 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHubert P. H. Shum
Two-Person Interaction Augmentation with Skeleton Priors
Apr 09, 2024
Close and continuous interaction with rich contacts is a crucial aspect of human activities (e.g. hugging, dancing) and of interest in many domains like activity recognition, motion prediction, character animation, etc. However, acquiring such skeletal motion is challenging. While direct motion capture is expensive and slow, motion editing/generation is also non-trivial, as complex contact patterns with topological and geometric constraints have to be retained. To this end, we propose a new deep learning method for two-body skeletal interaction motion augmentation, which can generate variations of contact-rich interactions with varying body sizes and proportions while retaining the key geometric/topological relations between two bodies. Our system can learn effectively from a relatively small amount of data and generalize to drastically different skeleton sizes. Through exhaustive evaluation and comparison, we show it can generate high-quality motions, has strong generalizability and outperforms traditional optimization-based methods and alternative deep learning solutions.
MAGR: Manifold-Aligned Graph Regularization for Continual Action Quality Assessment
Mar 07, 2024
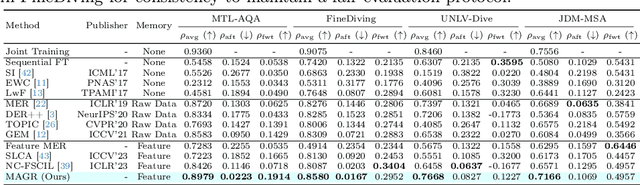

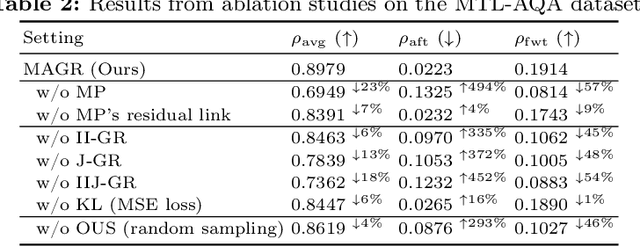
Action Quality Assessment (AQA) evaluates diverse skills but models struggle with non-stationary data. We propose Continual AQA (CAQA) to refine models using sparse new data. Feature replay preserves memory without storing raw inputs. However, the misalignment between static old features and the dynamically changing feature manifold causes severe catastrophic forgetting. To address this novel problem, we propose Manifold-Aligned Graph Regularization (MAGR), which first aligns deviated old features to the current feature manifold, ensuring representation consistency. It then constructs a graph jointly arranging old and new features aligned with quality scores. Experiments show MAGR outperforms recent strong baselines with up to 6.56%, 5.66%, 15.64%, and 9.05% correlation gains on the MTL-AQA, FineDiving, UNLV-Dive, and JDM-MSA split datasets, respectively. This validates MAGR for continual assessment challenges arising from non-stationary skill variations.
HINT: High-quality INPainting Transformer with Mask-Aware Encoding and Enhanced Attention
Feb 22, 2024Existing image inpainting methods leverage convolution-based downsampling approaches to reduce spatial dimensions. This may result in information loss from corrupted images where the available information is inherently sparse, especially for the scenario of large missing regions. Recent advances in self-attention mechanisms within transformers have led to significant improvements in many computer vision tasks including inpainting. However, limited by the computational costs, existing methods cannot fully exploit the efficacy of long-range modelling capabilities of such models. In this paper, we propose an end-to-end High-quality INpainting Transformer, abbreviated as HINT, which consists of a novel mask-aware pixel-shuffle downsampling module (MPD) to preserve the visible information extracted from the corrupted image while maintaining the integrity of the information available for high-level inferences made within the model. Moreover, we propose a Spatially-activated Channel Attention Layer (SCAL), an efficient self-attention mechanism interpreting spatial awareness to model the corrupted image at multiple scales. To further enhance the effectiveness of SCAL, motivated by recent advanced in speech recognition, we introduce a sandwich structure that places feed-forward networks before and after the SCAL module. We demonstrate the superior performance of HINT compared to contemporary state-of-the-art models on four datasets, CelebA, CelebA-HQ, Places2, and Dunhuang.
Enhancing Surgical Performance in Cardiothoracic Surgery with Innovations from Computer Vision and Artificial Intelligence: A Narrative Review
Feb 17, 2024When technical requirements are high, and patient outcomes are critical, opportunities for monitoring and improving surgical skills via objective motion analysis feedback may be particularly beneficial. This narrative review synthesises work on technical and non-technical surgical skills, collaborative task performance, and pose estimation to illustrate new opportunities to advance cardiothoracic surgical performance with innovations from computer vision and artificial intelligence. These technological innovations are critically evaluated in terms of the benefits they could offer the cardiothoracic surgical community, and any barriers to the uptake of the technology are elaborated upon. Like some other specialities, cardiothoracic surgery has relatively few opportunities to benefit from tools with data capture technology embedded within them (as with robotic-assisted laparoscopic surgery, for example). In such cases, pose estimation techniques that allow for movement tracking across a conventional operating field without using specialist equipment or markers offer considerable potential. With video data from either simulated or real surgical procedures, these tools can (1) provide insight into the development of expertise and surgical performance over a surgeon's career, (2) provide feedback to trainee surgeons regarding areas for improvement, (3) provide the opportunity to investigate what aspects of skill may be linked to patient outcomes which can (4) inform the aspects of surgical skill which should be focused on within training or mentoring programmes. Classifier or assessment algorithms that use artificial intelligence to 'learn' what expertise is from expert surgical evaluators could further assist educators in determining if trainees meet competency thresholds.
Pose-based Tremor Type and Level Analysis for Parkinson's Disease from Video
Dec 21, 2023Purpose:Current methods for diagnosis of PD rely on clinical examination. The accuracy of diagnosis ranges between 73% and 84%, and is influenced by the experience of the clinical assessor. Hence, an automatic, effective and interpretable supporting system for PD symptom identification would support clinicians in making more robust PD diagnostic decisions. Methods: We propose to analyze Parkinson's tremor (PT) to support the analysis of PD, since PT is one of the most typical symptoms of PD with broad generalizability. To realize the idea, we present SPA-PTA, a deep learning-based PT classification and severity estimation system that takes consumer-grade videos of front-facing humans as input. The core of the system is a novel attention module with a lightweight pyramidal channel-squeezing-fusion architecture that effectively extracts relevant PT information and filters noise. It enhances modeling performance while improving system interpretability. Results:We validate our system via individual-based leave-one-out cross-validation on two tasks: the PT classification task and the tremor severity rating estimation task. Our system presents a 91.3% accuracy and 80.0% F1-score in classifying PT with non-PT class, while providing a 76.4% accuracy and 76.7% F1-score in more complex multiclass tremor rating classification task. Conclusion: Our system offers a cost-effective PT classification and tremor severity estimation results as warning signs of PD for undiagnosed patients with PT symptoms. In addition, it provides a potential solution for supporting PD diagnosis in regions with limited clinical resources.
Correlation-Distance Graph Learning for Treatment Response Prediction from rs-fMRI
Nov 17, 2023Resting-state fMRI (rs-fMRI) functional connectivity (FC) analysis provides valuable insights into the relationships between different brain regions and their potential implications for neurological or psychiatric disorders. However, specific design efforts to predict treatment response from rs-fMRI remain limited due to difficulties in understanding the current brain state and the underlying mechanisms driving the observed patterns, which limited the clinical application of rs-fMRI. To overcome that, we propose a graph learning framework that captures comprehensive features by integrating both correlation and distance-based similarity measures under a contrastive loss. This approach results in a more expressive framework that captures brain dynamic features at different scales and enables more accurate prediction of treatment response. Our experiments on the chronic pain and depersonalization disorder datasets demonstrate that our proposed method outperforms current methods in different scenarios. To the best of our knowledge, we are the first to explore the integration of distance-based and correlation-based neural similarity into graph learning for treatment response prediction.
U3DS$^3$: Unsupervised 3D Semantic Scene Segmentation
Nov 10, 2023Contemporary point cloud segmentation approaches largely rely on richly annotated 3D training data. However, it is both time-consuming and challenging to obtain consistently accurate annotations for such 3D scene data. Moreover, there is still a lack of investigation into fully unsupervised scene segmentation for point clouds, especially for holistic 3D scenes. This paper presents U3DS$^3$, as a step towards completely unsupervised point cloud segmentation for any holistic 3D scenes. To achieve this, U3DS$^3$ leverages a generalized unsupervised segmentation method for both object and background across both indoor and outdoor static 3D point clouds with no requirement for model pre-training, by leveraging only the inherent information of the point cloud to achieve full 3D scene segmentation. The initial step of our proposed approach involves generating superpoints based on the geometric characteristics of each scene. Subsequently, it undergoes a learning process through a spatial clustering-based methodology, followed by iterative training using pseudo-labels generated in accordance with the cluster centroids. Moreover, by leveraging the invariance and equivariance of the volumetric representations, we apply the geometric transformation on voxelized features to provide two sets of descriptors for robust representation learning. Finally, our evaluation provides state-of-the-art results on the ScanNet and SemanticKITTI, and competitive results on the S3DIS, benchmark datasets.
Unaligned 2D to 3D Translation with Conditional Vector-Quantized Code Diffusion using Transformers
Aug 27, 2023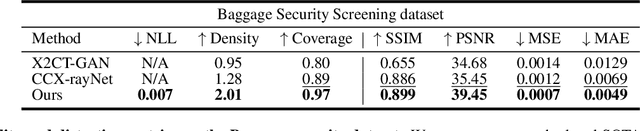
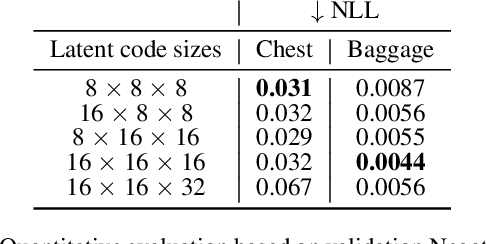

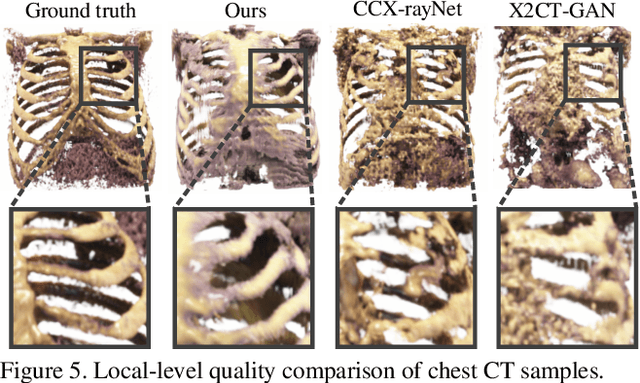
Generating 3D images of complex objects conditionally from a few 2D views is a difficult synthesis problem, compounded by issues such as domain gap and geometric misalignment. For instance, a unified framework such as Generative Adversarial Networks cannot achieve this unless they explicitly define both a domain-invariant and geometric-invariant joint latent distribution, whereas Neural Radiance Fields are generally unable to handle both issues as they optimize at the pixel level. By contrast, we propose a simple and novel 2D to 3D synthesis approach based on conditional diffusion with vector-quantized codes. Operating in an information-rich code space enables high-resolution 3D synthesis via full-coverage attention across the views. Specifically, we generate the 3D codes (e.g. for CT images) conditional on previously generated 3D codes and the entire codebook of two 2D views (e.g. 2D X-rays). Qualitative and quantitative results demonstrate state-of-the-art performance over specialized methods across varied evaluation criteria, including fidelity metrics such as density, coverage, and distortion metrics for two complex volumetric imagery datasets from in real-world scenarios.
Enhancing Perception and Immersion in Pre-Captured Environments through Learning-Based Eye Height Adaptation
Aug 24, 2023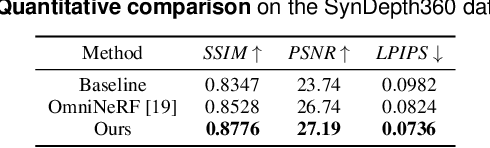
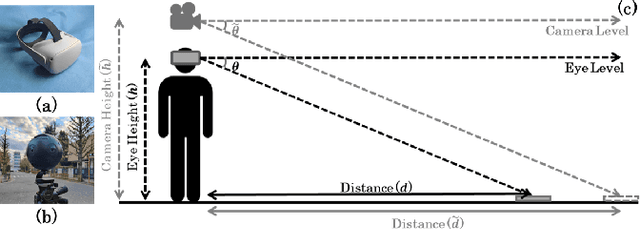


Pre-captured immersive environments using omnidirectional cameras provide a wide range of virtual reality applications. Previous research has shown that manipulating the eye height in egocentric virtual environments can significantly affect distance perception and immersion. However, the influence of eye height in pre-captured real environments has received less attention due to the difficulty of altering the perspective after finishing the capture process. To explore this influence, we first propose a pilot study that captures real environments with multiple eye heights and asks participants to judge the egocentric distances and immersion. If a significant influence is confirmed, an effective image-based approach to adapt pre-captured real-world environments to the user's eye height would be desirable. Motivated by the study, we propose a learning-based approach for synthesizing novel views for omnidirectional images with altered eye heights. This approach employs a multitask architecture that learns depth and semantic segmentation in two formats, and generates high-quality depth and semantic segmentation to facilitate the inpainting stage. With the improved omnidirectional-aware layered depth image, our approach synthesizes natural and realistic visuals for eye height adaptation. Quantitative and qualitative evaluation shows favorable results against state-of-the-art methods, and an extensive user study verifies improved perception and immersion for pre-captured real-world environments.
Hard No-Box Adversarial Attack on Skeleton-Based Human Action Recognition with Skeleton-Motion-Informed Gradient
Aug 18, 2023
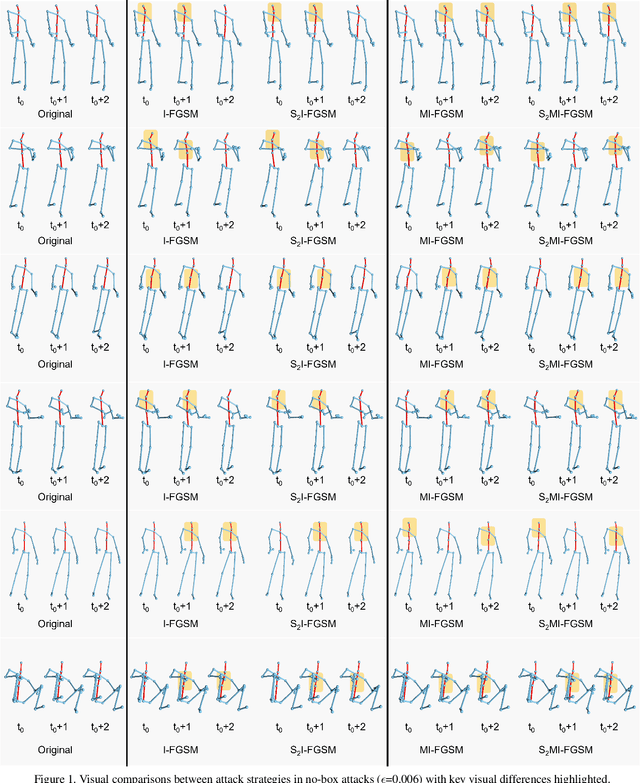


Recently, methods for skeleton-based human activity recognition have been shown to be vulnerable to adversarial attacks. However, these attack methods require either the full knowledge of the victim (i.e. white-box attacks), access to training data (i.e. transfer-based attacks) or frequent model queries (i.e. black-box attacks). All their requirements are highly restrictive, raising the question of how detrimental the vulnerability is. In this paper, we show that the vulnerability indeed exists. To this end, we consider a new attack task: the attacker has no access to the victim model or the training data or labels, where we coin the term hard no-box attack. Specifically, we first learn a motion manifold where we define an adversarial loss to compute a new gradient for the attack, named skeleton-motion-informed (SMI) gradient. Our gradient contains information of the motion dynamics, which is different from existing gradient-based attack methods that compute the loss gradient assuming each dimension in the data is independent. The SMI gradient can augment many gradient-based attack methods, leading to a new family of no-box attack methods. Extensive evaluation and comparison show that our method imposes a real threat to existing classifiers. They also show that the SMI gradient improves the transferability and imperceptibility of adversarial samples in both no-box and transfer-based black-box settings.