 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKexin Zhang
Position Paper: What Can Large Language Models Tell Us about Time Series Analysis
Feb 05, 2024
Time series analysis is essential for comprehending the complexities inherent in various real-world systems and applications. Although large language models (LLMs) have recently made significant strides, the development of artificial general intelligence (AGI) equipped with time series analysis capabilities remains in its nascent phase. Most existing time series models heavily rely on domain knowledge and extensive model tuning, predominantly focusing on prediction tasks. In this paper, we argue that current LLMs have the potential to revolutionize time series analysis, thereby promoting efficient decision-making and advancing towards a more universal form of time series analytical intelligence. Such advancement could unlock a wide range of possibilities, including modality switching and time series question answering. We encourage researchers and practitioners to recognize the potential of LLMs in advancing time series analysis and emphasize the need for trust in these related efforts. Furthermore, we detail the seamless integration of time series analysis with existing LLM technologies and outline promising avenues for future research.
The Robust Semantic Segmentation UNCV2023 Challenge Results
Sep 27, 2023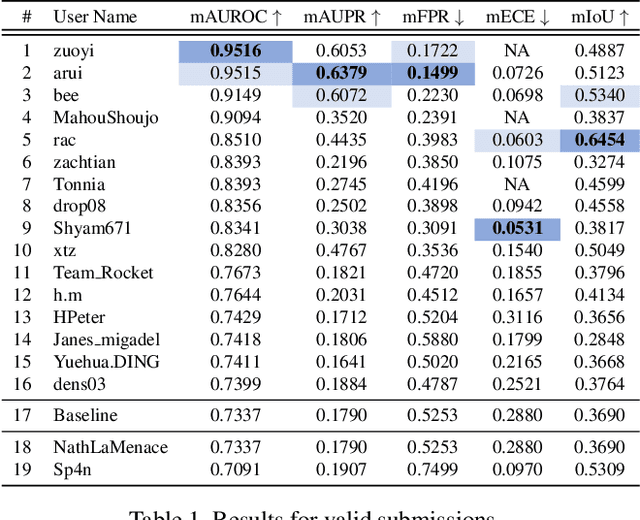
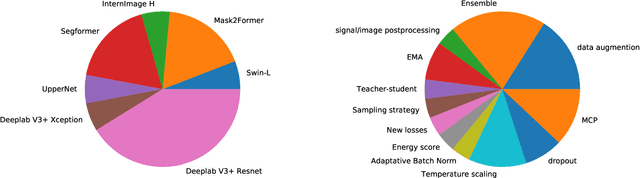

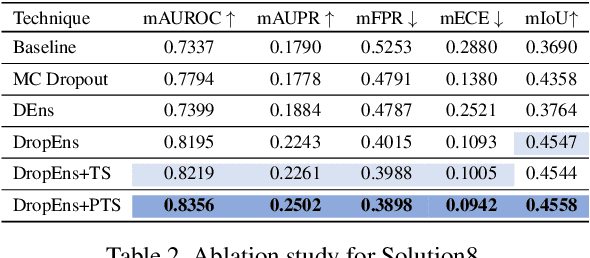
This paper outlines the winning solutions employed in addressing the MUAD uncertainty quantification challenge held at ICCV 2023. The challenge was centered around semantic segmentation in urban environments, with a particular focus on natural adversarial scenarios. The report presents the results of 19 submitted entries, with numerous techniques drawing inspiration from cutting-edge uncertainty quantification methodologies presented at prominent conferences in the fields of computer vision and machine learning and journals over the past few years. Within this document, the challenge is introduced, shedding light on its purpose and objectives, which primarily revolved around enhancing the robustness of semantic segmentation in urban scenes under varying natural adversarial conditions. The report then delves into the top-performing solutions. Moreover, the document aims to provide a comprehensive overview of the diverse solutions deployed by all participants. By doing so, it seeks to offer readers a deeper insight into the array of strategies that can be leveraged to effectively handle the inherent uncertainties associated with autonomous driving and semantic segmentation, especially within urban environments.
SoccerNet 2023 Challenges Results
Sep 12, 2023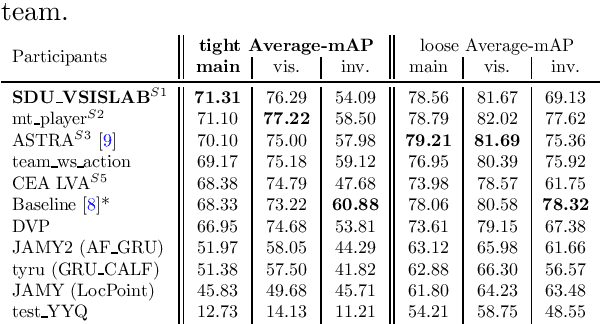
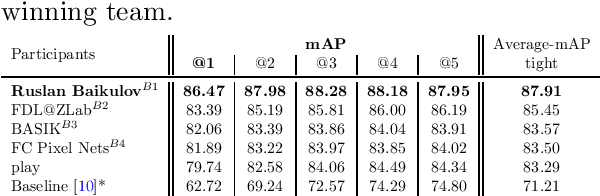
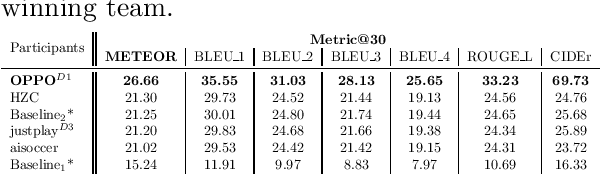
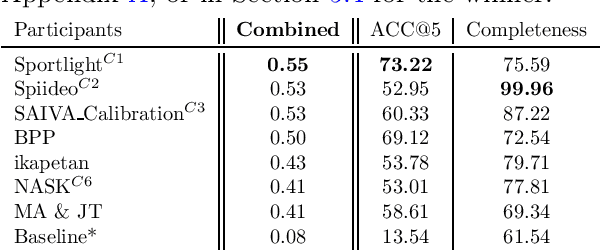
The SoccerNet 2023 challenges were the third annual video understanding challenges organized by the SoccerNet team. For this third edition, the challenges were composed of seven vision-based tasks split into three main themes. The first theme, broadcast video understanding, is composed of three high-level tasks related to describing events occurring in the video broadcasts: (1) action spotting, focusing on retrieving all timestamps related to global actions in soccer, (2) ball action spotting, focusing on retrieving all timestamps related to the soccer ball change of state, and (3) dense video captioning, focusing on describing the broadcast with natural language and anchored timestamps. The second theme, field understanding, relates to the single task of (4) camera calibration, focusing on retrieving the intrinsic and extrinsic camera parameters from images. The third and last theme, player understanding, is composed of three low-level tasks related to extracting information about the players: (5) re-identification, focusing on retrieving the same players across multiple views, (6) multiple object tracking, focusing on tracking players and the ball through unedited video streams, and (7) jersey number recognition, focusing on recognizing the jersey number of players from tracklets. Compared to the previous editions of the SoccerNet challenges, tasks (2-3-7) are novel, including new annotations and data, task (4) was enhanced with more data and annotations, and task (6) now focuses on end-to-end approaches. More information on the tasks, challenges, and leaderboards are available on https://www.soccer-net.org. Baselines and development kits can be found on https://github.com/SoccerNet.
Self-Supervised Learning for Time Series Analysis: Taxonomy, Progress, and Prospects
Jun 16, 2023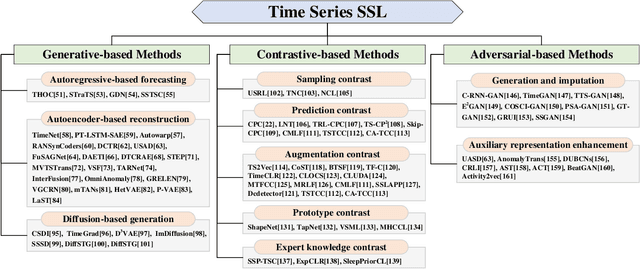
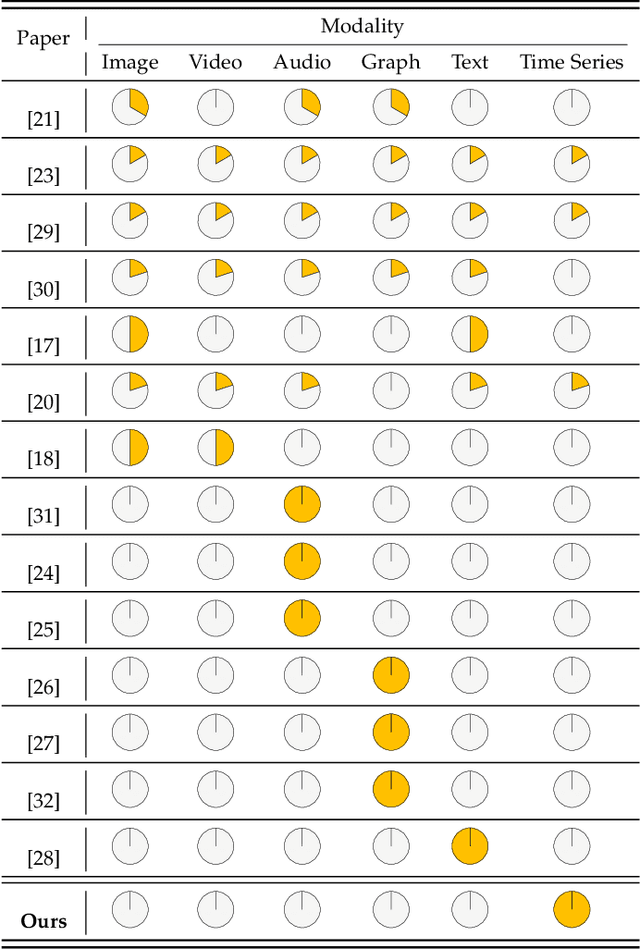
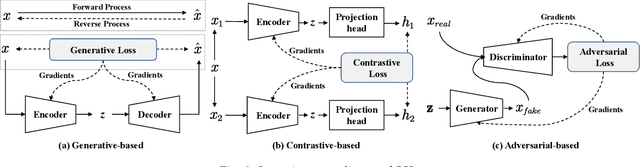
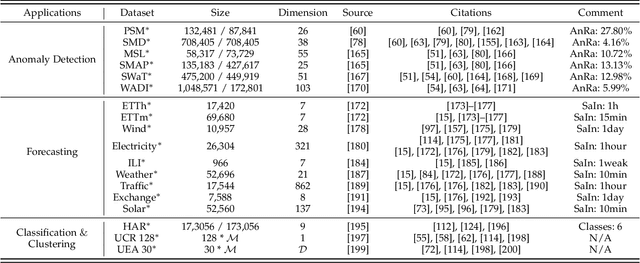
Self-supervised learning (SSL) has recently achieved impressive performance on various time series tasks. The most prominent advantage of SSL is that it reduces the dependence on labeled data. Based on the pre-training and fine-tuning strategy, even a small amount of labeled data can achieve high performance. Compared with many published self-supervised surveys on computer vision and natural language processing, a comprehensive survey for time series SSL is still missing. To fill this gap, we review current state-of-the-art SSL methods for time series data in this article. To this end, we first comprehensively review existing surveys related to SSL and time series, and then provide a new taxonomy of existing time series SSL methods. We summarize these methods into three categories: generative-based, contrastive-based, and adversarial-based. All methods can be further divided into ten subcategories. To facilitate the experiments and validation of time series SSL methods, we also summarize datasets commonly used in time series forecasting, classification, anomaly detection, and clustering tasks. Finally, we present the future directions of SSL for time series analysis.
Improve bone age assessment by learning from anatomical local regions
May 27, 2020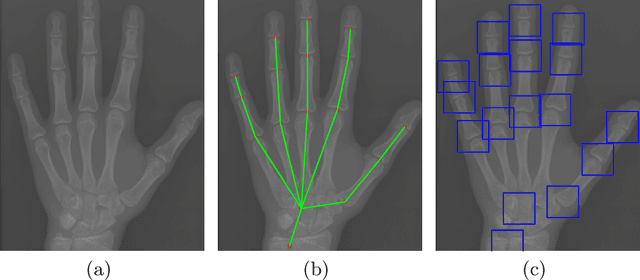

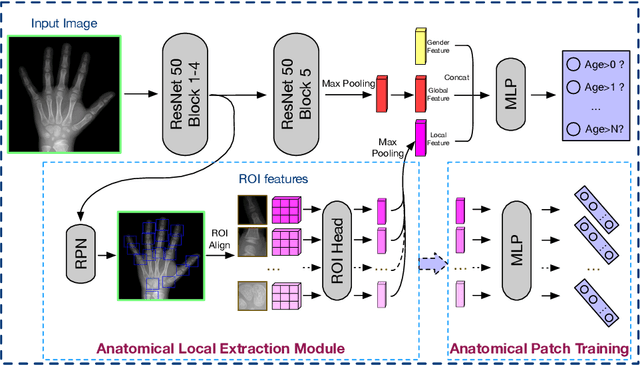
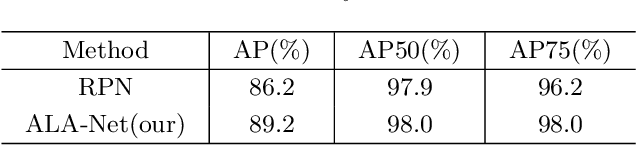
Skeletal bone age assessment (BAA), as an essential imaging examination, aims at evaluating the biological and structural maturation of human bones. In the clinical practice, Tanner and Whitehouse (TW2) method is a widely-used method for radiologists to perform BAA. The TW2 method splits the hands into Region Of Interests (ROI) and analyzes each of the anatomical ROI separately to estimate the bone age. Because of considering the analysis of local information, the TW2 method shows accurate results in practice. Following the spirit of TW2, we propose a novel model called Anatomical Local-Aware Network (ALA-Net) for automatic bone age assessment. In ALA-Net, anatomical local extraction module is introduced to learn the hand structure and extract local information. Moreover, we design an anatomical patch training strategy to provide extra regularization during the training process. Our model can detect the anatomical ROIs and estimate bone age jointly in an end-to-end manner. The experimental results show that our ALA-Net achieves a new state-of-the-art single model performance of 3.91 mean absolute error (MAE) on the public available RSNA dataset. Since the design of our model is well consistent with the well recognized TW2 method, it is interpretable and reliable for clinical usage.
FocalMix: Semi-Supervised Learning for 3D Medical Image Detection
Mar 20, 2020
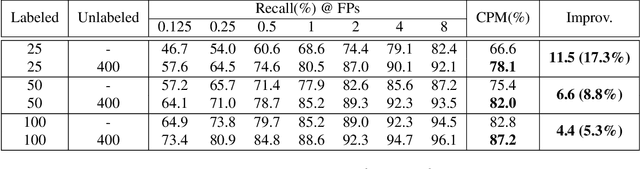
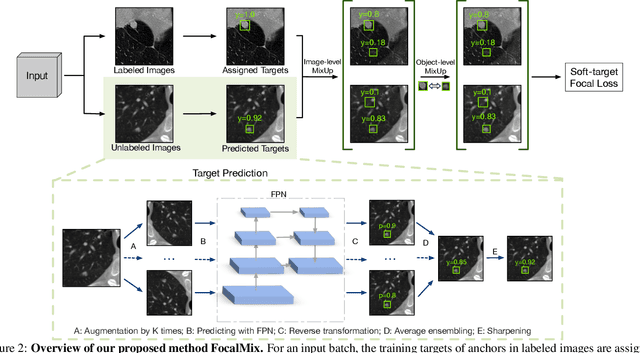
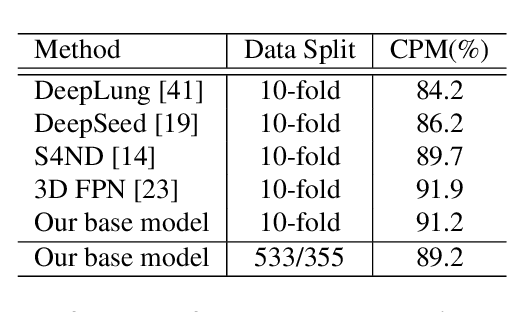
Applying artificial intelligence techniques in medical imaging is one of the most promising areas in medicine. However, most of the recent success in this area highly relies on large amounts of carefully annotated data, whereas annotating medical images is a costly process. In this paper, we propose a novel method, called FocalMix, which, to the best of our knowledge, is the first to leverage recent advances in semi-supervised learning (SSL) for 3D medical image detection. We conducted extensive experiments on two widely used datasets for lung nodule detection, LUNA16 and NLST. Results show that our proposed SSL methods can achieve a substantial improvement of up to 17.3% over state-of-the-art supervised learning approaches with 400 unlabeled CT scans.
An Approach to Super-Resolution of Sentinel-2 Images Based on Generative Adversarial Networks
Feb 07, 2020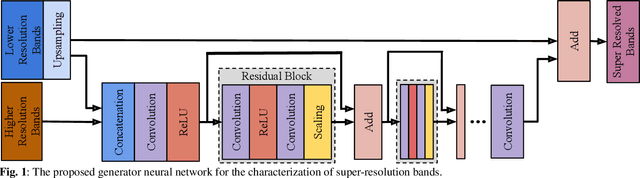

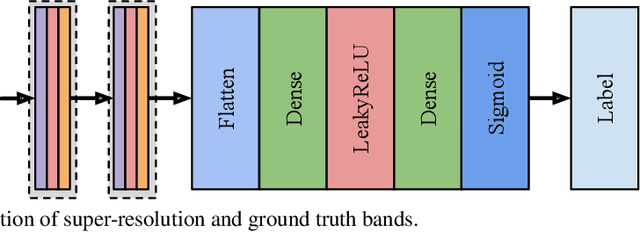

This paper presents a generative adversarial network based super-resolution (SR) approach (which is called as S2GAN) to enhance the spatial resolution of Sentinel-2 spectral bands. The proposed approach consists of two main steps. The first step aims to increase the spatial resolution of the bands with 20m and 60m spatial resolutions by the scaling factors of 2 and 6, respectively. To this end, we introduce a generator network that performs SR on the lower resolution bands with the guidance of the bands associated to 10m spatial resolution by utilizing the convolutional layers with residual connections and a long skip-connection between inputs and outputs. The second step aims to distinguish SR bands from their ground truth bands. This is achieved by the proposed discriminator network, which alternately characterizes the high level features of the two sets of bands and applying binary classification on the extracted features. Then, we formulate the adversarial learning of the generator and discriminator networks as a min-max game. In this learning procedure, the generator aims to produce realistic SR bands as much as possible so that the discriminator incorrectly classifies SR bands. Experimental results obtained on different Sentinel-2 images show the effectiveness of the proposed approach compared to both conventional and deep learning based SR approaches.
Orthogonal and Idempotent Transformations for Learning Deep Neural Networks
Jul 19, 2017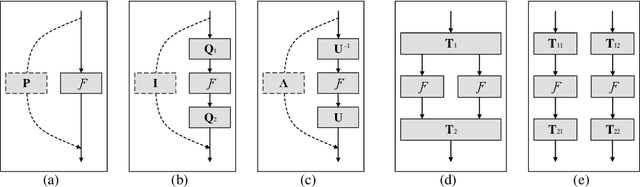
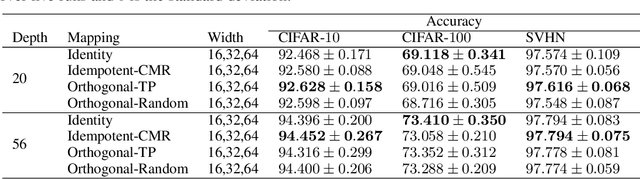
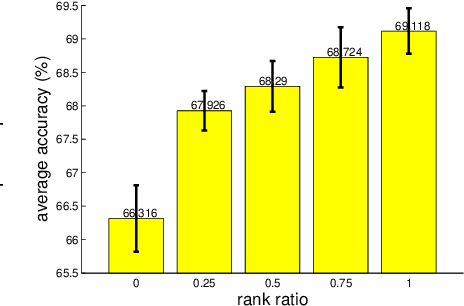
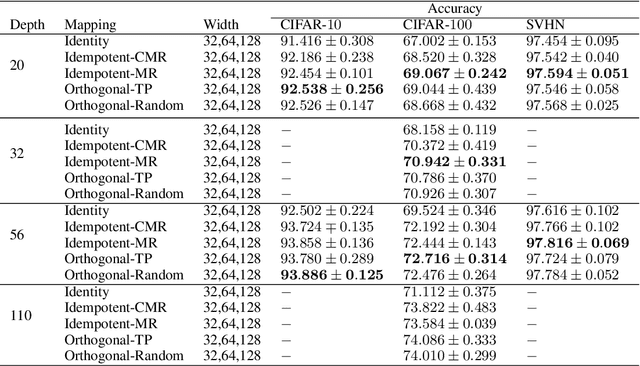
Identity transformations, used as skip-connections in residual networks, directly connect convolutional layers close to the input and those close to the output in deep neural networks, improving information flow and thus easing the training. In this paper, we introduce two alternative linear transforms, orthogonal transformation and idempotent transformation. According to the definition and property of orthogonal and idempotent matrices, the product of multiple orthogonal (same idempotent) matrices, used to form linear transformations, is equal to a single orthogonal (idempotent) matrix, resulting in that information flow is improved and the training is eased. One interesting point is that the success essentially stems from feature reuse and gradient reuse in forward and backward propagation for maintaining the information during flow and eliminating the gradient vanishing problem because of the express way through skip-connections. We empirically demonstrate the effectiveness of the proposed two transformations: similar performance in single-branch networks and even superior in multi-branch networks in comparison to identity transformations.