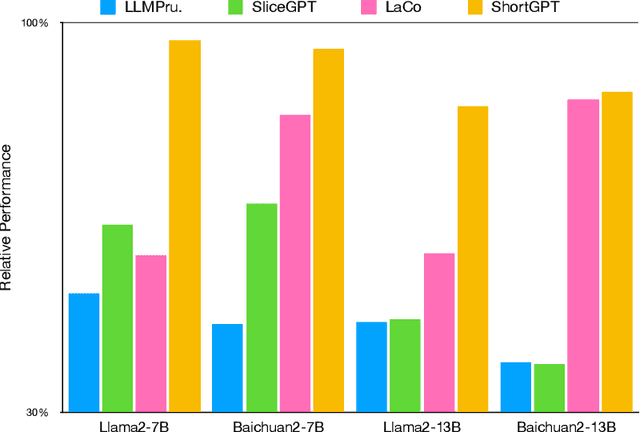
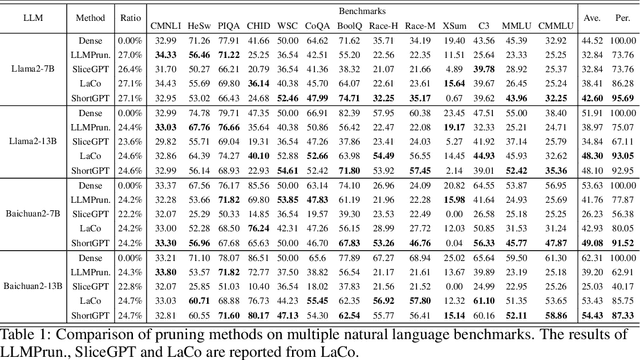
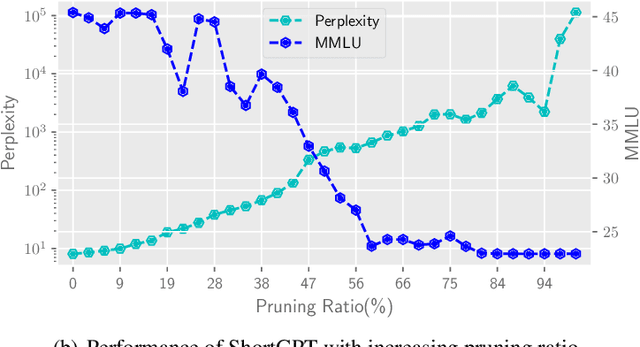
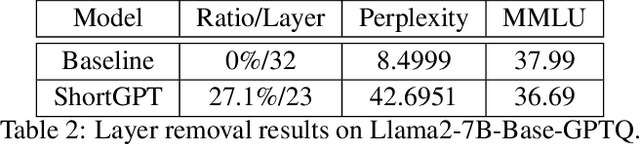
As Large Language Models (LLMs) continue to advance in performance, their size has escalated significantly, with current LLMs containing billions or even trillions of parameters. However, in this study, we discovered that many layers of LLMs exhibit high similarity, and some layers play a negligible role in network functionality. Based on this observation, we define a metric called Block Influence (BI) to gauge the significance of each layer in LLMs. We then propose a straightforward pruning approach: layer removal, in which we directly delete the redundant layers in LLMs based on their BI scores. Experiments demonstrate that our method, which we call ShortGPT, significantly outperforms previous state-of-the-art (SOTA) methods in model pruning. Moreover, ShortGPT is orthogonal to quantization-like methods, enabling further reduction in parameters and computation. The ability to achieve better results through simple layer removal, as opposed to more complex pruning techniques, suggests a high degree of redundancy in the model architecture.
Baichuan 2: Open Large-scale Language Models
Sep 20, 2023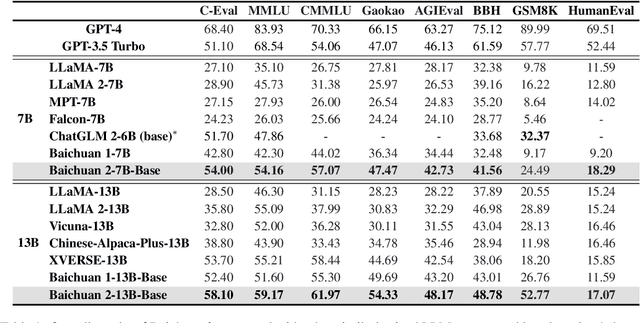
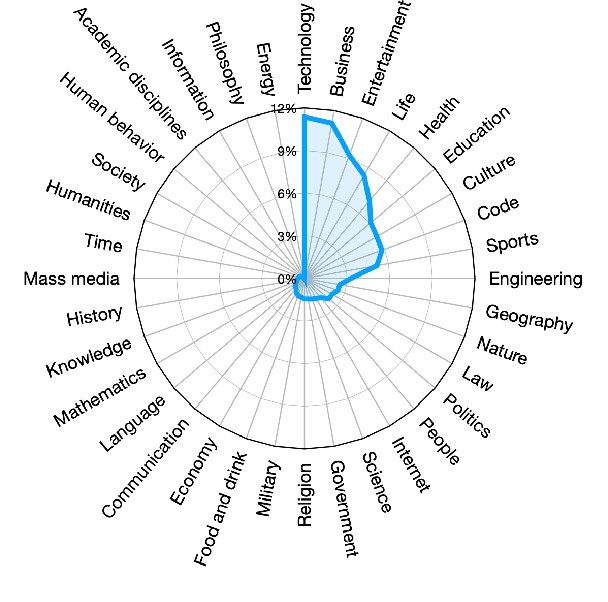
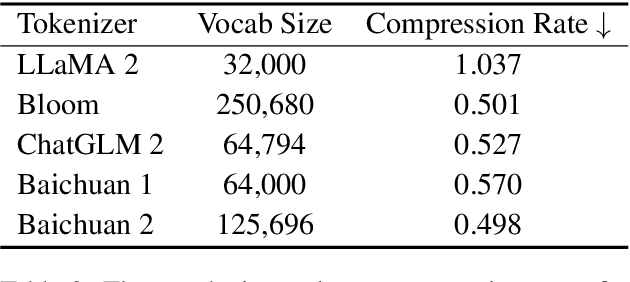
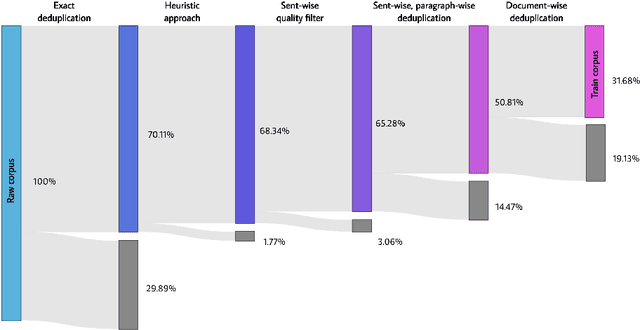
Large language models (LLMs) have demonstrated remarkable performance on a variety of natural language tasks based on just a few examples of natural language instructions, reducing the need for extensive feature engineering. However, most powerful LLMs are closed-source or limited in their capability for languages other than English. In this technical report, we present Baichuan 2, a series of large-scale multilingual language models containing 7 billion and 13 billion parameters, trained from scratch, on 2.6 trillion tokens. Baichuan 2 matches or outperforms other open-source models of similar size on public benchmarks like MMLU, CMMLU, GSM8K, and HumanEval. Furthermore, Baichuan 2 excels in vertical domains such as medicine and law. We will release all pre-training model checkpoints to benefit the research community in better understanding the training dynamics of Baichuan 2.
ComQA:Compositional Question Answering via Hierarchical Graph Neural Networks
Jan 16, 2021

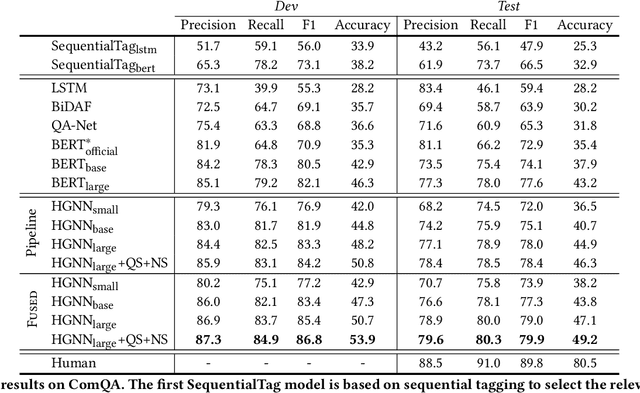
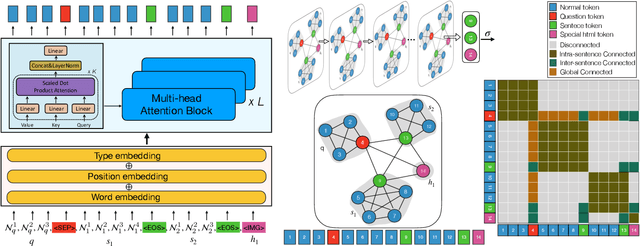
With the development of deep learning techniques and large scale datasets, the question answering (QA) systems have been quickly improved, providing more accurate and satisfying answers. However, current QA systems either focus on the sentence-level answer, i.e., answer selection, or phrase-level answer, i.e., machine reading comprehension. How to produce compositional answers has not been throughout investigated. In compositional question answering, the systems should assemble several supporting evidence from the document to generate the final answer, which is more difficult than sentence-level or phrase-level QA. In this paper, we present a large-scale compositional question answering dataset containing more than 120k human-labeled questions. The answer in this dataset is composed of discontiguous sentences in the corresponding document. To tackle the ComQA problem, we proposed a hierarchical graph neural networks, which represents the document from the low-level word to the high-level sentence. We also devise a question selection and node selection task for pre-training. Our proposed model achieves a significant improvement over previous machine reading comprehension methods and pre-training methods. Codes and dataset can be found at \url{https://github.com/benywon/ComQA}.