 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToby P. Breckon
Performance Evaluation of Segment Anything Model with Variational Prompting for Application to Non-Visible Spectrum Imagery
Apr 18, 2024
The Segment Anything Model (SAM) is a deep neural network foundational model designed to perform instance segmentation which has gained significant popularity given its zero-shot segmentation ability. SAM operates by generating masks based on various input prompts such as text, bounding boxes, points, or masks, introducing a novel methodology to overcome the constraints posed by dataset-specific scarcity. While SAM is trained on an extensive dataset, comprising ~11M images, it mostly consists of natural photographic images with only very limited images from other modalities. Whilst the rapid progress in visual infrared surveillance and X-ray security screening imaging technologies, driven forward by advances in deep learning, has significantly enhanced the ability to detect, classify and segment objects with high accuracy, it is not evident if the SAM zero-shot capabilities can be transferred to such modalities. This work assesses SAM capabilities in segmenting objects of interest in the X-ray/infrared modalities. Our approach reuses the pre-trained SAM with three different prompts: bounding box, centroid and random points. We present quantitative/qualitative results to showcase the performance on selected datasets. Our results show that SAM can segment objects in the X-ray modality when given a box prompt, but its performance varies for point prompts. Specifically, SAM performs poorly in segmenting slender objects and organic materials, such as plastic bottles. We find that infrared objects are also challenging to segment with point prompts given the low-contrast nature of this modality. This study shows that while SAM demonstrates outstanding zero-shot capabilities with box prompts, its performance ranges from moderate to poor for point prompts, indicating that special consideration on the cross-modal generalisation of SAM is needed when considering use on X-ray/infrared imagery.
Disentangling Racial Phenotypes: Fine-Grained Control of Race-related Facial Phenotype Characteristics
Mar 29, 2024
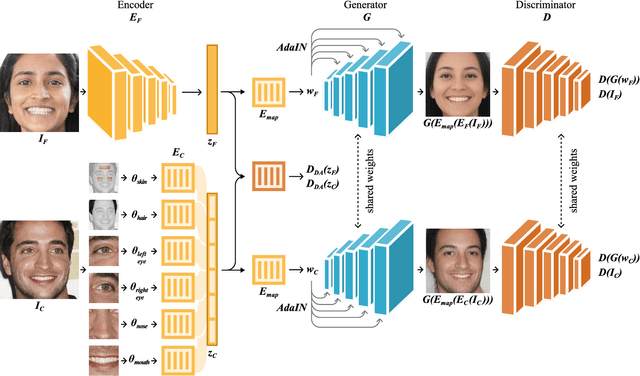

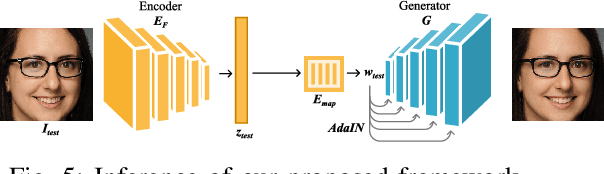
Achieving an effective fine-grained appearance variation over 2D facial images, whilst preserving facial identity, is a challenging task due to the high complexity and entanglement of common 2D facial feature encoding spaces. Despite these challenges, such fine-grained control, by way of disentanglement is a crucial enabler for data-driven racial bias mitigation strategies across multiple automated facial analysis tasks, as it allows to analyse, characterise and synthesise human facial diversity. In this paper, we propose a novel GAN framework to enable fine-grained control over individual race-related phenotype attributes of the facial images. Our framework factors the latent (feature) space into elements that correspond to race-related facial phenotype representations, thereby separating phenotype aspects (e.g. skin, hair colour, nose, eye, mouth shapes), which are notoriously difficult to annotate robustly in real-world facial data. Concurrently, we also introduce a high quality augmented, diverse 2D face image dataset drawn from CelebA-HQ for GAN training. Unlike prior work, our framework only relies upon 2D imagery and related parameters to achieve state-of-the-art individual control over race-related phenotype attributes with improved photo-realistic output.
U3DS$^3$: Unsupervised 3D Semantic Scene Segmentation
Nov 10, 2023Contemporary point cloud segmentation approaches largely rely on richly annotated 3D training data. However, it is both time-consuming and challenging to obtain consistently accurate annotations for such 3D scene data. Moreover, there is still a lack of investigation into fully unsupervised scene segmentation for point clouds, especially for holistic 3D scenes. This paper presents U3DS$^3$, as a step towards completely unsupervised point cloud segmentation for any holistic 3D scenes. To achieve this, U3DS$^3$ leverages a generalized unsupervised segmentation method for both object and background across both indoor and outdoor static 3D point clouds with no requirement for model pre-training, by leveraging only the inherent information of the point cloud to achieve full 3D scene segmentation. The initial step of our proposed approach involves generating superpoints based on the geometric characteristics of each scene. Subsequently, it undergoes a learning process through a spatial clustering-based methodology, followed by iterative training using pseudo-labels generated in accordance with the cluster centroids. Moreover, by leveraging the invariance and equivariance of the volumetric representations, we apply the geometric transformation on voxelized features to provide two sets of descriptors for robust representation learning. Finally, our evaluation provides state-of-the-art results on the ScanNet and SemanticKITTI, and competitive results on the S3DIS, benchmark datasets.
On Pixel-level Performance Assessment in Anomaly Detection
Oct 25, 2023Anomaly detection methods have demonstrated remarkable success across various applications. However, assessing their performance, particularly at the pixel-level, presents a complex challenge due to the severe imbalance that is most commonly present between normal and abnormal samples. Commonly adopted evaluation metrics designed for pixel-level detection may not effectively capture the nuanced performance variations arising from this class imbalance. In this paper, we dissect the intricacies of this challenge, underscored by visual evidence and statistical analysis, leading to delve into the need for evaluation metrics that account for the imbalance. We offer insights into more accurate metrics, using eleven leading contemporary anomaly detection methods on twenty-one anomaly detection problems. Overall, from this extensive experimental evaluation, we can conclude that Precision-Recall-based metrics can better capture relative method performance, making them more suitable for the task.
Unaligned 2D to 3D Translation with Conditional Vector-Quantized Code Diffusion using Transformers
Aug 27, 2023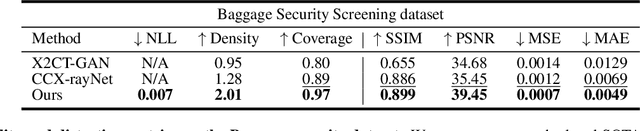
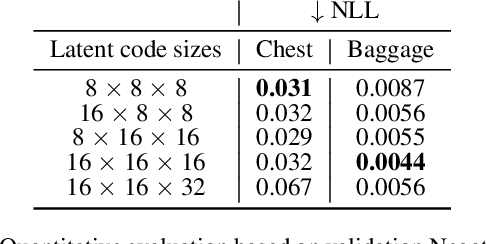

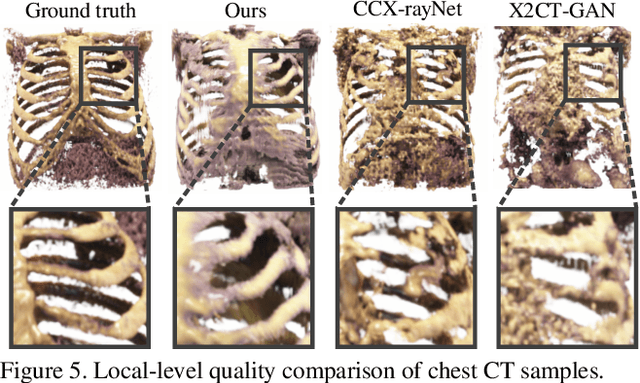
Generating 3D images of complex objects conditionally from a few 2D views is a difficult synthesis problem, compounded by issues such as domain gap and geometric misalignment. For instance, a unified framework such as Generative Adversarial Networks cannot achieve this unless they explicitly define both a domain-invariant and geometric-invariant joint latent distribution, whereas Neural Radiance Fields are generally unable to handle both issues as they optimize at the pixel level. By contrast, we propose a simple and novel 2D to 3D synthesis approach based on conditional diffusion with vector-quantized codes. Operating in an information-rich code space enables high-resolution 3D synthesis via full-coverage attention across the views. Specifically, we generate the 3D codes (e.g. for CT images) conditional on previously generated 3D codes and the entire codebook of two 2D views (e.g. 2D X-rays). Qualitative and quantitative results demonstrate state-of-the-art performance over specialized methods across varied evaluation criteria, including fidelity metrics such as density, coverage, and distortion metrics for two complex volumetric imagery datasets from in real-world scenarios.
Racial Bias within Face Recognition: A Survey
May 01, 2023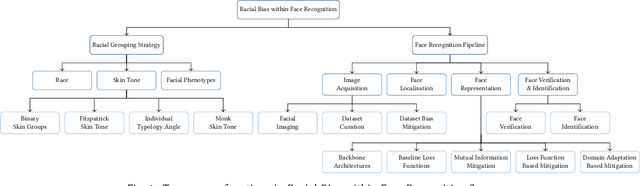
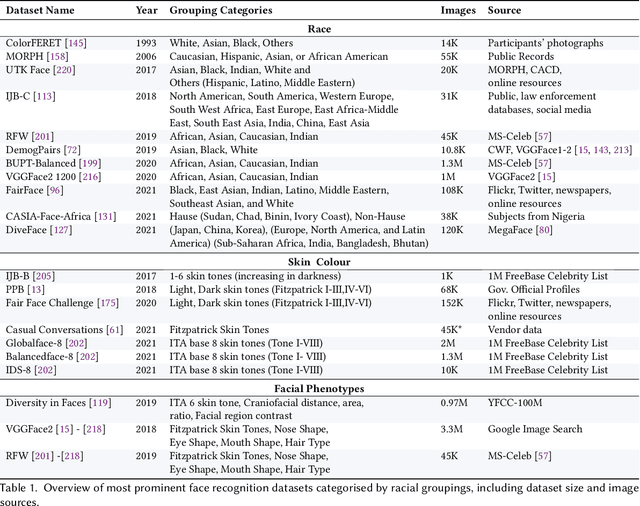

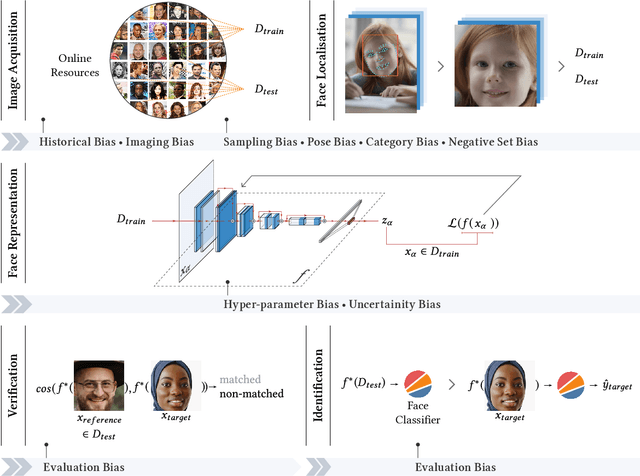
Facial recognition is one of the most academically studied and industrially developed areas within computer vision where we readily find associated applications deployed globally. This widespread adoption has uncovered significant performance variation across subjects of different racial profiles leading to focused research attention on racial bias within face recognition spanning both current causation and future potential solutions. In support, this study provides an extensive taxonomic review of research on racial bias within face recognition exploring every aspect and stage of the face recognition processing pipeline. Firstly, we discuss the problem definition of racial bias, starting with race definition, grouping strategies, and the societal implications of using race or race-related groupings. Secondly, we divide the common face recognition processing pipeline into four stages: image acquisition, face localisation, face representation, face verification and identification, and review the relevant corresponding literature associated with each stage. The overall aim is to provide comprehensive coverage of the racial bias problem with respect to each and every stage of the face recognition processing pipeline whilst also highlighting the potential pitfalls and limitations of contemporary mitigation strategies that need to be considered within future research endeavours or commercial applications alike.
Less is More: Reducing Task and Model Complexity for 3D Point Cloud Semantic Segmentation
Mar 28, 2023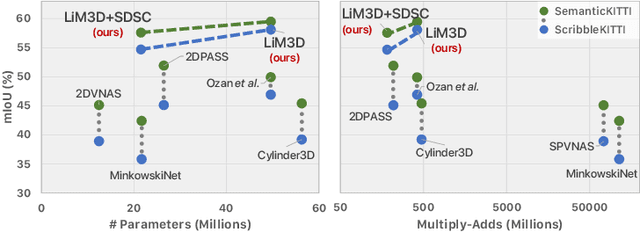
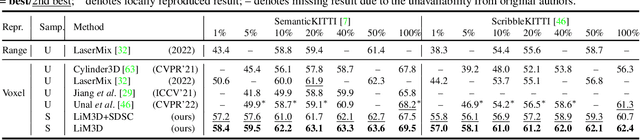

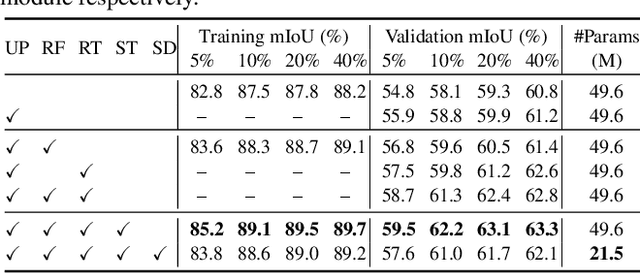
Whilst the availability of 3D LiDAR point cloud data has significantly grown in recent years, annotation remains expensive and time-consuming, leading to a demand for semi-supervised semantic segmentation methods with application domains such as autonomous driving. Existing work very often employs relatively large segmentation backbone networks to improve segmentation accuracy, at the expense of computational costs. In addition, many use uniform sampling to reduce ground truth data requirements for learning needed, often resulting in sub-optimal performance. To address these issues, we propose a new pipeline that employs a smaller architecture, requiring fewer ground-truth annotations to achieve superior segmentation accuracy compared to contemporary approaches. This is facilitated via a novel Sparse Depthwise Separable Convolution module that significantly reduces the network parameter count while retaining overall task performance. To effectively sub-sample our training data, we propose a new Spatio-Temporal Redundant Frame Downsampling (ST-RFD) method that leverages knowledge of sensor motion within the environment to extract a more diverse subset of training data frame samples. To leverage the use of limited annotated data samples, we further propose a soft pseudo-label method informed by LiDAR reflectivity. Our method outperforms contemporary semi-supervised work in terms of mIoU, using less labeled data, on the SemanticKITTI (59.5@5%) and ScribbleKITTI (58.1@5%) benchmark datasets, based on a 2.3x reduction in model parameters and 641x fewer multiply-add operations whilst also demonstrating significant performance improvement on limited training data (i.e., Less is More).
ACR: Attention Collaboration-based Regressor for Arbitrary Two-Hand Reconstruction
Mar 10, 2023
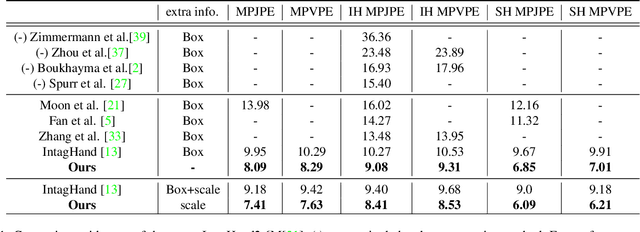
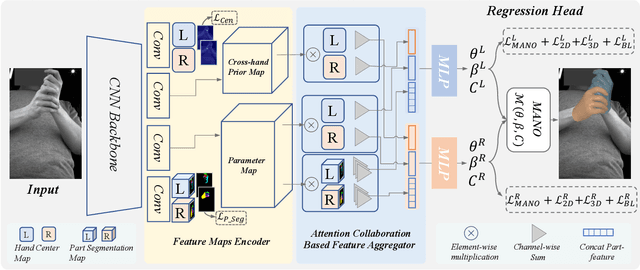

Reconstructing two hands from monocular RGB images is challenging due to frequent occlusion and mutual confusion. Existing methods mainly learn an entangled representation to encode two interacting hands, which are incredibly fragile to impaired interaction, such as truncated hands, separate hands, or external occlusion. This paper presents ACR (Attention Collaboration-based Regressor), which makes the first attempt to reconstruct hands in arbitrary scenarios. To achieve this, ACR explicitly mitigates interdependencies between hands and between parts by leveraging center and part-based attention for feature extraction. However, reducing interdependence helps release the input constraint while weakening the mutual reasoning about reconstructing the interacting hands. Thus, based on center attention, ACR also learns cross-hand prior that handle the interacting hands better. We evaluate our method on various types of hand reconstruction datasets. Our method significantly outperforms the best interacting-hand approaches on the InterHand2.6M dataset while yielding comparable performance with the state-of-the-art single-hand methods on the FreiHand dataset. More qualitative results on in-the-wild and hand-object interaction datasets and web images/videos further demonstrate the effectiveness of our approach for arbitrary hand reconstruction. Our code is available at https://github.com/ZhengdiYu/Arbitrary-Hands-3D-Reconstruction.
1st Workshop on Maritime Computer Vision (MaCVi) 2023: Challenge Results
Nov 28, 2022


The 1$^{\text{st}}$ Workshop on Maritime Computer Vision (MaCVi) 2023 focused on maritime computer vision for Unmanned Aerial Vehicles (UAV) and Unmanned Surface Vehicle (USV), and organized several subchallenges in this domain: (i) UAV-based Maritime Object Detection, (ii) UAV-based Maritime Object Tracking, (iii) USV-based Maritime Obstacle Segmentation and (iv) USV-based Maritime Obstacle Detection. The subchallenges were based on the SeaDronesSee and MODS benchmarks. This report summarizes the main findings of the individual subchallenges and introduces a new benchmark, called SeaDronesSee Object Detection v2, which extends the previous benchmark by including more classes and footage. We provide statistical and qualitative analyses, and assess trends in the best-performing methodologies of over 130 submissions. The methods are summarized in the appendix. The datasets, evaluation code and the leaderboard are publicly available at https://seadronessee.cs.uni-tuebingen.de/macvi.
Exact-NeRF: An Exploration of a Precise Volumetric Parameterization for Neural Radiance Fields
Nov 22, 2022



Neural Radiance Fields (NeRF) have attracted significant attention due to their ability to synthesize novel scene views with great accuracy. However, inherent to their underlying formulation, the sampling of points along a ray with zero width may result in ambiguous representations that lead to further rendering artifacts such as aliasing in the final scene. To address this issue, the recent variant mip-NeRF proposes an Integrated Positional Encoding (IPE) based on a conical view frustum. Although this is expressed with an integral formulation, mip-NeRF instead approximates this integral as the expected value of a multivariate Gaussian distribution. This approximation is reliable for short frustums but degrades with highly elongated regions, which arises when dealing with distant scene objects under a larger depth of field. In this paper, we explore the use of an exact approach for calculating the IPE by using a pyramid-based integral formulation instead of an approximated conical-based one. We denote this formulation as Exact-NeRF and contribute the first approach to offer a precise analytical solution to the IPE within the NeRF domain. Our exploratory work illustrates that such an exact formulation Exact-NeRF matches the accuracy of mip-NeRF and furthermore provides a natural extension to more challenging scenarios without further modification, such as in the case of unbounded scenes. Our contribution aims to both address the hitherto unexplored issues of frustum approximation in earlier NeRF work and additionally provide insight into the potential future consideration of analytical solutions in future NeRF extensions.