 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJianfeng Lu
AS-FIBA: Adaptive Selective Frequency-Injection for Backdoor Attack on Deep Face Restoration
Mar 11, 2024
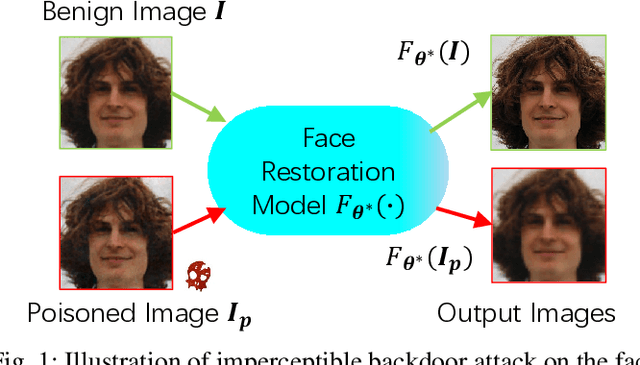
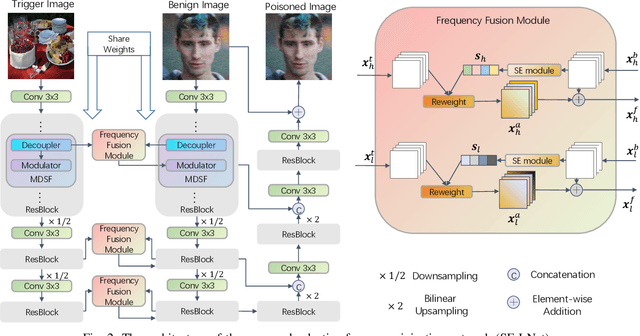
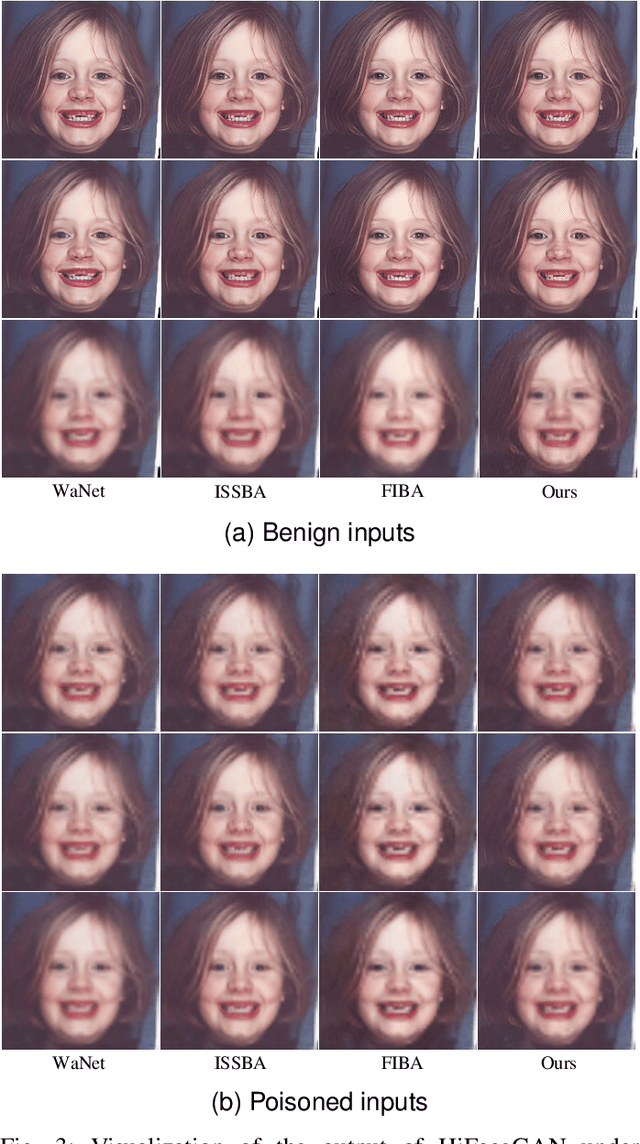

Deep learning-based face restoration models, increasingly prevalent in smart devices, have become targets for sophisticated backdoor attacks. These attacks, through subtle trigger injection into input face images, can lead to unexpected restoration outcomes. Unlike conventional methods focused on classification tasks, our approach introduces a unique degradation objective tailored for attacking restoration models. Moreover, we propose the Adaptive Selective Frequency Injection Backdoor Attack (AS-FIBA) framework, employing a neural network for input-specific trigger generation in the frequency domain, seamlessly blending triggers with benign images. This results in imperceptible yet effective attacks, guiding restoration predictions towards subtly degraded outputs rather than conspicuous targets. Extensive experiments demonstrate the efficacy of the degradation objective on state-of-the-art face restoration models. Additionally, it is notable that AS-FIBA can insert effective backdoors that are more imperceptible than existing backdoor attack methods, including WaNet, ISSBA, and FIBA.
Adversarial Purification and Fine-tuning for Robust UDC Image Restoration
Feb 21, 2024This study delves into the enhancement of Under-Display Camera (UDC) image restoration models, focusing on their robustness against adversarial attacks. Despite its innovative approach to seamless display integration, UDC technology faces unique image degradation challenges exacerbated by the susceptibility to adversarial perturbations. Our research initially conducts an in-depth robustness evaluation of deep-learning-based UDC image restoration models by employing several white-box and black-box attacking methods. This evaluation is pivotal in understanding the vulnerabilities of current UDC image restoration techniques. Following the assessment, we introduce a defense framework integrating adversarial purification with subsequent fine-tuning processes. First, our approach employs diffusion-based adversarial purification, effectively neutralizing adversarial perturbations. Then, we apply the fine-tuning methodologies to refine the image restoration models further, ensuring that the quality and fidelity of the restored images are maintained. The effectiveness of our proposed approach is validated through extensive experiments, showing marked improvements in resilience against typical adversarial attacks.
Learning Memory Kernels in Generalized Langevin Equations
Feb 18, 2024We introduce a novel approach for learning memory kernels in Generalized Langevin Equations. This approach initially utilizes a regularized Prony method to estimate correlation functions from trajectory data, followed by regression over a Sobolev norm-based loss function with RKHS regularization. Our approach guarantees improved performance within an exponentially weighted $L^2$ space, with the kernel estimation error controlled by the error in estimated correlation functions. We demonstrate the superiority of our estimator compared to other regression estimators that rely on $L^2$ loss functions and also an estimator derived from the inverse Laplace transform, using numerical examples that highlight its consistent advantage across various weight parameter selections. Additionally, we provide examples that include the application of force and drift terms in the equation.
Hyperspectral Image Denoising via Spatial-Spectral Recurrent Transformer
Jan 09, 2024Hyperspectral images (HSIs) often suffer from noise arising from both intra-imaging mechanisms and environmental factors. Leveraging domain knowledge specific to HSIs, such as global spectral correlation (GSC) and non-local spatial self-similarity (NSS), is crucial for effective denoising. Existing methods tend to independently utilize each of these knowledge components with multiple blocks, overlooking the inherent 3D nature of HSIs where domain knowledge is strongly interlinked, resulting in suboptimal performance. To address this challenge, this paper introduces a spatial-spectral recurrent transformer U-Net (SSRT-UNet) for HSI denoising. The proposed SSRT-UNet integrates NSS and GSC properties within a single SSRT block. This block consists of a spatial branch and a spectral branch. The spectral branch employs a combination of transformer and recurrent neural network to perform recurrent computations across bands, allowing for GSC exploitation beyond a fixed number of bands. Concurrently, the spatial branch encodes NSS for each band by sharing keys and values with the spectral branch under the guidance of GSC. This interaction between the two branches enables the joint utilization of NSS and GSC, avoiding their independent treatment. Experimental results demonstrate that our method outperforms several alternative approaches. The source code will be available at https://github.com/lronkitty/SSRT.
Deep Equilibrium Based Neural Operators for Steady-State PDEs
Nov 30, 2023Data-driven machine learning approaches are being increasingly used to solve partial differential equations (PDEs). They have shown particularly striking successes when training an operator, which takes as input a PDE in some family, and outputs its solution. However, the architectural design space, especially given structural knowledge of the PDE family of interest, is still poorly understood. We seek to remedy this gap by studying the benefits of weight-tied neural network architectures for steady-state PDEs. To achieve this, we first demonstrate that the solution of most steady-state PDEs can be expressed as a fixed point of a non-linear operator. Motivated by this observation, we propose FNO-DEQ, a deep equilibrium variant of the FNO architecture that directly solves for the solution of a steady-state PDE as the infinite-depth fixed point of an implicit operator layer using a black-box root solver and differentiates analytically through this fixed point resulting in $\mathcal{O}(1)$ training memory. Our experiments indicate that FNO-DEQ-based architectures outperform FNO-based baselines with $4\times$ the number of parameters in predicting the solution to steady-state PDEs such as Darcy Flow and steady-state incompressible Navier-Stokes. Finally, we show FNO-DEQ is more robust when trained with datasets with more noisy observations than the FNO-based baselines, demonstrating the benefits of using appropriate inductive biases in architectural design for different neural network based PDE solvers. Further, we show a universal approximation result that demonstrates that FNO-DEQ can approximate the solution to any steady-state PDE that can be written as a fixed point equation.
Convergence of flow-based generative models via proximal gradient descent in Wasserstein space
Oct 26, 2023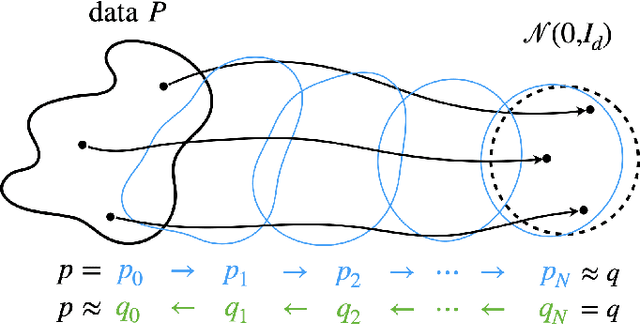
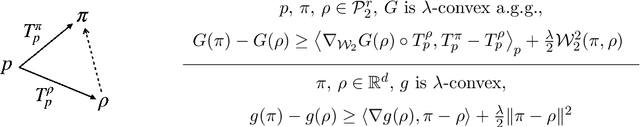
Flow-based generative models enjoy certain advantages in computing the data generation and the likelihood, and have recently shown competitive empirical performance. Compared to the accumulating theoretical studies on related score-based diffusion models, analysis of flow-based models, which are deterministic in both forward (data-to-noise) and reverse (noise-to-data) directions, remain sparse. In this paper, we provide a theoretical guarantee of generating data distribution by a progressive flow model, the so-called JKO flow model, which implements the Jordan-Kinderleherer-Otto (JKO) scheme in a normalizing flow network. Leveraging the exponential convergence of the proximal gradient descent (GD) in Wasserstein space, we prove the Kullback-Leibler (KL) guarantee of data generation by a JKO flow model to be $O(\varepsilon^2)$ when using $N \lesssim \log (1/\varepsilon)$ many JKO steps ($N$ Residual Blocks in the flow) where $\varepsilon $ is the error in the per-step first-order condition. The assumption on data density is merely a finite second moment, and the theory extends to data distributions without density and when there are inversion errors in the reverse process where we obtain KL-$W_2$ mixed error guarantees. The non-asymptotic convergence rate of the JKO-type $W_2$-proximal GD is proved for a general class of convex objective functionals that includes the KL divergence as a special case, which can be of independent interest.
Solution for SMART-101 Challenge of ICCV Multi-modal Algorithmic Reasoning Task 2023
Oct 10, 2023
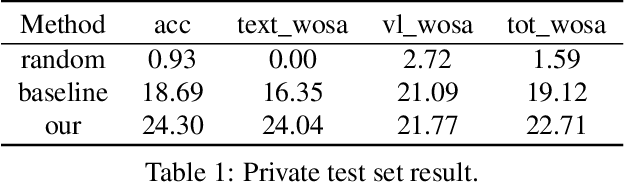
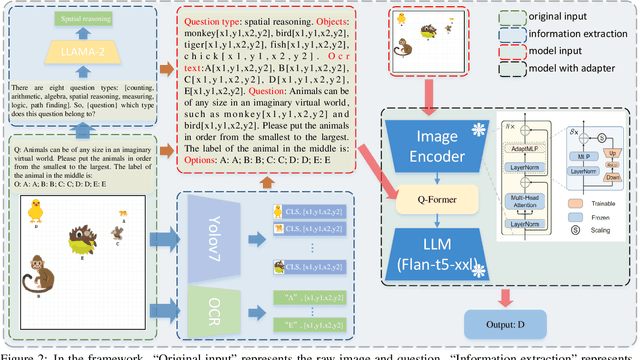
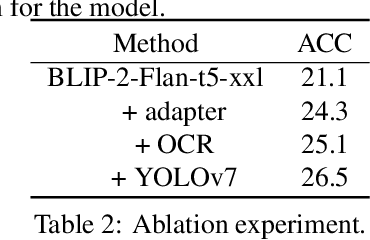
In this paper, we present our solution to a Multi-modal Algorithmic Reasoning Task: SMART-101 Challenge. Different from the traditional visual question-answering datasets, this challenge evaluates the abstraction, deduction, and generalization abilities of neural networks in solving visuolinguistic puzzles designed specifically for children in the 6-8 age group. We employed a divide-and-conquer approach. At the data level, inspired by the challenge paper, we categorized the whole questions into eight types and utilized the llama-2-chat model to directly generate the type for each question in a zero-shot manner. Additionally, we trained a yolov7 model on the icon45 dataset for object detection and combined it with the OCR method to recognize and locate objects and text within the images. At the model level, we utilized the BLIP-2 model and added eight adapters to the image encoder VIT-G to adaptively extract visual features for different question types. We fed the pre-constructed question templates as input and generated answers using the flan-t5-xxl decoder. Under the puzzle splits configuration, we achieved an accuracy score of 26.5 on the validation set and 24.30 on the private test set.
The Solution for the CVPR2023 NICE Image Captioning Challenge
Oct 10, 2023

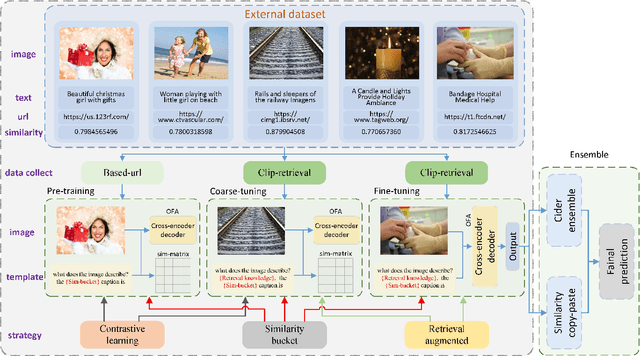
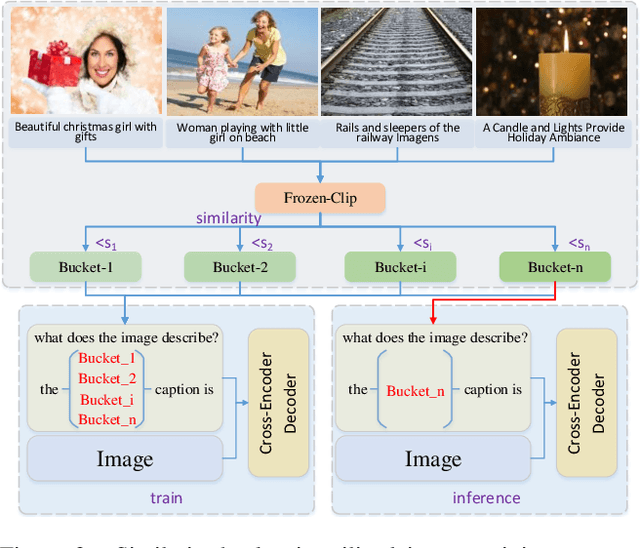
In this paper, we present our solution to the New frontiers for Zero-shot Image Captioning Challenge. Different from the traditional image captioning datasets, this challenge includes a larger new variety of visual concepts from many domains (such as COVID-19) as well as various image types (photographs, illustrations, graphics). For the data level, we collect external training data from Laion-5B, a large-scale CLIP-filtered image-text dataset. For the model level, we use OFA, a large-scale visual-language pre-training model based on handcrafted templates, to perform the image captioning task. In addition, we introduce contrastive learning to align image-text pairs to learn new visual concepts in the pre-training stage. Then, we propose a similarity-bucket strategy and incorporate this strategy into the template to force the model to generate higher quality and more matching captions. Finally, by retrieval-augmented strategy, we construct a content-rich template, containing the most relevant top-k captions from other image-text pairs, to guide the model in generating semantic-rich captions. Our method ranks first on the leaderboard, achieving 105.17 and 325.72 Cider-Score in the validation and test phase, respectively.
Learning Dense Flow Field for Highly-accurate Cross-view Camera Localization
Sep 27, 2023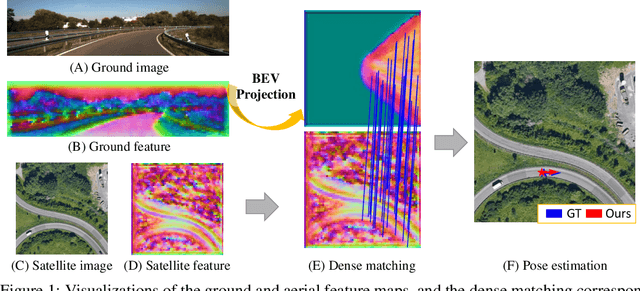
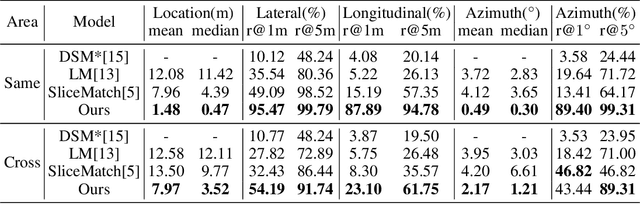
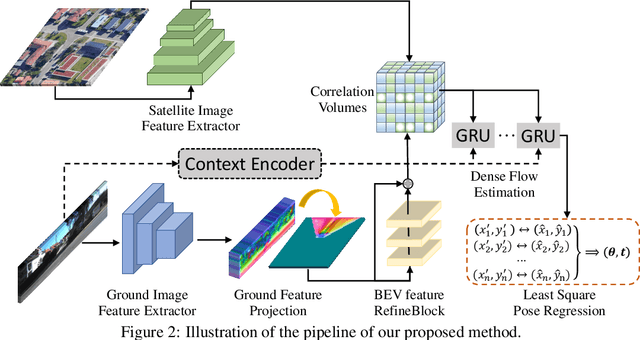

This paper addresses the problem of estimating the 3-DoF camera pose for a ground-level image with respect to a satellite image that encompasses the local surroundings. We propose a novel end-to-end approach that leverages the learning of dense pixel-wise flow fields in pairs of ground and satellite images to calculate the camera pose. Our approach differs from existing methods by constructing the feature metric at the pixel level, enabling full-image supervision for learning distinctive geometric configurations and visual appearances across views. Specifically, our method employs two distinct convolution networks for ground and satellite feature extraction. Then, we project the ground feature map to the bird's eye view (BEV) using a fixed camera height assumption to achieve preliminary geometric alignment. To further establish content association between the BEV and satellite features, we introduce a residual convolution block to refine the projected BEV feature. Optical flow estimation is performed on the refined BEV feature map and the satellite feature map using flow decoder networks based on RAFT. After obtaining dense flow correspondences, we apply the least square method to filter matching inliers and regress the ground camera pose. Extensive experiments demonstrate significant improvements compared to state-of-the-art methods. Notably, our approach reduces the median localization error by 89%, 19%, 80% and 35% on the KITTI, Ford multi-AV, VIGOR and Oxford RobotCar datasets, respectively.
Diffusion Methods for Generating Transition Paths
Sep 19, 2023
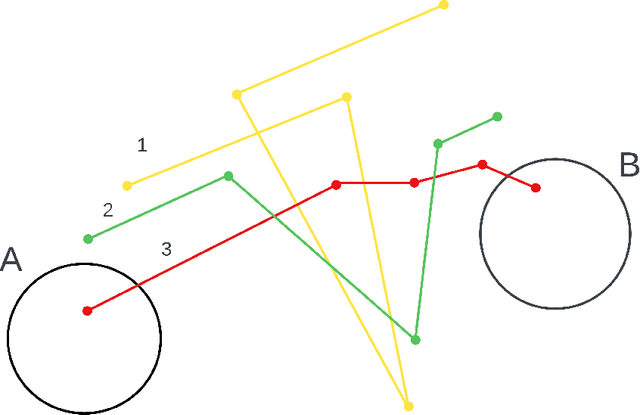
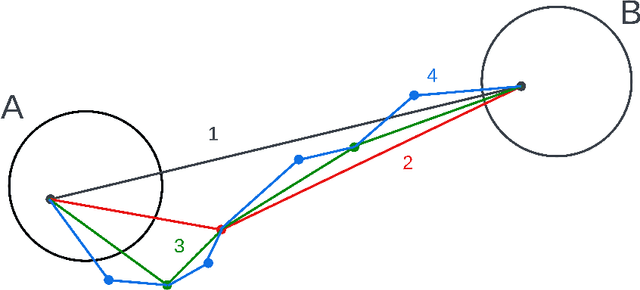
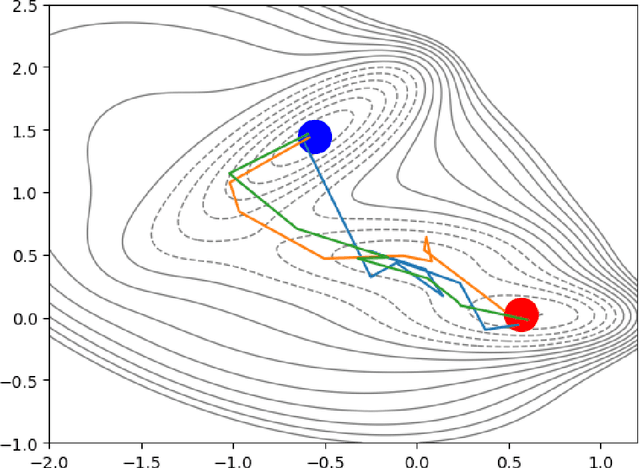
In this work, we seek to simulate rare transitions between metastable states using score-based generative models. An efficient method for generating high-quality transition paths is valuable for the study of molecular systems since data is often difficult to obtain. We develop two novel methods for path generation in this paper: a chain-based approach and a midpoint-based approach. The first biases the original dynamics to facilitate transitions, while the second mirrors splitting techniques and breaks down the original transition into smaller transitions. Numerical results of generated transition paths for the M\"uller potential and for Alanine dipeptide demonstrate the effectiveness of these approaches in both the data-rich and data-scarce regimes.