 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLiyuan Wang
Transitive Vision-Language Prompt Learning for Domain Generalization
Apr 29, 2024
The vision-language pre-training has enabled deep models to make a huge step forward in generalizing across unseen domains. The recent learning method based on the vision-language pre-training model is a great tool for domain generalization and can solve this problem to a large extent. However, there are still some issues that an advancement still suffers from trading-off between domain invariance and class separability, which are crucial in current DG problems. However, there are still some issues that an advancement still suffers from trading-off between domain invariance and class separability, which are crucial in current DG problems. In this paper, we introduce a novel prompt learning strategy that leverages deep vision prompts to address domain invariance while utilizing language prompts to ensure class separability, coupled with adaptive weighting mechanisms to balance domain invariance and class separability. Extensive experiments demonstrate that deep vision prompts effectively extract domain-invariant features, significantly improving the generalization ability of deep models and achieving state-of-the-art performance on three datasets.
CoFInAl: Enhancing Action Quality Assessment with Coarse-to-Fine Instruction Alignment
Apr 22, 2024Action Quality Assessment (AQA) is pivotal for quantifying actions across domains like sports and medical care. Existing methods often rely on pre-trained backbones from large-scale action recognition datasets to boost performance on smaller AQA datasets. However, this common strategy yields suboptimal results due to the inherent struggle of these backbones to capture the subtle cues essential for AQA. Moreover, fine-tuning on smaller datasets risks overfitting. To address these issues, we propose Coarse-to-Fine Instruction Alignment (CoFInAl). Inspired by recent advances in large language model tuning, CoFInAl aligns AQA with broader pre-trained tasks by reformulating it as a coarse-to-fine classification task. Initially, it learns grade prototypes for coarse assessment and then utilizes fixed sub-grade prototypes for fine-grained assessment. This hierarchical approach mirrors the judging process, enhancing interpretability within the AQA framework. Experimental results on two long-term AQA datasets demonstrate CoFInAl achieves state-of-the-art performance with significant correlation gains of 5.49% and 3.55% on Rhythmic Gymnastics and Fis-V, respectively. Our code is available at https://github.com/ZhouKanglei/CoFInAl_AQA.
Orchestrate Latent Expertise: Advancing Online Continual Learning with Multi-Level Supervision and Reverse Self-Distillation
Mar 30, 2024To accommodate real-world dynamics, artificial intelligence systems need to cope with sequentially arriving content in an online manner. Beyond regular Continual Learning (CL) attempting to address catastrophic forgetting with offline training of each task, Online Continual Learning (OCL) is a more challenging yet realistic setting that performs CL in a one-pass data stream. Current OCL methods primarily rely on memory replay of old training samples. However, a notable gap from CL to OCL stems from the additional overfitting-underfitting dilemma associated with the use of rehearsal buffers: the inadequate learning of new training samples (underfitting) and the repeated learning of a few old training samples (overfitting). To this end, we introduce a novel approach, Multi-level Online Sequential Experts (MOSE), which cultivates the model as stacked sub-experts, integrating multi-level supervision and reverse self-distillation. Supervision signals across multiple stages facilitate appropriate convergence of the new task while gathering various strengths from experts by knowledge distillation mitigates the performance decline of old tasks. MOSE demonstrates remarkable efficacy in learning new samples and preserving past knowledge through multi-level experts, thereby significantly advancing OCL performance over state-of-the-art baselines (e.g., up to 7.3% on Split CIFAR-100 and 6.1% on Split Tiny-ImageNet).
MAGR: Manifold-Aligned Graph Regularization for Continual Action Quality Assessment
Mar 07, 2024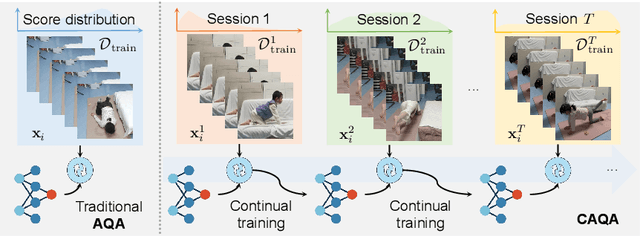
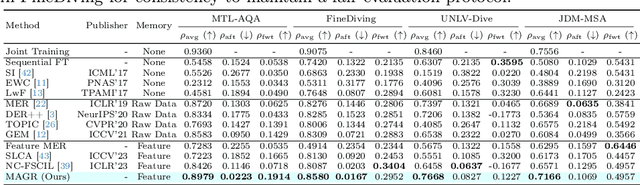

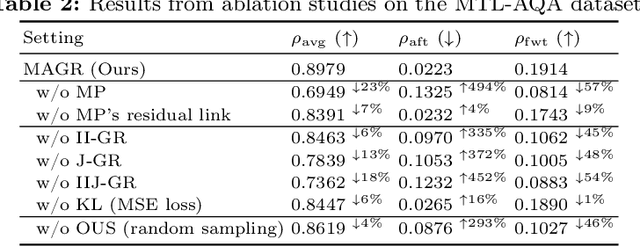
Action Quality Assessment (AQA) evaluates diverse skills but models struggle with non-stationary data. We propose Continual AQA (CAQA) to refine models using sparse new data. Feature replay preserves memory without storing raw inputs. However, the misalignment between static old features and the dynamically changing feature manifold causes severe catastrophic forgetting. To address this novel problem, we propose Manifold-Aligned Graph Regularization (MAGR), which first aligns deviated old features to the current feature manifold, ensuring representation consistency. It then constructs a graph jointly arranging old and new features aligned with quality scores. Experiments show MAGR outperforms recent strong baselines with up to 6.56%, 5.66%, 15.64%, and 9.05% correlation gains on the MTL-AQA, FineDiving, UNLV-Dive, and JDM-MSA split datasets, respectively. This validates MAGR for continual assessment challenges arising from non-stationary skill variations.
Pearl: A Production-ready Reinforcement Learning Agent
Dec 06, 2023Reinforcement Learning (RL) offers a versatile framework for achieving long-term goals. Its generality allows us to formalize a wide range of problems that real-world intelligent systems encounter, such as dealing with delayed rewards, handling partial observability, addressing the exploration and exploitation dilemma, utilizing offline data to improve online performance, and ensuring safety constraints are met. Despite considerable progress made by the RL research community in addressing these issues, existing open-source RL libraries tend to focus on a narrow portion of the RL solution pipeline, leaving other aspects largely unattended. This paper introduces Pearl, a Production-ready RL agent software package explicitly designed to embrace these challenges in a modular fashion. In addition to presenting preliminary benchmark results, this paper highlights Pearl's industry adoptions to demonstrate its readiness for production usage. Pearl is open sourced on Github at github.com/facebookresearch/pearl and its official website is located at pearlagent.github.io.
Towards a General Framework for Continual Learning with Pre-training
Oct 21, 2023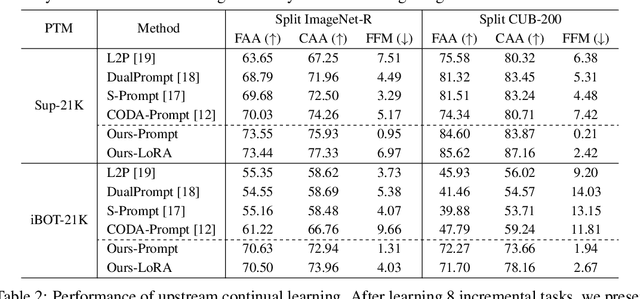
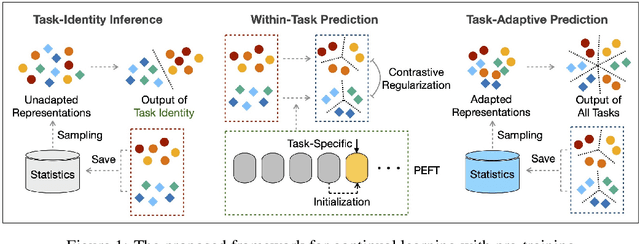
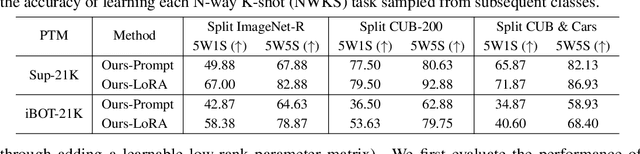
In this work, we present a general framework for continual learning of sequentially arrived tasks with the use of pre-training, which has emerged as a promising direction for artificial intelligence systems to accommodate real-world dynamics. From a theoretical perspective, we decompose its objective into three hierarchical components, including within-task prediction, task-identity inference, and task-adaptive prediction. Then we propose an innovative approach to explicitly optimize these components with parameter-efficient fine-tuning (PEFT) techniques and representation statistics. We empirically demonstrate the superiority and generality of our approach in downstream continual learning, and further explore the applicability of PEFT techniques in upstream continual learning. We also discuss the biological basis of the proposed framework with recent advances in neuroscience.
Overcoming Recency Bias of Normalization Statistics in Continual Learning: Balance and Adaptation
Oct 13, 2023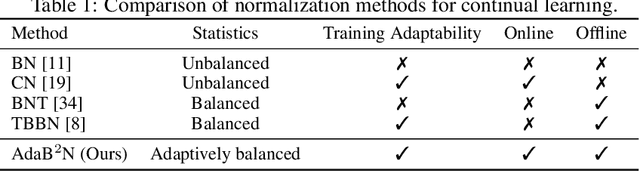
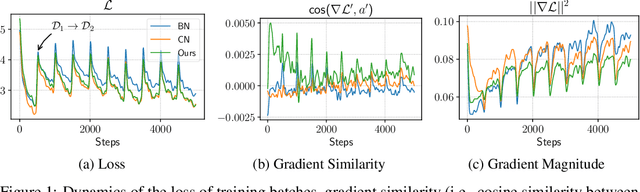
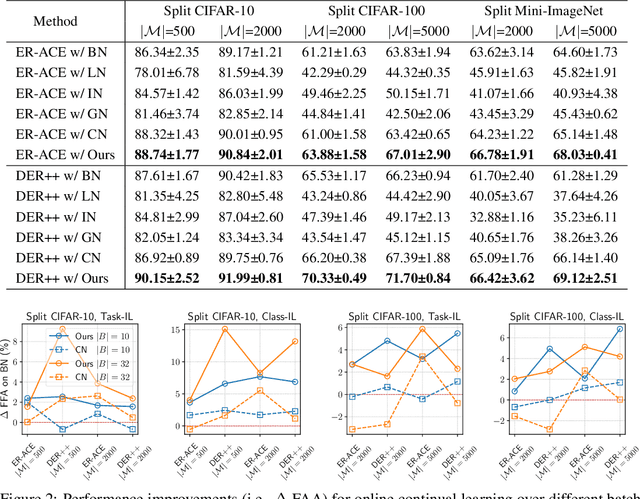
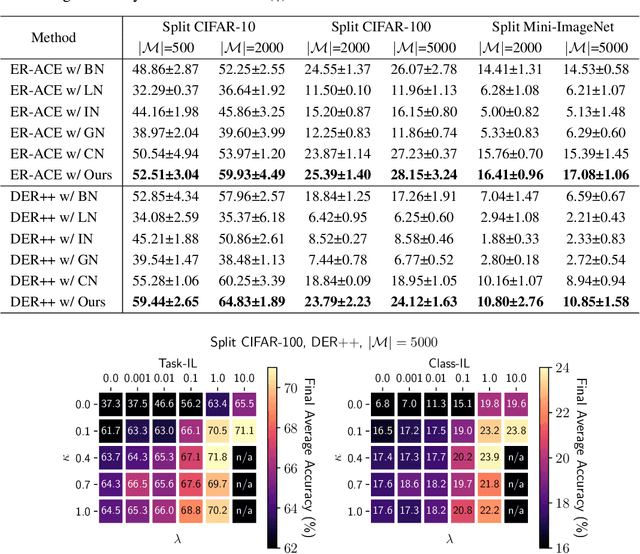
Continual learning entails learning a sequence of tasks and balancing their knowledge appropriately. With limited access to old training samples, much of the current work in deep neural networks has focused on overcoming catastrophic forgetting of old tasks in gradient-based optimization. However, the normalization layers provide an exception, as they are updated interdependently by the gradient and statistics of currently observed training samples, which require specialized strategies to mitigate recency bias. In this work, we focus on the most popular Batch Normalization (BN) and provide an in-depth theoretical analysis of its sub-optimality in continual learning. Our analysis demonstrates the dilemma between balance and adaptation of BN statistics for incremental tasks, which potentially affects training stability and generalization. Targeting on these particular challenges, we propose Adaptive Balance of BN (AdaB$^2$N), which incorporates appropriately a Bayesian-based strategy to adapt task-wise contributions and a modified momentum to balance BN statistics, corresponding to the training and testing stages. By implementing BN in a continual learning fashion, our approach achieves significant performance gains across a wide range of benchmarks, particularly for the challenging yet realistic online scenarios (e.g., up to 7.68%, 6.86% and 4.26% on Split CIFAR-10, Split CIFAR-100 and Split Mini-ImageNet, respectively). Our code is available at https://github.com/lvyilin/AdaB2N.
Hierarchical Decomposition of Prompt-Based Continual Learning: Rethinking Obscured Sub-optimality
Oct 11, 2023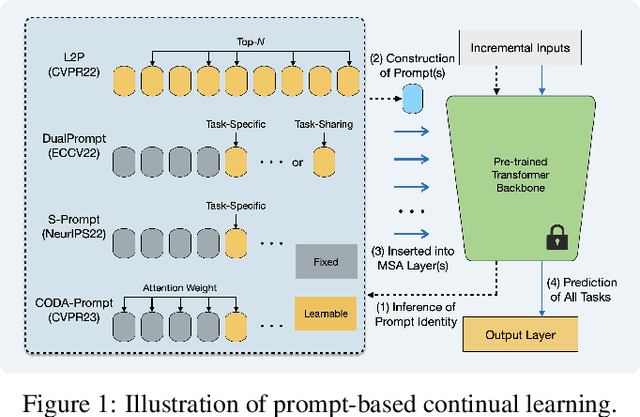
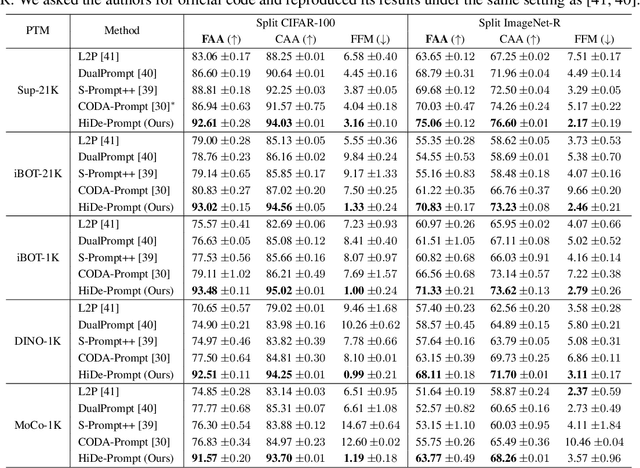
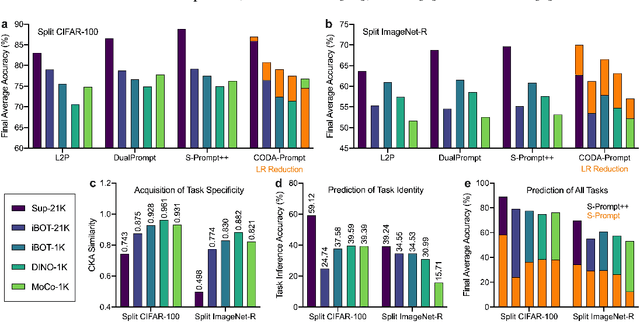
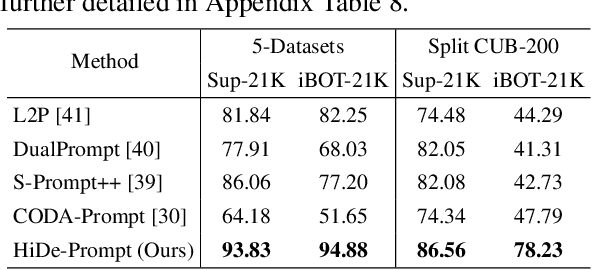
Prompt-based continual learning is an emerging direction in leveraging pre-trained knowledge for downstream continual learning, and has almost reached the performance pinnacle under supervised pre-training. However, our empirical research reveals that the current strategies fall short of their full potential under the more realistic self-supervised pre-training, which is essential for handling vast quantities of unlabeled data in practice. This is largely due to the difficulty of task-specific knowledge being incorporated into instructed representations via prompt parameters and predicted by uninstructed representations at test time. To overcome the exposed sub-optimality, we conduct a theoretical analysis of the continual learning objective in the context of pre-training, and decompose it into hierarchical components: within-task prediction, task-identity inference, and task-adaptive prediction. Following these empirical and theoretical insights, we propose Hierarchical Decomposition (HiDe-)Prompt, an innovative approach that explicitly optimizes the hierarchical components with an ensemble of task-specific prompts and statistics of both uninstructed and instructed representations, further with the coordination of a contrastive regularization strategy. Our extensive experiments demonstrate the superior performance of HiDe-Prompt and its robustness to pre-training paradigms in continual learning (e.g., up to 15.01% and 9.61% lead on Split CIFAR-100 and Split ImageNet-R, respectively). Our code is available at \url{https://github.com/thu-ml/HiDe-Prompt}.
Incorporating Neuro-Inspired Adaptability for Continual Learning in Artificial Intelligence
Aug 29, 2023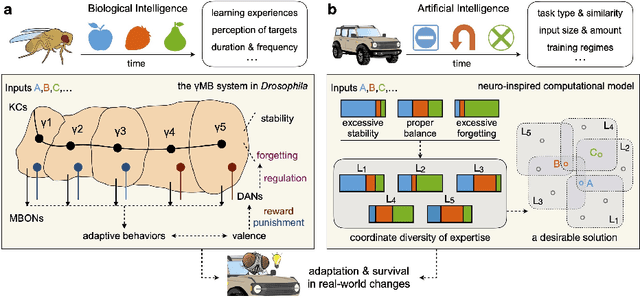
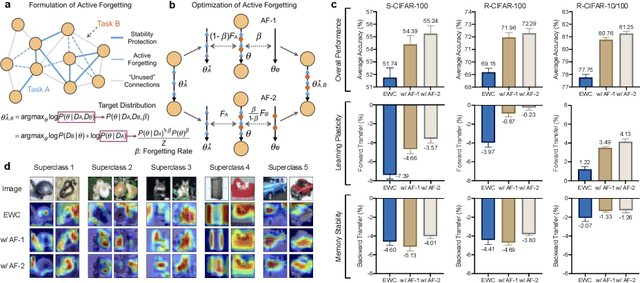
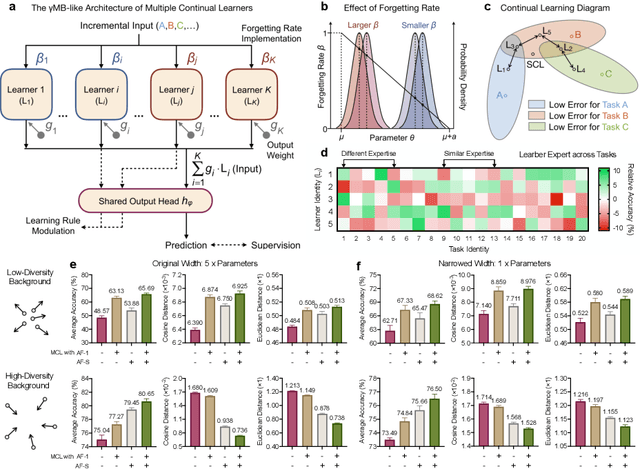
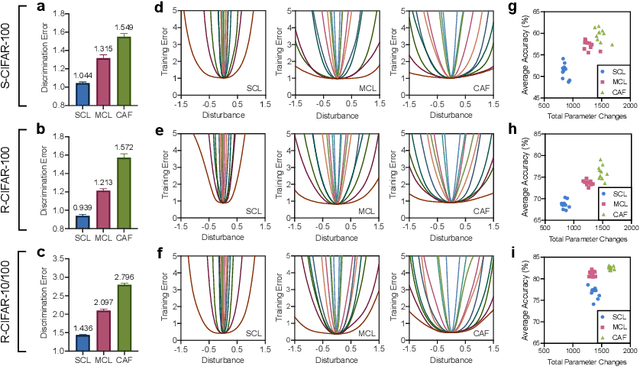
Continual learning aims to empower artificial intelligence (AI) with strong adaptability to the real world. For this purpose, a desirable solution should properly balance memory stability with learning plasticity, and acquire sufficient compatibility to capture the observed distributions. Existing advances mainly focus on preserving memory stability to overcome catastrophic forgetting, but remain difficult to flexibly accommodate incremental changes as biological intelligence (BI) does. By modeling a robust Drosophila learning system that actively regulates forgetting with multiple learning modules, here we propose a generic approach that appropriately attenuates old memories in parameter distributions to improve learning plasticity, and accordingly coordinates a multi-learner architecture to ensure solution compatibility. Through extensive theoretical and empirical validation, our approach not only clearly enhances the performance of continual learning, especially over synaptic regularization methods in task-incremental settings, but also potentially advances the understanding of neurological adaptive mechanisms, serving as a novel paradigm to progress AI and BI together.
SLCA: Slow Learner with Classifier Alignment for Continual Learning on a Pre-trained Model
Mar 09, 2023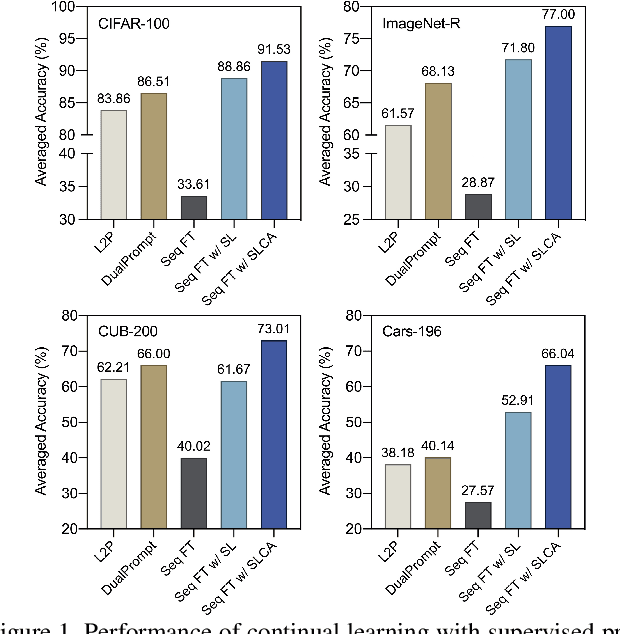
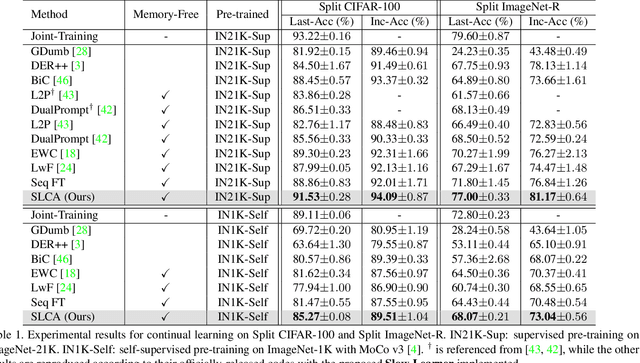
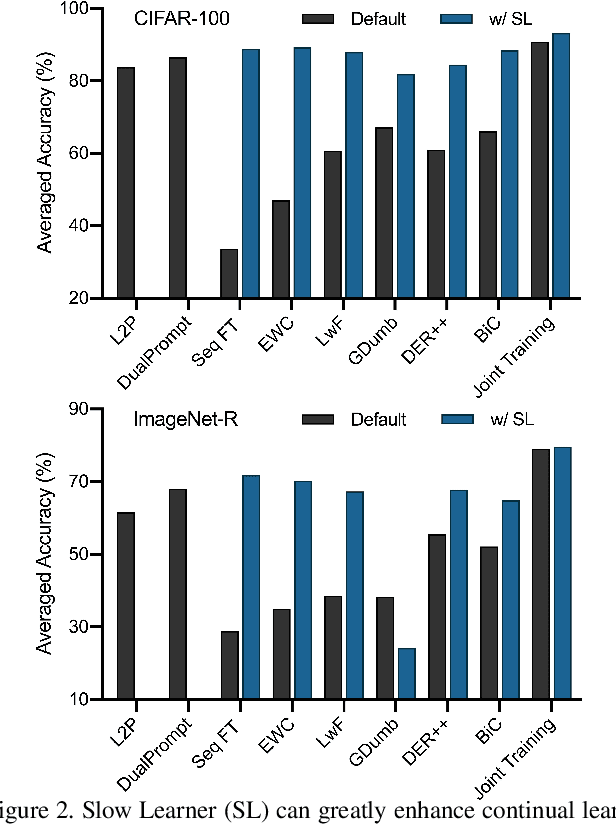
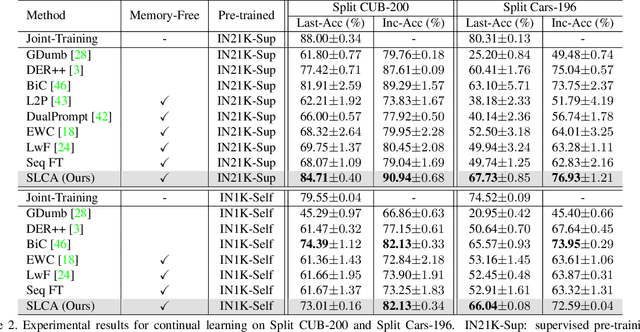
The goal of continual learning is to improve the performance of recognition models in learning sequentially arrived data. Although most existing works are established on the premise of learning from scratch, growing efforts have been devoted to incorporating the benefits of pre-training. However, how to adaptively exploit the pre-trained knowledge for each incremental task while maintaining its generalizability remains an open question. In this work, we present an extensive analysis for continual learning on a pre-trained model (CLPM), and attribute the key challenge to a progressive overfitting problem. Observing that selectively reducing the learning rate can almost resolve this issue in the representation layer, we propose a simple but extremely effective approach named Slow Learner with Classifier Alignment (SLCA), which further improves the classification layer by modeling the class-wise distributions and aligning the classification layers in a post-hoc fashion. Across a variety of scenarios, our proposal provides substantial improvements for CLPM (e.g., up to 49.76%, 50.05%, 44.69% and 40.16% on Split CIFAR-100, Split ImageNet-R, Split CUB-200 and Split Cars-196, respectively), and thus outperforms state-of-the-art approaches by a large margin. Based on such a strong baseline, critical factors and promising directions are analyzed in-depth to facilitate subsequent research.