 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZhaoxin Fan
Idea-2-3D: Collaborative LMM Agents Enable 3D Model Generation from Interleaved Multimodal Inputs
Apr 05, 2024
In this paper, we pursue a novel 3D AIGC setting: generating 3D content from IDEAs. The definition of an IDEA is the composition of multimodal inputs including text, image, and 3D models. To our knowledge, this challenging and appealing 3D AIGC setting has not been studied before. We propose the novel framework called Idea-2-3D to achieve this goal, which consists of three agents based upon large multimodel models (LMMs) and several existing algorithmic tools for them to invoke. Specifically, these three LMM-based agents are prompted to do the jobs of prompt generation, model selection and feedback reflection. They work in a cycle that involves both mutual collaboration and criticism. Note that this cycle is done in a fully automatic manner, without any human intervention. The framework then outputs a text prompt to generate 3D models that well align with input IDEAs. We show impressive 3D AIGC results that are beyond any previous methods can achieve. For quantitative comparisons, we construct caption-based baselines using a whole bunch of state-of-the-art 3D AIGC models and demonstrate Idea-2-3D out-performs significantly. In 94.2% of cases, Idea-2-3D meets users' requirements, marking a degree of match between IDEA and 3D models that is 2.3 times higher than baselines. Moreover, in 93.5% of the cases, users agreed that Idea-2-3D was better than baselines. Codes, data and models will made publicly available.
Ultraman: Single Image 3D Human Reconstruction with Ultra Speed and Detail
Mar 18, 2024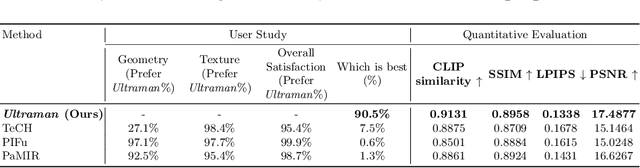
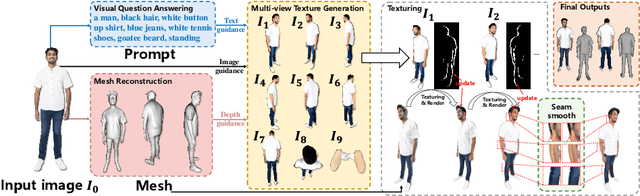
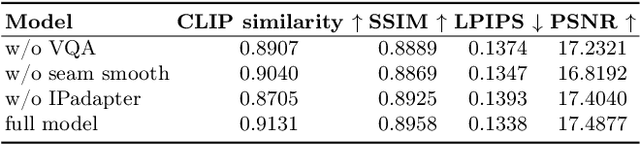

3D human body reconstruction has been a challenge in the field of computer vision. Previous methods are often time-consuming and difficult to capture the detailed appearance of the human body. In this paper, we propose a new method called \emph{Ultraman} for fast reconstruction of textured 3D human models from a single image. Compared to existing techniques, \emph{Ultraman} greatly improves the reconstruction speed and accuracy while preserving high-quality texture details. We present a set of new frameworks for human reconstruction consisting of three parts, geometric reconstruction, texture generation and texture mapping. Firstly, a mesh reconstruction framework is used, which accurately extracts 3D human shapes from a single image. At the same time, we propose a method to generate a multi-view consistent image of the human body based on a single image. This is finally combined with a novel texture mapping method to optimize texture details and ensure color consistency during reconstruction. Through extensive experiments and evaluations, we demonstrate the superior performance of \emph{Ultraman} on various standard datasets. In addition, \emph{Ultraman} outperforms state-of-the-art methods in terms of human rendering quality and speed. Upon acceptance of the article, we will make the code and data publicly available.
AS-FIBA: Adaptive Selective Frequency-Injection for Backdoor Attack on Deep Face Restoration
Mar 11, 2024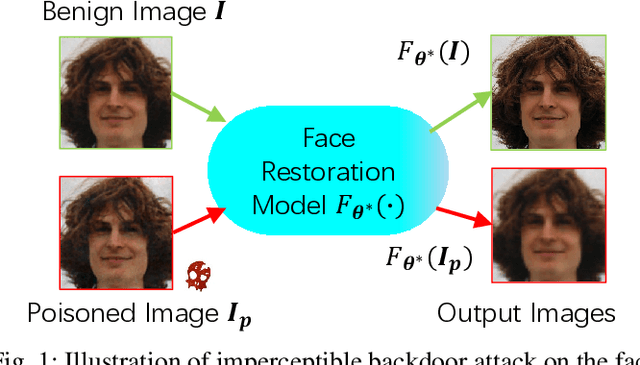
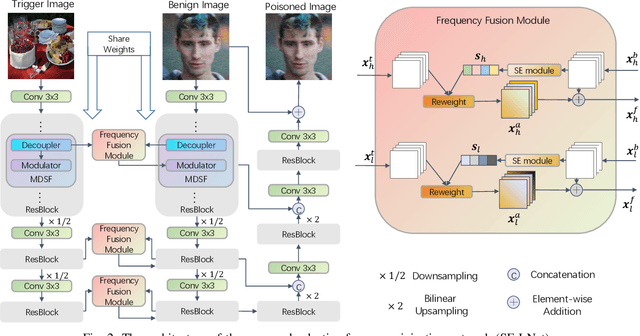
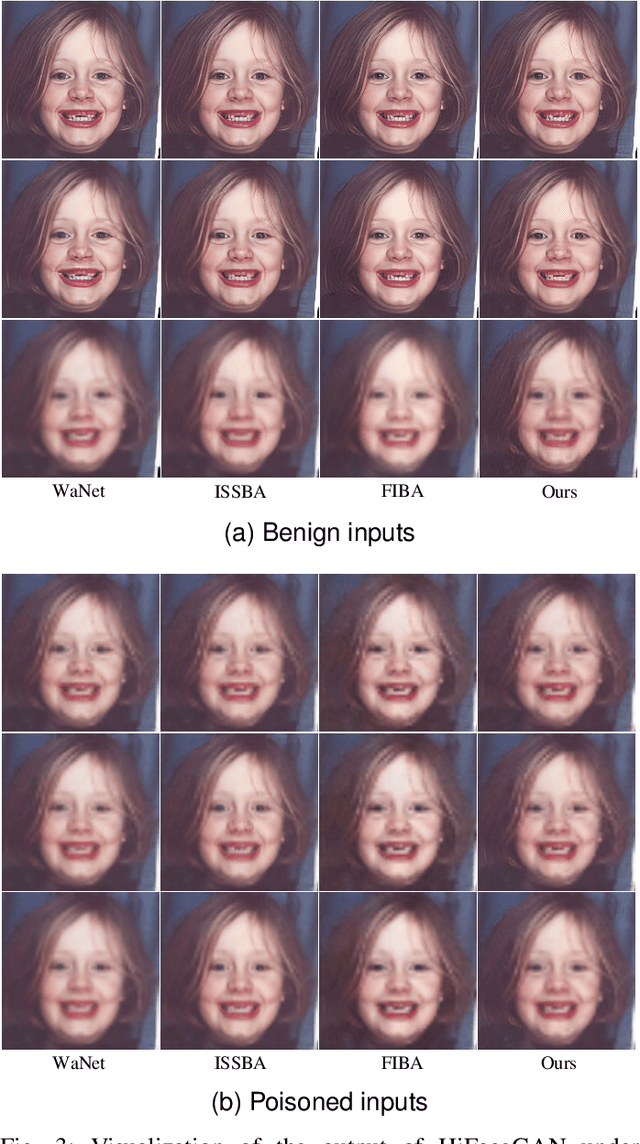

Deep learning-based face restoration models, increasingly prevalent in smart devices, have become targets for sophisticated backdoor attacks. These attacks, through subtle trigger injection into input face images, can lead to unexpected restoration outcomes. Unlike conventional methods focused on classification tasks, our approach introduces a unique degradation objective tailored for attacking restoration models. Moreover, we propose the Adaptive Selective Frequency Injection Backdoor Attack (AS-FIBA) framework, employing a neural network for input-specific trigger generation in the frequency domain, seamlessly blending triggers with benign images. This results in imperceptible yet effective attacks, guiding restoration predictions towards subtly degraded outputs rather than conspicuous targets. Extensive experiments demonstrate the efficacy of the degradation objective on state-of-the-art face restoration models. Additionally, it is notable that AS-FIBA can insert effective backdoors that are more imperceptible than existing backdoor attack methods, including WaNet, ISSBA, and FIBA.
Enhancing Weakly Supervised 3D Medical Image Segmentation through Probabilistic-aware Learning
Mar 05, 2024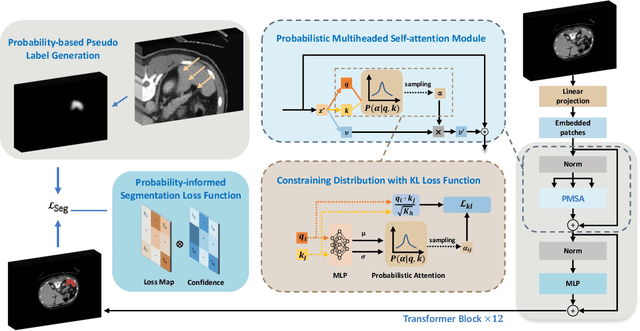
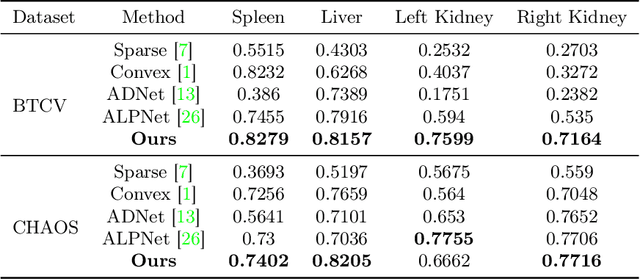
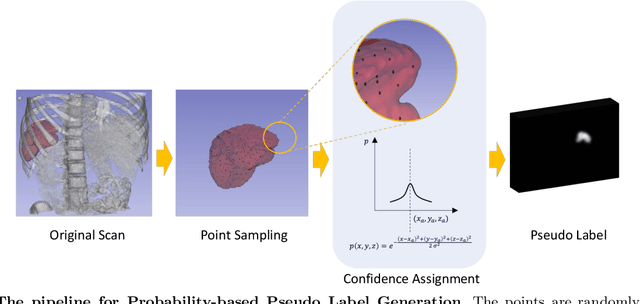
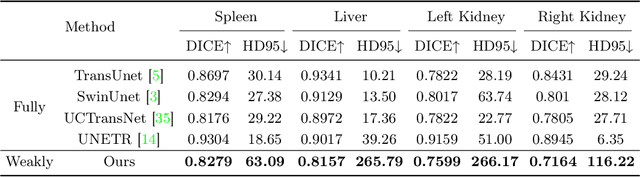
3D medical image segmentation is a challenging task with crucial implications for disease diagnosis and treatment planning. Recent advances in deep learning have significantly enhanced fully supervised medical image segmentation. However, this approach heavily relies on labor-intensive and time-consuming fully annotated ground-truth labels, particularly for 3D volumes. To overcome this limitation, we propose a novel probabilistic-aware weakly supervised learning pipeline, specifically designed for 3D medical imaging. Our pipeline integrates three innovative components: a probability-based pseudo-label generation technique for synthesizing dense segmentation masks from sparse annotations, a Probabilistic Multi-head Self-Attention network for robust feature extraction within our Probabilistic Transformer Network, and a Probability-informed Segmentation Loss Function to enhance training with annotation confidence. Demonstrating significant advances, our approach not only rivals the performance of fully supervised methods but also surpasses existing weakly supervised methods in CT and MRI datasets, achieving up to 18.1% improvement in Dice scores for certain organs. The code is available at https://github.com/runminjiang/PW4MedSeg.
Adversarial Purification and Fine-tuning for Robust UDC Image Restoration
Feb 21, 2024This study delves into the enhancement of Under-Display Camera (UDC) image restoration models, focusing on their robustness against adversarial attacks. Despite its innovative approach to seamless display integration, UDC technology faces unique image degradation challenges exacerbated by the susceptibility to adversarial perturbations. Our research initially conducts an in-depth robustness evaluation of deep-learning-based UDC image restoration models by employing several white-box and black-box attacking methods. This evaluation is pivotal in understanding the vulnerabilities of current UDC image restoration techniques. Following the assessment, we introduce a defense framework integrating adversarial purification with subsequent fine-tuning processes. First, our approach employs diffusion-based adversarial purification, effectively neutralizing adversarial perturbations. Then, we apply the fine-tuning methodologies to refine the image restoration models further, ensuring that the quality and fidelity of the restored images are maintained. The effectiveness of our proposed approach is validated through extensive experiments, showing marked improvements in resilience against typical adversarial attacks.
SyncTalk: The Devil is in the Synchronization for Talking Head Synthesis
Nov 29, 2023Achieving high synchronization in the synthesis of realistic, speech-driven talking head videos presents a significant challenge. Traditional Generative Adversarial Networks (GAN) struggle to maintain consistent facial identity, while Neural Radiance Fields (NeRF) methods, although they can address this issue, often produce mismatched lip movements, inadequate facial expressions, and unstable head poses. A lifelike talking head requires synchronized coordination of subject identity, lip movements, facial expressions, and head poses. The absence of these synchronizations is a fundamental flaw, leading to unrealistic and artificial outcomes. To address the critical issue of synchronization, identified as the "devil" in creating realistic talking heads, we introduce SyncTalk. This NeRF-based method effectively maintains subject identity, enhancing synchronization and realism in talking head synthesis. SyncTalk employs a Face-Sync Controller to align lip movements with speech and innovatively uses a 3D facial blendshape model to capture accurate facial expressions. Our Head-Sync Stabilizer optimizes head poses, achieving more natural head movements. The Portrait-Sync Generator restores hair details and blends the generated head with the torso for a seamless visual experience. Extensive experiments and user studies demonstrate that SyncTalk outperforms state-of-the-art methods in synchronization and realism. We recommend watching the supplementary video: https://ziqiaopeng.github.io/synctalk
BeatDance: A Beat-Based Model-Agnostic Contrastive Learning Framework for Music-Dance Retrieval
Oct 16, 2023Dance and music are closely related forms of expression, with mutual retrieval between dance videos and music being a fundamental task in various fields like education, art, and sports. However, existing methods often suffer from unnatural generation effects or fail to fully explore the correlation between music and dance. To overcome these challenges, we propose BeatDance, a novel beat-based model-agnostic contrastive learning framework. BeatDance incorporates a Beat-Aware Music-Dance InfoExtractor, a Trans-Temporal Beat Blender, and a Beat-Enhanced Hubness Reducer to improve dance-music retrieval performance by utilizing the alignment between music beats and dance movements. We also introduce the Music-Dance (MD) dataset, a large-scale collection of over 10,000 music-dance video pairs for training and testing. Experimental results on the MD dataset demonstrate the superiority of our method over existing baselines, achieving state-of-the-art performance. The code and dataset will be made public available upon acceptance.
Multi-dimensional Fusion and Consistency for Semi-supervised Medical Image Segmentation
Sep 16, 2023
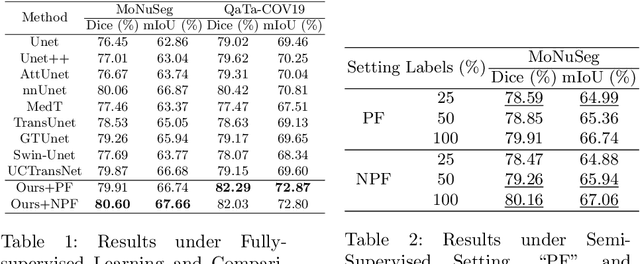

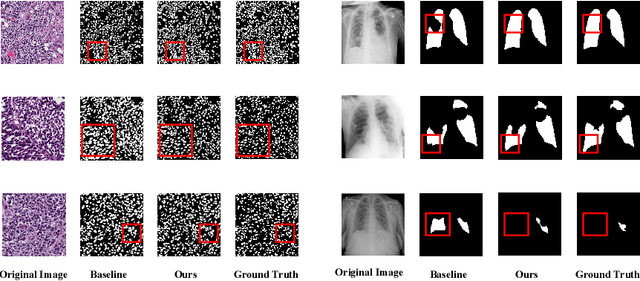
In this paper, we introduce a novel semi-supervised learning framework tailored for medical image segmentation. Central to our approach is the innovative Multi-scale Text-aware ViT-CNN Fusion scheme. This scheme adeptly combines the strengths of both ViTs and CNNs, capitalizing on the unique advantages of both architectures as well as the complementary information in vision-language modalities. Further enriching our framework, we propose the Multi-Axis Consistency framework for generating robust pseudo labels, thereby enhancing the semi-supervised learning process. Our extensive experiments on several widely-used datasets unequivocally demonstrate the efficacy of our approach.
STDG: Semi-Teacher-Student Training Paradigram for Depth-guided One-stage Scene Graph Generation
Sep 15, 2023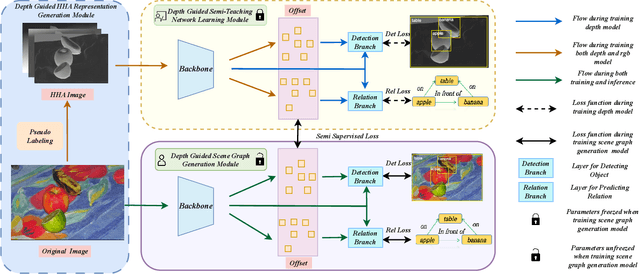

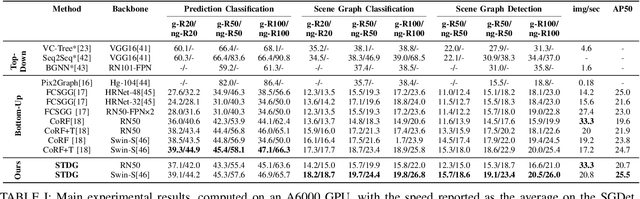
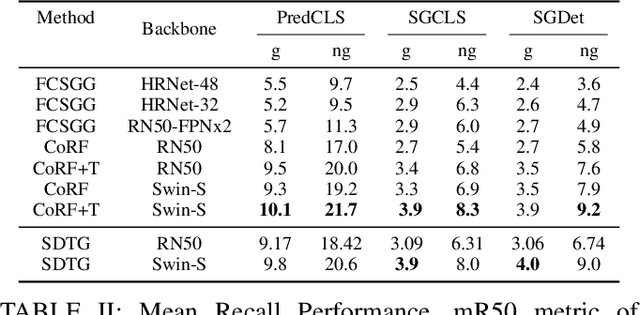
Scene Graph Generation is a critical enabler of environmental comprehension for autonomous robotic systems. Most of existing methods, however, are often thwarted by the intricate dynamics of background complexity, which limits their ability to fully decode the inherent topological information of the environment. Additionally, the wealth of contextual information encapsulated within depth cues is often left untapped, rendering existing approaches less effective. To address these shortcomings, we present STDG, an avant-garde Depth-Guided One-Stage Scene Graph Generation methodology. The innovative architecture of STDG is a triad of custom-built modules: The Depth Guided HHA Representation Generation Module, the Depth Guided Semi-Teaching Network Learning Module, and the Depth Guided Scene Graph Generation Module. This trifecta of modules synergistically harnesses depth information, covering all aspects from depth signal generation and depth feature utilization, to the final scene graph prediction. Importantly, this is achieved without imposing additional computational burden during the inference phase. Experimental results confirm that our method significantly enhances the performance of one-stage scene graph generation baselines.
D-IF: Uncertainty-aware Human Digitization via Implicit Distribution Field
Aug 17, 2023Realistic virtual humans play a crucial role in numerous industries, such as metaverse, intelligent healthcare, and self-driving simulation. But creating them on a large scale with high levels of realism remains a challenge. The utilization of deep implicit function sparks a new era of image-based 3D clothed human reconstruction, enabling pixel-aligned shape recovery with fine details. Subsequently, the vast majority of works locate the surface by regressing the deterministic implicit value for each point. However, should all points be treated equally regardless of their proximity to the surface? In this paper, we propose replacing the implicit value with an adaptive uncertainty distribution, to differentiate between points based on their distance to the surface. This simple ``value to distribution'' transition yields significant improvements on nearly all the baselines. Furthermore, qualitative results demonstrate that the models trained using our uncertainty distribution loss, can capture more intricate wrinkles, and realistic limbs. Code and models are available for research purposes at https://github.com/psyai-net/D-IF_release.