 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYujie Feng
Towards LLM-driven Dialogue State Tracking
Oct 23, 2023
Dialogue State Tracking (DST) is of paramount importance in ensuring accurate tracking of user goals and system actions within task-oriented dialogue systems. The emergence of large language models (LLMs) such as GPT3 and ChatGPT has sparked considerable interest in assessing their efficacy across diverse applications. In this study, we conduct an initial examination of ChatGPT's capabilities in DST. Our evaluation uncovers the exceptional performance of ChatGPT in this task, offering valuable insights to researchers regarding its capabilities and providing useful directions for designing and enhancing dialogue systems. Despite its impressive performance, ChatGPT has significant limitations including its closed-source nature, request restrictions, raising data privacy concerns, and lacking local deployment capabilities. To address these concerns, we present LDST, an LLM-driven DST framework based on smaller, open-source foundation models. By utilizing a novel domain-slot instruction tuning method, LDST achieves performance on par with ChatGPT. Comprehensive evaluations across three distinct experimental settings, we find that LDST exhibits remarkable performance improvements in both zero-shot and few-shot setting compared to previous SOTA methods. The source code is provided for reproducibility.
A Multi-scale Generalized Shrinkage Threshold Network for Image Blind Deblurring in Remote Sensing
Sep 14, 2023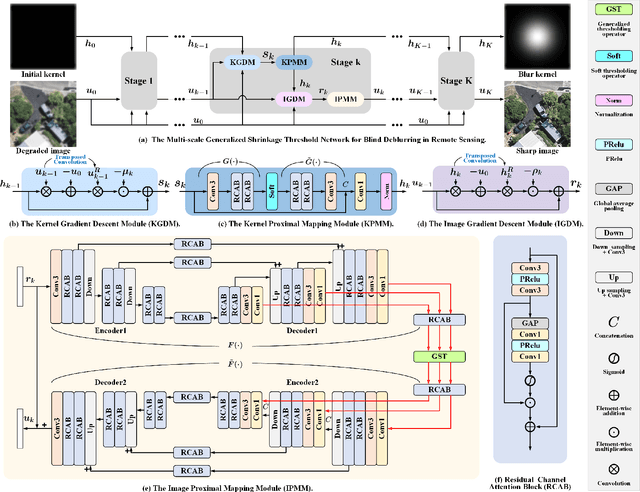
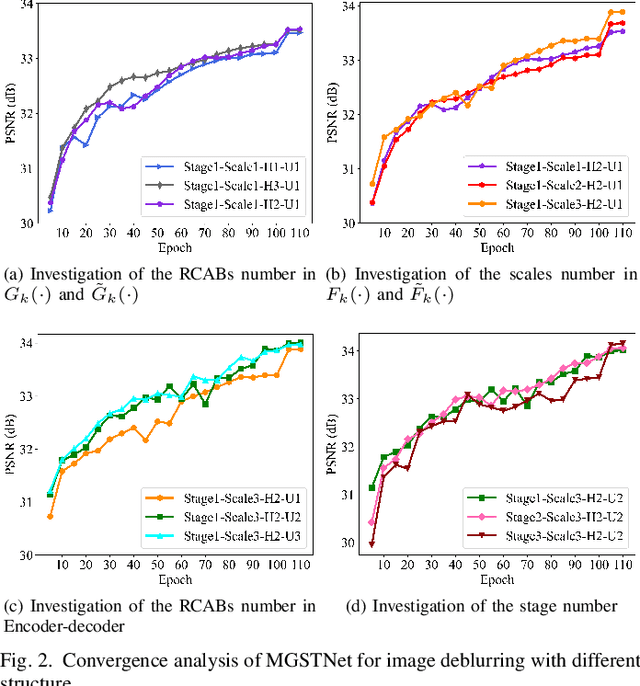


Remote sensing images are essential for many earth science applications, but their quality can be degraded due to limitations in sensor technology and complex imaging environments. To address this, various remote sensing image deblurring methods have been developed to restore sharp, high-quality images from degraded observational data. However, most traditional model-based deblurring methods usually require predefined hand-craft prior assumptions, which are difficult to handle in complex applications, and most deep learning-based deblurring methods are designed as a black box, lacking transparency and interpretability. In this work, we propose a novel blind deblurring learning framework based on alternating iterations of shrinkage thresholds, alternately updating blurring kernels and images, with the theoretical foundation of network design. Additionally, we propose a learnable blur kernel proximal mapping module to improve the blur kernel evaluation in the kernel domain. Then, we proposed a deep proximal mapping module in the image domain, which combines a generalized shrinkage threshold operator and a multi-scale prior feature extraction block. This module also introduces an attention mechanism to adaptively adjust the prior importance, thus avoiding the drawbacks of hand-crafted image prior terms. Thus, a novel multi-scale generalized shrinkage threshold network (MGSTNet) is designed to specifically focus on learning deep geometric prior features to enhance image restoration. Experiments demonstrate the superiority of our MGSTNet framework on remote sensing image datasets compared to existing deblurring methods.
How Good Are Large Language Models at Out-of-Distribution Detection?
Aug 23, 2023



Out-of-distribution (OOD) detection plays a vital role in enhancing the reliability of machine learning (ML) models. The emergence of large language models (LLMs) has catalyzed a paradigm shift within the ML community, showcasing their exceptional capabilities across diverse natural language processing tasks. While existing research has probed OOD detection with relative small-scale Transformers like BERT, RoBERTa and GPT-2, the stark differences in scales, pre-training objectives, and inference paradigms call into question the applicability of these findings to LLMs. This paper embarks on a pioneering empirical investigation of OOD detection in the domain of LLMs, focusing on LLaMA series ranging from 7B to 65B in size. We thoroughly evaluate commonly-used OOD detectors, scrutinizing their performance in both zero-grad and fine-tuning scenarios. Notably, we alter previous discriminative in-distribution fine-tuning into generative fine-tuning, aligning the pre-training objective of LLMs with downstream tasks. Our findings unveil that a simple cosine distance OOD detector demonstrates superior efficacy, outperforming other OOD detectors. We provide an intriguing explanation for this phenomenon by highlighting the isotropic nature of the embedding spaces of LLMs, which distinctly contrasts with the anisotropic property observed in smaller BERT family models. The new insight enhances our understanding of how LLMs detect OOD data, thereby enhancing their adaptability and reliability in dynamic environments.
Nest-DGIL: Nesterov-optimized Deep Geometric Incremental Learning for CS Image Reconstruction
Aug 06, 2023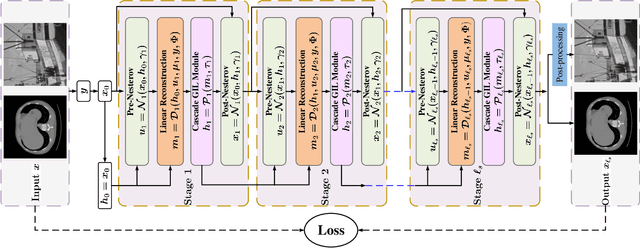
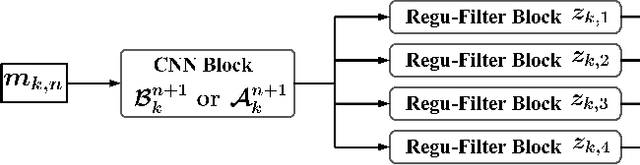
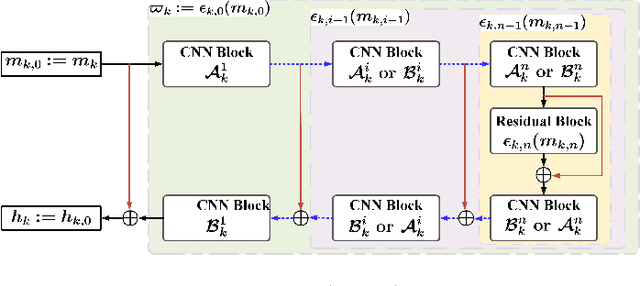
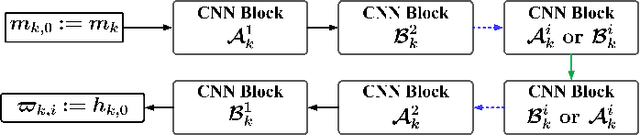
Proximal gradient-based optimization is one of the most common strategies for solving image inverse problems as well as easy to implement. However, these techniques often generate heavy artifacts in image reconstruction. One of the most popular refinement methods is to fine-tune the regularization parameter to alleviate such artifacts, but it may not always be sufficient or applicable due to increased computational costs. In this work, we propose a deep geometric incremental learning framework based on second Nesterov proximal gradient optimization. The proposed end-to-end network not only has the powerful learning ability for high/low frequency image features,but also can theoretically guarantee that geometric texture details will be reconstructed from preliminary linear reconstruction.Furthermore, it can avoid the risk of intermediate reconstruction results falling outside the geometric decomposition domains and achieve fast convergence. Our reconstruction framework is decomposed into four modules including general linear reconstruction, cascade geometric incremental restoration, Nesterov acceleration and post-processing. In the image restoration step,a cascade geometric incremental learning module is designed to compensate for the missing texture information from different geometric spectral decomposition domains. Inspired by overlap-tile strategy, we also develop a post-processing module to remove the block-effect in patch-wise-based natural image reconstruction. All parameters in the proposed model are learnable,an adaptive initialization technique of physical-parameters is also employed to make model flexibility and ensure converging smoothly. We compare the reconstruction performance of the proposed method with existing state-of-the-art methods to demonstrate its superiority. Our source codes are available at https://github.com/fanxiaohong/Nest-DGIL.