 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYuhang Zheng
TOD3Cap: Towards 3D Dense Captioning in Outdoor Scenes
Mar 28, 2024
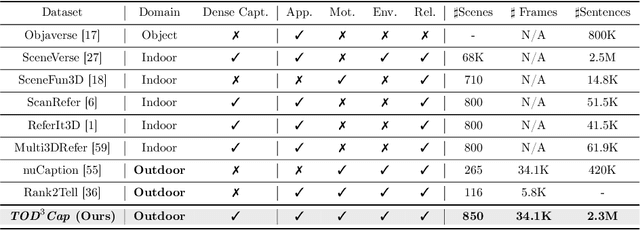
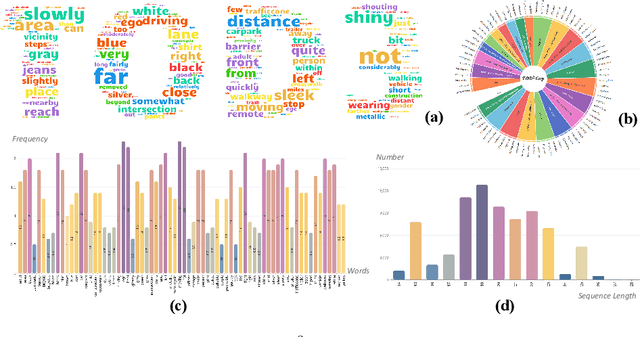
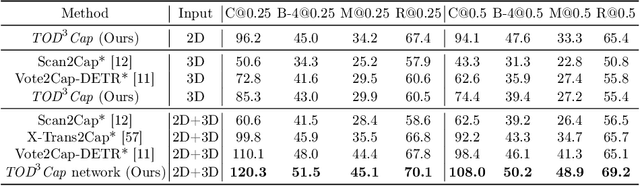
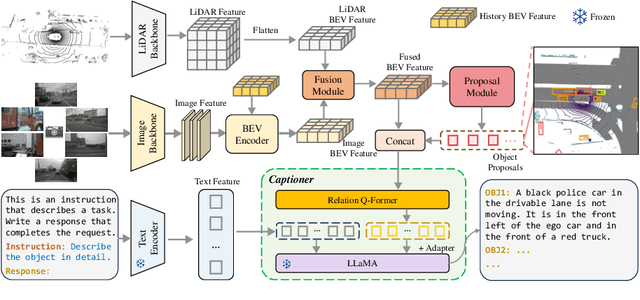
3D dense captioning stands as a cornerstone in achieving a comprehensive understanding of 3D scenes through natural language. It has recently witnessed remarkable achievements, particularly in indoor settings. However, the exploration of 3D dense captioning in outdoor scenes is hindered by two major challenges: 1) the \textbf{domain gap} between indoor and outdoor scenes, such as dynamics and sparse visual inputs, makes it difficult to directly adapt existing indoor methods; 2) the \textbf{lack of data} with comprehensive box-caption pair annotations specifically tailored for outdoor scenes. To this end, we introduce the new task of outdoor 3D dense captioning. As input, we assume a LiDAR point cloud and a set of RGB images captured by the panoramic camera rig. The expected output is a set of object boxes with captions. To tackle this task, we propose the TOD3Cap network, which leverages the BEV representation to generate object box proposals and integrates Relation Q-Former with LLaMA-Adapter to generate rich captions for these objects. We also introduce the TOD3Cap dataset, the largest one to our knowledge for 3D dense captioning in outdoor scenes, which contains 2.3M descriptions of 64.3K outdoor objects from 850 scenes. Notably, our TOD3Cap network can effectively localize and caption 3D objects in outdoor scenes, which outperforms baseline methods by a significant margin (+9.6 CiDEr@0.5IoU). Code, data, and models are publicly available at https://github.com/jxbbb/TOD3Cap.
GaussianGrasper: 3D Language Gaussian Splatting for Open-vocabulary Robotic Grasping
Mar 14, 2024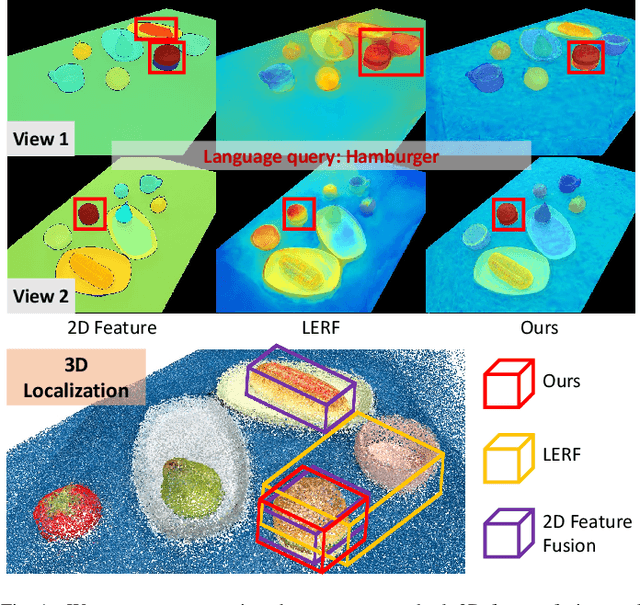
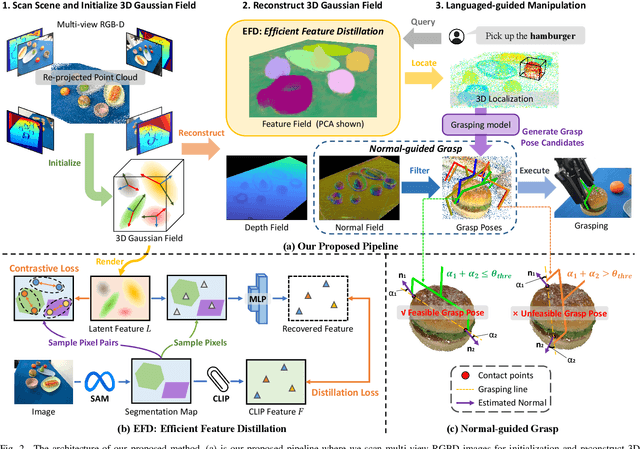
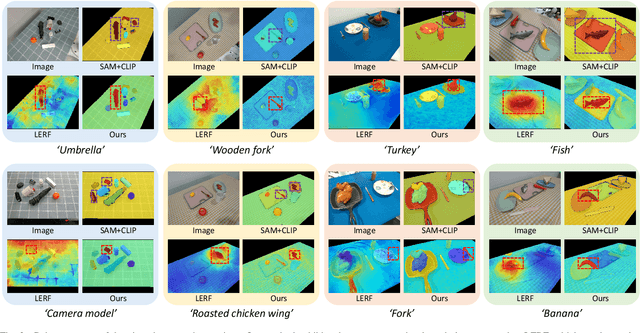

Constructing a 3D scene capable of accommodating open-ended language queries, is a pivotal pursuit, particularly within the domain of robotics. Such technology facilitates robots in executing object manipulations based on human language directives. To tackle this challenge, some research efforts have been dedicated to the development of language-embedded implicit fields. However, implicit fields (e.g. NeRF) encounter limitations due to the necessity of processing a large number of input views for reconstruction, coupled with their inherent inefficiencies in inference. Thus, we present the GaussianGrasper, which utilizes 3D Gaussian Splatting to explicitly represent the scene as a collection of Gaussian primitives. Our approach takes a limited set of RGB-D views and employs a tile-based splatting technique to create a feature field. In particular, we propose an Efficient Feature Distillation (EFD) module that employs contrastive learning to efficiently and accurately distill language embeddings derived from foundational models. With the reconstructed geometry of the Gaussian field, our method enables the pre-trained grasping model to generate collision-free grasp pose candidates. Furthermore, we propose a normal-guided grasp module to select the best grasp pose. Through comprehensive real-world experiments, we demonstrate that GaussianGrasper enables robots to accurately query and grasp objects with language instructions, providing a new solution for language-guided manipulation tasks. Data and codes can be available at https://github.com/MrSecant/GaussianGrasper.
MonoOcc: Digging into Monocular Semantic Occupancy Prediction
Mar 13, 2024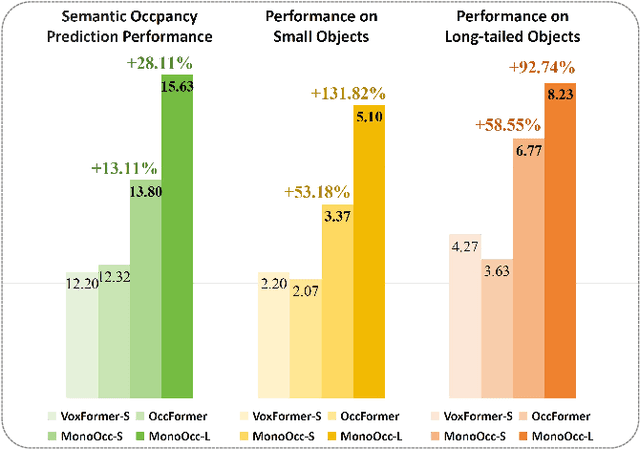
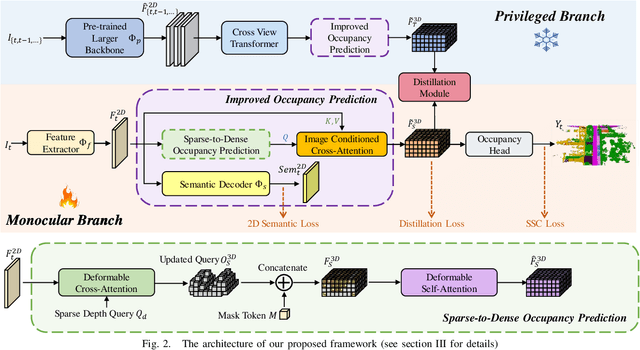
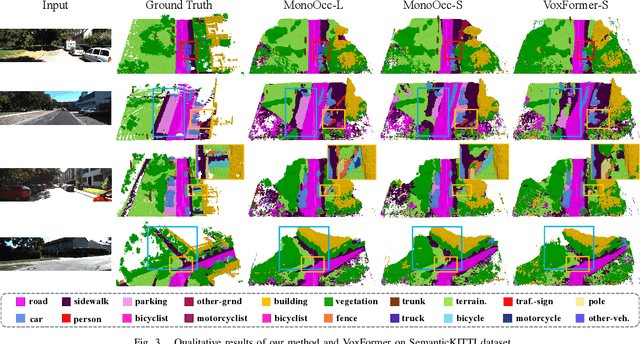
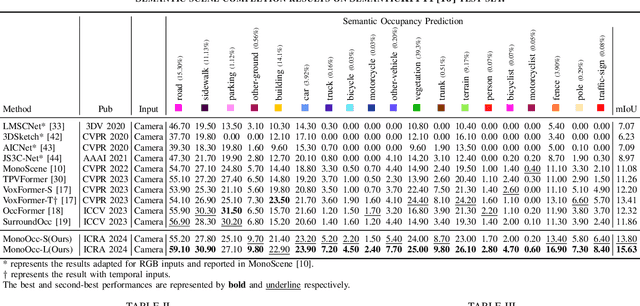
Monocular Semantic Occupancy Prediction aims to infer the complete 3D geometry and semantic information of scenes from only 2D images. It has garnered significant attention, particularly due to its potential to enhance the 3D perception of autonomous vehicles. However, existing methods rely on a complex cascaded framework with relatively limited information to restore 3D scenes, including a dependency on supervision solely on the whole network's output, single-frame input, and the utilization of a small backbone. These challenges, in turn, hinder the optimization of the framework and yield inferior prediction results, particularly concerning smaller and long-tailed objects. To address these issues, we propose MonoOcc. In particular, we (i) improve the monocular occupancy prediction framework by proposing an auxiliary semantic loss as supervision to the shallow layers of the framework and an image-conditioned cross-attention module to refine voxel features with visual clues, and (ii) employ a distillation module that transfers temporal information and richer knowledge from a larger image backbone to the monocular semantic occupancy prediction framework with low cost of hardware. With these advantages, our method yields state-of-the-art performance on the camera-based SemanticKITTI Scene Completion benchmark. Codes and models can be accessed at https://github.com/ucaszyp/MonoOcc
Adaptive Surface Normal Constraint for Geometric Estimation from Monocular Images
Feb 08, 2024We introduce a novel approach to learn geometries such as depth and surface normal from images while incorporating geometric context. The difficulty of reliably capturing geometric context in existing methods impedes their ability to accurately enforce the consistency between the different geometric properties, thereby leading to a bottleneck of geometric estimation quality. We therefore propose the Adaptive Surface Normal (ASN) constraint, a simple yet efficient method. Our approach extracts geometric context that encodes the geometric variations present in the input image and correlates depth estimation with geometric constraints. By dynamically determining reliable local geometry from randomly sampled candidates, we establish a surface normal constraint, where the validity of these candidates is evaluated using the geometric context. Furthermore, our normal estimation leverages the geometric context to prioritize regions that exhibit significant geometric variations, which makes the predicted normals accurately capture intricate and detailed geometric information. Through the integration of geometric context, our method unifies depth and surface normal estimations within a cohesive framework, which enables the generation of high-quality 3D geometry from images. We validate the superiority of our approach over state-of-the-art methods through extensive evaluations and comparisons on diverse indoor and outdoor datasets, showcasing its efficiency and robustness.
Improving Data Augmentation for Robust Visual Question Answering with Effective Curriculum Learning
Jan 28, 2024Being widely used in learning unbiased visual question answering (VQA) models, Data Augmentation (DA) helps mitigate language biases by generating extra training samples beyond the original samples. While today's DA methods can generate robust samples, the augmented training set, significantly larger than the original dataset, often exhibits redundancy in terms of difficulty or content repetition, leading to inefficient model training and even compromising the model performance. To this end, we design an Effective Curriculum Learning strategy ECL to enhance DA-based VQA methods. Intuitively, ECL trains VQA models on relatively ``easy'' samples first, and then gradually changes to ``harder'' samples, and less-valuable samples are dynamically removed. Compared to training on the entire augmented dataset, our ECL strategy can further enhance VQA models' performance with fewer training samples. Extensive ablations have demonstrated the effectiveness of ECL on various methods.
3D Implicit Transporter for Temporally Consistent Keypoint Discovery
Sep 10, 2023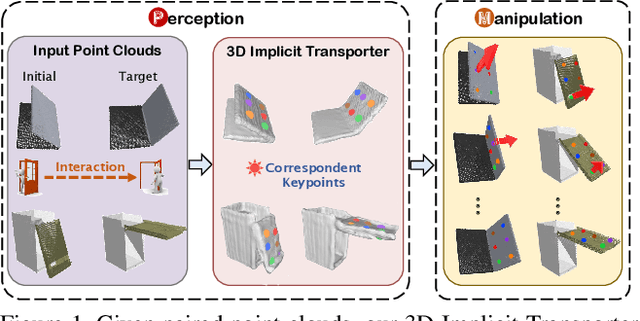


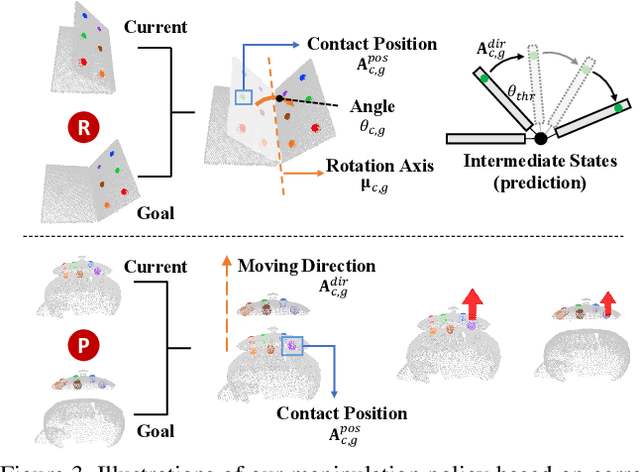
Keypoint-based representation has proven advantageous in various visual and robotic tasks. However, the existing 2D and 3D methods for detecting keypoints mainly rely on geometric consistency to achieve spatial alignment, neglecting temporal consistency. To address this issue, the Transporter method was introduced for 2D data, which reconstructs the target frame from the source frame to incorporate both spatial and temporal information. However, the direct application of the Transporter to 3D point clouds is infeasible due to their structural differences from 2D images. Thus, we propose the first 3D version of the Transporter, which leverages hybrid 3D representation, cross attention, and implicit reconstruction. We apply this new learning system on 3D articulated objects and nonrigid animals (humans and rodents) and show that learned keypoints are spatio-temporally consistent. Additionally, we propose a closed-loop control strategy that utilizes the learned keypoints for 3D object manipulation and demonstrate its superior performance. Codes are available at https://github.com/zhongcl-thu/3D-Implicit-Transporter.
ECT: Fine-grained Edge Detection with Learned Cause Tokens
Aug 06, 2023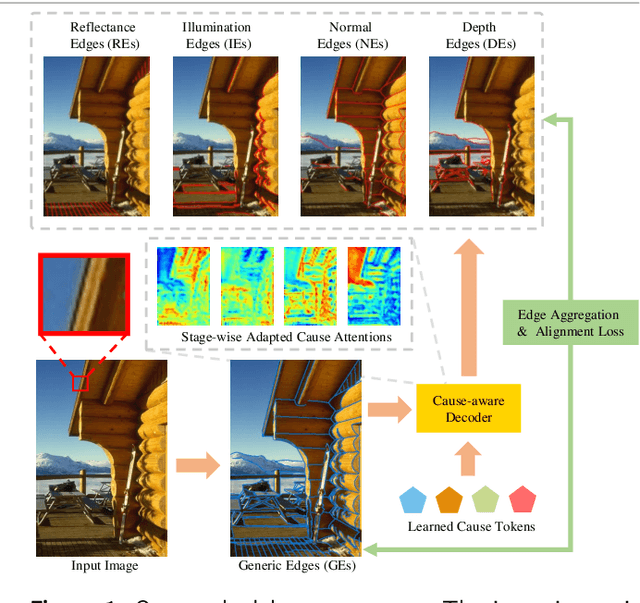

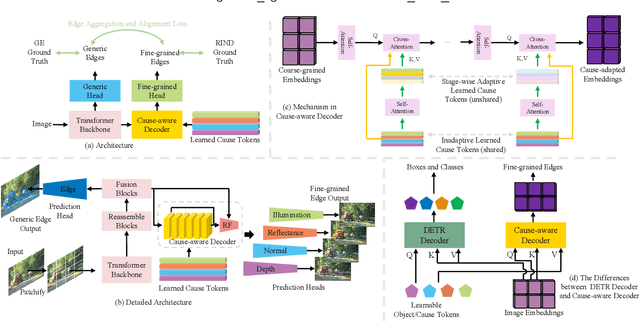

In this study, we tackle the challenging fine-grained edge detection task, which refers to predicting specific edges caused by reflectance, illumination, normal, and depth changes, respectively. Prior methods exploit multi-scale convolutional networks, which are limited in three aspects: (1) Convolutions are local operators while identifying the cause of edge formation requires looking at far away pixels. (2) Priors specific to edge cause are fixed in prediction heads. (3) Using separate networks for generic and fine-grained edge detection, and the constraint between them may be violated. To address these three issues, we propose a two-stage transformer-based network sequentially predicting generic edges and fine-grained edges, which has a global receptive field thanks to the attention mechanism. The prior knowledge of edge causes is formulated as four learnable cause tokens in a cause-aware decoder design. Furthermore, to encourage the consistency between generic edges and fine-grained edges, an edge aggregation and alignment loss is exploited. We evaluate our method on the public benchmark BSDS-RIND and several newly derived benchmarks, and achieve new state-of-the-art results. Our code, data, and models are publicly available at https://github.com/Daniellli/ECT.git.
DPF: Learning Dense Prediction Fields with Weak Supervision
Mar 29, 2023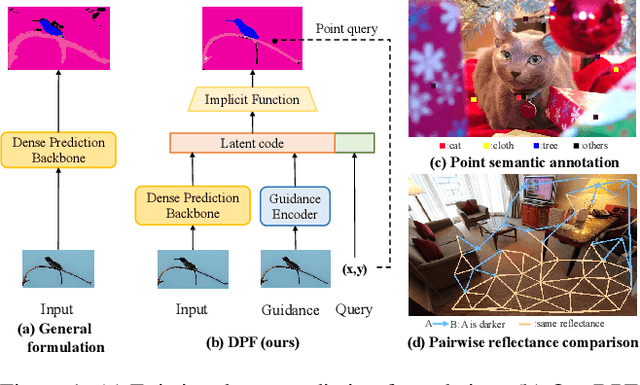
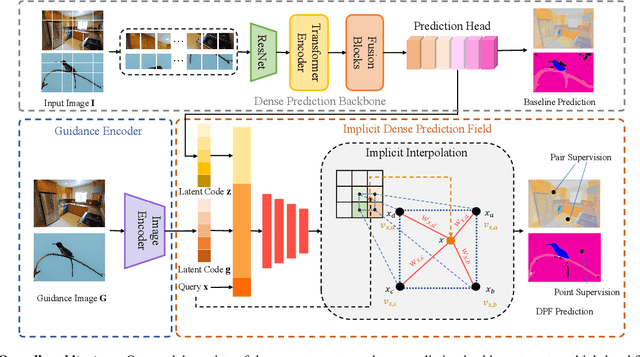

Nowadays, many visual scene understanding problems are addressed by dense prediction networks. But pixel-wise dense annotations are very expensive (e.g., for scene parsing) or impossible (e.g., for intrinsic image decomposition), motivating us to leverage cheap point-level weak supervision. However, existing pointly-supervised methods still use the same architecture designed for full supervision. In stark contrast to them, we propose a new paradigm that makes predictions for point coordinate queries, as inspired by the recent success of implicit representations, like distance or radiance fields. As such, the method is named as dense prediction fields (DPFs). DPFs generate expressive intermediate features for continuous sub-pixel locations, thus allowing outputs of an arbitrary resolution. DPFs are naturally compatible with point-level supervision. We showcase the effectiveness of DPFs using two substantially different tasks: high-level semantic parsing and low-level intrinsic image decomposition. In these two cases, supervision comes in the form of single-point semantic category and two-point relative reflectance, respectively. As benchmarked by three large-scale public datasets PASCALContext, ADE20K and IIW, DPFs set new state-of-the-art performance on all of them with significant margins. Code can be accessed at https://github.com/cxx226/DPF.
STEPS: Joint Self-supervised Nighttime Image Enhancement and Depth Estimation
Feb 02, 2023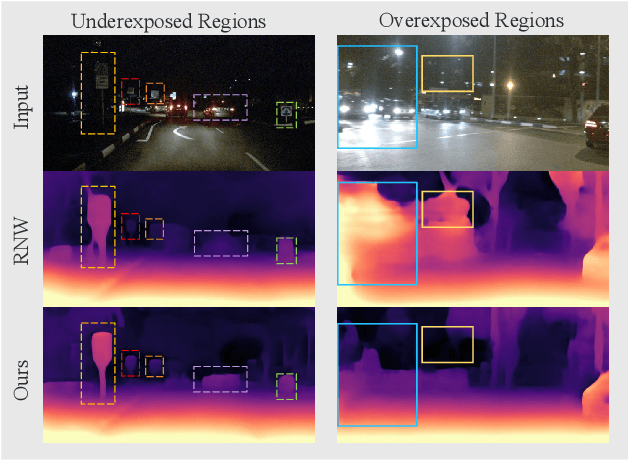
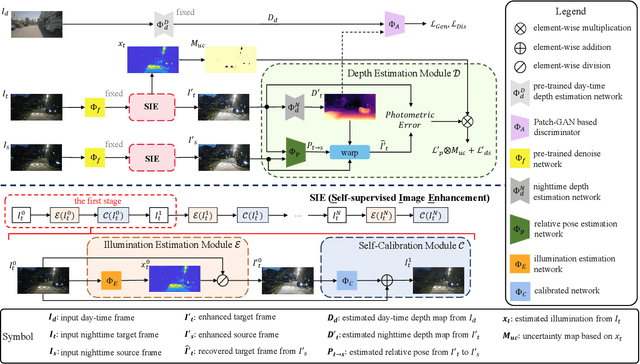

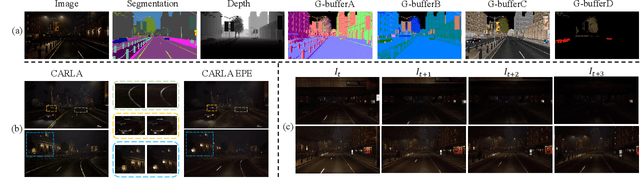
Self-supervised depth estimation draws a lot of attention recently as it can promote the 3D sensing capabilities of self-driving vehicles. However, it intrinsically relies upon the photometric consistency assumption, which hardly holds during nighttime. Although various supervised nighttime image enhancement methods have been proposed, their generalization performance in challenging driving scenarios is not satisfactory. To this end, we propose the first method that jointly learns a nighttime image enhancer and a depth estimator, without using ground truth for either task. Our method tightly entangles two self-supervised tasks using a newly proposed uncertain pixel masking strategy. This strategy originates from the observation that nighttime images not only suffer from underexposed regions but also from overexposed regions. By fitting a bridge-shaped curve to the illumination map distribution, both regions are suppressed and two tasks are bridged naturally. We benchmark the method on two established datasets: nuScenes and RobotCar and demonstrate state-of-the-art performance on both of them. Detailed ablations also reveal the mechanism of our proposal. Last but not least, to mitigate the problem of sparse ground truth of existing datasets, we provide a new photo-realistically enhanced nighttime dataset based upon CARLA. It brings meaningful new challenges to the community. Codes, data, and models are available at https://github.com/ucaszyp/STEPS.
ADAPT: Action-aware Driving Caption Transformer
Feb 01, 2023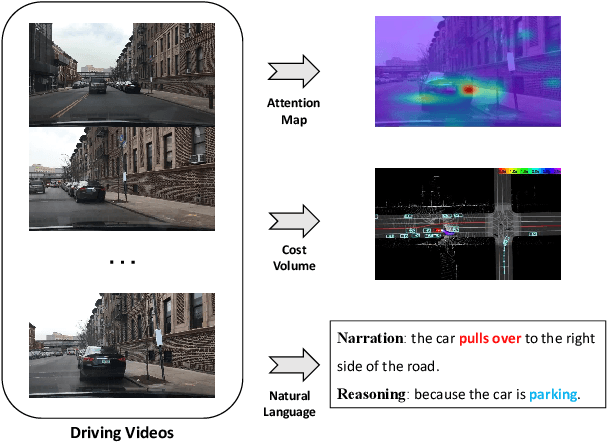
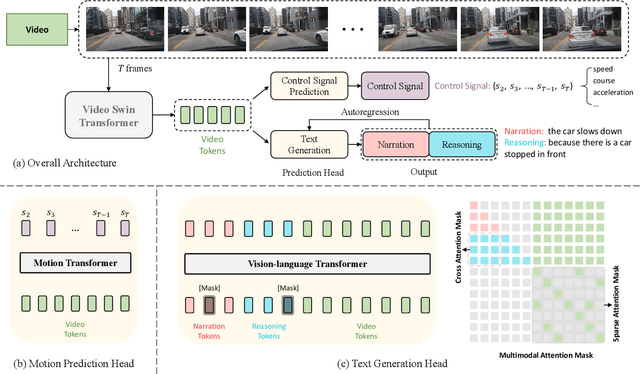
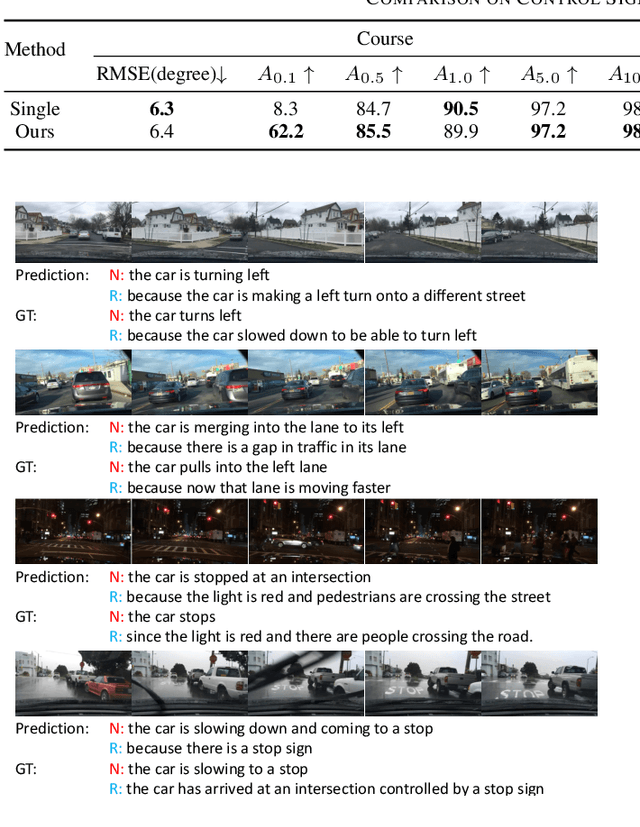
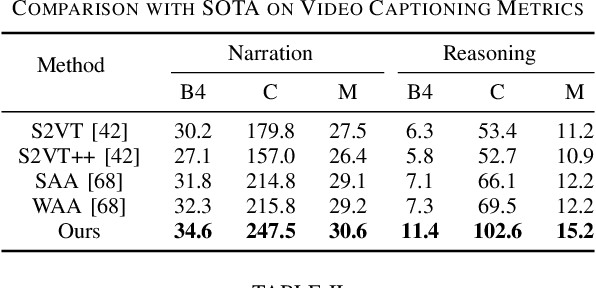
End-to-end autonomous driving has great potential in the transportation industry. However, the lack of transparency and interpretability of the automatic decision-making process hinders its industrial adoption in practice. There have been some early attempts to use attention maps or cost volume for better model explainability which is difficult for ordinary passengers to understand. To bridge the gap, we propose an end-to-end transformer-based architecture, ADAPT (Action-aware Driving cAPtion Transformer), which provides user-friendly natural language narrations and reasoning for each decision making step of autonomous vehicular control and action. ADAPT jointly trains both the driving caption task and the vehicular control prediction task, through a shared video representation. Experiments on BDD-X (Berkeley DeepDrive eXplanation) dataset demonstrate state-of-the-art performance of the ADAPT framework on both automatic metrics and human evaluation. To illustrate the feasibility of the proposed framework in real-world applications, we build a novel deployable system that takes raw car videos as input and outputs the action narrations and reasoning in real time. The code, models and data are available at https://github.com/jxbbb/ADAPT.