 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMingtian Zhang
Mafin: Enhancing Black-Box Embeddings with Model Augmented Fine-Tuning
Feb 26, 2024
Retrieval Augmented Generation (RAG) has emerged as an effective solution for mitigating hallucinations in Large Language Models (LLMs). The retrieval stage in RAG typically involves a pre-trained embedding model, which converts queries and passages into vectors to capture their semantics. However, a standard pre-trained embedding model may exhibit sub-optimal performance when applied to specific domain knowledge, necessitating fine-tuning. This paper addresses scenarios where the embeddings are only available from a black-box model. We introduce Model augmented fine-tuning (Mafin) -- a novel approach for fine-tuning a black-box embedding model by augmenting it with a trainable embedding model. Our results demonstrate that Mafin significantly enhances the performance of the black-box embeddings by only requiring the training of a small augmented model. We validate the effectiveness of our method on both labeled and unlabeled datasets, illustrating its broad applicability and efficiency.
Active Preference Learning for Large Language Models
Feb 12, 2024As large language models (LLMs) become more capable, fine-tuning techniques for aligning with human intent are increasingly important. A key consideration for aligning these models is how to most effectively use human resources, or model resources in the case where LLMs themselves are used as oracles. Reinforcement learning from Human or AI preferences (RLHF/RLAIF) is the most prominent example of such a technique, but is complex and often unstable. Direct Preference Optimization (DPO) has recently been proposed as a simpler and more stable alternative. In this work, we develop an active learning strategy for DPO to make better use of preference labels. We propose a practical acquisition function for prompt/completion pairs based on the predictive entropy of the language model and a measure of certainty of the implicit preference model optimized by DPO. We demonstrate how our approach improves both the rate of learning and final performance of fine-tuning on pairwise preference data.
Diffusive Gibbs Sampling
Feb 05, 2024The inadequate mixing of conventional Markov Chain Monte Carlo (MCMC) methods for multi-modal distributions presents a significant challenge in practical applications such as Bayesian inference and molecular dynamics. Addressing this, we propose Diffusive Gibbs Sampling (DiGS), an innovative family of sampling methods designed for effective sampling from distributions characterized by distant and disconnected modes. DiGS integrates recent developments in diffusion models, leveraging Gaussian convolution to create an auxiliary noisy distribution that bridges isolated modes in the original space and applying Gibbs sampling to alternately draw samples from both spaces. Our approach exhibits a better mixing property for sampling multi-modal distributions than state-of-the-art methods such as parallel tempering. We demonstrate that our sampler attains substantially improved results across various tasks, including mixtures of Gaussians, Bayesian neural networks and molecular dynamics.
Incorporating Neuro-Inspired Adaptability for Continual Learning in Artificial Intelligence
Aug 29, 2023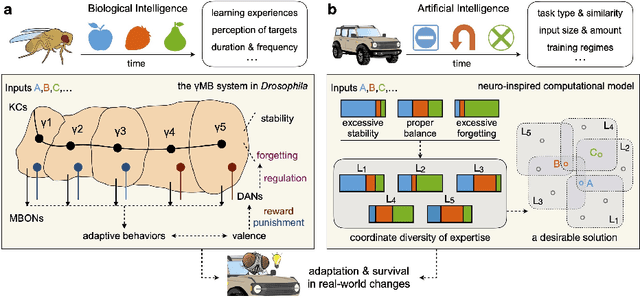
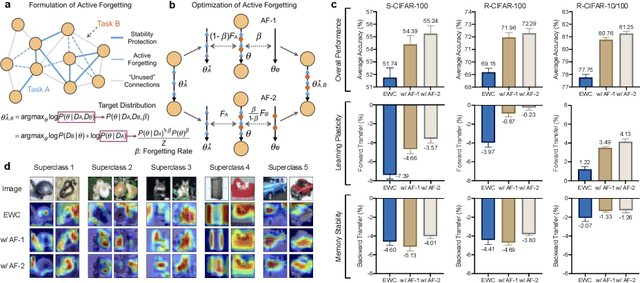
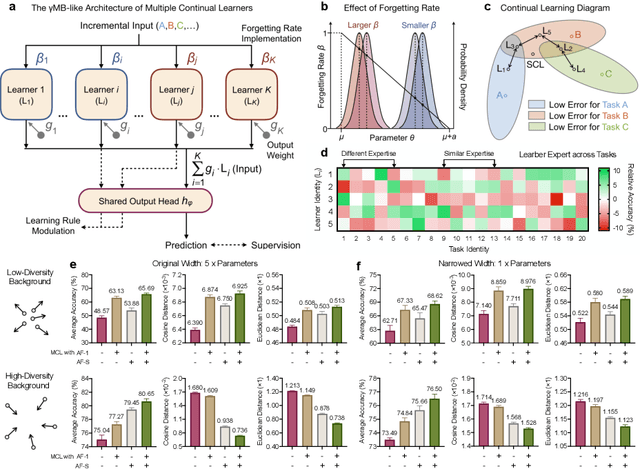
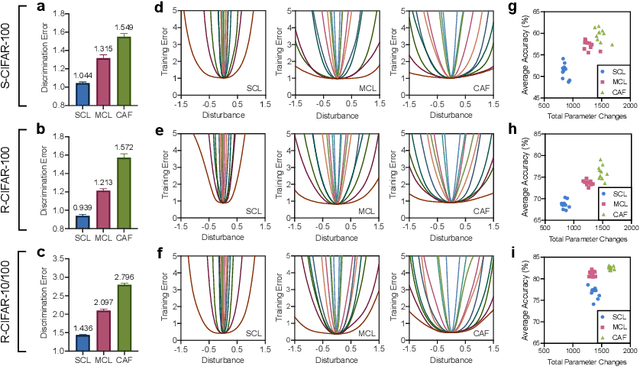
Continual learning aims to empower artificial intelligence (AI) with strong adaptability to the real world. For this purpose, a desirable solution should properly balance memory stability with learning plasticity, and acquire sufficient compatibility to capture the observed distributions. Existing advances mainly focus on preserving memory stability to overcome catastrophic forgetting, but remain difficult to flexibly accommodate incremental changes as biological intelligence (BI) does. By modeling a robust Drosophila learning system that actively regulates forgetting with multiple learning modules, here we propose a generic approach that appropriately attenuates old memories in parameter distributions to improve learning plasticity, and accordingly coordinates a multi-learner architecture to ensure solution compatibility. Through extensive theoretical and empirical validation, our approach not only clearly enhances the performance of continual learning, especially over synaptic regularization methods in task-incremental settings, but also potentially advances the understanding of neurological adaptive mechanisms, serving as a novel paradigm to progress AI and BI together.
Moment Matching Denoising Gibbs Sampling
May 19, 2023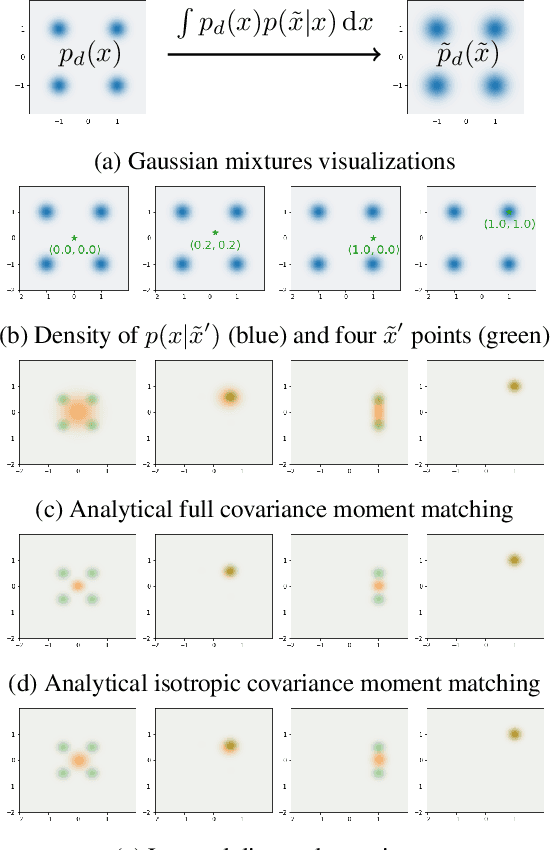
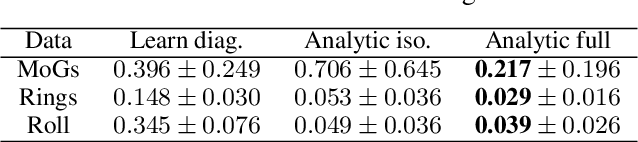


Energy-Based Models (EBMs) offer a versatile framework for modeling complex data distributions. However, training and sampling from EBMs continue to pose significant challenges. The widely-used Denoising Score Matching (DSM) method for scalable EBM training suffers from inconsistency issues, causing the energy model to learn a `noisy' data distribution. In this work, we propose an efficient sampling framework: (pseudo)-Gibbs sampling with moment matching, which enables effective sampling from the underlying clean model when given a `noisy' model that has been well-trained via DSM. We explore the benefits of our approach compared to related methods and demonstrate how to scale the method to high-dimensional datasets.
Towards Healing the Blindness of Score Matching
Sep 15, 2022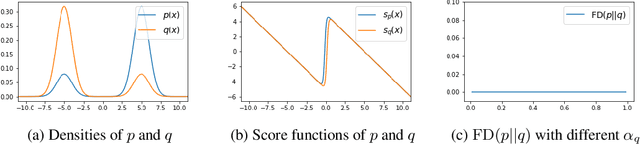
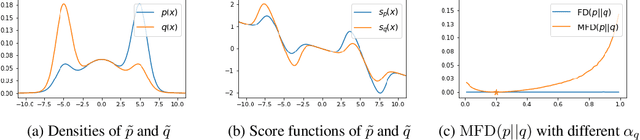
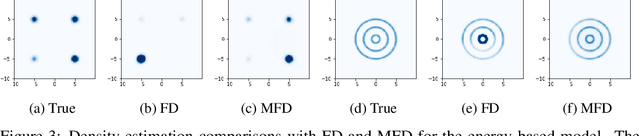
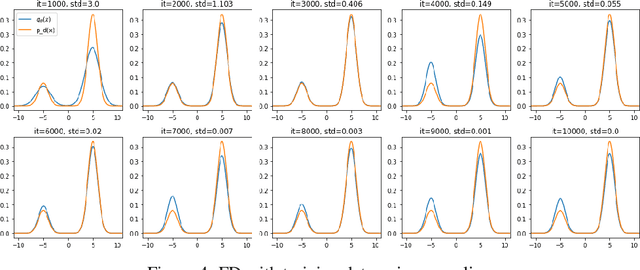
Score-based divergences have been widely used in machine learning and statistics applications. Despite their empirical success, a blindness problem has been observed when using these for multi-modal distributions. In this work, we discuss the blindness problem and propose a new family of divergences that can mitigate the blindness problem. We illustrate our proposed divergence in the context of density estimation and report improved performance compared to traditional approaches.
Integrated Weak Learning
Jun 19, 2022



We introduce Integrated Weak Learning, a principled framework that integrates weak supervision into the training process of machine learning models. Our approach jointly trains the end-model and a label model that aggregates multiple sources of weak supervision. We introduce a label model that can learn to aggregate weak supervision sources differently for different datapoints and takes into consideration the performance of the end-model during training. We show that our approach outperforms existing weak learning techniques across a set of 6 benchmark classification datasets. When both a small amount of labeled data and weak supervision are present the increase in performance is both consistent and large, reliably getting a 2-5 point test F1 score gain over non-integrated methods.
Out-of-Distribution Detection with Class Ratio Estimation
Jun 08, 2022



Density-based Out-of-distribution (OOD) detection has recently been shown unreliable for the task of detecting OOD images. Various density ratio based approaches achieve good empirical performance, however methods typically lack a principled probabilistic modelling explanation. In this work, we propose to unify density ratio based methods under a novel framework that builds energy-based models and employs differing base distributions. Under our framework, the density ratio can be viewed as the unnormalized density of an implicit semantic distribution. Further, we propose to directly estimate the density ratio of a data sample through class ratio estimation. We report competitive results on OOD image problems in comparison with recent work that alternatively requires training of deep generative models for the task. Our approach enables a simple and yet effective path towards solving the OOD detection problem.
Improving VAE-based Representation Learning
May 28, 2022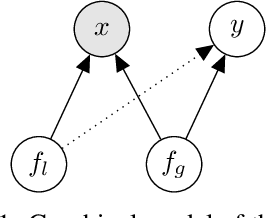

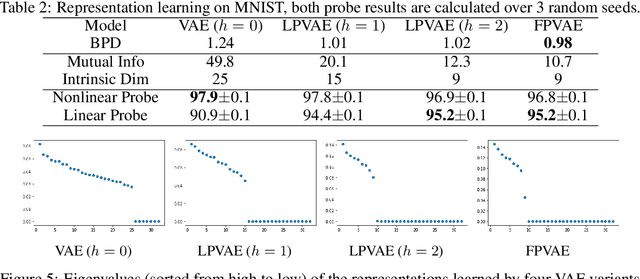
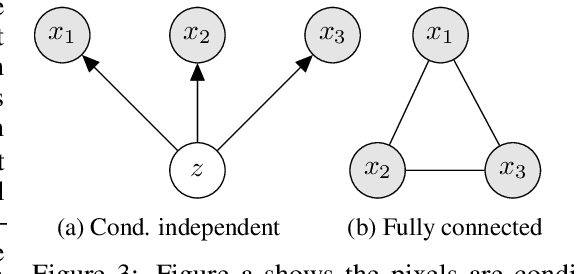
Latent variable models like the Variational Auto-Encoder (VAE) are commonly used to learn representations of images. However, for downstream tasks like semantic classification, the representations learned by VAE are less competitive than other non-latent variable models. This has led to some speculations that latent variable models may be fundamentally unsuitable for representation learning. In this work, we study what properties are required for good representations and how different VAE structure choices could affect the learned properties. We show that by using a decoder that prefers to learn local features, the remaining global features can be well captured by the latent, which significantly improves performance of a downstream classification task. We further apply the proposed model to semi-supervised learning tasks and demonstrate improvements in data efficiency.
Generalization Gap in Amortized Inference
May 23, 2022

The ability of likelihood-based probabilistic models to generalize to unseen data is central to many machine learning applications such as lossless compression. In this work, we study the generalizations of a popular class of probabilistic models - the Variational Auto-Encoder (VAE). We point out the two generalization gaps that can affect the generalization ability of VAEs and show that the over-fitting phenomenon is usually dominated by the amortized inference network. Based on this observation we propose a new training objective, inspired by the classic wake-sleep algorithm, to improve the generalizations properties of amortized inference. We also demonstrate how it can improve generalization performance in the context of image modeling and lossless compression.