 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnthony Cioppa
Multi-Stream Cellular Test-Time Adaptation of Real-Time Models Evolving in Dynamic Environments
Apr 27, 2024
In the era of the Internet of Things (IoT), objects connect through a dynamic network, empowered by technologies like 5G, enabling real-time data sharing. However, smart objects, notably autonomous vehicles, face challenges in critical local computations due to limited resources. Lightweight AI models offer a solution but struggle with diverse data distributions. To address this limitation, we propose a novel Multi-Stream Cellular Test-Time Adaptation (MSC-TTA) setup where models adapt on the fly to a dynamic environment divided into cells. Then, we propose a real-time adaptive student-teacher method that leverages the multiple streams available in each cell to quickly adapt to changing data distributions. We validate our methodology in the context of autonomous vehicles navigating across cells defined based on location and weather conditions. To facilitate future benchmarking, we release a new multi-stream large-scale synthetic semantic segmentation dataset, called DADE, and show that our multi-stream approach outperforms a single-stream baseline. We believe that our work will open research opportunities in the IoT and 5G eras, offering solutions for real-time model adaptation.
SoccerNet Game State Reconstruction: End-to-End Athlete Tracking and Identification on a Minimap
Apr 17, 2024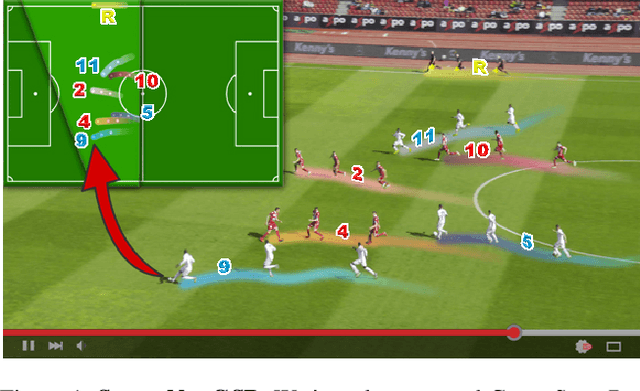
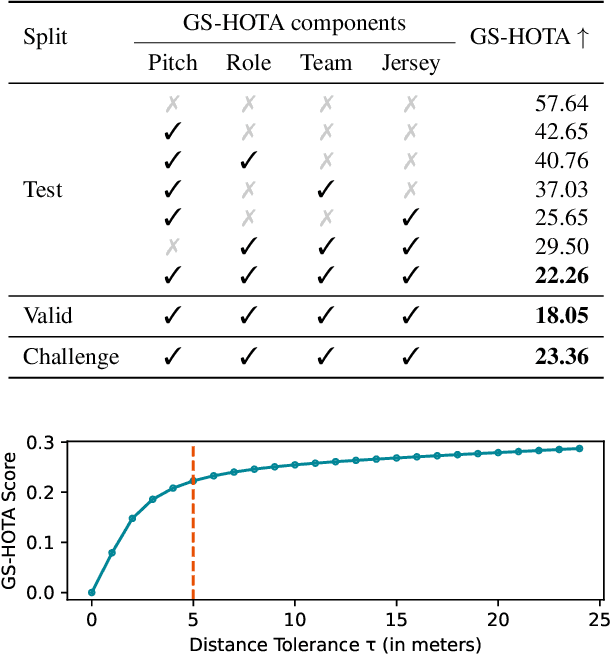
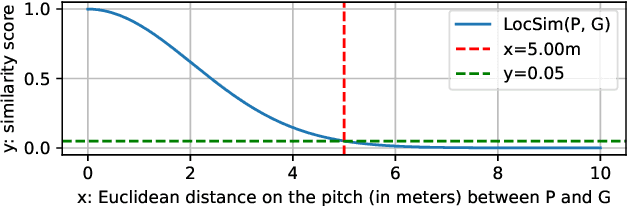

Tracking and identifying athletes on the pitch holds a central role in collecting essential insights from the game, such as estimating the total distance covered by players or understanding team tactics. This tracking and identification process is crucial for reconstructing the game state, defined by the athletes' positions and identities on a 2D top-view of the pitch, (i.e. a minimap). However, reconstructing the game state from videos captured by a single camera is challenging. It requires understanding the position of the athletes and the viewpoint of the camera to localize and identify players within the field. In this work, we formalize the task of Game State Reconstruction and introduce SoccerNet-GSR, a novel Game State Reconstruction dataset focusing on football videos. SoccerNet-GSR is composed of 200 video sequences of 30 seconds, annotated with 9.37 million line points for pitch localization and camera calibration, as well as over 2.36 million athlete positions on the pitch with their respective role, team, and jersey number. Furthermore, we introduce GS-HOTA, a novel metric to evaluate game state reconstruction methods. Finally, we propose and release an end-to-end baseline for game state reconstruction, bootstrapping the research on this task. Our experiments show that GSR is a challenging novel task, which opens the field for future research. Our dataset and codebase are publicly available at https://github.com/SoccerNet/sn-gamestate.
X-VARS: Introducing Explainability in Football Refereeing with Multi-Modal Large Language Model
Apr 07, 2024
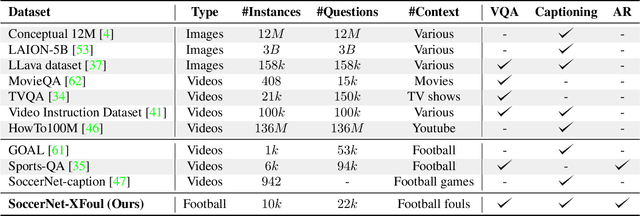
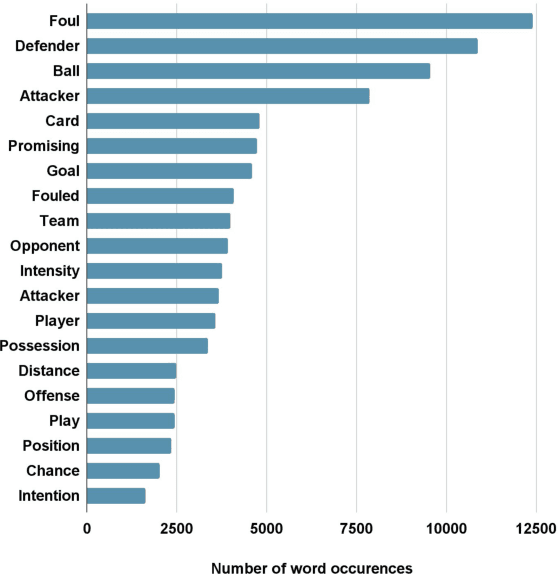

The rapid advancement of artificial intelligence has led to significant improvements in automated decision-making. However, the increased performance of models often comes at the cost of explainability and transparency of their decision-making processes. In this paper, we investigate the capabilities of large language models to explain decisions, using football refereeing as a testing ground, given its decision complexity and subjectivity. We introduce the Explainable Video Assistant Referee System, X-VARS, a multi-modal large language model designed for understanding football videos from the point of view of a referee. X-VARS can perform a multitude of tasks, including video description, question answering, action recognition, and conducting meaningful conversations based on video content and in accordance with the Laws of the Game for football referees. We validate X-VARS on our novel dataset, SoccerNet-XFoul, which consists of more than 22k video-question-answer triplets annotated by over 70 experienced football referees. Our experiments and human study illustrate the impressive capabilities of X-VARS in interpreting complex football clips. Furthermore, we highlight the potential of X-VARS to reach human performance and support football referees in the future.
Efficient Image Pre-Training with Siamese Cropped Masked Autoencoders
Mar 26, 2024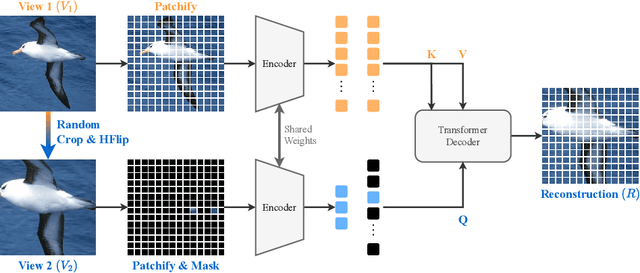
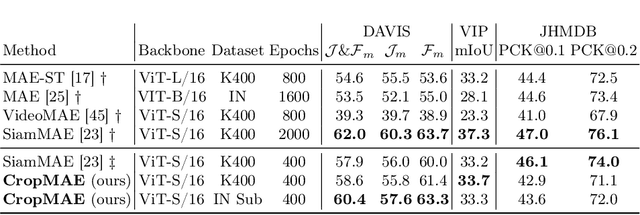

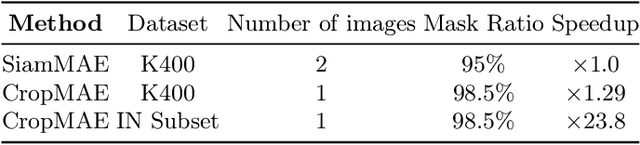
Self-supervised pre-training of image encoders is omnipresent in the literature, particularly following the introduction of Masked autoencoders (MAE). Current efforts attempt to learn object-centric representations from motion in videos. In particular, SiamMAE recently introduced a Siamese network, training a shared-weight encoder from two frames of a video with a high asymmetric masking ratio (95%). In this work, we propose CropMAE, an alternative approach to the Siamese pre-training introduced by SiamMAE. Our method specifically differs by exclusively considering pairs of cropped images sourced from the same image but cropped differently, deviating from the conventional pairs of frames extracted from a video. CropMAE therefore alleviates the need for video datasets, while maintaining competitive performances and drastically reducing pre-training time. Furthermore, we demonstrate that CropMAE learns similar object-centric representations without explicit motion, showing that current self-supervised learning methods do not learn objects from motion, but rather thanks to the Siamese architecture. Finally, CropMAE achieves the highest masking ratio to date (98.5%), enabling the reconstruction of images using only two visible patches. Our code is available at https://github.com/alexandre-eymael/CropMAE.
SoccerNet 2023 Challenges Results
Sep 12, 2023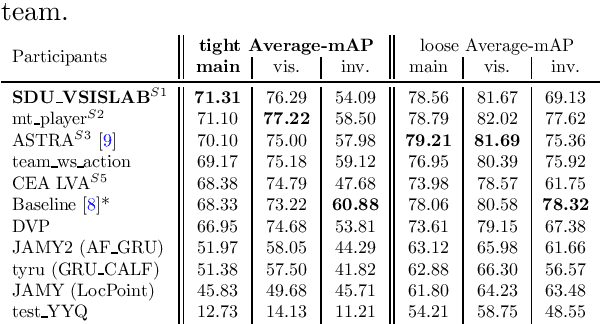
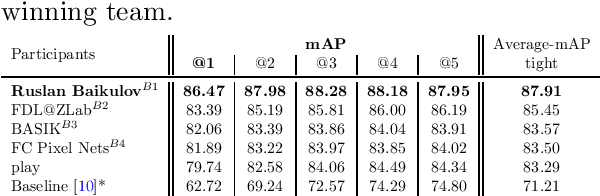
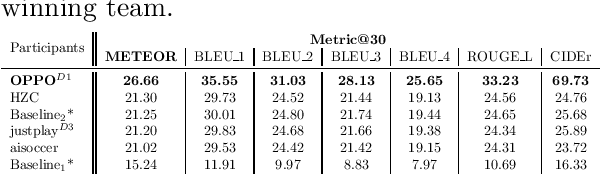
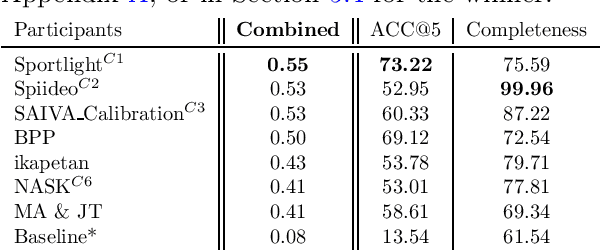
The SoccerNet 2023 challenges were the third annual video understanding challenges organized by the SoccerNet team. For this third edition, the challenges were composed of seven vision-based tasks split into three main themes. The first theme, broadcast video understanding, is composed of three high-level tasks related to describing events occurring in the video broadcasts: (1) action spotting, focusing on retrieving all timestamps related to global actions in soccer, (2) ball action spotting, focusing on retrieving all timestamps related to the soccer ball change of state, and (3) dense video captioning, focusing on describing the broadcast with natural language and anchored timestamps. The second theme, field understanding, relates to the single task of (4) camera calibration, focusing on retrieving the intrinsic and extrinsic camera parameters from images. The third and last theme, player understanding, is composed of three low-level tasks related to extracting information about the players: (5) re-identification, focusing on retrieving the same players across multiple views, (6) multiple object tracking, focusing on tracking players and the ball through unedited video streams, and (7) jersey number recognition, focusing on recognizing the jersey number of players from tracklets. Compared to the previous editions of the SoccerNet challenges, tasks (2-3-7) are novel, including new annotations and data, task (4) was enhanced with more data and annotations, and task (6) now focuses on end-to-end approaches. More information on the tasks, challenges, and leaderboards are available on https://www.soccer-net.org. Baselines and development kits can be found on https://github.com/SoccerNet.
VARS: Video Assistant Referee System for Automated Soccer Decision Making from Multiple Views
Apr 10, 2023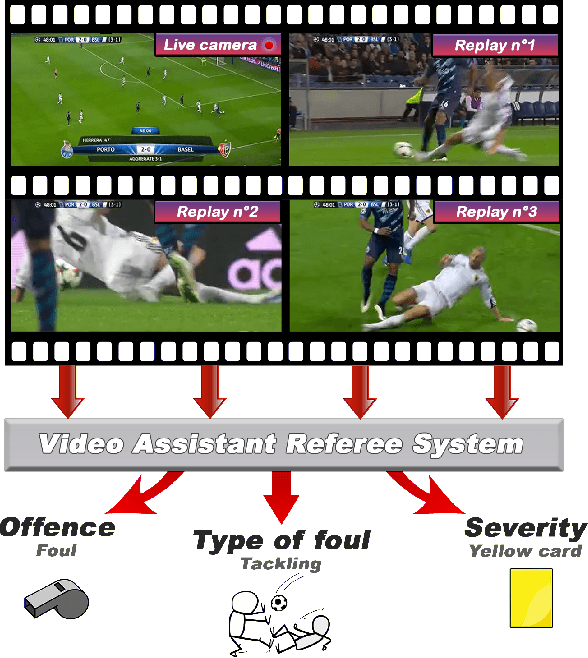


The Video Assistant Referee (VAR) has revolutionized association football, enabling referees to review incidents on the pitch, make informed decisions, and ensure fairness. However, due to the lack of referees in many countries and the high cost of the VAR infrastructure, only professional leagues can benefit from it. In this paper, we propose a Video Assistant Referee System (VARS) that can automate soccer decision-making. VARS leverages the latest findings in multi-view video analysis, to provide real-time feedback to the referee, and help them make informed decisions that can impact the outcome of a game. To validate VARS, we introduce SoccerNet-MVFoul, a novel video dataset of soccer fouls from multiple camera views, annotated with extensive foul descriptions by a professional soccer referee, and we benchmark our VARS to automatically recognize the characteristics of these fouls. We believe that VARS has the potential to revolutionize soccer refereeing and take the game to new heights of fairness and accuracy across all levels of professional and amateur federations.
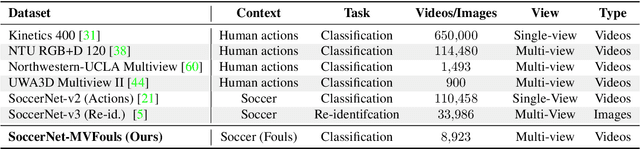
SoccerNet-Caption: Dense Video Captioning for Soccer Broadcasts Commentaries
Apr 10, 2023

Soccer is more than just a game - it is a passion that transcends borders and unites people worldwide. From the roar of the crowds to the excitement of the commentators, every moment of a soccer match is a thrill. Yet, with so many games happening simultaneously, fans cannot watch them all live. Notifications for main actions can help, but lack the engagement of live commentary, leaving fans feeling disconnected. To fulfill this need, we propose in this paper a novel task of dense video captioning focusing on the generation of textual commentaries anchored with single timestamps. To support this task, we additionally present a challenging dataset consisting of almost 37k timestamped commentaries across 715.9 hours of soccer broadcast videos. Additionally, we propose a first benchmark and baseline for this task, highlighting the difficulty of temporally anchoring commentaries yet showing the capacity to generate meaningful commentaries. By providing broadcasters with a tool to summarize the content of their video with the same level of engagement as a live game, our method could help satisfy the needs of the numerous fans who follow their team but cannot necessarily watch the live game. We believe our method has the potential to enhance the accessibility and understanding of soccer content for a wider audience, bringing the excitement of the game to more people.
Towards Active Learning for Action Spotting in Association Football Videos
Apr 09, 2023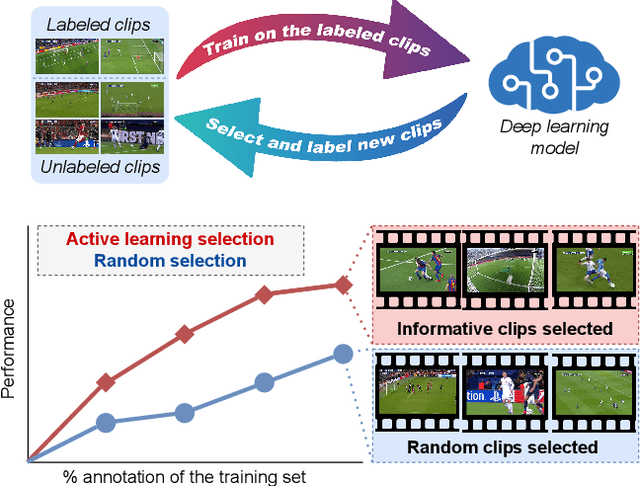
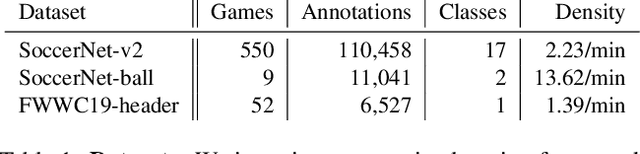
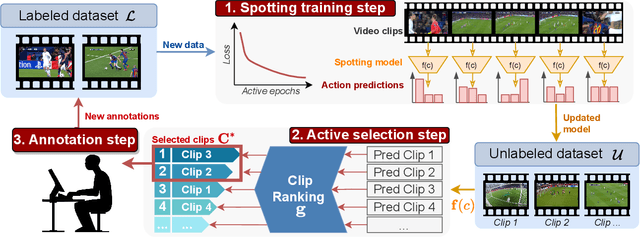

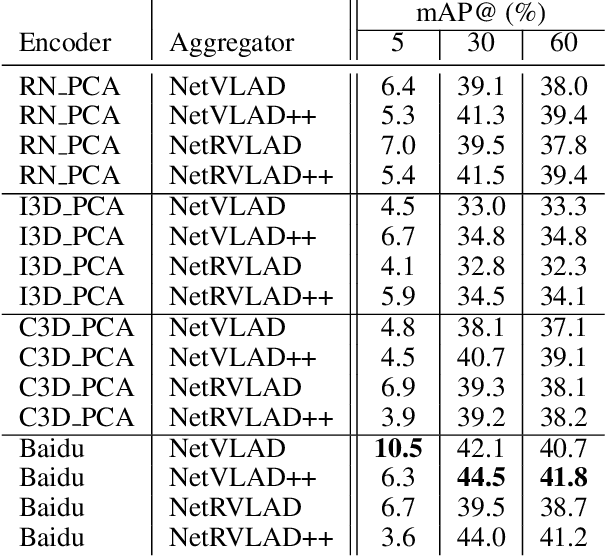
Association football is a complex and dynamic sport, with numerous actions occurring simultaneously in each game. Analyzing football videos is challenging and requires identifying subtle and diverse spatio-temporal patterns. Despite recent advances in computer vision, current algorithms still face significant challenges when learning from limited annotated data, lowering their performance in detecting these patterns. In this paper, we propose an active learning framework that selects the most informative video samples to be annotated next, thus drastically reducing the annotation effort and accelerating the training of action spotting models to reach the highest accuracy at a faster pace. Our approach leverages the notion of uncertainty sampling to select the most challenging video clips to train on next, hastening the learning process of the algorithm. We demonstrate that our proposed active learning framework effectively reduces the required training data for accurate action spotting in football videos. We achieve similar performances for action spotting with NetVLAD++ on SoccerNet-v2, using only one-third of the dataset, indicating significant capabilities for reducing annotation time and improving data efficiency. We further validate our approach on two new datasets that focus on temporally localizing actions of headers and passes, proving its effectiveness across different action semantics in football. We believe our active learning framework for action spotting would support further applications of action spotting algorithms and accelerate annotation campaigns in the sports domain.
Online Distillation with Continual Learning for Cyclic Domain Shifts
Apr 03, 2023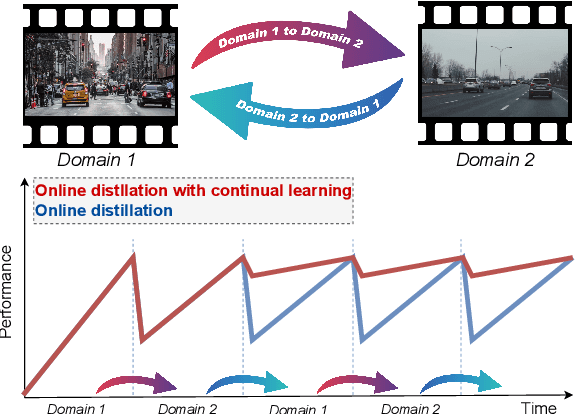
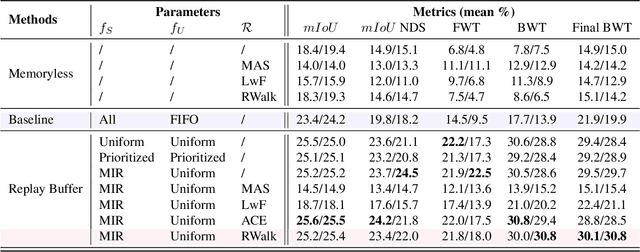


In recent years, online distillation has emerged as a powerful technique for adapting real-time deep neural networks on the fly using a slow, but accurate teacher model. However, a major challenge in online distillation is catastrophic forgetting when the domain shifts, which occurs when the student model is updated with data from the new domain and forgets previously learned knowledge. In this paper, we propose a solution to this issue by leveraging the power of continual learning methods to reduce the impact of domain shifts. Specifically, we integrate several state-of-the-art continual learning methods in the context of online distillation and demonstrate their effectiveness in reducing catastrophic forgetting. Furthermore, we provide a detailed analysis of our proposed solution in the case of cyclic domain shifts. Our experimental results demonstrate the efficacy of our approach in improving the robustness and accuracy of online distillation, with potential applications in domains such as video surveillance or autonomous driving. Overall, our work represents an important step forward in the field of online distillation and continual learning, with the potential to significantly impact real-world applications.
Mixture Domain Adaptation to Improve Semantic Segmentation in Real-World Surveillance
Nov 18, 2022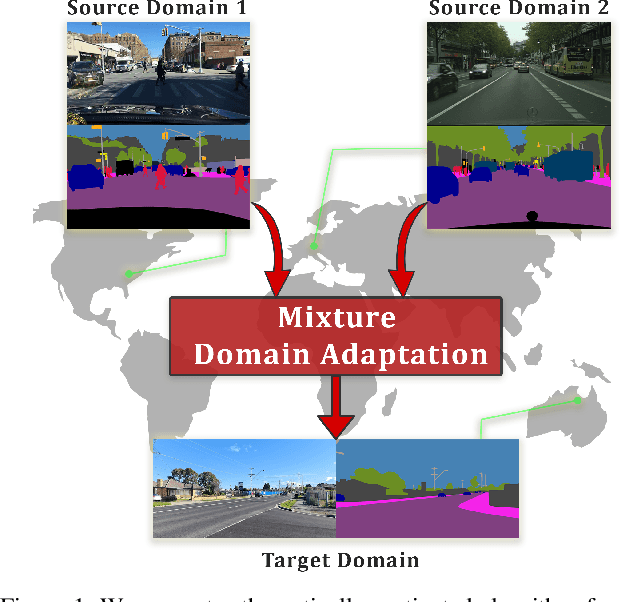
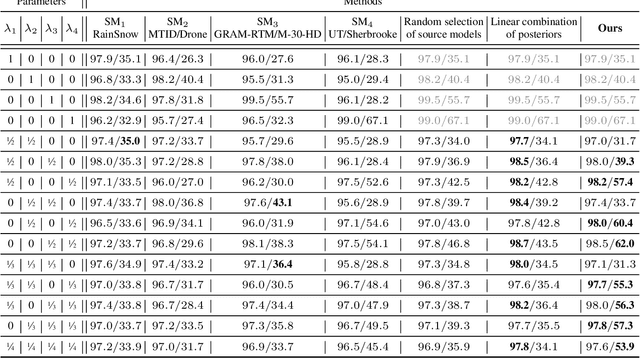
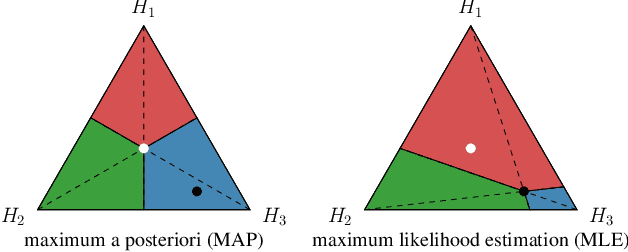
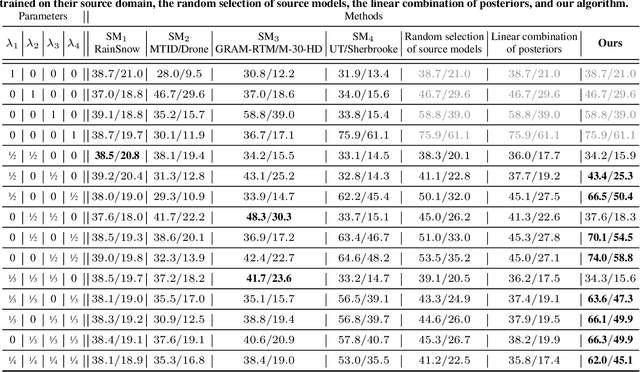
Various tasks encountered in real-world surveillance can be addressed by determining posteriors (e.g. by Bayesian inference or machine learning), based on which critical decisions must be taken. However, the surveillance domain (acquisition device, operating conditions, etc.) is often unknown, which prevents any possibility of scene-specific optimization. In this paper, we define a probabilistic framework and present a formal proof of an algorithm for the unsupervised many-to-infinity domain adaptation of posteriors. Our proposed algorithm is applicable when the probability measure associated with the target domain is a convex combination of the probability measures of the source domains. It makes use of source models and a domain discriminator model trained off-line to compute posteriors adapted on the fly to the target domain. Finally, we show the effectiveness of our algorithm for the task of semantic segmentation in real-world surveillance. The code is publicly available at https://github.com/rvandeghen/MDA.