 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTangjie Lv
Let Storytelling Tell Vivid Stories: An Expressive and Fluent Multimodal Storyteller
Mar 12, 2024
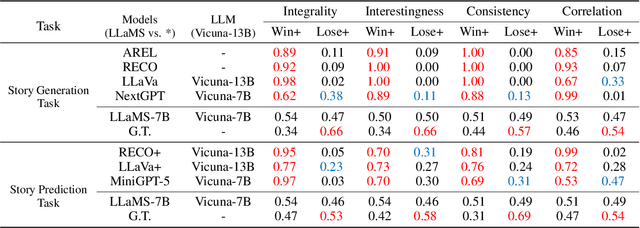
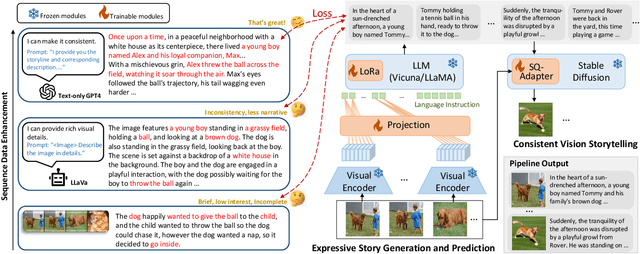
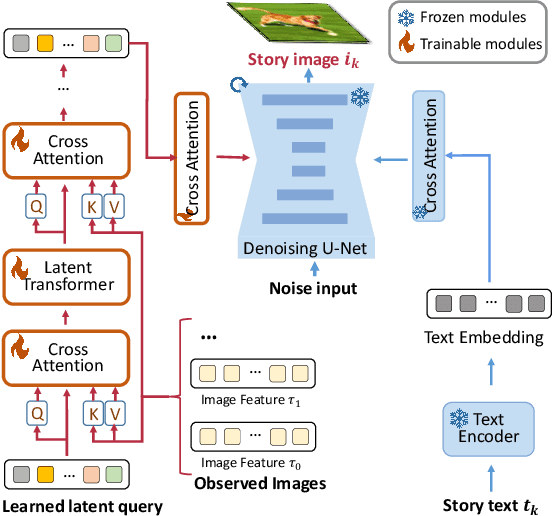
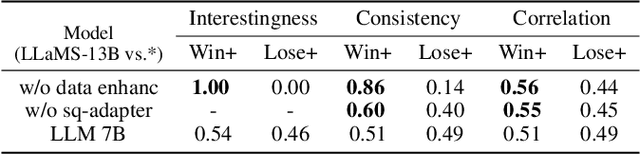
Storytelling aims to generate reasonable and vivid narratives based on an ordered image stream. The fidelity to the image story theme and the divergence of story plots attract readers to keep reading. Previous works iteratively improved the alignment of multiple modalities but ultimately resulted in the generation of simplistic storylines for image streams. In this work, we propose a new pipeline, termed LLaMS, to generate multimodal human-level stories that are embodied in expressiveness and consistency. Specifically, by fully exploiting the commonsense knowledge within the LLM, we first employ a sequence data auto-enhancement strategy to enhance factual content expression and leverage a textual reasoning architecture for expressive story generation and prediction. Secondly, we propose SQ-Adatpter module for story illustration generation which can maintain sequence consistency. Numerical results are conducted through human evaluation to verify the superiority of proposed LLaMS. Evaluations show that LLaMS achieves state-of-the-art storytelling performance and 86% correlation and 100% consistency win rate as compared with previous SOTA methods. Furthermore, ablation experiments are conducted to verify the effectiveness of proposed sequence data enhancement and SQ-Adapter.
A Dataset for the Validation of Truth Inference Algorithms Suitable for Online Deployment
Mar 10, 2024
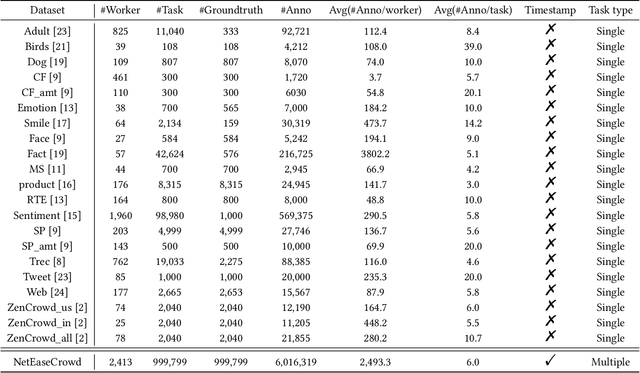
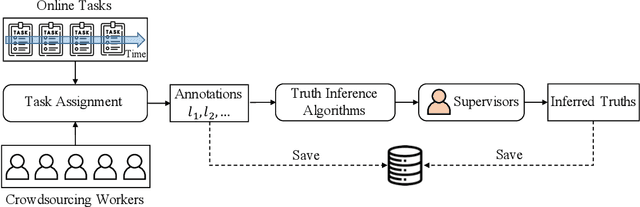
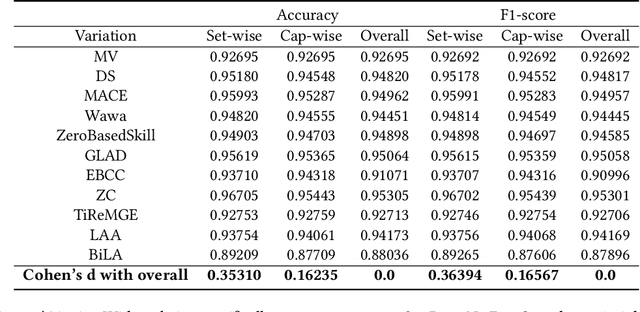
For the purpose of efficient and cost-effective large-scale data labeling, crowdsourcing is increasingly being utilized. To guarantee the quality of data labeling, multiple annotations need to be collected for each data sample, and truth inference algorithms have been developed to accurately infer the true labels. Despite previous studies having released public datasets to evaluate the efficacy of truth inference algorithms, these have typically focused on a single type of crowdsourcing task and neglected the temporal information associated with workers' annotation activities. These limitations significantly restrict the practical applicability of these algorithms, particularly in the context of long-term and online truth inference. In this paper, we introduce a substantial crowdsourcing annotation dataset collected from a real-world crowdsourcing platform. This dataset comprises approximately two thousand workers, one million tasks, and six million annotations. The data was gathered over a period of approximately six months from various types of tasks, and the timestamps of each annotation were preserved. We analyze the characteristics of the dataset from multiple perspectives and evaluate the effectiveness of several representative truth inference algorithms on this dataset. We anticipate that this dataset will stimulate future research on tracking workers' abilities over time in relation to different types of tasks, as well as enhancing online truth inference.
Crafting a Good Prompt or Providing Exemplary Dialogues? A Study of In-Context Learning for Persona-based Dialogue Generation
Feb 17, 2024Previous in-context learning (ICL) research has focused on tasks such as classification, machine translation, text2table, etc., while studies on whether ICL can improve human-like dialogue generation are scarce. Our work fills this gap by systematically investigating the ICL capabilities of large language models (LLMs) in persona-based dialogue generation, conducting extensive experiments on high-quality real human Chinese dialogue datasets. From experimental results, we draw three conclusions: 1) adjusting prompt instructions is the most direct, effective, and economical way to improve generation quality; 2) randomly retrieving demonstrations (demos) achieves the best results, possibly due to the greater diversity and the amount of effective information; counter-intuitively, retrieving demos with a context identical to the query performs the worst; 3) even when we destroy the multi-turn associations and single-turn semantics in the demos, increasing the number of demos still improves dialogue performance, proving that LLMs can learn from corrupted dialogue demos. Previous explanations of the ICL mechanism, such as $n$-gram induction head, cannot fully account for this phenomenon.
Towards a Simultaneous and Granular Identity-Expression Control in Personalized Face Generation
Jan 02, 2024In human-centric content generation, the pre-trained text-to-image models struggle to produce user-wanted portrait images, which retain the identity of individuals while exhibiting diverse expressions. This paper introduces our efforts towards personalized face generation. To this end, we propose a novel multi-modal face generation framework, capable of simultaneous identity-expression control and more fine-grained expression synthesis. Our expression control is so sophisticated that it can be specialized by the fine-grained emotional vocabulary. We devise a novel diffusion model that can undertake the task of simultaneously face swapping and reenactment. Due to the entanglement of identity and expression, it's nontrivial to separately and precisely control them in one framework, thus has not been explored yet. To overcome this, we propose several innovative designs in the conditional diffusion model, including balancing identity and expression encoder, improved midpoint sampling, and explicitly background conditioning. Extensive experiments have demonstrated the controllability and scalability of the proposed framework, in comparison with state-of-the-art text-to-image, face swapping, and face reenactment methods.
Towards Long-term Annotators: A Supervised Label Aggregation Baseline
Nov 15, 2023
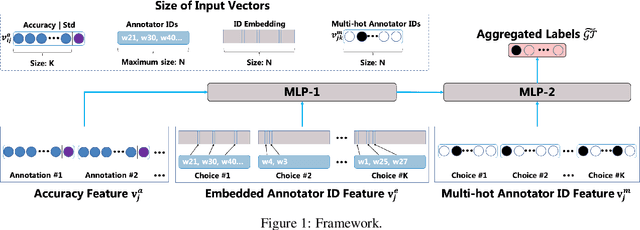
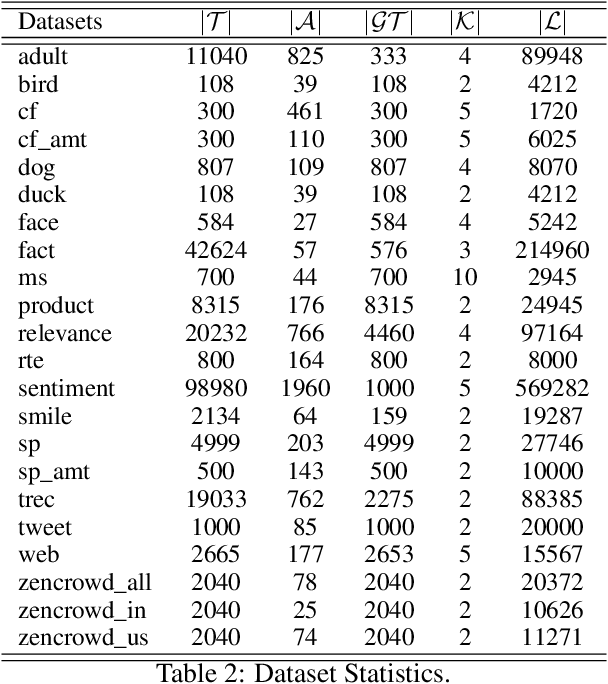
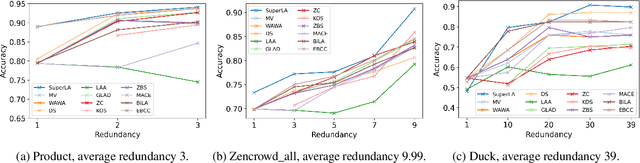
Relying on crowdsourced workers, data crowdsourcing platforms are able to efficiently provide vast amounts of labeled data. Due to the variability in the annotation quality of crowd workers, modern techniques resort to redundant annotations and subsequent label aggregation to infer true labels. However, these methods require model updating during the inference, posing challenges in real-world implementation. Meanwhile, in recent years, many data labeling tasks have begun to require skilled and experienced annotators, leading to an increasing demand for long-term annotators. These annotators could leave substantial historical annotation records on the crowdsourcing platforms, which can benefit label aggregation, but are ignored by previous works. Hereby, in this paper, we propose a novel label aggregation technique, which does not need any model updating during inference and can extensively explore the historical annotation records. We call it SuperLA, a Supervised Label Aggregation method. Inside this model, we design three types of input features and a straightforward neural network structure to merge all the information together and subsequently produce aggregated labels. Based on comparison experiments conducted on 22 public datasets and 11 baseline methods, we find that SuperLA not only outperforms all those baselines in inference performance but also offers significant advantages in terms of efficiency.
AlignDiff: Aligning Diverse Human Preferences via Behavior-Customisable Diffusion Model
Oct 03, 2023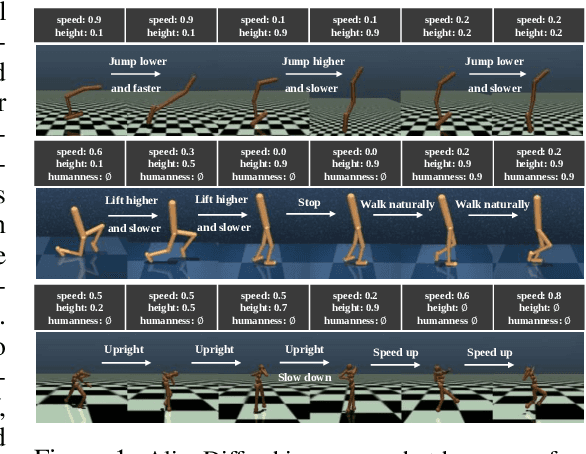
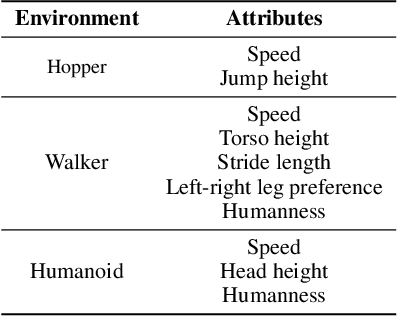
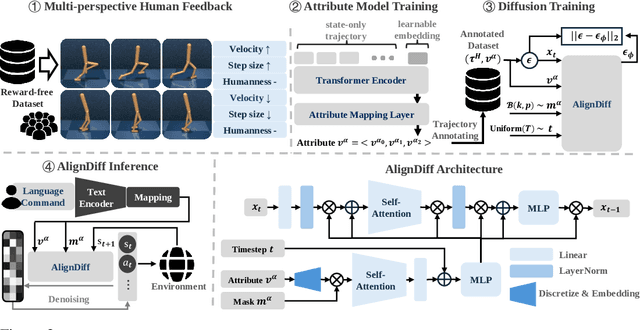
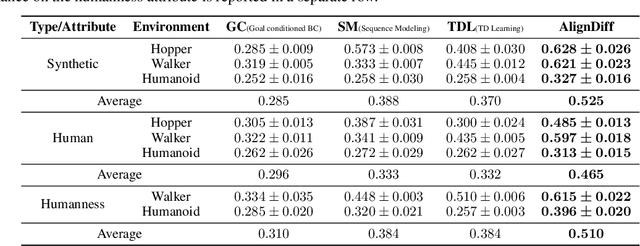
Aligning agent behaviors with diverse human preferences remains a challenging problem in reinforcement learning (RL), owing to the inherent abstractness and mutability of human preferences. To address these issues, we propose AlignDiff, a novel framework that leverages RL from Human Feedback (RLHF) to quantify human preferences, covering abstractness, and utilizes them to guide diffusion planning for zero-shot behavior customizing, covering mutability. AlignDiff can accurately match user-customized behaviors and efficiently switch from one to another. To build the framework, we first establish the multi-perspective human feedback datasets, which contain comparisons for the attributes of diverse behaviors, and then train an attribute strength model to predict quantified relative strengths. After relabeling behavioral datasets with relative strengths, we proceed to train an attribute-conditioned diffusion model, which serves as a planner with the attribute strength model as a director for preference aligning at the inference phase. We evaluate AlignDiff on various locomotion tasks and demonstrate its superior performance on preference matching, switching, and covering compared to other baselines. Its capability of completing unseen downstream tasks under human instructions also showcases the promising potential for human-AI collaboration. More visualization videos are released on https://aligndiff.github.io/.
Examining the Effect of Pre-training on Time Series Classification
Sep 11, 2023
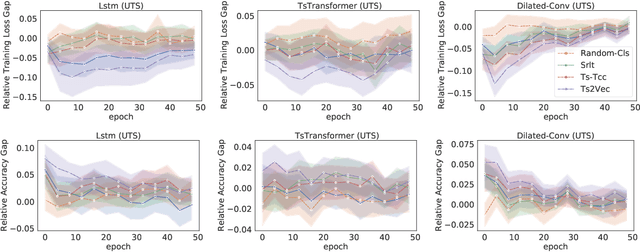
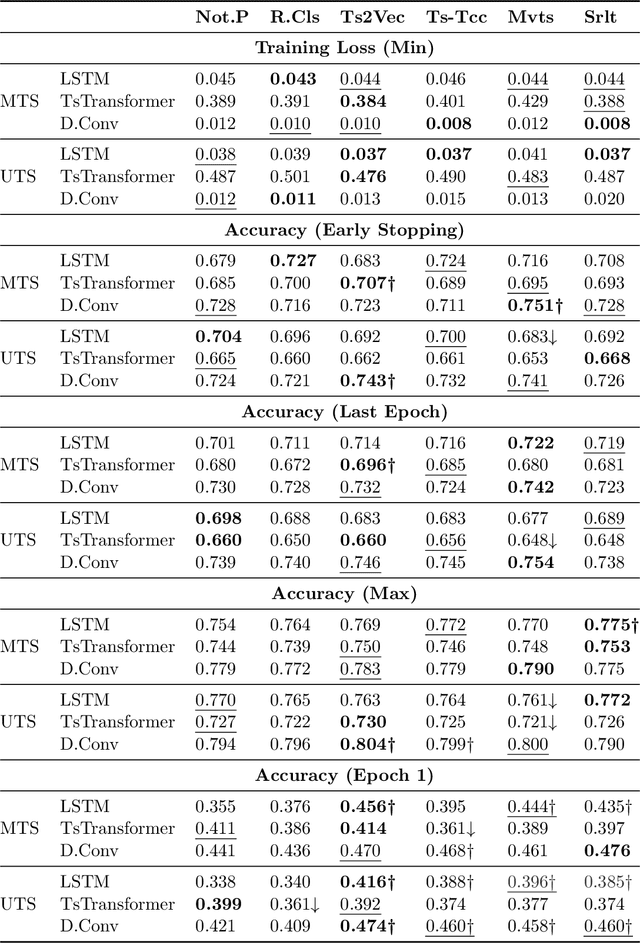
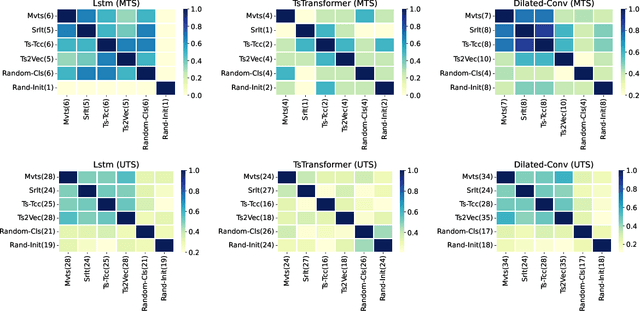
Although the pre-training followed by fine-tuning paradigm is used extensively in many fields, there is still some controversy surrounding the impact of pre-training on the fine-tuning process. Currently, experimental findings based on text and image data lack consensus. To delve deeper into the unsupervised pre-training followed by fine-tuning paradigm, we have extended previous research to a new modality: time series. In this study, we conducted a thorough examination of 150 classification datasets derived from the Univariate Time Series (UTS) and Multivariate Time Series (MTS) benchmarks. Our analysis reveals several key conclusions. (i) Pre-training can only help improve the optimization process for models that fit the data poorly, rather than those that fit the data well. (ii) Pre-training does not exhibit the effect of regularization when given sufficient training time. (iii) Pre-training can only speed up convergence if the model has sufficient ability to fit the data. (iv) Adding more pre-training data does not improve generalization, but it can strengthen the advantage of pre-training on the original data volume, such as faster convergence. (v) While both the pre-training task and the model structure determine the effectiveness of the paradigm on a given dataset, the model structure plays a more significant role.
Beyond First Impressions: Integrating Joint Multi-modal Cues for Comprehensive 3D Representation
Aug 06, 2023



In recent years, 3D representation learning has turned to 2D vision-language pre-trained models to overcome data scarcity challenges. However, existing methods simply transfer 2D alignment strategies, aligning 3D representations with single-view 2D images and coarse-grained parent category text. These approaches introduce information degradation and insufficient synergy issues, leading to performance loss. Information degradation arises from overlooking the fact that a 3D representation should be equivalent to a series of multi-view images and more fine-grained subcategory text. Insufficient synergy neglects the idea that a robust 3D representation should align with the joint vision-language space, rather than independently aligning with each modality. In this paper, we propose a multi-view joint modality modeling approach, termed JM3D, to obtain a unified representation for point cloud, text, and image. Specifically, a novel Structured Multimodal Organizer (SMO) is proposed to address the information degradation issue, which introduces contiguous multi-view images and hierarchical text to enrich the representation of vision and language modalities. A Joint Multi-modal Alignment (JMA) is designed to tackle the insufficient synergy problem, which models the joint modality by incorporating language knowledge into the visual modality. Extensive experiments on ModelNet40 and ScanObjectNN demonstrate the effectiveness of our proposed method, JM3D, which achieves state-of-the-art performance in zero-shot 3D classification. JM3D outperforms ULIP by approximately 4.3% on PointMLP and achieves an improvement of up to 6.5% accuracy on PointNet++ in top-1 accuracy for zero-shot 3D classification on ModelNet40. The source code and trained models for all our experiments are publicly available at https://github.com/Mr-Neko/JM3D.
Rethinking Noisy Label Learning in Real-world Annotation Scenarios from the Noise-type Perspective
Jul 28, 2023
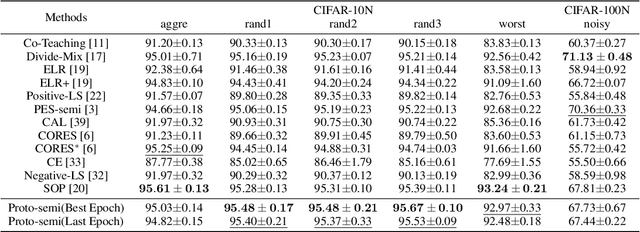
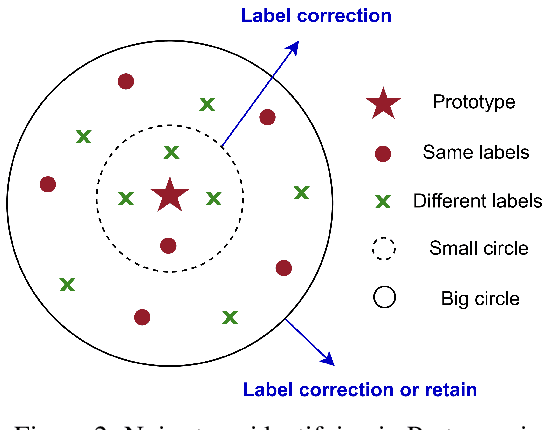
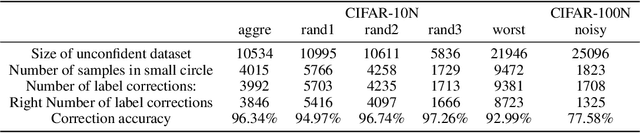
We investigate the problem of learning with noisy labels in real-world annotation scenarios, where noise can be categorized into two types: factual noise and ambiguity noise. To better distinguish these noise types and utilize their semantics, we propose a novel sample selection-based approach for noisy label learning, called Proto-semi. Proto-semi initially divides all samples into the confident and unconfident datasets via warm-up. By leveraging the confident dataset, prototype vectors are constructed to capture class characteristics. Subsequently, the distances between the unconfident samples and the prototype vectors are calculated to facilitate noise classification. Based on these distances, the labels are either corrected or retained, resulting in the refinement of the confident and unconfident datasets. Finally, we introduce a semi-supervised learning method to enhance training. Empirical evaluations on a real-world annotated dataset substantiate the robustness of Proto-semi in handling the problem of learning from noisy labels. Meanwhile, the prototype-based repartitioning strategy is shown to be effective in mitigating the adverse impact of label noise. Our code and data are available at https://github.com/fuxiAIlab/ProtoSemi.
Prioritized Trajectory Replay: A Replay Memory for Data-driven Reinforcement Learning
Jun 27, 2023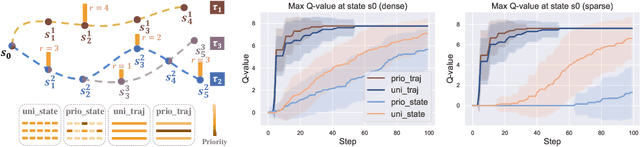
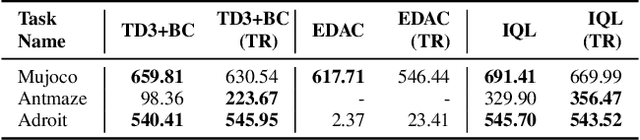
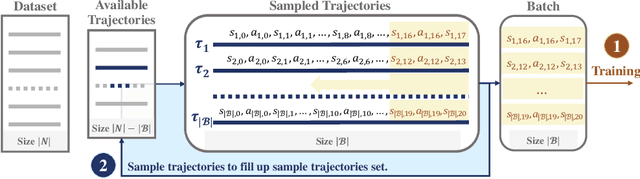
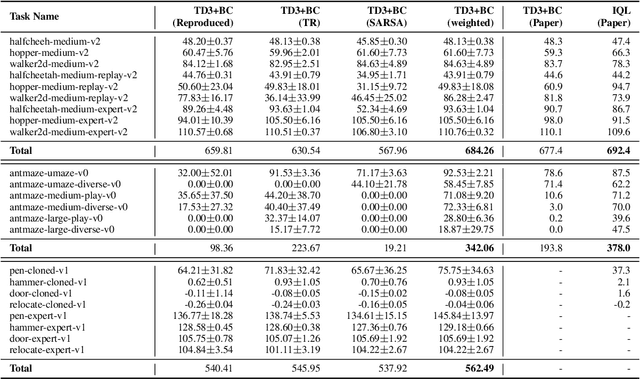
In recent years, data-driven reinforcement learning (RL), also known as offline RL, have gained significant attention. However, the role of data sampling techniques in offline RL has been overlooked despite its potential to enhance online RL performance. Recent research suggests applying sampling techniques directly to state-transitions does not consistently improve performance in offline RL. Therefore, in this study, we propose a memory technique, (Prioritized) Trajectory Replay (TR/PTR), which extends the sampling perspective to trajectories for more comprehensive information extraction from limited data. TR enhances learning efficiency by backward sampling of trajectories that optimizes the use of subsequent state information. Building on TR, we build the weighted critic target to avoid sampling unseen actions in offline training, and Prioritized Trajectory Replay (PTR) that enables more efficient trajectory sampling, prioritized by various trajectory priority metrics. We demonstrate the benefits of integrating TR and PTR with existing offline RL algorithms on D4RL. In summary, our research emphasizes the significance of trajectory-based data sampling techniques in enhancing the efficiency and performance of offline RL algorithms.