 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXiaoxue Chen
Spectrally Pruned Gaussian Fields with Neural Compensation
May 01, 2024
Recently, 3D Gaussian Splatting, as a novel 3D representation, has garnered attention for its fast rendering speed and high rendering quality. However, this comes with high memory consumption, e.g., a well-trained Gaussian field may utilize three million Gaussian primitives and over 700 MB of memory. We credit this high memory footprint to the lack of consideration for the relationship between primitives. In this paper, we propose a memory-efficient Gaussian field named SUNDAE with spectral pruning and neural compensation. On one hand, we construct a graph on the set of Gaussian primitives to model their relationship and design a spectral down-sampling module to prune out primitives while preserving desired signals. On the other hand, to compensate for the quality loss of pruning Gaussians, we exploit a lightweight neural network head to mix splatted features, which effectively compensates for quality losses while capturing the relationship between primitives in its weights. We demonstrate the performance of SUNDAE with extensive results. For example, SUNDAE can achieve 26.80 PSNR at 145 FPS using 104 MB memory while the vanilla Gaussian splatting algorithm achieves 25.60 PSNR at 160 FPS using 523 MB memory, on the Mip-NeRF360 dataset. Codes are publicly available at https://runyiyang.github.io/projects/SUNDAE/.
Ultraman: Single Image 3D Human Reconstruction with Ultra Speed and Detail
Mar 18, 2024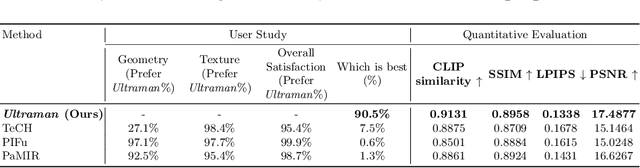
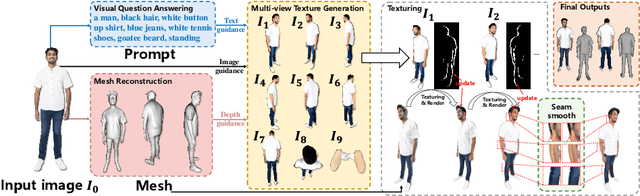
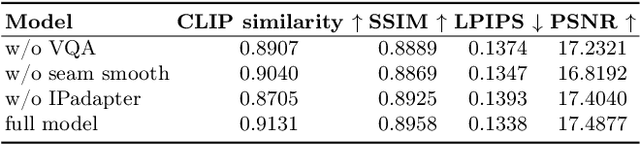

3D human body reconstruction has been a challenge in the field of computer vision. Previous methods are often time-consuming and difficult to capture the detailed appearance of the human body. In this paper, we propose a new method called \emph{Ultraman} for fast reconstruction of textured 3D human models from a single image. Compared to existing techniques, \emph{Ultraman} greatly improves the reconstruction speed and accuracy while preserving high-quality texture details. We present a set of new frameworks for human reconstruction consisting of three parts, geometric reconstruction, texture generation and texture mapping. Firstly, a mesh reconstruction framework is used, which accurately extracts 3D human shapes from a single image. At the same time, we propose a method to generate a multi-view consistent image of the human body based on a single image. This is finally combined with a novel texture mapping method to optimize texture details and ensure color consistency during reconstruction. Through extensive experiments and evaluations, we demonstrate the superior performance of \emph{Ultraman} on various standard datasets. In addition, \emph{Ultraman} outperforms state-of-the-art methods in terms of human rendering quality and speed. Upon acceptance of the article, we will make the code and data publicly available.
NeRRF: 3D Reconstruction and View Synthesis for Transparent and Specular Objects with Neural Refractive-Reflective Fields
Sep 22, 2023Neural radiance fields (NeRF) have revolutionized the field of image-based view synthesis. However, NeRF uses straight rays and fails to deal with complicated light path changes caused by refraction and reflection. This prevents NeRF from successfully synthesizing transparent or specular objects, which are ubiquitous in real-world robotics and A/VR applications. In this paper, we introduce the refractive-reflective field. Taking the object silhouette as input, we first utilize marching tetrahedra with a progressive encoding to reconstruct the geometry of non-Lambertian objects and then model refraction and reflection effects of the object in a unified framework using Fresnel terms. Meanwhile, to achieve efficient and effective anti-aliasing, we propose a virtual cone supersampling technique. We benchmark our method on different shapes, backgrounds and Fresnel terms on both real-world and synthetic datasets. We also qualitatively and quantitatively benchmark the rendering results of various editing applications, including material editing, object replacement/insertion, and environment illumination estimation. Codes and data are publicly available at https://github.com/dawning77/NeRRF.
ECT: Fine-grained Edge Detection with Learned Cause Tokens
Aug 06, 2023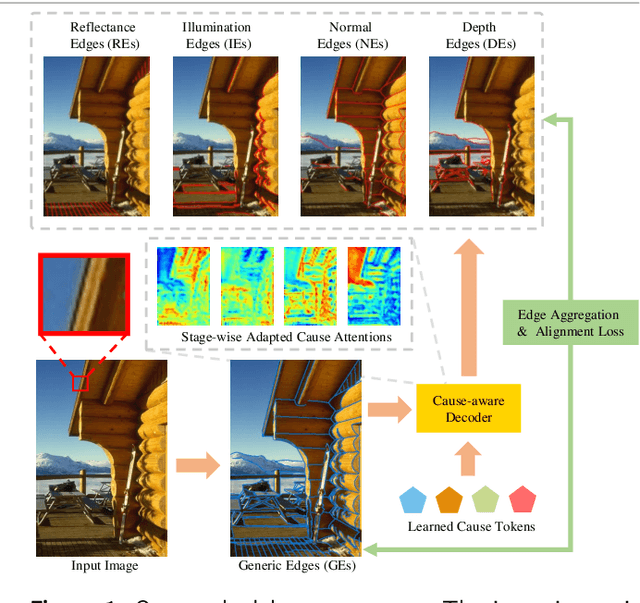

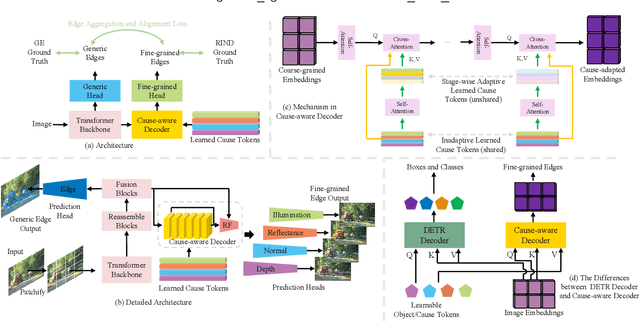

In this study, we tackle the challenging fine-grained edge detection task, which refers to predicting specific edges caused by reflectance, illumination, normal, and depth changes, respectively. Prior methods exploit multi-scale convolutional networks, which are limited in three aspects: (1) Convolutions are local operators while identifying the cause of edge formation requires looking at far away pixels. (2) Priors specific to edge cause are fixed in prediction heads. (3) Using separate networks for generic and fine-grained edge detection, and the constraint between them may be violated. To address these three issues, we propose a two-stage transformer-based network sequentially predicting generic edges and fine-grained edges, which has a global receptive field thanks to the attention mechanism. The prior knowledge of edge causes is formulated as four learnable cause tokens in a cause-aware decoder design. Furthermore, to encourage the consistency between generic edges and fine-grained edges, an edge aggregation and alignment loss is exploited. We evaluate our method on the public benchmark BSDS-RIND and several newly derived benchmarks, and achieve new state-of-the-art results. Our code, data, and models are publicly available at https://github.com/Daniellli/ECT.git.
STRAP: Structured Object Affordance Segmentation with Point Supervision
Apr 17, 2023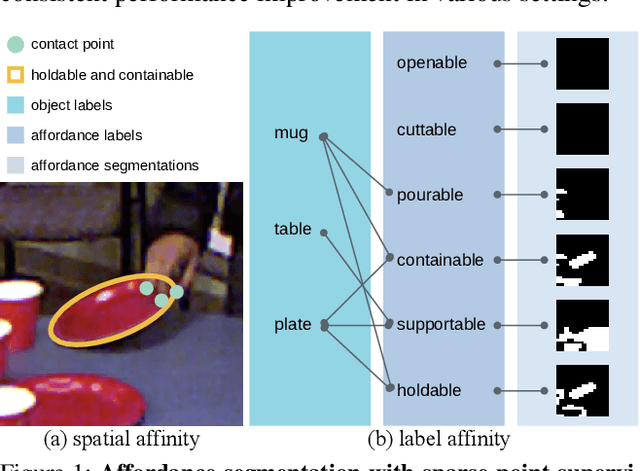
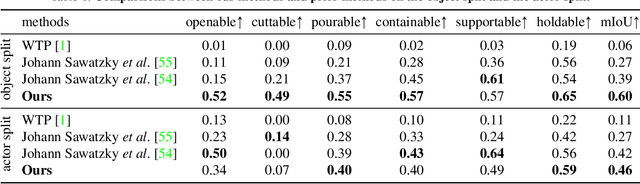
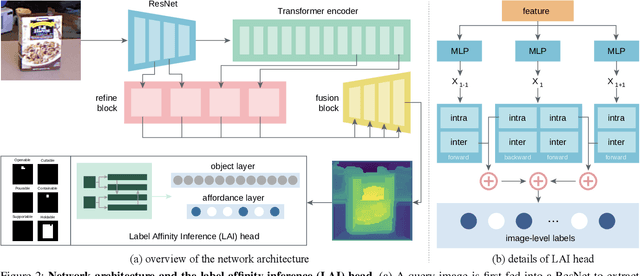
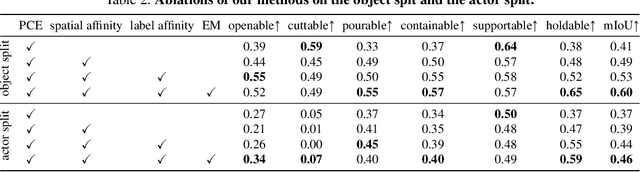
With significant annotation savings, point supervision has been proven effective for numerous 2D and 3D scene understanding problems. This success is primarily attributed to the structured output space; i.e., samples with high spatial affinity tend to share the same labels. Sharing this spirit, we study affordance segmentation with point supervision, wherein the setting inherits an unexplored dual affinity-spatial affinity and label affinity. By label affinity, we refer to affordance segmentation as a multi-label prediction problem: A plate can be both holdable and containable. By spatial affinity, we refer to a universal prior that nearby pixels with similar visual features should share the same point annotation. To tackle label affinity, we devise a dense prediction network that enhances label relations by effectively densifying labels in a new domain (i.e., label co-occurrence). To address spatial affinity, we exploit a Transformer backbone for global patch interaction and a regularization loss. In experiments, we benchmark our method on the challenging CAD120 dataset, showing significant performance gains over prior methods.
DPF: Learning Dense Prediction Fields with Weak Supervision
Mar 29, 2023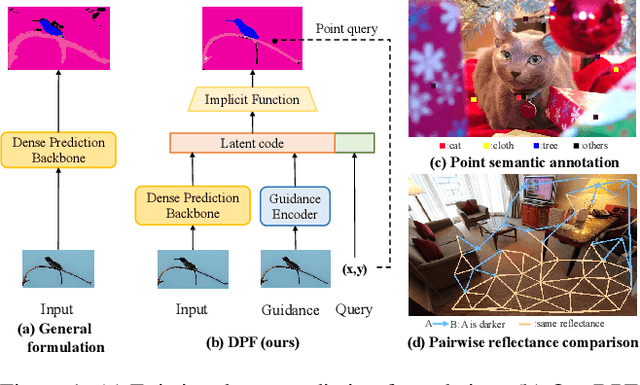
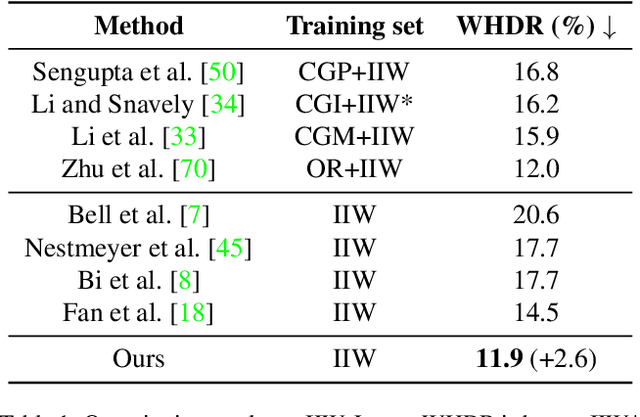
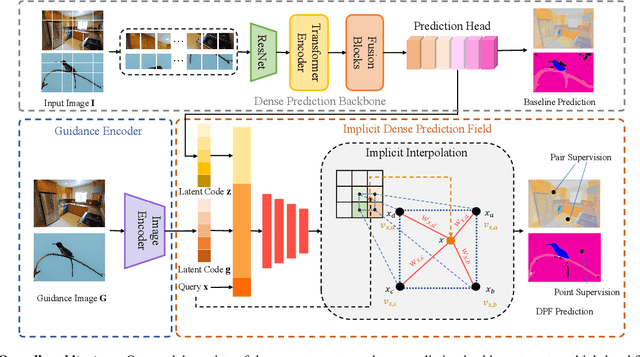

Nowadays, many visual scene understanding problems are addressed by dense prediction networks. But pixel-wise dense annotations are very expensive (e.g., for scene parsing) or impossible (e.g., for intrinsic image decomposition), motivating us to leverage cheap point-level weak supervision. However, existing pointly-supervised methods still use the same architecture designed for full supervision. In stark contrast to them, we propose a new paradigm that makes predictions for point coordinate queries, as inspired by the recent success of implicit representations, like distance or radiance fields. As such, the method is named as dense prediction fields (DPFs). DPFs generate expressive intermediate features for continuous sub-pixel locations, thus allowing outputs of an arbitrary resolution. DPFs are naturally compatible with point-level supervision. We showcase the effectiveness of DPFs using two substantially different tasks: high-level semantic parsing and low-level intrinsic image decomposition. In these two cases, supervision comes in the form of single-point semantic category and two-point relative reflectance, respectively. As benchmarked by three large-scale public datasets PASCALContext, ADE20K and IIW, DPFs set new state-of-the-art performance on all of them with significant margins. Code can be accessed at https://github.com/cxx226/DPF.
From Semi-supervised to Omni-supervised Room Layout Estimation Using Point Clouds
Jan 31, 2023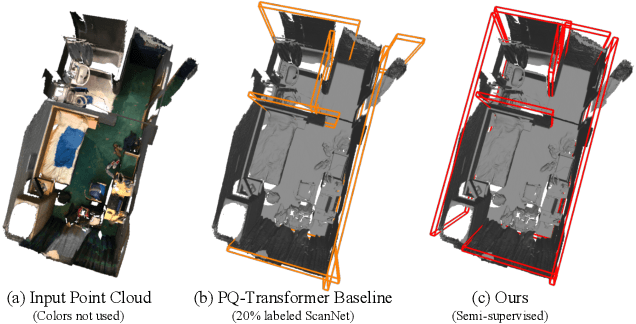
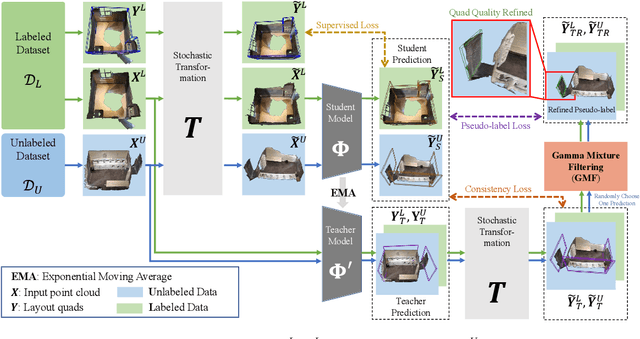
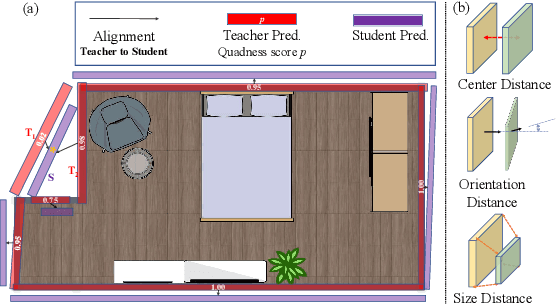
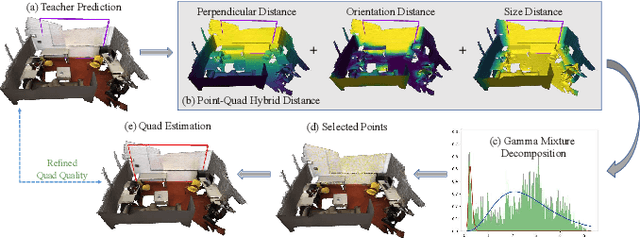
Room layout estimation is a long-existing robotic vision task that benefits both environment sensing and motion planning. However, layout estimation using point clouds (PCs) still suffers from data scarcity due to annotation difficulty. As such, we address the semi-supervised setting of this task based upon the idea of model exponential moving averaging. But adapting this scheme to the state-of-the-art (SOTA) solution for PC-based layout estimation is not straightforward. To this end, we define a quad set matching strategy and several consistency losses based upon metrics tailored for layout quads. Besides, we propose a new online pseudo-label harvesting algorithm that decomposes the distribution of a hybrid distance measure between quads and PC into two components. This technique does not need manual threshold selection and intuitively encourages quads to align with reliable layout points. Surprisingly, this framework also works for the fully-supervised setting, achieving a new SOTA on the ScanNet benchmark. Last but not least, we also push the semi-supervised setting to the realistic omni-supervised setting, demonstrating significantly promoted performance on a newly annotated ARKitScenes testing set. Our codes, data and models are released in this repository.
TOIST: Task Oriented Instance Segmentation Transformer with Noun-Pronoun Distillation
Oct 19, 2022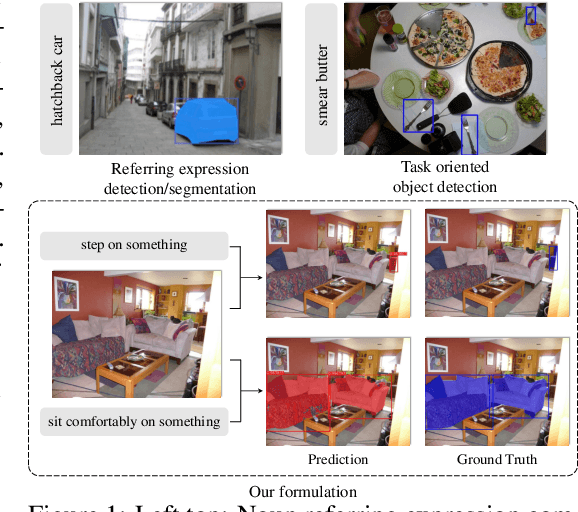

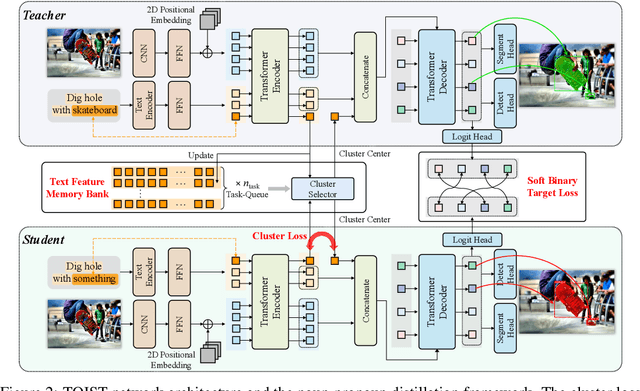
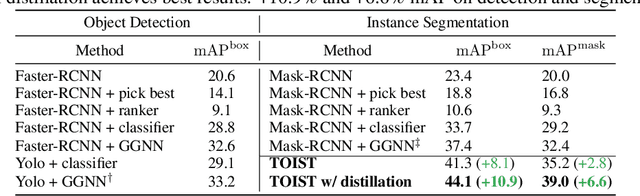
Current referring expression comprehension algorithms can effectively detect or segment objects indicated by nouns, but how to understand verb reference is still under-explored. As such, we study the challenging problem of task oriented detection, which aims to find objects that best afford an action indicated by verbs like sit comfortably on. Towards a finer localization that better serves downstream applications like robot interaction, we extend the problem into task oriented instance segmentation. A unique requirement of this task is to select preferred candidates among possible alternatives. Thus we resort to the transformer architecture which naturally models pair-wise query relationships with attention, leading to the TOIST method. In order to leverage pre-trained noun referring expression comprehension models and the fact that we can access privileged noun ground truth during training, a novel noun-pronoun distillation framework is proposed. Noun prototypes are generated in an unsupervised manner and contextual pronoun features are trained to select prototypes. As such, the network remains noun-agnostic during inference. We evaluate TOIST on the large-scale task oriented dataset COCO-Tasks and achieve +10.9% higher $\rm{mAP^{box}}$ than the best-reported results. The proposed noun-pronoun distillation can boost $\rm{mAP^{box}}$ and $\rm{mAP^{mask}}$ by +2.8% and +3.8%. Codes and models are publicly available at https://github.com/AIR-DISCOVER/TOIST.
Understanding Embodied Reference with Touch-Line Transformer
Oct 12, 2022

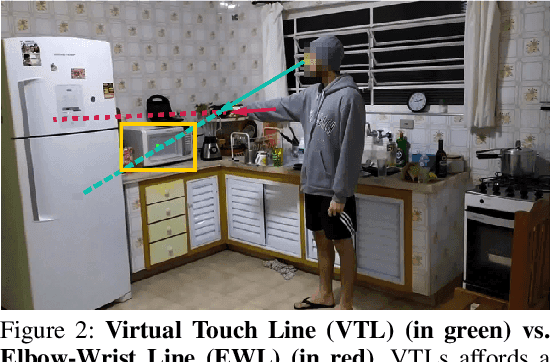
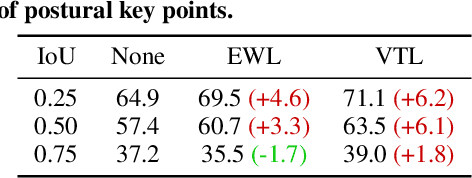
We study embodied reference understanding, the task of locating referents using embodied gestural signals and language references. Human studies have revealed that objects referred to or pointed to do not lie on the elbow-wrist line, a common misconception; instead, they lie on the so-called virtual touch line. However, existing human pose representations fail to incorporate the virtual touch line. To tackle this problem, we devise the touch-line transformer: It takes as input tokenized visual and textual features and simultaneously predicts the referent's bounding box and a touch-line vector. Leveraging this touch-line prior, we further devise a geometric consistency loss that encourages the co-linearity between referents and touch lines. Using the touch-line as gestural information improves model performances significantly. Experiments on the YouRefIt dataset show our method achieves a +25.0% accuracy improvement under the 0.75 IoU criterion, closing 63.6% of the gap between model and human performances. Furthermore, we computationally verify prior human studies by showing that computational models more accurately locate referents when using the virtual touch line than when using the elbow-wrist line.
Distance-Aware Occlusion Detection with Focused Attention
Aug 23, 2022

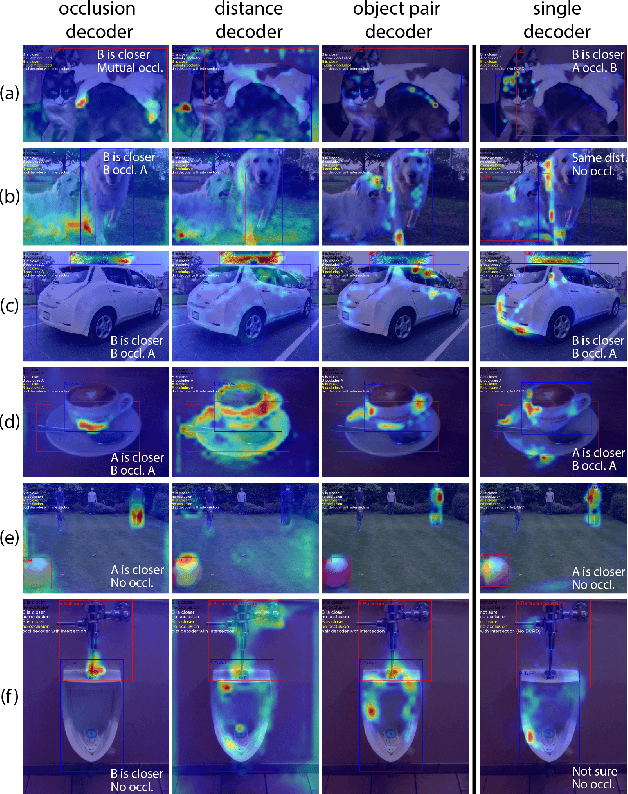
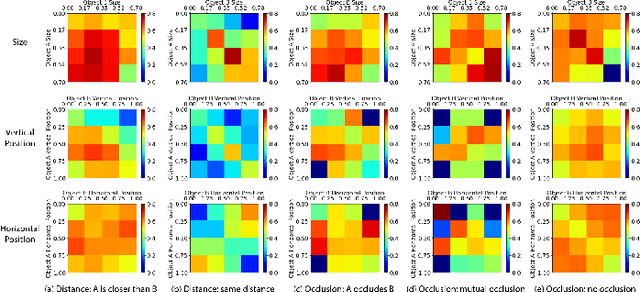
For humans, understanding the relationships between objects using visual signals is intuitive. For artificial intelligence, however, this task remains challenging. Researchers have made significant progress studying semantic relationship detection, such as human-object interaction detection and visual relationship detection. We take the study of visual relationships a step further from semantic to geometric. In specific, we predict relative occlusion and relative distance relationships. However, detecting these relationships from a single image is challenging. Enforcing focused attention to task-specific regions plays a critical role in successfully detecting these relationships. In this work, (1) we propose a novel three-decoder architecture as the infrastructure for focused attention; 2) we use the generalized intersection box prediction task to effectively guide our model to focus on occlusion-specific regions; 3) our model achieves a new state-of-the-art performance on distance-aware relationship detection. Specifically, our model increases the distance F1-score from 33.8% to 38.6% and boosts the occlusion F1-score from 34.4% to 41.2%. Our code is publicly available.