 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChristophe De Vleeschouwer
Self-Avatar Animation in Virtual Reality: Impact of Motion Signals Artifacts on the Full-Body Pose Reconstruction
Apr 29, 2024
Virtual Reality (VR) applications have revolutionized user experiences by immersing individuals in interactive 3D environments. These environments find applications in numerous fields, including healthcare, education, or architecture. A significant aspect of VR is the inclusion of self-avatars, representing users within the virtual world, which enhances interaction and embodiment. However, generating lifelike full-body self-avatar animations remains challenging, particularly in consumer-grade VR systems, where lower-body tracking is often absent. One method to tackle this problem is by providing an external source of motion information that includes lower body information such as full Cartesian positions estimated from RGB(D) cameras. Nevertheless, the limitations of these systems are multiples: the desynchronization between the two motion sources and occlusions are examples of significant issues that hinder the implementations of such systems. In this paper, we aim to measure the impact on the reconstruction of the articulated self-avatar's full-body pose of (1) the latency between the VR motion features and estimated positions, (2) the data acquisition rate, (3) occlusions, and (4) the inaccuracy of the position estimation algorithm. In addition, we analyze the motion reconstruction errors using ground truth and 3D Cartesian coordinates estimated from \textit{YOLOv8} pose estimation. These analyzes show that the studied methods are significantly sensitive to any degradation tested, especially regarding the velocity reconstruction error.
Multi-Stream Cellular Test-Time Adaptation of Real-Time Models Evolving in Dynamic Environments
Apr 27, 2024In the era of the Internet of Things (IoT), objects connect through a dynamic network, empowered by technologies like 5G, enabling real-time data sharing. However, smart objects, notably autonomous vehicles, face challenges in critical local computations due to limited resources. Lightweight AI models offer a solution but struggle with diverse data distributions. To address this limitation, we propose a novel Multi-Stream Cellular Test-Time Adaptation (MSC-TTA) setup where models adapt on the fly to a dynamic environment divided into cells. Then, we propose a real-time adaptive student-teacher method that leverages the multiple streams available in each cell to quickly adapt to changing data distributions. We validate our methodology in the context of autonomous vehicles navigating across cells defined based on location and weather conditions. To facilitate future benchmarking, we release a new multi-stream large-scale synthetic semantic segmentation dataset, called DADE, and show that our multi-stream approach outperforms a single-stream baseline. We believe that our work will open research opportunities in the IoT and 5G eras, offering solutions for real-time model adaptation.
SoccerNet Game State Reconstruction: End-to-End Athlete Tracking and Identification on a Minimap
Apr 17, 2024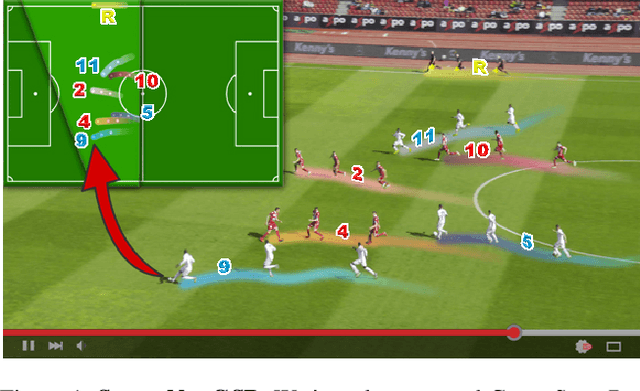
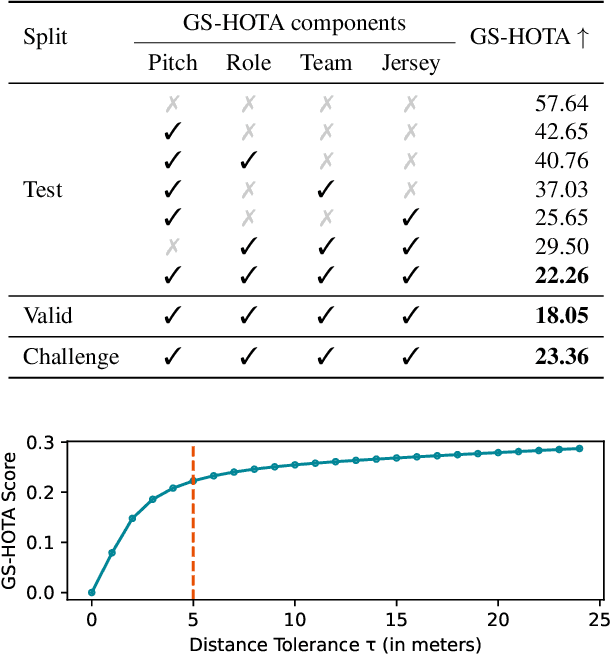
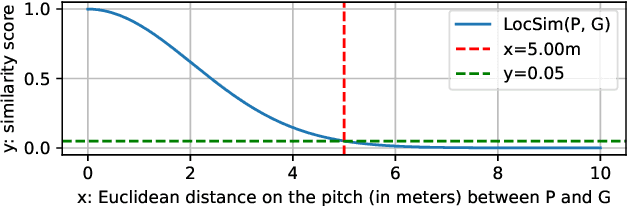

Tracking and identifying athletes on the pitch holds a central role in collecting essential insights from the game, such as estimating the total distance covered by players or understanding team tactics. This tracking and identification process is crucial for reconstructing the game state, defined by the athletes' positions and identities on a 2D top-view of the pitch, (i.e. a minimap). However, reconstructing the game state from videos captured by a single camera is challenging. It requires understanding the position of the athletes and the viewpoint of the camera to localize and identify players within the field. In this work, we formalize the task of Game State Reconstruction and introduce SoccerNet-GSR, a novel Game State Reconstruction dataset focusing on football videos. SoccerNet-GSR is composed of 200 video sequences of 30 seconds, annotated with 9.37 million line points for pitch localization and camera calibration, as well as over 2.36 million athlete positions on the pitch with their respective role, team, and jersey number. Furthermore, we introduce GS-HOTA, a novel metric to evaluate game state reconstruction methods. Finally, we propose and release an end-to-end baseline for game state reconstruction, bootstrapping the research on this task. Our experiments show that GSR is a challenging novel task, which opens the field for future research. Our dataset and codebase are publicly available at https://github.com/SoccerNet/sn-gamestate.
Camera clustering for scalable stream-based active distillation
Apr 16, 2024We present a scalable framework designed to craft efficient lightweight models for video object detection utilizing self-training and knowledge distillation techniques. We scrutinize methodologies for the ideal selection of training images from video streams and the efficacy of model sharing across numerous cameras. By advocating for a camera clustering methodology, we aim to diminish the requisite number of models for training while augmenting the distillation dataset. The findings affirm that proper camera clustering notably amplifies the accuracy of distilled models, eclipsing the methodologies that employ distinct models for each camera or a universal model trained on the aggregate camera data.
Multi-task Learning for Joint Re-identification, Team Affiliation, and Role Classification for Sports Visual Tracking
Jan 18, 2024
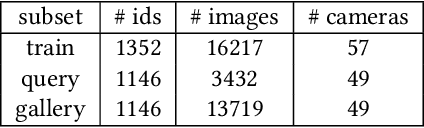
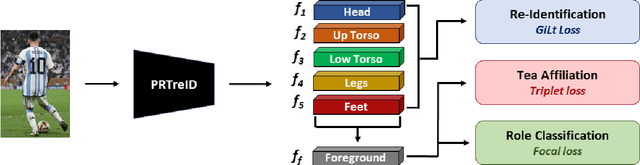

Effective tracking and re-identification of players is essential for analyzing soccer videos. But, it is a challenging task due to the non-linear motion of players, the similarity in appearance of players from the same team, and frequent occlusions. Therefore, the ability to extract meaningful embeddings to represent players is crucial in developing an effective tracking and re-identification system. In this paper, a multi-purpose part-based person representation method, called PRTreID, is proposed that performs three tasks of role classification, team affiliation, and re-identification, simultaneously. In contrast to available literature, a single network is trained with multi-task supervision to solve all three tasks, jointly. The proposed joint method is computationally efficient due to the shared backbone. Also, the multi-task learning leads to richer and more discriminative representations, as demonstrated by both quantitative and qualitative results. To demonstrate the effectiveness of PRTreID, it is integrated with a state-of-the-art tracking method, using a part-based post-processing module to handle long-term tracking. The proposed tracking method outperforms all existing tracking methods on the challenging SoccerNet tracking dataset.
SoccerNet 2023 Challenges Results
Sep 12, 2023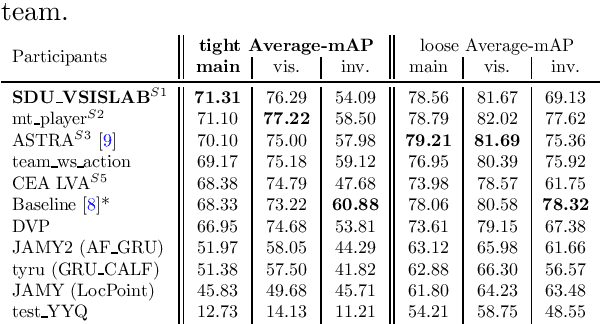
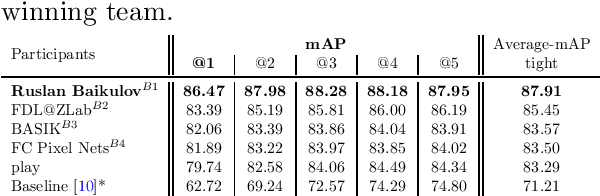
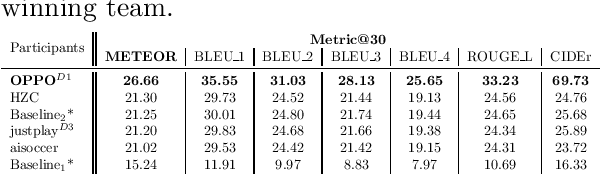
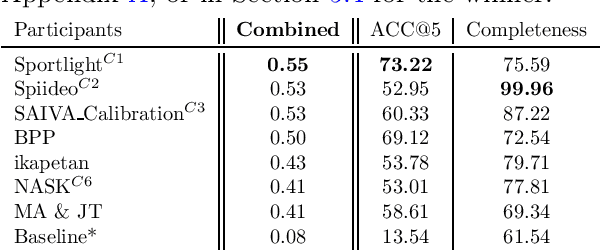
The SoccerNet 2023 challenges were the third annual video understanding challenges organized by the SoccerNet team. For this third edition, the challenges were composed of seven vision-based tasks split into three main themes. The first theme, broadcast video understanding, is composed of three high-level tasks related to describing events occurring in the video broadcasts: (1) action spotting, focusing on retrieving all timestamps related to global actions in soccer, (2) ball action spotting, focusing on retrieving all timestamps related to the soccer ball change of state, and (3) dense video captioning, focusing on describing the broadcast with natural language and anchored timestamps. The second theme, field understanding, relates to the single task of (4) camera calibration, focusing on retrieving the intrinsic and extrinsic camera parameters from images. The third and last theme, player understanding, is composed of three low-level tasks related to extracting information about the players: (5) re-identification, focusing on retrieving the same players across multiple views, (6) multiple object tracking, focusing on tracking players and the ball through unedited video streams, and (7) jersey number recognition, focusing on recognizing the jersey number of players from tracklets. Compared to the previous editions of the SoccerNet challenges, tasks (2-3-7) are novel, including new annotations and data, task (4) was enhanced with more data and annotations, and task (6) now focuses on end-to-end approaches. More information on the tasks, challenges, and leaderboards are available on https://www.soccer-net.org. Baselines and development kits can be found on https://github.com/SoccerNet.
Context-Aware 3D Object Localization from Single Calibrated Images: A Study of Basketballs
Sep 07, 2023


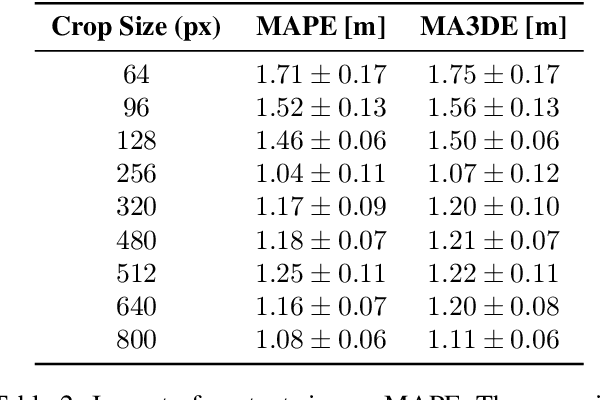
Accurately localizing objects in three dimensions (3D) is crucial for various computer vision applications, such as robotics, autonomous driving, and augmented reality. This task finds another important application in sports analytics and, in this work, we present a novel method for 3D basketball localization from a single calibrated image. Our approach predicts the object's height in pixels in image space by estimating its projection onto the ground plane within the image, leveraging the image itself and the object's location as inputs. The 3D coordinates of the ball are then reconstructed by exploiting the known projection matrix. Extensive experiments on the public DeepSport dataset, which provides ground truth annotations for 3D ball location alongside camera calibration information for each image, demonstrate the effectiveness of our method, offering substantial accuracy improvements compared to recent work. Our work opens up new possibilities for enhanced ball tracking and understanding, advancing computer vision in diverse domains. The source code of this work is made publicly available at \url{https://github.com/gabriel-vanzandycke/deepsport}.
On the Importance of Denoising when Learning to Compress Images
Jul 12, 2023
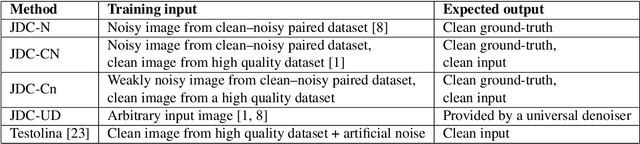

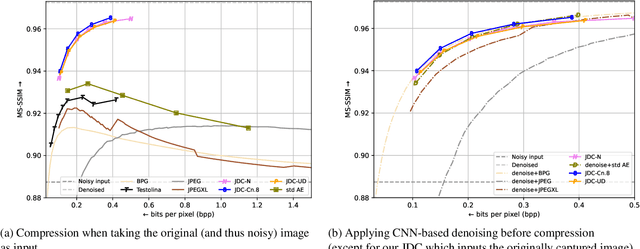
Image noise is ubiquitous in photography. However, image noise is not compressible nor desirable, thus attempting to convey the noise in compressed image bitstreams yields sub-par results in both rate and distortion. We propose to explicitly learn the image denoising task when training a codec. Therefore, we leverage the Natural Image Noise Dataset, which offers a wide variety of scenes captured with various ISO numbers, leading to different noise levels, including insignificant ones. Given this training set, we supervise the codec with noisy-clean image pairs, and show that a single model trained based on a mixture of images with variable noise levels appears to yield best-in-class results with both noisy and clean images, achieving better rate-distortion than a compression-only model or even than a pair of denoising-then-compression models with almost one order of magnitude fewer GMac operations.
An Experimental Investigation into the Evaluation of Explainability Methods
May 25, 2023



EXplainable Artificial Intelligence (XAI) aims to help users to grasp the reasoning behind the predictions of an Artificial Intelligence (AI) system. Many XAI approaches have emerged in recent years. Consequently, a subfield related to the evaluation of XAI methods has gained considerable attention, with the aim to determine which methods provide the best explanation using various approaches and criteria. However, the literature lacks a comparison of the evaluation metrics themselves, that one can use to evaluate XAI methods. This work aims to fill this gap by comparing 14 different metrics when applied to nine state-of-the-art XAI methods and three dummy methods (e.g., random saliency maps) used as references. Experimental results show which of these metrics produces highly correlated results, indicating potential redundancy. We also demonstrate the significant impact of varying the baseline hyperparameter on the evaluation metric values. Finally, we use dummy methods to assess the reliability of metrics in terms of ranking, pointing out their limitations.
Are Straight-Through gradients and Soft-Thresholding all you need for Sparse Training?
Dec 02, 2022


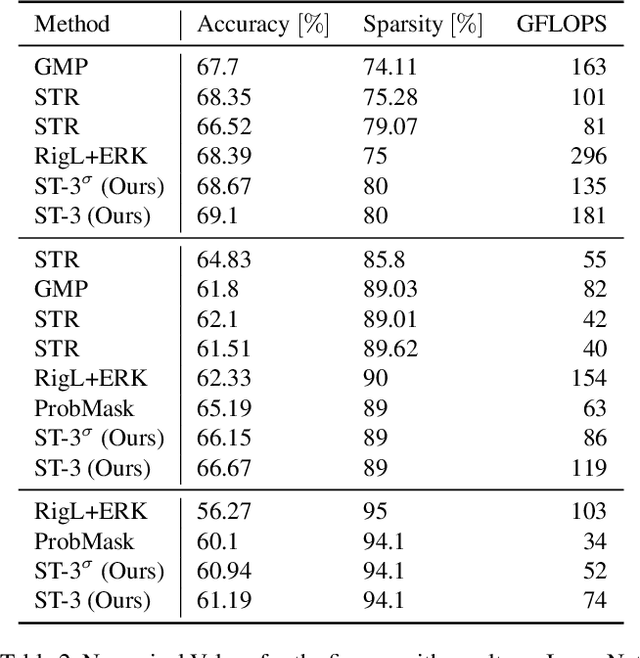
Turning the weights to zero when training a neural network helps in reducing the computational complexity at inference. To progressively increase the sparsity ratio in the network without causing sharp weight discontinuities during training, our work combines soft-thresholding and straight-through gradient estimation to update the raw, i.e. non-thresholded, version of zeroed weights. Our method, named ST-3 for straight-through/soft-thresholding/sparse-training, obtains SoA results, both in terms of accuracy/sparsity and accuracy/FLOPS trade-offs, when progressively increasing the sparsity ratio in a single training cycle. In particular, despite its simplicity, ST-3 favorably compares to the most recent methods, adopting differentiable formulations or bio-inspired neuroregeneration principles. This suggests that the key ingredients for effective sparsification primarily lie in the ability to give the weights the freedom to evolve smoothly across the zero state while progressively increasing the sparsity ratio. Source code and weights available at https://github.com/vanderschuea/stthree